前馈补偿与变阻尼建模相融合的力阻抗控制方法
1.本发明涉及机器人技术领域,具体涉及一种前馈补偿与变阻尼建模相融合的力阻抗控制方法。
背景技术:
2.机器人技术已经进入智能阶段,在制造业、交通运输、服务业等领域占有重要地位。在机器人进行打磨、去毛刺、夹持物品、精密装配、人机交互等操作时,往往需要将接触力控制在一定的期望范围。但因任务不同,刚度和位置随环境信息变化等原因,使得接触力保持良好的跟踪和动态响应指标的控制难度加大。由于大多数工业机器人具有较高的位置精度,因此机器人接触未知环境的力控制借助于位置控制,其现有的方法有:1)直接预测参考轨迹或估计环境信息。有文献由力稳态误差的必要条件和环境模型得到参考轨迹及外力的估计公式,采用lyapunov稳定性实时估计环境信息。有文献由当前位置和参考位置差值,构建参考位置自适应律,并把pid(proportion-integral-derivative)引入阻抗控制,形成新的阻抗关系。有文献将分数阶的思想引入自适应阻抗控制框架,对接触环境表现出柔顺性。有文献从环境刚度和接触位置未知两方面出发,构建阻尼系数自适应的阻抗关系,并证明该方法的稳定性。2)将智能控制技术用于阻抗系数的调整。有文献在自适应阻抗控制基础上引入模糊控制,根据力测量信息实时调整阻抗系数,提高系统动态响应能力。有文献提出模糊自适应混合阻抗控制策略,以补偿由接触环境的刚度实时变化引起的力控制误差。有文献采用神经网络补偿参考轨迹,使得最终的系统效果表现出阻抗特性。有文献引入小波神经网络在线调整阻尼项,补偿阻抗关系的未知项,提高控制系统鲁棒性。虽然已有研究从预测参考轨迹、估计环境信息、调节阻抗系数以补偿系统不确定性等角度提高力控制性能,但未综合考虑机器人与环境接触时的稳态性能以及动态特性,直接影响了力控制性能的进一步提高。
技术实现要素:
3.本发明所要解决的是现有机器人力阻抗控制中,不能有效地适应随机且未知的接触环境的动态变化,从而限制了工业机器人力控制的静、动态特性进一步提高的问题,提供一种前馈补偿与变阻尼建模相融合的力阻抗控制方法。
4.为解决上述问题,本发明是通过以下技术方案实现的:
5.前馈补偿与变阻尼建模相融合的力阻抗控制方法,包括步骤如下:
6.步骤1、通过力传感器采集机器人的接触力fe,并根据设定的期望力fr与采集的接触力fe得到力偏差δf,其中δf=f
r-fe;
7.步骤2、构建深度神经网络变阻尼模型,该深度神经网络变阻尼模型由输入层、隐含层、卷积层和输出层构成,深度神经网络变阻尼模型的输入为力偏差的绝对值|δf|,输出为阻尼系数bd;
8.步骤3、将力偏差的绝对值|δf|送入到步骤2所构建的深度神经网络变阻尼模型
中对网络参数进行学习,得到阻尼系数bd;
9.步骤4、利用机器人与环境的阻抗模型计算位置误差δx;其中机器人与环境的阻抗模型为:
[0010][0011]
步骤5、在初始参考位置x
r0
的基础上,利用前馈pi在线补偿当前参考位置xr,即:
[0012]
xr=x
r0
+k
p
δf+ki∫δfdt
[0013]
步骤6、根据步骤4所得到的位置误差δx与步骤5得到的当前参考位置xr得到机器人的位置控制量xc,其中xc=xr+δx;
[0014]
步骤7、通过位置传感器采集机器人的实际位置x,并对步骤6所得的位置控制量xc与采集的实际位置x的偏差x
c-x进行pid控制后,得到机器人的控制扭矩去对机器人进行位置控制,达到控制力的目的;
[0015]
式中,δf表示力偏差;bd表示阻尼系数,md表示质量系数,kd表示刚度系数;δx表示位置误差,和分别表示位置误差δx的一次微分和二次微分;xr表示当前参考位置,x
r0
表示初始参考位置,k
p
表示比例参数,ki表示积分参数。
[0016]
上述步骤2所构建的深度神经网络变阻尼模型为:
[0017]
输入层的输入为:
[0018]
|δf|
[0019]
隐含层的激活函数为:
[0020][0021]
卷积层的卷积结果为:
[0022][0023]
输出层的输出为:
[0024][0025]
式中,|δf|表示力偏差的绝对值;h(i)表示隐含层的第i个神经元的激活函数,ci和bi分别表示隐含层的第i个神经元激活函数的高度和宽度;aj表示卷积层第j个神经元的卷积结果,bj表示卷积层的第j个神经元的偏置;表示隐含层与卷积层的共享权值向量,h(j)表示隐含层的第j个神经元的激活函数,h(j+1)表示隐含层的第j+1个神经元的激活函数,h(j+2)表示隐含层的第j+2个神经元的激活函数;wj表示卷积层第j个神经元到输出层的权值,bd表示阻尼系数;i=1,2,
…
,i,i是隐含层神经元的个数;j=1,2,
…
,j,j是卷积层神经元的个数。
[0026]
作为改进,步骤5中,比例参数k
p
为固定值;积分参数ki为与力偏差δf呈非线性关系的自适应值,其中积分参数ki为:
[0027]
[0028]
式中,δf表示力偏差,h1表示设定的非线性函数高度,w表示设定的非线性函数宽度。
[0029]
与现有技术相比,本发明具有如下特点:
[0030]
1、引入的深度神经网络变阻尼模型,在深度神经网络变阻尼模型中,根据力误差δf与阻尼系数bd机理特性,设计隐含层的激活函数,同时卷积层利用共享权值和局部连接方式提取数据有用的特征,相较于其它神经网络权值参数更少,且能够更好地提取隐含层的数据特征,加快更新参数速度的同时,降低模型复杂度。
[0031]
2、引入pi结构的前馈控制,在线补偿参考位置量,并设计了以力偏差为自变量的非线性函数以改变积分强度,实现前馈pi补偿中积分的自适应调整,达到动态修正参考位置信息的目的。
[0032]
3.变阻尼系数的在线获取与自适应前馈pi补偿,提高力控制的静态与动态跟踪性能,减小了力控制的超调量,实现机器人的柔顺控制。
附图说明
[0033]
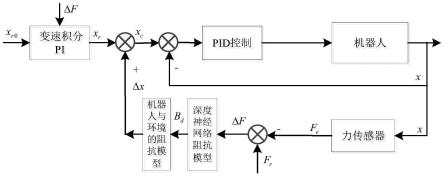
图1为本发明机器人力阻抗控制系统原理图。
[0034]
图2为隐含层的激活函数曲线图。
[0035]
图3为深度神经网络变阻尼模型的结构图。
[0036]
图4为非线性函数曲线图。
具体实施方式
[0037]
为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实例,对本发明进一步详细说明。
[0038]
基于位置的力跟踪阻抗控制是把质量-阻尼-弹簧模型等效为机器人末端与环境接触力模型,当存在力偏差时,机器人末端存在相应的位置误差,这两种误差之间的关系由该模型的阻抗系数调节,从而间接柔顺地控制接触力。
[0039]
机器人与环境的阻抗模型为:
[0040][0041]
式中,δx是位置误差,δx=x
c-xr,xc是机器人位置控制量,xr是期望力对应的参考位置,和分别是位置误差δx的一次微分和二次微分;md是已知的质量系数,bd是阻尼系数,kd是已知的刚度系数;fr是期望力,fe是接触力通过力传感器获得。
[0042]
力传感器描述:
[0043][0044]
式中,x是实际位置,xe是环境位置,ke是环境刚度。
[0045]
1)稳态性能
[0046]
令力偏差δf=f
r-fe,由已有技术可知,当系统稳定时,力偏差δf对应稳态误差e
fss
为:
[0047][0048]
为了达到稳态误差为0,则需满足如下条件:
[0049][0050]
公式(4)说明:1)精准力控制的前提是通过环境信息,实时获取准确的参考位置xr,或刚度系数kd=0。当kd=0,阻抗控制退化为阻尼控制;2)当参考位置xr为恒值,接触环境变化,不做适应调整,系统将产生较大的力偏差。
[0051]
在实际中,接触环境的信息不可精确得知,即刚度和接触面位置是未知和动态变化的,这使得xr时刻在变化,提前获取准确的xr非常困难。
[0052]
2)动态性能
[0053]
机器人与环境的阻抗模型,可知其阻尼比为:
[0054][0055]
自然频率ωn为:
[0056][0057]
由阻尼比和自然频率影响因素可知,当接触环境改变,环境刚度ke实时变化,导致阻尼比和自然频率ωn随之变化,直接影响系统动态性能。另外,因为环境刚度ke和刚度系数kd都由系统本身特性决定,人为无法调整。所以实时调节目标阻尼系数bd,可达到间接调整阻尼比,降低环境变化对系统动态性能的影响的目的。
[0058]
在位置阻抗控制框架下,本发明所提出的前馈补偿与变阻尼建模相融合的力阻抗控制方法,如图1所示,其设定值是通过自适应前馈补偿获得,位置误差δx是通过深度神经网络变阻尼模型得到阻尼比bd代入公式(1),再解公式(1)获得。
[0059]
(1)深度神经网络变阻尼模型
[0060]
在机器人力阻抗控制中,力偏差δf与阻尼系数bd的机理特性表现为:1)当力偏差δf较大时,期望阻尼系数bd变小,以期快速响应;2)当力偏差δf较小时,期望阻尼系数bd增大,降低系统超调量,以期维持稳定。为此,根据力偏差δf和阻尼系数bd机理特性,构建一个描述其特性的深度神经网络,其设计隐含层的激活函数为:
[0061][0062]
式中,h(i)是隐含层的第i个神经元的激活函数,其用于表示力偏差δf与阻尼系数bd的非线性的机理关系,h(i)如图2所示;ci和bi分别是隐含层的第i个神经元激活函数的高度和宽度;δf是力偏差,δf=f
r-fe,fr是期望力,fe是接触力。
[0063]
考虑到网络结构复杂及运算量,本发明所设计的深度神经网络变阻尼模型由输入层、隐含层、卷积层和输出层构成,如图3所示。隐含层通过激活函数h(i)来描述力偏差δf
与阻尼系数bd的关系,卷积层能够利用共享权值和局部连接方式提取数据有用的特征,其权值参数更少,有利于模型加权的快速学习。图3中,是神经网络输入变量即力偏差δf;ci是隐含层的激活函数高度,bi是隐含层的激活函数宽度,h(i)是隐含层的第i个神经元的非线性激活函数;是隐含层与卷积层的共享权值向量;zj是卷积层的第j个神经元激活函数值,aj是卷积层的第j个神经元的卷积结果;wj是卷积层第j个神经元到输出层的权值;是神经网络输出即阻尼系数bd。i=1,2,
…
,i,i是隐含层神经元的个数。j=1,2,
…
,j,j是卷积层神经元的个数。
[0064]
网络优化过程由前向传播和参数学习两部分组成,前向传播计算输出值,参数学习采用梯度下降法更新相关参数以逼近目标值。
[0065]
(1.1)网络的前向传播
[0066]
1)输入层:
[0067][0068]
2)隐含层:
[0069][0070]
3)卷积层:
[0071][0072][0073]
式中,bj是卷积层的第j个神经元的偏置。
[0074]
4)输出层:
[0075][0076]
(1.2)网络参数学习
[0077]
设性能指标函数为:
[0078][0079]
根据最速下降法分别得到神经网络各层的加权系数的更新增量公式。
[0080]
1)输出层到卷积层的权值增量:
[0081][0082]
2)隐含层到卷积层的共享权值增量:
[0083][0084]
式中:
[0085]
3)卷积层偏置增量:
[0086][0087]
4)隐含层激活函数宽度参数增量:
[0088][0089][0090][0091][0092][0093][0094]
式中:
[0095]
5)隐含层激活函数高度参数增量:
[0096][0097][0098][0099]
[0100][0101][0102]
式中:
[0103]
则在神经网络迭代过程,权系数更新公式如下
[0104]
wj(k)=wj(k-1)+δwj+α[wj(k-1)-wj(k-2)]
ꢀꢀꢀꢀ
(29)
[0105][0106]bj
(k)=bj(k-1)+δbj+α[bj(k-1)-bj(k-2)]
ꢀꢀꢀꢀꢀꢀ
(31)
[0107]bi
(k)=bi(k-1)+δbi+α[bi(k-1)-bi(k-2)]
ꢀꢀꢀꢀꢀꢀꢀꢀ
(32)
[0108]ci
(k)=ci(k-1)+δci+α[ci(k-1)-ci(k-2)]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(33)
[0109]
式中:wj(k)为当前k时刻隐含层第j个神经元到输出层的权值,为当前k时刻卷积层第m个共享权值,bj(k)为当前k时刻卷积层第j个神经元的偏置,bi(k)为当前k时刻隐含层第i个神经元的激活函数宽度,ci(k)为当前k时刻隐含层第i个神经元的激活函数高度,η为学习速率,α为动量因子。k-1为当前k时刻的前一时刻。
[0110]
(2)自适应前馈pi补偿
[0111]
在初始参考位置x
r0
处引入前馈pi在线补偿参考位置xr,通过力偏差直接调整参考位置,使力稳态误差趋近0。前馈pi补偿参考位置为:
[0112]
xr=x
r0
+k
p
(f
r-fe)+ki∫(f
r-fe)dt
ꢀꢀꢀꢀ
(34)
[0113]
式中,k
p
是比例参数,ki是积分参数。
[0114]
考虑到变化的接触环境会使得系统接触过程具有波动性,固定的比例参数k
p
和积分参数ki无法适应,因此本发明利用非线性函数f(δf)作为积分参数ki,以使得积分参数ki速度随着接触过程中受力跟踪情况作动态调整,力误差小时增大积分作用,力误差大时减弱积分作用,以期更好地适应变化的接触环境,提高控制系统稳定性。其中非线性函数f(δf)调整规则为:当力偏差较大时,应降低f(δf)以防止系统积分饱和,引起大超调;当力偏差较小时,增大f(δf)以消除稳态误差,如图4所示。根据图4中的目标曲线,设计力偏差为自变量,f(δf)为因变量的非线性函数:
[0115][0116]
式中,h1表示设定的非线性函数高度,w表示设定的非线性函数宽度。当力偏差变小,f(δf)逐渐趋近1,则积分作用变强;反之,f(δf)逐渐趋近0时,则积分作用变弱,达到动态调整ki速度的目的,更好的降低力稳态误差。
[0117]
此时自适应前馈pi补偿参考位置的阻抗控制为
[0118]
xr=x
r0
+k
p
δf+f(δf)∫δfdt
ꢀꢀꢀꢀ
(36)
[0119]
基于上述分析,本发明所提出的一种前馈补偿与变阻尼建模相融合的力阻抗控制
方法,包括步骤如下:
[0120]
步骤1、通过力传感器采集机器人的接触力fe,并根据设定的期望力fr与采集的接触力fe得到力偏差δf,其中δf=f
r-fe;
[0121]
步骤2、构建深度神经网络变阻尼模型,该深度神经网络变阻尼模型由输入层、隐含层、卷积层和输出层构成,该深度神经网络变阻尼模型的输入为力偏差的绝对值|δf|,输出为阻尼系数bd;
[0122]
输入层的输入为:
[0123]
|δf|
[0124]
隐含层的激活函数为:
[0125][0126]
卷积层的卷积结果为:
[0127][0128]
输出层的输出为:
[0129][0130]
步骤3、将力偏差的绝对值|δf|送入到步骤2所构建的深度神经网络变阻尼模型中对网络参数进行学习,得到阻尼系数bd;
[0131]
步骤4、利用机器人与环境的阻抗模型计算位置误差δx;其中机器人与环境的阻抗模型为:
[0132][0133]
步骤5、在初始参考位置x
r0
的基础上,利用自适应前馈pi在线补偿当前参考位置xr,即:
[0134]
xr=x
r0
+k
p
δf+ki∫δfdt
[0135]
步骤6、根据步骤4所得到的位置误差δx与步骤5得到的当前参考位置xr得到机器人的位置控制量xc,其中xc=xr+δx;
[0136]
步骤7、通过位置传感器采集机器人的实际位置x,并对步骤6所得的位置控制量xc与采集的实际位置x的偏差x
c-x进行pid控制后,得到机器人的控制扭矩去对机器人进行位置控制,达到控制力的目的;
[0137]
式中,|δf|表示力偏差的绝对值;h(i)表示隐含层的第i个神经元的激活函数,ci和bi分别表示隐含层的第i个神经元激活函数的高度和宽度;aj表示卷积层第j个神经元的卷积结果,bj表示卷积层的第j个神经元的偏置;表示隐含层与卷积层的共享权值向量,h(j)表示隐含层的第j个神经元的激活函数,h(j+1)表示隐含层的第j+1个神经元的激活函数,h(j+2)表示隐含层的第j+2个神经元的激活函数;wj表示卷积层第j个神经元到输出层的权值,bd表示阻尼系数;i=1,2,
…
,i,i是隐含层神经元的个数;j=1,2,
…
,j,j是卷积层神经元的个数;δf表示力偏差;md表示质量系数,kd表示刚度系数;δx表
示位置误差,和分别表示位置误差δx的一次微分和二次微分;xr表示当前参考位置,x
r0
表示初始参考位置,k
p
表示设定的比例参数,为设定的固定值。ki表示设定的积分参数,可以为设定的固定值,也可以为与力偏差δf呈非线性关系的自适应值,即h1表示设定的非线性函数高度,w表示设定的非线性函数宽度。
[0138]
本发明在位置阻抗控制框架下,基于自适应前馈pi补偿与深度神经网络变阻尼模型融合的工业机器人力阻抗控制方法。其中自适应pi控制通过前馈控制,有效补偿参考位置信息,降低力稳态误差;深度神经网络变阻尼模型在线实时调整阻尼系数,以动态适应未知的接触环境,实现接触力的有效控制。
[0139]
需要说明的是,尽管以上本发明所述的实施例是说明性的,但这并非是对本发明的限制,因此本发明并不局限于上述具体实施方式中。在不脱离本发明原理的情况下,凡是本领域技术人员在本发明的启示下获得的其它实施方式,均视为在本发明的保护之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1