基于感知增强和场景迁移的深度强化学习机器人抓取方法
1.本发明涉及智能机器人领域,具体是基于感知增强和场景迁移的深度强化学习机器人抓取方法。
背景技术:
2.机器人抓取技术就是借助机械臂和夹爪将目标对象抓取起来,它是许多机器人任务的基础,是很多操作的前提环节。许多工业场景中都离不开抓取,比如在码垛中需要先将对象抓取起来才能进行堆放,在分拣中需要先将对象抓取起来才能进行分类放置,在装配中需要先将零件抓取起来才能进行组装。
3.目前,工业上应用的比较多的机器人抓取算法是通过模板匹配的方法,具体流程是首先对要抓取的对象建立cad模型,将所有的cad模型保存起来形成模板数据库,然后扫描抓取环境得到场景点云数据,使用模板在场景点云中通过特征信息进行匹配,得到抓取对象的位姿,这种方法多用于目标物体单一的情况,如果要抓取的对象种类繁多,将难以保证模板匹配准确性。面对非结构化环境的复杂性,人工智能技术的发展为机器人抓取提供新思路,基于深度学习的机器人抓取技术主要是标注一些带有正确位姿标签的数据,通过深度学习网络进行有监督训练,这种方法需要标注大量训练数据集,耗费人力物力,且在测试过程中对于训练集中未曾见过的物体抓取效果不是很好,也就是说模型泛化能力不好。
技术实现要素:
4.本发明的目的在于解决现有技术中存在的问题,提供基于感知增强和场景迁移的深度强化学习机器人抓取方法,深度强化学习是一种自监督的学习方法,无需去人工准备训练数据集,该方法让机器人去自主去探索抓取,如果抓取成功便给予奖励,否则便给予惩罚,通过不断试错,使得机器人能够自主掌握抓取能力。
5.本发明为实现上述目的,通过以下技术方案实现:
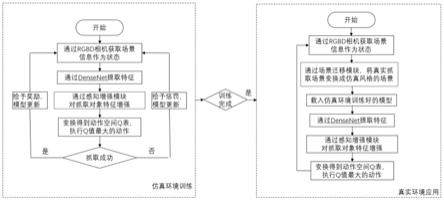
6.基于感知增强和场景迁移的深度强化学习机器人抓取方法,首先进行仿真环境训练,获得算法模型,然后再进行真实环境应用;
7.所述仿真环境训练包括步骤:
8.s11、通过rgb-d相机获取场景信息作为状态;
9.s12、通过densenet提取特征;
10.s13、通过感知增强模块对抓取对象特征增强;
11.s14、变换得到动作空间q表,执行q值最大的动作;
12.s15、判定是否抓取成功,如果抓取成功则给予奖励,否则给予惩罚,并进行模型更新;
13.所述真实环境应用包括步骤:
14.s21、通过rgb-d相机获取场景信息作为状态;
15.s22、通过场景迁移模块,将真实抓取场景变换成仿真风格的场景;
16.s23、载入仿真环境训练好的模型;
17.s24、通过densenet提取特征;
18.s25、通过感知增强模块对抓取对象特征增强;
19.s26、变换得到动作空间q表,执行q值最大的动作。
20.优选的,所述步骤s11和s21中,将通过rgb-d相机拍摄的rgb-d图像进行正交变换并根据工作区域得到224
×
224尺寸的rgb-d俯视图像,以此作为状态输送给算法模型。
21.优选的,所述步骤s13和s25中,感知增强模块包括densenet卷积网络、基于正弦相似度的感知增强模块以及全卷积网络,在进行特征增强时,首先将实际抓取场景的rgb-d图送入densenet卷积网络进行特征提取,得到特征矩阵(1
×
2048
×
20
×
20),同时,将抓取场景背景rgb-d图送入同一个densenet卷积网络进行特征提取,得到特征矩阵(1
×
2048
×
20
×
20),将实际抓取场景和背景的特征矩阵中的20
×
20子矩阵两两对应进行正弦相似度检测,得到相似度指数α,α的区间为0-1,通过1-α得到实际的特征权重,最后得到2048个特征权重,然后将权重与之前实际抓取场景特征矩阵相乘得到感知增强后的特征矩阵,传入后续全卷积网络。
22.优选的,所述步骤s14和s26中,全卷积网络通过卷积计算以及上采样,得到224
×
224
×
12的q表矩阵,每个值对应着动作空间中的具体动作,从中选取q值最大的动作来进行抓取。
23.优选的,所述步骤s22中,将仿真环境背景去除后的图片和仿真环境原始图片作为配对数据集进行训练,让模型学习从仿真环境背景去除后的图片到仿真环境原始图片的映射,训练完成后,在真实环境下应用时,也将真实环境下的图片进行背景去除,然后通过pix2pix模型变换成仿真环境风格的图片,这样即可应用仿真环境下训练的模型。
24.优选的,在背景去除环节,采用grabcut法和漫水填充法混合的算法去除背景。
25.对比现有技术,本发明的有益效果在于:
26.1、与基于模板匹配的方法相比,现有的基于模板匹配的方法需要建立模板数据库,每次增加新的抓取对象都要进行3d建模以便进行匹配,而本发明的深度强化学习方法能够对新的抓取对象具有较好的抓取效果,也就是说算法模型具有较好的泛化能力。
27.2、与基于深度学习的机器人抓取方法相比,现有的基于深度学习的机器人抓取方法需要标注大量数据集进行训练学习,而本发明的机器人抓取技术采用自监督的学习方式,能够让机器人自主去进行学习,不用去耗费大量人力物力标注数据集。
28.3、深度强化学习主要包括感知层和决策层,本发明的机器人抓取方法在感知层方面进行改进,设计了一种抓取对象特征增强方法,将感知注意力集中在抓取对象上,抑制环境背景的影响,从而促进抓取性能提升;针对深度强化学习在真实机器人上训练成本高的问题,本发明提出一种场景迁移的方法,首先让机器人在仿真环境下训练,在应用到真实机器人上时采用将真实抓取场景变换成仿真环境风格,从而可以直接将仿真环境下训练的模型直接应用到真实机器人上,而不用在真实机器人上进行训练,克服深度强化学习在真实机器人上训练成本高的问题。
附图说明
29.附图1是本发明的算法总体结构图;
30.附图2是本发明的感知增强模块的示意图;
31.附图3是仿真环境和真实环境图的对比图;
32.附图4是本发明的场景迁移模块流程图;
33.附图5是场景替换测试结果的对比图。
具体实施方式
34.下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本技术所限定的范围。
35.实施例:
36.1)总体方案:
37.如附图1,本发明所述是基于感知增强和场景迁移的深度强化学习机器人抓取方法,主要包括两个部分,一个是算法模型仿真训练部分,一个是真实机器人应用部分,首先进行仿真环境训练,获得算法模型,然后再进行真实环境应用,让算法模型在仿真环境中训练是因为在真实机器人上的训练成本高,在仿真环境下训练好了之后直接在真实机器人上应用可以节省训练成本。
38.深度强化学习过程可以看做一个马尔可夫决策过程,在时刻t,机器人根据状态s
t
,选择并执行一个动作a
t
,根据奖励函数被基于奖励r(s
t
,a
t
),深度强化学习的目的是学习一个最优的策略来获取最大的累积奖励。
39.结合机器人抓取的过程特点,可以将机器人抓取过程归纳为马尔可夫决策过程。本发明采用深度q学习算法作为基础,因此,需要明确机器人抓取任务的状态、动作、奖励。
40.为了获取状态,首先通过rgb-d相机拍摄rgb-d图像,将图像进行正交变换并根据工作区域得到224
×
224尺寸的rgb-d俯视图像,以此作为状态输送给算法模型。
41.动作方面,为了方便训练,将抓取动作空间进行简化和离散化,机械臂是六自由度的,这里仅考虑垂直抓取,因此就是四自由度,也就是仅仅包括抓取的位置坐标(x,y,z)以及沿z轴旋转角度θ。抓取点的(x,y)坐标与状态图的像素一一对应,并根据深度图可以得到抓取点z坐标。沿z轴旋转角度离散成12种角度(k
×
30
°
,k=1,2,3
…
12),因此动作空间主要有12
×
224
×
224种动作。
42.奖励方面根据夹爪反馈传感自动判定是否抓取成功,如果抓取成功则给予奖励1,否则给予奖励0。总之,将经过变换得到的224
×
224尺寸的rgb-d俯视图输入到算法模型,模型输出对应动作空间的12
×
224
×
224的q表,在训练完成后,执行q表中q值最大对应的动作,即可实现抓取。
43.2)感知增强模块
44.深度强化学习主要包括感知层和决策层,感知层用于提取状态的特征信息并传输给决策层进行决策。可以说感知层的特征提取效果将影响算法的整体效果。在抓取任务中,我们希望感知注意力集中在抓取对象上,场景的背景信息不是我们关注的重点,因此,本发明提出了一种面向抓取场景的感知增强模块,如图2所示,其基本思想是对卷积网络提取的抓取场景特征进行加权,如果某个特征与背景对应的特征相似度低,则代表该特征包含更多的抓取对象信息,赋予该特征较高的权重,相反,如果某个特征与背景对应的特征相似度
高,则赋予该特征较低的权重。
45.算法的网络模型可以分为三个部分,分别是densenet特征提取网络、基于正弦相似度的感知增强模块以及全卷积网络。densenet是一种主流的卷积神经网络,其优点是减轻了梯度消失,加强了特征传递,减少了参数量,在本发明中主要用于特征的初步提取。densenet提取到的特征权重都是一样的,并不对抓取对象相关特征和背景相关特征进行区分,本发明期望对抓取对象进行感知增强,因此设计了一种基于正弦相似度的感知增强模块。首先将实际抓取场景的rgb-d图送入densenet卷积网络进行特征提取,得到特征矩阵(1
×
2048
×
20
×
20),同时,将抓取场景背景rgb-d图送入同一个densenet卷积网络进行特征提取,得到特征矩阵(1
×
2048
×
20
×
20),将实际抓取场景和背景的特征矩阵中的20
×
20子矩阵两两对应进行正弦相似度检测,得到相似度指数α,区间为0-1。由于我们期望相似度高的权重小,因此通过1-α得到实际的特征权重,最后得到2048个特征权重。将权重与之前实际抓取场景特征矩阵相乘得到感知增强后的特征矩阵,传入后续全卷积网络。全卷积网络通过卷积计算以及上采样,得到224
×
224
×
12的q表矩阵,每个值对应着动作空间中的具体动作,从中选取q值最大的动作来进行抓取。本发明提出的感知增强模块,能够将机器人抓取的感知注意力集中在抓取对象上,减少背景的干扰。
46.3)场景迁移模块
47.深度强化学习的训练是一种自监督的过程,它让智能体通过自主试错的方式来进行学习。在机器人抓取任务中,让真实机械臂在真实场景下大量试错训练费时费力,对机械臂造成磨损,训练成本非常高。因此,本发明的训练环节将在仿真环境下进行,训练完成后直接将模型应用到真实场景。然而,仿真环境和真实环境的视觉风格是不一样的,如图3所示,在仿真环境下训练的模型不一定能适应真实场景。为此,本发明提出了一种场景迁移模块,能将真实环境风格变换成仿真环境风格,这样就可以直接应用在仿真环境下的模型。
48.场景迁移模块的具体的流程如图4所示。在场景迁移模块中主要用到一种风格变换对抗生成网络pix2pix,这种网络能够将a风格的图像变换成b风格的图像。然而,这种网络需要配对的训练数据集,而准备仿真和真实环境下配对的数据集工作量非常大,为此,这里换了一种思路,将仿真环境背景去除后的图片和仿真环境原始图片作为配对数据集进行训练,让模型学习从仿真环境背景去除后的图片到仿真环境原始图片的映射,训练完成后,在真实环境下应用时,也将真实环境下的图片进行背景去除,然后通过pix2pix模型变换成仿真环境风格的图片,这样即可应用仿真环境下训练的模型。在背景去除环节,采用grabcut法和漫水填充法混合的算法,能够有效去除背景,避免背景残留。
49.为了验证场景迁移模块效果,将变换前后的图像分别输入到在仿真环境下训练好的模型,得到热力图结果如图5所示。热度越高的地方代表在该位置抓取成功可能性越高。可以看出,变换后图片的测试结果热度更聚焦,在不存在抓取对象的地方不会有明显热度,从而验证了场景迁移模块的有效性。
50.本发明提出一种感知增强的深度强化学习机器人抓取算法,能够对抓取对象特征进行增强,抑制环境背景特征,促进抓取性能的提升。
51.本发明提出一种场景迁移深度强化学习机器人抓取训练方法,可以让机器人在仿真环境下训练,训练完成后直接应用到真实机器人上,能够节省训练成本。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1