基于异常声音和图像事件驱动的智能服务机器人及方法与流程
本发明属于智能安保服务机器人技术领域,特别是一种基于异常声音和图像事件驱动的智能服务机器人及处理方法。
背景技术:
在家庭以及公共安全等领域,对于信息监控等安保装备有着迫切的需求,传统的解决方法是在家庭以及公共场所架设摄像头等监控系统,这需要预先铺设管线,费时费力。
智能服务机器人包括智能安保服务机器人具有更好的灵活性、智能性得到了广泛的关注和应用,但是对于异常事件的检测一般通过摄像头远程监控来实现,这会导致摄像头一直处于开启状态,造成人员的隐私泄露
智能服务机器人在对异常检测时已有了一定方法研究,但是都是基于异常事件的单一特征进行分析的,这种检测方法一般都有局限性,自主分析能力低。专利201110444850.7公开了一种公共场所异常声音的识别与定位方法用于公共场所异常声音识别及定位方法,也只是在音频信号方面进行处理。
技术实现要素:
本发明的目的在于提供一种解决家庭以及公共安全等领域的基于异常声音和图像事件驱动的智能服务机器人及处理方法。
实现本发明目的的技术解决方案为:一种基于异常声音和图像事件驱动的智能服务机器人,包括移动机器人单元、声音和图像传感器、声音和图像事件控制单元以及远程客户端,声音和图像传感器设置在移动机器人单元上,并通过接口与声音和图像事件控制单元相连,声音和图像事件控制单元安装在移动机器人单元上并通过接口与移动机器人单元连接,声音和图像事件控制单元通过网络与远程客户端通信。
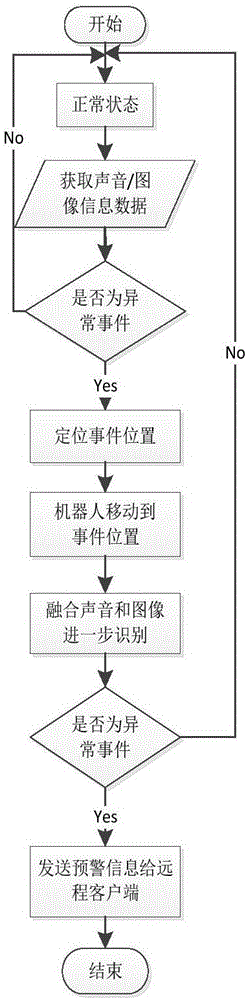
一种基于异常声音和图像事件驱动的智能服务机器人的处理方法,在正常情况下,智能服务机器人停在原处或者在指定区域移动,当听到或者看到有异常的事件时,则导航到事件发生的地点,融合声音和图像进一步识别该事件并根据识别结果做相应处理。
本发明与现有技术相比,其显著优点:(1)本发明在正常情况下机器人在原地或者指定区域移动,避免了摄像头一直拍摄人员特别是家庭环境所造成的隐私泄露以及不舒服感。(2)本发明在正常情况下机器人在原地或者指定区域移动,大大降低了功耗,提高了效率。(3)本发明对异常情况的监测,分别在听觉和视觉方面进行分析,然后进行多模态的生物特征融合处理,解决了单信息分析问题的不足。
下面结合附图对本发明作进一步详细描述。
附图说明
图1是本发明基于异常声音和图像事件驱动的智能服务机器人组成示意图。
图2是本发明基于异常声音和图像事件驱动的智能服务机器人的工作流程。
图3是本发明异常事件的识别、定位以及导航流程图。
图4是本发明声音和图像融合识别事件的流程图。
具体实施方式
结合图1,本发明基于异常声音和图像事件驱动的智能服务机器人,包括移动机器人单元1、声音和图像传感器2、声音和图像事件控制单元3以及远程客户端12,声音和图像传感器2设置在移动机器人单元1上,并通过接口与声音和图像事件控制单元3相连,声音和图像事件控制单元3安装在移动机器人单元1上并通过接口与移动机器人单元1连接,声音和图像事件控制单元3通过网络与远程客户端12通信。该移动机器人单元1用于二维或者三维空间运动,接受声音和图像事件控制单元3的控制命令实现移动的能力。
本发明的移动机器人单元1可以为地面移动机器人或空中无人机。如果移动机器人单元1为地面移动机器人时,包括移动机器人本体6、障碍检测传感器7、控制器8,所述障碍检测传感器7安装在移动机器人本体6上与控制器8连接,用于导航中获取障碍物的距离。控制器8安装在移动机器人本体6上,用于导航中控制移动机器人本体6的速度和方向。
所述声音和图像传感器2包括Kinect传感器的麦克风阵列4和图像传感器5,由麦克风阵列4获取事件声音信号,图像传感器5获得事件场景图像以及深度信息。所述声音和图像事件控制单元3包括计算机9、声音和图像采集模块10、串口通讯模块11,声音和图像采集模块10连接声音和图像传感器2和计算机9,用于读取声音和图像的数据;串口通讯模块11连接控制器8和计算机9,用于计算机9向控制器8传输异常事件的位置信息。
结合图2,本发明利用了上述基于异常声音和图像事件驱动的智能服务机器人来进行智能服务处理方法,在正常情况下,智能服务机器人停在原处或者在指定区域移动,当听到或者看到有异常的事件时,则导航到事件发生的地点,融合声音和图像进一步识别该事件并根据识别结果做相应处理,具体处理过程如下:
1)正常情况下,移动机器人单元1停在原处或者在指定区域移动;
2)同时声音和图像事件控制单元3通过声音和图像传感器2获取声音和图像信息;
3)若声音和图像事件控制单元3识别到声音和图像异常事件,则定位事件发生的位置;
4)声音和图像事件控制单元3控制移动机器人单元1导航到事件发生位置;
5)声音和图像事件控制单元3融合声音和图像进一步识别该事件;
6)若判断为异常事件,则声音和图像事件控制单元3发送事件预警信息给远程客户端12;
7)若判断为正常事件,则返回到步骤1)。
结合图3,本发明的移动机器人单元1对于异常事件的识别、定位以及导航步骤如下:
1)移动机器人单元1上的声音和图像事件控制单元3通过Kinect传感器内部的麦克风阵列4获取异常声音信号,比如判断出异常声音为老人跌倒的声音;
2)声音和图像事件控制单元3中的计算机9首先对获取的声信号进行端点检测、分帧加窗处理,通过倒谱分析提取声信号的特征梅尔频率倒谱系数,采用支持向量机对特征系数进行分类,得到声信号的分类结果;
3)若分类结果为异常事件,声音和图像事件控制单元3中的声音和图像采集模块10获取麦克风阵列4的声信号数据,计算机10对声信号数据进行分帧加窗处理后,声信号矩阵和背景噪声矩阵进行广义特征值分解,将分解的噪声特征向量构造空间谱函数,通过求解极大值得到异常事件发生的方位角;
4)移动机器人单元1得到异常事件的方位角后,计算机3通过串口通讯模块11向控制器8发送方位角,控制器8调整移动机器人单元1向异常事件的发生位置移动,同时控制器8根据移动机器人单元1的运动距离,结合方位角利用三角测量得到异常事件发生的位置距离;
5)在移动机器人单元1移动过程中,根据障碍检测传感器7获取障碍物区域,选择非障碍物区域移动。重复步骤4),最终移动机器人单元1移动到异常事件发生位置。
如图4所示,所述的声音和图像事件控制单元3融合声音和图像进一步识别事件的,具体步骤如下:
1)移动机器人单元1到达发生事件的位置后,声音和图像采集模块10读取声音和图像传感器2采集人的语音信号和人脸图像;
2)声音和图像事件控制单元3提取语音信号的特征梅尔频率倒谱系数进行矢量量化的说话人识别,同时声音和图像事件控制单元3使用Haar分类器对人脸图像进行人脸检测,定位人脸区域,然后声音和图像事件控制单元3对人脸区域进行分块,将小波分解和奇异值分解结合提取人脸特征,最后采用稀疏表示进行人脸识别;
3)声音和图像事件控制单元3在做决策时,采用模糊积分融合语音和人脸,将说话人识别和人脸识别的匹配相似度进行归一化处理分别作为语音和人脸的分类证据,将说话人识别和人脸识别的识别率分别作为语音和人脸的模糊密度,最后通过模糊积分进行非线性加权决策得到最终身份验证的结果,再将分析结果通过网络发送到远程客户端12。
- 还没有人留言评论。精彩留言会获得点赞!