基于预测型间接迭代学习的SCARA机器人轨迹跟踪控制方法与流程
本发明属于SCARA机器人的高精度轨迹跟踪控制领域,具体涉及一种基于预测型间接迭代学习的SCARA机器人轨迹跟踪控制方法。
背景技术:
机器人技术是集机构学、电子技术、计算机技术、传感技术、控制论、人工智能等多学科于一体的高新技术。其中机器人控制系统的设计涉及到伺服驱动、运动控制、计算机软件等。其中,SCARA机器人是一个复杂的多输入多输出系统,具有时变、强耦合和非线性的动力学特性,并在实际生产中得到了大量应用,例如切割、焊接、涂胶等,这些应用都需要高精度重复跟踪固定的轨迹。机器人的轨迹跟踪控制是指通过给定各关节的驱动力矩,使机器人的位置、速度等状态变量跟踪给定的理想轨迹。
对于机器人来说,控制器设计分为两种:(1)按照机器人实际轨迹与期望轨迹间的偏差进行负反馈控制。这种控制方法控制律简单,易于实现,称为“运动控制”,例如PID控制、模糊控制、鲁棒控制等。(2)充分考虑机器人的动力学模型,设计出更加精细的非线性控制律,即基于模型的控制策略,这种控制方法称为“动态控制”,例如重力补偿控制、计算力矩法、内模控制等。由于机器人时变、强耦合和非线性的动力学特性,并且简单的“运动控制”方法仅仅是基于反馈的控制策略,这使得对于高速高精度的轨迹跟踪控制来说,难以保证系统具有良好的跟踪精度。基于模型的动态控制,虽然能使机器人具有较好的动态和静态性能,但是由于机器人动态模型的复杂性,使得计算过程极其耗时,不利于工程实现。而且在实际的机器人系统中,由于摩擦模型和黏滞力的难以确定,以及结构参数的摄动,导致了无法精确建立机器人的动力学模型。
很多智能控制策略也用来设计机器人的轨迹跟踪控制,例如神经网络控制、滑模变结构控制等。其中,迭代学习控制不需要机器人动力学模型,属于“运动控制”范畴。迭代学习控制,利用控制系统先前的控制经验,根据测量所得的系统实际输出信息和事先给定的目标轨迹的偏差修正不理想的控制信号,运用比较简单的学习算法来寻找一个理想的输入,使被控对象产生期望的运动。其中“寻找”的过程就是被控对象做反复训练的过程,也就是实行迭代学习控制,使系统的实际输出逼近期望目标轨迹的过程。
迭代学习控制又分为直接迭代学习控制和间接迭代学习控制。在机器人控制中,直接迭代学习控制器的输出信号为直接作用于机器人关节的力矩信号。在工程实际中,机器人控制系统一般是多轴运动控制器加伺服驱动器的模式,交流伺服驱动器的内部参数整定好之后,一般不能在线修改,并且多数情况下不允许用户对驱动器输出的力矩信号进行补偿,这使得直接迭代学习控制很难进行工程应用。间接迭代学习控制是利用交流伺服电机编码器输出的实际关节位置与给定期望关节位置之间的偏差来优化调整位置的给定,该策略不需要改变伺服驱动器内部结构,也不需要多轴运动控制器具有力矩补偿接口。虽然间接迭代学习控制能很好克服重复性干扰,但实际生产环境中往往存在电压波动、旁路电机的启动停止、负载脉动等干扰,使得机器人输入力矩易受脉冲干扰的影响。所以,在设计预测型迭代学习控制器时,加入了前馈环节,当有外界干扰时能够有效的通过伺服驱动器反馈和预测型迭代学习控制器前馈的共同作用,快速消除干扰的影响,并且相比于传统PD型迭代学习控制器,预测型迭代学习控制器具有更快的收敛速度和跟踪精度。
技术实现要素:
本发明针对工程实际中,交流电机伺服驱动器的内部参数整定好之后,一般不能在线修改,并且多数情况下不允许用户对驱动器输出的力矩信号进行补偿的问题,为了提高SCARA机器人轨迹跟踪的精度和抗干扰能力,提出了一种基于预测型间接迭代学习的SCARA机器人轨迹跟踪控制方法。首先设计了直接作用于机器人本体的双闭环反馈控制器,其包含一个比例型(P)位置闭环和比例积分(PI)型速度闭环,通过反馈作用实现机器人关节位置和关节速度的跟踪控制。为了提高双闭环控制器的动态性能,通过改进比例微分型迭代学习控制器(PD-ILC),设计得到预测型迭代学习控制器(A-ILC),利用之前运行批次在采样时刻t+Δ处的误差输出信息,来调整下次运行时在采样时刻t处的控制效果,以达到消除重复干扰和加快学习速度的目的。同时为了克服工业环境中脉冲干扰的影响,在设计A-ILC时加入了前馈环节,使SCARA机器人系统能更加快速消除干扰的影响。
为实现以上的技术目的,结合具体案例,本发明将采取以下技术方案:基于预测型间接迭代学习的SCARA机器人轨迹跟踪控制方法,其特征在于:利用SCARA机器人各关节输出的轨迹跟踪误差数据来优化调整关节位置给定,对传统比例微分型迭代学习控制器进行改进,得到预测型迭代学习控制器,以消除重复干扰和加快学习速度,为了快速消除脉冲干扰的影响,在预测型迭代学习控制器中加入前馈环节,技术方案实现步骤如下:
步骤(1):采用D-H参数法构建SCARA机器人数学模型,并将任务空间的期望轨迹逆解到关节空间;
步骤(2):设计直接作用于SCARA机器人本体的双闭环反馈控制器;
步骤(3):通过编码器检测反馈SCARA机器人关节实际位置xi(t)和关节实际运行角速度ωi(t);
步骤(4):设计具有前馈功能的预测型迭代学习控制器;
步骤(5):根据SCARA机器人实际关节位置与期望关节位置的偏差,通过预测型迭代学习控制器,优化调整双闭环反馈控制器的关节位置指令给定;
步骤(6):运行完成后检验是否达到离线迭代学习停止条件,若达到停止条件则停止学习,开始在线运行,否则继续迭代学习。
所述SCARA机器人数学模型包括SCARA机器人正运动学和逆运动学;所述双闭环反馈控制器包括比例型(P)位置闭环和比例积分(PI)型速度闭环,其输入为优化调整后的关节位置指令,输出为作用于机器人关节的力矩信号;所述具有前馈功能的预测型迭代学习控制器,利用前一运行批次的误差经验数据及本次运行的实时误差数据,对双闭环反馈控制器的位置给定进行优化,其表示形式为:
对于PD型迭代学习控制器,其表示形式为:
其中,i表示第i个运行批次,t表示运行采样时刻,ri(t)表示第i次运行时双闭环反馈控制器实际关节位置给定值,rd(t)表示关节期望位置给定,rILC_i(t)表示第i次运行时关节位置给定的调整量,rILC_i-1(t)表示前一运行批次,即i-1次运行时关节位置给定的调整量,ei(t)表示第i次运行时t采样时刻的关节位置跟踪误差,ei-1(t+Δ)表示第i-1次运行时采样时刻t+Δ处的关节位置跟踪误差,ei-1(t)表示第i-1次运行时采样时刻t处的关节位置跟踪误差,k为比例增益、kA表示预测学习增益、Δ为超前采样时间,kP和kD表示比例和微分增益。
根据以上方案,可实现以下的有益效果:
本发明与现有直接型迭代学习控制相比,具有以下优点:
(1)本发明方法不需要改变现有机器人系统的多轴运动控制器加伺服驱动器的控制模式,不需要在线修改驱动器内部参数,不需要用户对驱动器输出的力矩信号进行补偿。
本发明与现有PD型间接迭代学习控制方法相比,具有如下优点:
(1)本发明利用之前运行批次在采样时刻t+Δ处的误差输出信息,来调整下次运行时在采样时刻t处的控制效果,既能够完全克服重复未知干扰,又能加快迭代收敛速度和提高跟踪精度。
(2)本发明在设计预测型迭代学习控制器时,加入了前馈环节,使得预测型迭代学习控制器不仅能利用前一运行批次的误差经验数据,同时能利用本次运行的跟踪误差数据,使得系统在双闭环反馈和迭代学习控制器前馈功能的共同作用下,能快速有效的消除外界干扰。
附图说明
图1为本发明所述的一种基于预测型间接迭代学习的SCARA机器人轨迹跟踪控制方法的系统结构示意图;
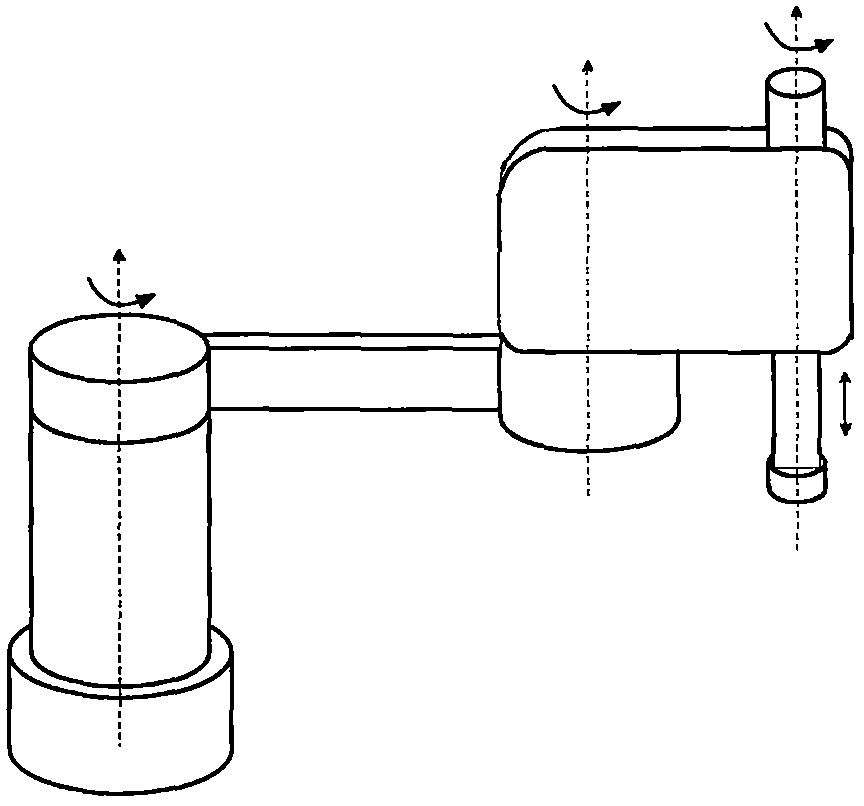
图2为本发明所述SCARA机器人的本体结构图;
图3为本发明所述SCARA机器人连杆坐标系;
图4为本发明所述的一种基于预测型间接迭代学习的SCARA机器人轨迹跟踪控制方法的算法流程图。
具体实施方式
为使本发明的目的、技术方案和带来的有益效果更加的清楚明白,下面参照附图,对本发明作进一步详细说明。
本发明提供了基于预测型间接迭代学习的SCARA机器人轨迹跟踪控制方 法的结构图,如图1所示。双闭环反馈控制器作用于机器人本体,实现关节位置和关节速度的跟踪,在此基础上设计了具有前馈功能的预测型迭代学习控制器,以提高双闭环反馈控制器的动态性能,提升轨迹跟踪精度。根据编码器输出的关节位置数据,预测型迭代学习控制器利用上一运行批次的在采样时刻t+Δ的位置跟踪误差,优化调整本次运行在采样时刻t处的位置给定。当外界存在脉冲干扰时,为了快速消除干扰的影响,在预测型迭代学习控制器中加入前馈环节,使得本次运行的误差信息能够快速通过前馈通道叠加在实际输入中,在与双闭环反馈控制的共同作用下,实现干扰的快速消除。
结合具体SCARA机器人,本发明实现步骤如下:
步骤(1):采用D-H参数法构建SCARA机器人数学模型。
SCARA机器人本体结构如图2所示,按D-H参数法建立SCARA机器人连杆坐标系如图3所示,按照图3所示连杆坐标系得SCARA机器人连杆参数如下:
其中,αn-1为连杆扭角,an-1为连杆长度,θn为关节转角,dn为连杆间距。
设与机器人机座相固连的坐标系O0X0Y0Z0为参考坐标系,每个杆件上固连一个坐标系,即为动坐标系,根据机器人连杆参数,可得连杆之间位姿齐次变换矩阵(记为i-1Ti)为:
个坐标系,即为动坐标系,根据机器人连杆参数,可得连杆之间位姿齐次变换矩阵(记为i-1Ti)为:
式中,c1、s1、c2、s2、c4、s4分别为cos(θ1)、sin(θ1)、cos(θ2)、sin(θ2)、cos(θ4)、sin(θ4)。的缩写形式。
各连杆其次变换矩阵相乘,可得到机器人末端执行器的正运动学方程为:
式中:
正运动学描述了末端连杆坐标系{4}相对基坐标系{0}的位姿,即已知各连杆转动角度求出机器人末端位姿。
已知机器人末端的位姿,需要求出机器人对应于这个位姿的全部关节角,以驱动关节上的电机运动,即SCARA机器人逆运动学为:
式中:
在获取SCARA机器人数学模型后,在任务空间给定期望待跟踪轨迹 f(px(t),py(t),pz(t)),通过运动学逆解,获得对应关节期望角度的位置输入rd(t)。
步骤(2):搭建直接作用于SCARA机器人本体的双闭环反馈控制器,包含一个比例(P)位置闭环和比例积分(PI)速度闭环,其表达形式为:
其中,i表示第i个运行批次,t表示运行采样时刻,Δt为运行采样间隔时间,ri(t)表示第i次运行时双闭环反馈控制器的实际关节位置给定值,xi(t)表示第i次运行时编码器反馈的关节位置信号,ωi(t)表示第i次运行时编码器反馈的关节角速度信号,τi(t)表示第i次运行时作用于关节的力矩信号。Kp为位置环比例增益,Kv和Kvi为速度环比例和积分增益。
步骤(3):通过编码器检测反馈SCARA机器人关节实际位置xi(t)和关节实际运行角速度ωi(t)。
步骤(4):设计具有前馈功能的预测型迭代学习控制器。
预测型迭代学习控制算法利用前一运行批次在采样时刻t+Δ处的输出误差信息,来调整下次运行在采样时刻t处的控制效果。
第i次运行时,机器人关节轨迹跟踪误差为:
ei(t)=rd(t)-xi(t)
对于无前馈的预测型迭代学习控制器,其表示形式为:
第一次运行时,由于还没有前一运行批次的输出信息,所以位置给定调整量为0,因此定义rILC_0(t)=0,使得rILC_1(t)=0。
则可以得到:
rILC_i(t)=kA·(e1(t+Δ)+e2(t+Δ)+…+ei-1(t+Δ))i=2,3,…
由以上所述可以看出,无前馈的预测型迭代学习控制器仅利用了前一运行批次的输出误差经验,而没有利用本次输出的轨迹跟踪误差,这使得当有外界干扰时,系统不能快速有效的消除干扰。所以,本发明设计了具有前馈功能的预测型迭代学习控制器,其表示表示形式为:
其中,K为前馈增益,kA为预测学习增益;Δ为超前采样时间;rd(t)表示各关节待跟踪轨迹;ri(t)表示第i次运行时双闭环反馈控制器的实际关节位置给定值;rILC_i(t)表示第i次运行时各关节位置给定的调整量;xi(t)为第i次运行完成后机器人关节输出角度位置;ei(t)表示第i次运行时关节角度的跟踪误差。
步骤(5):根据SCARA机器人实际关节位置与期望关节位置的偏差,通过预测型迭代学习控制器,优化调整双闭环反馈控制器的关节位置指令给定。
步骤(6):运行完成后检验是否达到离线迭代学习停止条件。
离线迭代学习停止条件为
Δpx(t)、Δpy(t)和Δpz(t)分别代表在采样时刻t处机器人末端在x轴、y轴和z轴上的实际位置与期望位置的偏差;Emax代表一个运行批次过程中,机器人末端在空间中的实际轨迹与期望轨迹偏差的最大值,ξ为最大轨迹跟踪误差的阈值(单位mm)。
本发明提供了基于预测型间接迭代学习的SCARA机器人轨迹跟踪控制方法的算法流程图,如图4所示,进行轨迹跟踪的工程实现流程如下:
(1)轨迹给定。在任务空间给定待跟踪期望轨迹f(px(t),py(t),pz(t)),通过运动学逆解,转换为对应的关节期望角度位置输入rd(t)。
(2)初始化设置。初始化并存储第一次运行的位置指令调整量rILC_1(t)=0,
(3)进行第i次(i从1开始)迭代运行。双闭环反馈控制器的位置指令实际给定为ri(t)=rd(t)+rILC_i(t)+Kei(t),t∈[0,T],同时采样并存储ei(t)。
(4)检验是否达到迭代停止条件。当没有达到停止条件时,置i=i+1,同时根据ei(t)更新rILC_i+1(t)=rILC_i(t)+kAei(t+Δ),返回步骤(3)进行第i+1次运行;否则离线迭代学习停止,保存rILC_i(t),开始在线运行。
- 还没有人留言评论。精彩留言会获得点赞!