基于HTCVIVE可穿戴设备的机器人演示学习方法与流程
本发明属于机器人控制领域,更具体地涉及一种基于htcvive可穿戴设备的机器人演示学习方法。
背景技术:
近年来,随着机器人技术的迅猛发展,机器人所执行任务多样性与复杂性不断提高,机器人越来越多的应用在与人密切接触、密切交互、密切协作的环境中,需要面对复杂、难以预知的环境、任务和作业对象。因此,传统的针对固定作业的预编程方法已经难以服务机器人的作业要求。为了使机器人能够更加自然的与随机动态的环境进行交互,更加合理的应对作业过程中的突发和未知情况,必须提高其智能化程度。
演示学习使机器人能够通过观察其他人或机器人的动作来学习新的动作,进而能够自主适应新环境,自主获取新技能,不断提升自身的自主作业能力,是提高机器人智能性的重要途径。它可以有效减少编程,降低机器人学习的难度,近年来成为机器人学习控制中的重要研究方向,引起研究者的极大兴趣。
rozo等使用演示学习方法实现了一台六自由度工业机器人能够自主完成ball-in-box的力控制操作任务(rozol.,jiménezp.,torrasc..arobotlearningfromdemonstrationframeworktoperformforce-basedmanipulationtasks[j].intelligentservicerobotics,2013,6(1):33-51.)。在示教者演示阶段采集机械臂末端六维力向量和对应的各关节速度,在动作复现阶段由所得模型在输入当前末端力矩信息时输出各关节角速度,从而驱动机械臂控制盒中小球的运动并使其在孔洞处跌落。该方法采用力传感器采集示教者动作信息,成本比较高,而且需要用隐马尔科夫模型对动作序列建模,计算量大,实时性难以保证。刘昆等人以universalrobot为研究对象,通过一个力/力矩传感器感知操作者的示教力,利用数据采集卡收集到力/力矩的电压模拟信号,在上位机进行转换为力/力矩,然后进行力与位置的转换,实现机器人对操作者动作的学习(刘昆,李世中,王宝祥.基于ur机器人的直接示教系统研究.科学技术与工程,2015,15(28):22-26)。该方法也使用了成本较高的力传感器,由于没有对力传感器采集的信号进行滤波和温度补偿,而且人的示教力波动较大,所以系统精度不高。王朝阳提出一种基于kinect的类人机械臂演示学习方法,通过kinect相机获取人体运动信息,建立人体手臂和机器人之间的映射关系模型,实现对人体手臂运动的学习(王朝阳.基于kinect的类人机械臂演示学习研究[d].硕士学位论文,黑龙江:哈尔滨工业大学,2017.)。该方法借助kinect的人体运动捕捉功能进行人臂运动追踪,该体感设备虽然成本较低,但采集的数据存在较大噪声,容易导致学习的运动轨迹不平稳。
技术实现要素:
基于上述背景,本发明提供一种基于htcvive可穿戴设备的机器人演示学习方法。该方法包括步骤如下:
步骤s0:示教者手持htcvive的单手无线控制器演示机器人要学习的操作任务;
步骤s1:利用lighthouse定位技术得到单手无线控制器在htcvive坐标系的位姿信息,以演示开始时刻的位姿为初始位姿,根据当前位姿和初始位姿,得到单手无线控制器的位姿偏差;
步骤s2:根据htcvive坐标系和机器人坐标系之间的关系,以及s1中单手无线控制器在htcvive坐标系下的位姿偏差,得到机器人的位姿偏差;
步骤s3:根据s2的机器人位姿偏差,得到机器人下一步的运动调整量,控制机器人运动,记录机器人的末端位姿;
步骤s4:重复步骤s0到s3,直到操作任务演示结束,得到整个演示过程的机器人末端运动轨迹;
步骤s5:对s4的机器人末端运动轨迹进行卡尔曼滤波,得到机器人的学习轨迹,将学习轨迹发送给机器人,实现对演示内容的重现。
进一步所述,其中演示学习过程中只用到一个单手无线控制器。
进一步所述,其中步骤s1中所述的单手无线控制器位姿偏差如下:
利用htcvive的lighthouse定位技术,得到单手无线控制其在htcvive坐标系的位置和姿态,以演示开始时刻的姿态为初始位姿,根据当前位姿和初始位姿,得到单手无线控制器偏差[dx,dy,dz,drx,dry,drz]t:
其中,[hx,hy,hz,hrx,hry,hrz]t是单手无线控制器的当前位姿,[hx0,hy0,hz0,hrx0,hry0,hrz0]t是单手无线控制器的初始位姿。
进一步所述,其中步骤s2中所述的机器人的位姿偏差:
利用通用旋转变换,将s1的单手无线控制器位姿偏差[dx,dy,dz,drx,dry,drz]t转换为位姿矩阵th。根据htcvive坐标系与机器人坐标系的关系矩阵tm,得到机器人的位姿偏差:
t=thtm(2)
根据通用旋转变换,可将公式(2)的位姿矩阵t等价变换成六维位姿向量[x,y,z,δθx,δθy,δθz]t。
进一步所述,其中步骤s3中所述的机器人下一步的运动调整量如下:
其中,λp是调整系数。
将式(3)所示的运动调整量发送给机器人,控制机器人运动,记录机器人运动后的末端位姿j。
进一步所述,其中步骤s4中所述的整个演示过程的机器人运动轨迹如下:
每个控制周期,重复步骤s0到s3,记录机器人的末端位姿。操作任务演示结束后,得到机器人运动轨迹为为:
w=(j0,j1,…,jm)(4)
其中,m是演示过程的控制周期数。
进一步所述,其中步骤s5中所述的机器人学习轨迹如下:
建立卡尔曼滤波的预测模型:
其中,
卡尔曼增益系数更新如下:
ki+1=(pi+q)/(pi+q+r)(6)
其中,pi是上一次估计值的方差,q是高斯噪声的方差,r是真实值的方差。
估计值的方差计算如下:
pi+1=(1-ki+1)pi(7)
根据s4的机器人运动轨迹w,利用公式(5)~(7),对s4的机器人运动轨迹进行卡尔曼滤波,得到机器人的学习轨迹l为:
将学习轨迹l发送给机器人,即可实现对演示任务的重现。
基于上述技术方案可知,本发明具有以下有益效果:传统的示教板、编程等示教技术对操作者要求较高,示教过程繁琐、费时效率不高。当前的演示学习方法多采用力/力矩传感器,成本高,而且采集过程复杂,且需要对采集的数据进行温度补偿。基于体感相机进行演示学习的方法获取人体运动信息较容易,但学习效果受限于体感相机的运动捕捉精度。
为了提高机器人行为的自主性,降低非专业人员参与机器人控制的难度,本发明针对机器人的演示学习,采用htcvive可穿戴设备,通过示教者手持单手无线控制器演示机器人要学习的操作任务,利用单手无线控制器的位姿偏差,得到机器人在演示控制过程中的末端运动轨迹,进而实现机器人对演示任务的学习。
本发明借助htcvive的lighthouse定位技术,很容易提取单手控制器的六维位姿信息,演示学习的实时性好。本发明使用的htcvive可穿戴设备价格低廉,成本低,仅需要手持单手无线控制器即可实现操作任务的演示,毫无经验的操作者也可以进行机器人的演示示教,操作简便。本发明以演示开始时刻的状态为初始状态,演示学习可以在任何位姿状态下开始,大大提高了演示学习效率。
附图说明
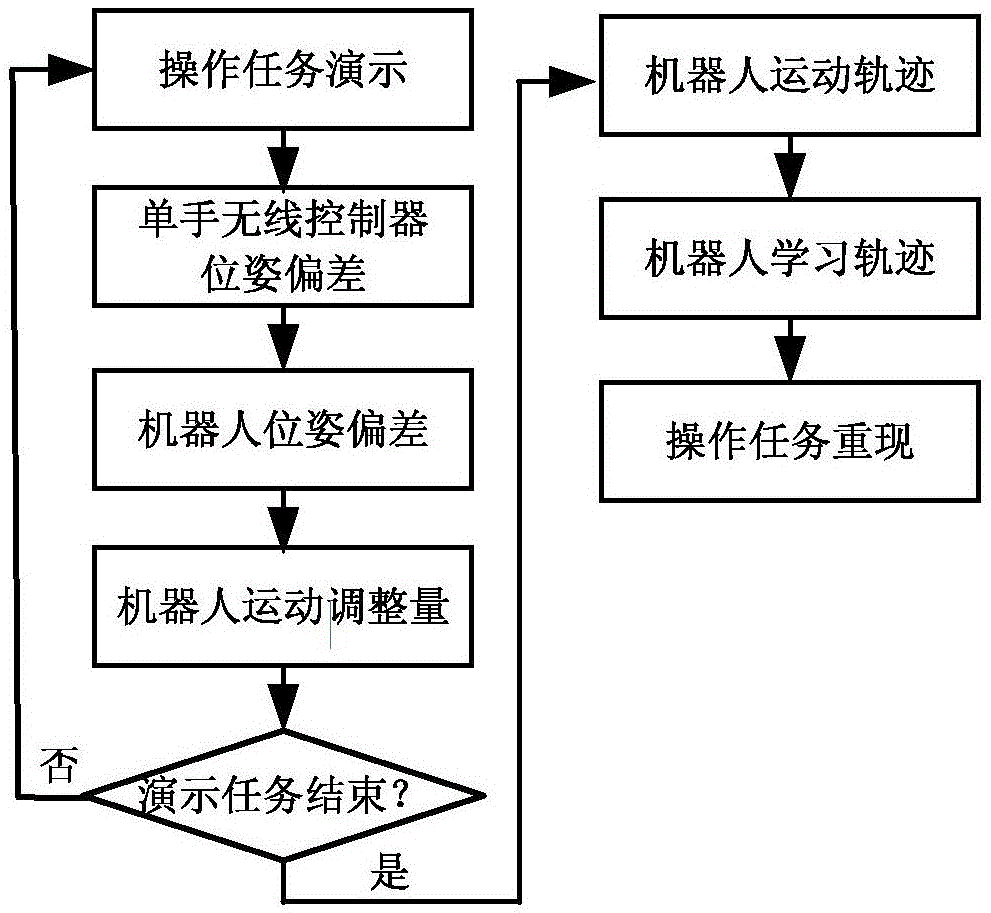
图1为本发明的基于htcvive可穿戴设备的机器人演示学习方法流程图。
具体实施方式
下面结合附图对本发明的实施例作详细的说明:本实施例在以本发明技术方案为前提下进行实施,结合详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述实施例。
本发明公开了一种基于htcvive可穿戴设备的机器人演示学习方法。本发明通过示教者手持htcvive的单手无线控制器演示机器人要学习的操作任务,利用单手无线控制器的位姿偏差,得到机器人在演示控制过程中的末端运动轨迹,进而实现机器人对演示任务的学习。
更具体地,作为本发明的一个优选实施例,如图1示出本发明的基于htcvive可穿戴设备的机器人演示学习方法流程图。演示学习过程中,首先示教者手持htcvive的单手无线控制器演示操作任务,然后根据无线控制器在演示过程中的示教轨迹,控制机器人运动,得到机器人在演示过程中的末端运动轨迹,最后,对机器人末端运动轨迹进行卡尔曼滤波,得到机器人的学习轨迹,实现演示任务的学习。该方法包括以下步骤:
第一步:示教者手持htcvive的单手无线控制器演示机器人要学习的操作任务。利用lighthouse定位技术得到单手无线控制器在htcvive坐标系的位姿信息,以演示开始时刻的位姿为初始位姿,根据当前位姿和初始位姿,得到单手无线控制器的位姿偏差;
第二步:根据htcvive坐标系和机器人坐标系之间的关系,以及第一步中单手无线控制器在htcvive坐标系下的位姿偏差,得到机器人的位姿偏差;
第三步:根据第二步的机器人位姿偏差,得到机器人下一步的运动调整量,控制机器人运动,记录机器人的末端位姿;
第四步:重复第一步到第三步,直到操作任务演示结束,得到整个演示过程的机器人运动轨迹;
第五步:对第四步的机器人末端轨迹进行卡尔曼滤波,得到机器人的学习轨迹,将学习轨迹发送给机器人,实现对演示内容的重现。
所述第一步,具体如下:
利用htcvive的lighthouse定位技术,得到单手无线控制其在htcvive坐标系的位置和姿态,以演示开始时刻的姿态为初始位姿,根据当前位姿和初始位姿,利用公式(1),得到单手无线控制器偏差。
其中,[hx,hy,hz,hrx,hry,hrz]t是单手无线控制器的当前位姿,[hx0,hy0,hz0,hrx0,hry0,hrz0]t是单手无线控制器的初始位姿。
所述第二步,具体如下:
根据第一步的单手无线控制器位姿偏差,以及htcvive坐标系与机器人坐标系的关系矩阵tm,利用公式(2),得到机器人的位姿偏差。
其中式(2)由以下具体步骤获得:
利用通用旋转变换,将第一步的单手无线控制器位姿偏差[dx,dy,dz,drx,dry,drz]t转换为位姿矩阵th。根据htcvive坐标系与机器人坐标系的关系矩阵tm,得到机器人的位姿偏差:
t=thtm(2)
根据通用旋转变换,可将公式(2)的位姿矩阵t等价变换成六维位姿向量[x,y,z,δθx,δθy,δθz]t。
所述第三步,具体如下:
根据第二步的机器人位姿偏差,利用公式(3),得到机器人下一步的运动调整量,控制机器人运动,记录机器人运动后的末端位姿。
其中,λp是调整系数。
所述第四步,具体如下:
每个控制周期,重复步骤第一步到第三步,记录机器人的末端位姿。操作任务演示结束后,得到式(4)所示的机器人运动轨迹。
w=(j0,j1,…,jm)(4)
其中,m是演示过程的控制周期数。
所述第五步,具体如下:
基于第四步得到的机器人运动轨迹,根据公式(5)建立卡尔曼滤波预测模型,根据公式(6)和(7)更新卡尔曼增益系数,对机器人运动轨迹进行卡尔曼滤波,得到式(8)所示的机器人学习轨迹,将学习轨迹发送给机器人,实现对演示任务的重现。
建立卡尔曼滤波的预测模型:
其中,
卡尔曼增益系数更新如下:
ki+1=(pi+q)/(pi+q+r)(6)
其中,pi是上一次估计值的方差,q是高斯噪声的方差,r是真实值的方差。
估计值的方差计算如下:
pi+1=(1-ki+1)pi(7)
根据第四步的机器人运动轨迹w,利用公式(5)~(7),对第四步的机器人运动轨迹进行卡尔曼滤波,得到机器人的学习轨迹l为:
以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!