基于卷积神经网络融合的家庭服务机器人抓取检测方法
1.本发明涉及深度学习以及服务机器人技术领域,具体涉及一种基于卷积神经网络融合的家庭服务机器人抓取检测方法。
背景技术:
2.进入21世纪,大数据、人工智能和多维传感器技术被广泛应用于机器人和人们对高质量服务需求的快速增长,使服务机器人有了跨越式的发展。伴随着中国开始进入老龄化阶段,社会对家庭服务机器人的需求不断增加。为了护理照料残疾人和老年人,家庭服务机器人需要能对日常环境下的物体,比如茶杯、饮料瓶等生活用品进行抓取。抓取方法一般有分析方法和经验方法两种,基于分析的方法通常需要接触模型和刚体建模,人工复杂度高;基于经验或数据驱动的方法在复杂场景下表现差。
3.随着卷积神经网络的发展,深度学习在机器人抓取检测领域应用越来越广泛,出现了一系列基于卷积神经网络的抓取检测方法。当前基于深度学习的抓取检测方法对单物体进行抓取检测已经取得较好的精度和实时性,但是对于多物体场景下的抓取检测,多数方法只提供物体的可抓取位置,不能为机器人提供指定物体的抓取姿态信息,而且检测精度和检测效率较低。
4.因此,如何在多物体场景下提供高效的抓取检测方案是本领域技术人员目前需要解决的问题。
技术实现要素:
5.针对上述研究的问题,本发明提出了一种基于卷积神经网络融合的家庭服务机器人抓取检测方法,能够实现在多物体场景下高效的完成目标物体抓取位置和抓取概率值的预测。
6.本发明采用的技术方案如下:
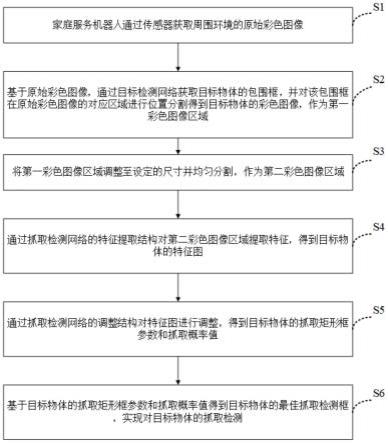
7.一种基于卷积神经网络融合的家庭服务机器人抓取检测方法,包括如下步骤:
8.s1:通过安装于家庭服务机器人上面的传感器获取周围环境的原始彩色图像和原始深度图像;
9.s2:基于所述原始彩色图像,通过基于深度学习的目标检测网络获取目标物体的包围框,并对所述包围框在所述原始彩色图像的对应区域进行位置分割得到目标物体的彩色图像,作为第一彩色图像区域;
10.s3:将所述第一彩色图像区域调整至设定的尺寸并均匀分割成7
×
7个小单元,作为第二彩色图像区域;
11.s4:通过抓取检测网络的特征提取结构对所述第二彩色图像区域提取特征,得到目标物体的特征图;
12.s5:通过抓取检测网络的调整结构对所述特征图进行调整,得到目标物体的抓取矩形框参数x,y,h,w,sinθ,cosθ和抓取概率值p;
13.s6:基于p,x,y,h,w,sinθ,cosθ得到目标物体的最佳抓取检测框,实现对目标物体的抓取检测;
14.其中p,x,y,h,w,sinθ,cosθ分别代表抓取矩形框的抓取概率值、中心点坐标、高度、宽度、朝向角的正弦值、朝向角的余弦值。
15.在一些优选的实施方式中,步骤s3中“将所述第一彩色图像区域调整至设定的尺寸并均匀分割成7
×
7个小单元,作为第二彩色图像区域”,其方法为:通过双线性插值法将第一彩色图像区域调整至设定的尺寸并均匀分割成7
×
7个小单元,得到第二图像区域。
16.在一些优选的实施方式中,步骤s4中“特征提取结构”,其是由卷积分量以及四个残差分量构建,每个卷积分量是由一个二维(2d)卷积、relu激活函数和一个批处理归一化函数组成,每个残差分量是由卷积分量和残差单元组成。
17.在一些优选的实施方式中,步骤s5中“调整结构”,其是由三个2d卷积构建。
18.在一些优选的实施方式中,步骤s6的具体步骤为:
19.s6.1:选择最高抓取概率值所对应的x,y,h,w作为最佳抓取矩形的中心坐标和最佳抓取矩形的高、宽;
20.s6.2:最佳抓取矩形的朝向角为:
[0021][0022]
s6.3:获取深度图像的深度信息对所述最佳抓取矩形参数完成平面到三维的转换,获得目标物体真实位置和姿态的信息。
[0023]
在一些优选的实施方式中,所述抓取检测网络的损失函数为:
[0024][0025]
其中,l
loss
为抓取检测网络在训练时获取的损失值,s表示图像横、纵轴分成的单元格个数,b表示每张图像选取的标签值个数,p表示每个单元格预测的参数个数,pi、表示每个单元格的抓取概率标签值与预测值,c
i,j
、表示每个单元格的抓取参数标签值与预测值。
[0026]
本发明的有益效果:
[0027]
本发明实现了在多物体场景下高效的对目标物体抓取位置和抓取概率值的预测。本发明通过由抓取检测网络的提取特征结构对目标物体进行特征提取,然后通过调整结构获得抓取矩阵框参数,进而得到最佳抓取检测框,实现对目标物体的抓取检测,能够在保证较好实时性的同时,提供较为准确的抓取检测结果,有效提升了抓取检测的质量。
附图说明
[0028]
图1为本发明的基于卷积神经网络融合的家庭服务机器人抓取检测方法流程示意图;
[0029]
图2为本发明的抓取检测网络结构示意图;
[0030]
图3为本发明的用于训练抓取检测网络的抓取参数标签图;
具体实施方式
[0031]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
[0032]
本发明的一种基于卷积神经网络融合的家庭服务机器人抓取检测方法,如图1所示,该方法包括以下步骤:
[0033]
s1:通过安装于家庭服务机器人上面的传感器获取周围环境的原始彩色图像和原始深度图像;
[0034]
s2:基于所述原始彩色图像,通过基于深度学习的目标检测网络获取目标物体的包围框,并对所述包围框在所述原始彩色图像的对应区域进行位置分割得到目标物体的彩色图像,作为第一彩色图像区域;
[0035]
s3:将所述第一彩色图像区域调整至设定的尺寸并均匀分割成7
×
7个小单元,作为第二彩色图像区域;
[0036]
s4:通过抓取检测网络的特征提取结构对所述第二彩色图像区域提取特征,得到目标物体的特征图;
[0037]
s5:通过抓取检测网络的调整结构对所述特征图进行调整,得到目标物体的抓取矩形框参数x,y,h,w,sinθ,cosθ和抓取概率值p;
[0038]
s6:基于p,x,y,h,w,sinθ,cosθ得到目标物体的最佳抓取检测框,实现对目标物体的抓取检测;
[0039]
其中p,x,y,h,w,sinθ,cosθ分别代表抓取矩形框的抓取概率值、中心点坐标、高度、宽度、朝向角的正弦值、朝向角的余弦值。
[0040]
为了更清晰地对本发明基于卷积神经网络融合的家庭服务机器人抓取检测方法进行说明,下面对本发明方法一种实施例中各步骤进行展开详述。
[0041]
该实施例为一种较优的实现方式,预先构建一个抓取检测网络,基于构建的训练样本集并结合预先设计的损失函数(具体损失函数的设置会在下文具体展开说明)对该网络进行训练。本发明使用x,y,h,w,θ这5个参数对抓取矩形进行表征,其中x,y为抓取矩形的中心,h,w为抓取矩形的高度和宽度,为抓取矩形的宽度方向与图像水平方向的角度,称之为抓取矩形的朝向角,并对每个抓取矩形,设定一个抓取概率值p∈[0,1]。
[0042]
s1:通过安装于家庭服务机器人上面的传感器获取周围环境的原始彩色图像和原始深度图像;
[0043]
在本实施例中,服务机器人通过安装在自身的kinect传感器获取周围环境的原始彩色图像和原始深度图像。
[0044]
s2:基于所述原始彩色图像,通过基于深度学习的目标检测网络获取目标物体的包围框,并对所述包围框在所述原始彩色图像的对应区域进行位置分割得到目标物体的彩色图像,作为第一彩色图像区域;
[0045]
在本实施例中,基于所述原始彩色图像,利用基于深度学习的目标检测网络进行目标物体的检测,得到目标物体的包围框,进而得到该包围框的四个顶点的坐标,然后对顶点坐标所在区域进行位置分割,得到目标物体的彩色图像,称之为第一彩色图像区域;其中,在本发明中,目标检测与分割网络采用的是yolov5。
[0046]
s3:将所述第一彩色图像区域调整至设定的尺寸并均匀分割成7
×
7个小单元,作为第二彩色图像区域;
[0047]
在本实施例中,根据抓取检测网络输入图片和第一彩色图像的大小可以得到两者的高、宽缩放比,然后利用双线性插值法,先在高度方向上作线性插值,再在宽度方向上作线性插值,调整到设定尺寸,最后再均匀分割成7
×
7个小单元,获得第二彩色图像区域。
[0048]
s4:通过抓取检测网络的特征提取结构对所述第二彩色图像区域提取特征,得到目标物体的特征图;
[0049]
在本实施例中,将第二彩色图像区域送入抓取检测网络中,如图2所示,经过特征提取结构得到特征图。
[0050]
其中,抓取检测网络是基于yolov5的backbone构建,特征提取结构包含卷积分量和残差分量,将该结构分为五部分为{c1,c2,c3,c4,c5},其中c1对输入图像进行调整,c2,c3,c4,c5对调整后的图像进行特征提取。目标图像经过特征提取结构后生成大小为7
×7×
1024的特征图。
[0051]
s5:通过抓取检测网络的调整结构对所述特征图进行调整,得到目标物体的抓取矩形框参数x,y,h,w,sinθ,cosθ和抓取概率值p;
[0052]
在本实施例中,特征图经过抓取检测网络的调整结构,输出抓取矩形框参数x,y,h,w,sinθ,cosθ和抓取概率值p。
[0053]
其中调整结构包括三个二维卷积层,这三个二维卷积层依次连接,特征图经过三个二维卷积层处理后得到7
×7×
7大小的向量,该向量最后一个维度7表示通道数,第1个通道代表抓取的可能性p,剩下6个通道代表抓取矩形的参数,分别是x,y,h,w,sinθ,cosθ。
[0054]
s6:基于p,x,y,h,w,sinθ,cosθ得到目标物体的最佳抓取检测框,实现对目标物体的抓取检测;
[0055]
在本实施例中,得到最佳抓取矩形的具体过程如下:
[0056]
选择最高抓取概率值所对应的x,y,h,w作为最佳抓取矩形的中心坐标和最佳抓取矩形的高、宽;
[0057]
最佳抓取矩形的朝向角为:
[0058][0059]
获取深度图像的深度信息对所述最佳抓取矩形参数完成平面到三维的转换,获得目标物体真实位置和姿态的信息。
[0060]
下面对本发明实施例包含的抓取检测网络的训练样本、损失函数进行说明。
[0061]
本实施例中,抓取检测网络采用康奈尔大学提供的抓取数据集进行训练,该数据集包括240种物体、855张图像。在将数据集输入网络训练之前,先对康奈尔数据集进行预处理,经过对图片裁剪、旋转并缩放到网络模型需要的输入大小224
×
224,数据集被扩充了125倍,共包含110625张图像,基本满足进行下一步网络训练的要求。
[0062]
因为抓取检测网络每次预测7
×
7个抓取矩形框,因此不能在每次训练时只随机选取一个真实值,这里每次选取5个真实值作为标签,对于有的图像没有足够真实标签值就在现有的标签中重复选择。对这些对应抓取矩形框的标签值记上标记,矩形框的中心点坐标落在哪个单元格中就将该单元格的第一个通道记为1,整个第一通道的其余值记为0,形成
一个表示抓取概率的热图,值越高对应抓取的可能性越高。同时,将抓取矩形参数值x,y,h,w,sinθ,cosθ填入对应的列中,形成用于训练的7
×7×
7标签,如图3所示。然而,在建立损失函数时,并不是将这个7
×7×
7的标签值与网络输出的7
×7×
7结果进行比较,因为很多概率为0的位置对应的其他通道赋值为0,全部计算损失并回归没有意义。因此,本章选择整张7
×
7的抓取概率分布图和5个选中的标签值与网络输出中对应的部分计算均方误差作为损失函数。
[0063]
上述抓取检测网络的损失函数如下所示:
[0064][0065]
其中,l
loss
为抓取检测网络在训练时获取的损失值,s表示图像横、纵轴分成的单元格个数,b表示每张图像选取的标签值个数,p表示每个单元格预测的参数个数,pi、表示每个单元格的抓取概率标签值与预测值,c
i,j
、表示每个单元格的抓取参数标签值与预测值。
[0066]
术语“第一”、“第二”等是用于区别类似的对象,而不是用于描述或表示特定的顺序或先后次序。
[0067]
至此,已经结合附图所示的实施方式描述了本发明的技术方案,但是以上所述仅为本发明的一个实施方式,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1