一种基于视听问答的机器人及其控制方法与流程
本发明涉及机器人,特别涉及一种基于视听问答的机器人及其控制方法。
背景技术:
1、近年来,在机器人环境感知领域的研究中,在声音对象感知、视觉场景解析和内容描述等方面取得了显著进展,尽管这些方法能将视觉对象与声音关联,但它们中的大多数在复杂视听场景下的跨模态推理能力仍然有限。
2、因此,人类可以充分利用多模态场景中的上下文内容和时间信息来解决复杂的场景推理任务,如视听问答任务等。
3、本专利拟在机器人整合视觉和声音的多模态信息,将视听问答(audio-visualquestion answering,avqa)应用于机器人,通过回答有关不同视觉对象、声音及其在视频中的关联的问题,并将相应信息转化为运动控制信号反馈给机器人控制系统,从而大幅提升机器人对场景的感知和理解能力。
技术实现思路
1、本发明的目的在于提供一种基于视听问答的机器人及其控制方法,能够大幅提升机器人对场景的感知和理解能力。
2、为了达到上述目的,本发明提供以下技术方案:
3、一种基于视听问答的机器人控制方法,包括以下步骤:
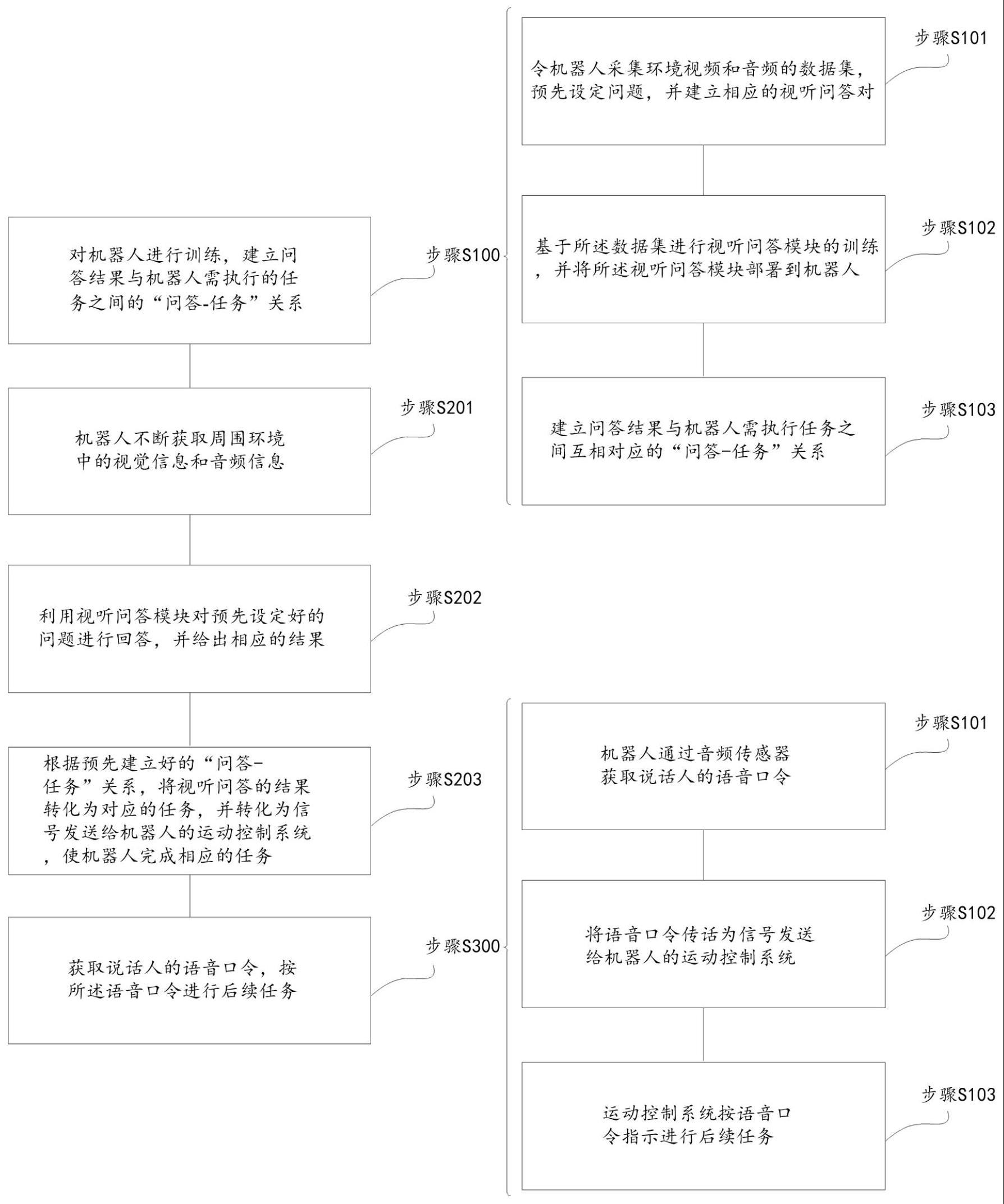
4、步骤s100:对机器人进行训练,建立问答结果与机器人需执行的任务之间的“问答-任务”关系;
5、步骤s201:机器人不断获取周围环境中的视觉信息和音频信息;
6、步骤s202:利用视听问答模块对预先设定好的问题进行回答,并给出相应的结果;
7、步骤s203:根据预先建立好的“问答-任务”关系,将视听问答的结果转化为对应的任务,并转化为信号发送给机器人的运动控制系统,使机器人完成相应的任务。
8、这种控制方法,充分利用环境中的视觉和声音信息,多模态信息提高了机器人对周围环境的理解和感知能力,同时增强了机器人的鲁棒性;视听问答可以回答视觉对象、声音及其在视频中关联关系的问题,从而赋予了机器人更为灵活的交互能力。
9、可选地,步骤s100具体包括:
10、步骤s101:令机器人采集环境视频和音频的数据集,预先设定问题,并建立相应的视听问答对;
11、步骤s102:基于数据集进行视听问答模块的训练,并将视听问答模块部署到机器人;
12、步骤s103:建立问答结果与机器人需执行任务之间互相对应的“问答-任务”关系。
13、可选地,在步骤s101中,采集环境视频和音频的数据集包括:在机器人设置声音传感器以及视觉传感器,通过声音传感器采集环境的音频数据、通过视觉传感器采集环境的视频数据。
14、可选地,在步骤s101中,预先设定问题包括:此声音是否由a发出;视频中一共有多少人在说话;说话的人在视频中的什么位置。
15、可选地,在步骤s103中,机器人需执行任务包括:将说话人在视频中的位置换算成实际位置,并移动至说话人的位置。
16、可选地,控制方法还包括:步骤s300:获取说话人的语音口令,按语音口令进行后续任务。
17、可选地,步骤s300具体包括:
18、步骤s301,机器人通过音频传感器获取说话人的语音口令;
19、步骤s302,将语音口令传话为信号发送给机器人的运动控制系统;
20、步骤s303,运动控制系统按语音口令指示进行后续任务。
21、可选地,语音口令包括:去自主充电。
22、可选地,语音口令包括:将a货物搬运到x地点。
23、一种基于视听问答的机器人,适用于上述的任一种基于视听问答的机器人控制方法,包括:声音传感器、视觉传感器、视听问答模块、音频传感器以及运动控制系统。
技术特征:
1.一种基于视听问答的机器人控制方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于视听问答的机器人控制方法,其特征在于,步骤s100具体包括:
3.根据权利要求2所述的基于视听问答的机器人控制方法,其特征在于,在步骤s101中,所述采集环境视频和音频的数据集包括:
4.根据权利要求2所述的基于视听问答的机器人控制方法,其特征在于,在步骤s101中,所述预先设定问题包括:
5.根据权利要求4所述的基于视听问答的机器人控制方法,其特征在于,在步骤s103中,所述机器人需执行任务包括:
6.根据权利要求5所述的基于视听问答的机器人控制方法,其特征在于,所述控制方法还包括:
7.根据权利要求6所述的基于视听问答的机器人控制方法,其特征在于,步骤s300具体包括:
8.根据权利要求7所述的基于视听问答的机器人控制方法,其特征在于,所述语音口令包括:
9.根据权利要求7所述的基于视听问答的机器人控制方法,其特征在于,所述语音口令包括:
10.一种基于视听问答的机器人,其特征在于,适用于如权利要求1-9任一项所述的基于视听问答的机器人控制方法,包括:
技术总结
本发明涉及机器人技术领域,公开了一种基于视听问答的机器人及其控制方法,该方法包括:对机器人进行训练,建立问答结果与机器人需执行的任务之间的“问答‑任务”关系;机器人不断获取周围环境中的视觉信息和音频信息;利用视听问答模块对预先设定好的问题进行回答,并给出相应的结果;根据预先建立好的“问答‑任务”关系,将视听问答的结果转化为对应的任务,并转化为信号发送给机器人的运动控制系统,使机器人完成相应的任务。该方法充分利用环境中的视觉和声音信息,提高了机器人对周围环境的理解和感知能力,同时增强了机器人的鲁棒性;视听问答可以回答视觉对象、声音及其在视频中关联关系的问题,从而赋予了机器人更为灵活的交互能力。
技术研发人员:侯晓楠,王春雷,詹明昊
受保护的技术使用者:上海微电机研究所(中国电子科技集团公司第二十一研究所)
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!