一种基于动态交互表征的灵巧机械手抓取方法
本发明属于机械手智能抓取应用,具体涉及一种基于动态交互表征的灵巧机械手抓取方法。
背景技术:
1、在机器人操作任务中,从域内数据学习表征往往很难泛化到未见过环境和任务中,但是使用大规模数据训练出来的大模型学习到的表征具备很强的泛化能力。有学者探究了使用大量域外的人类操作数据预训练一个具备大量人类操作知识的模型,用该模型学到的表征知识指导下游机器人任务。这些模型通常在大规模的真实世界图像数据集上进行训练,因此具有广泛的语义和特征理解。
2、然而,目前大部分研究关注如何训练更好的预训练模型本身,比如使用掩码自编码器(mae)、使用规模更大的数据集进行预训练,或者将语言集成到模型中。在将预训练模型应用于机器人学习的下游任务时,以前的研究主要使用整个图像的全局视觉表征而没有更深入地探索更有效的表征方式,因此应用于机器人灵巧操作任务效果并不理想。为了更好地利用预训练模型的表征能力,本文提出一种基于动态交互表征的灵巧机械手抓取方法。
技术实现思路
1、本发明目的在于提供一种基于动态交互表征的灵巧机械手抓取方法,将机械手与物体交互过程中的动态交互信息融入到预训练模型的表征中以提高下游抓取任务的成功率泛化性。为实现该目的,本发明的具体技术方案如下:
2、所述的一种基于动态交互表征的灵巧机械手抓取方法,包括以下步骤:
3、s1.动态交互表征提取:从预训练模型中提取抓取过程中的局部动态交互表征作为策略网络输入;
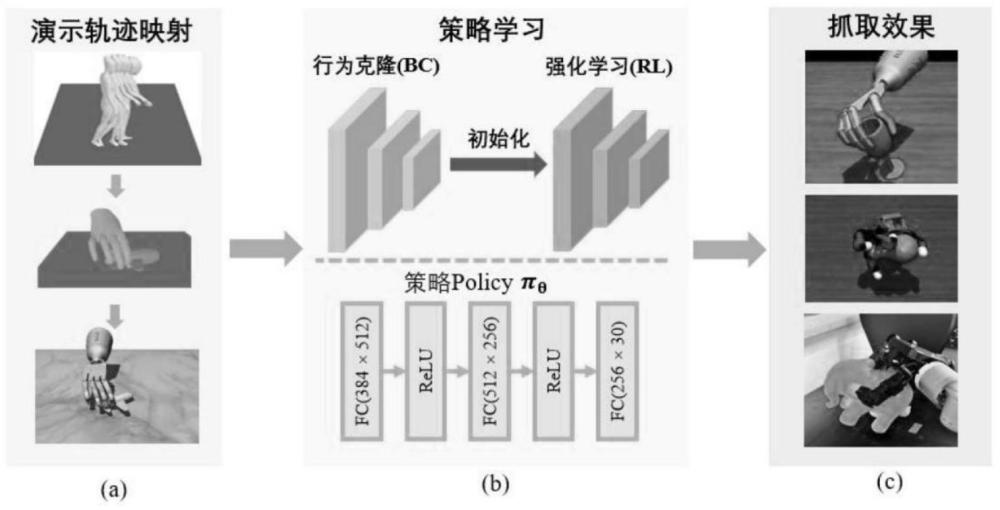
4、s2.人手演示轨迹到机械手演示轨迹的重映射:收集人手抓取物体的演示轨迹,通过优化将人手轨迹映射成机械手轨迹;
5、s3.基于动态交互表征的学习策略:采用行为克隆初始化-强化学习微调的两阶段学习策略加速强化学习训练,将映射后得到的机械手的轨迹作为行为克隆的训练数据,结合步骤s1得到的表征预训练一个策略网络,用该策略网络的参数初始化后续强化学习策略网络的参数,并利用融合演示的强化学习算法在仿真中训练抓取策略;
6、s4.实物机器人验证平台:搭建实物抓取平台,将仿真中训练得到的抓取策略部署到抓取平台生成灵巧抓取轨迹,控制机械手进行物体抓取。
7、进一步地,所述步骤s1中动态交互表征提取包括两个部分:
8、第一部分:物体区域分割,利用视觉模型从整个图像中分割出物体和机械手;
9、第二部分:局部动态交互表征计算,将任务场景图片输入使用大量人手操作视频预训练好的掩码自编码器,通过选择物体上最接近机械手区域的像素点的局部特征,集成动态交互信息。
10、进一步地,所述第一部分中物体区域分割的具体流程为:
11、首先,渲染场景的初始帧i0,并利用语义分割模型sam模型通过点提示来分割物体;
12、然后,sam预测的掩模被输入到掩膜追踪模型xmem模型中,在强化学习训练过程中逐步跟踪掩模的变化;
13、最终,每一帧的物体掩模mo被提取如下:
14、
15、进一步地,所述第二部分中局部动态交互表征计算的具体步骤如下:
16、r1.用获取物体掩膜同样的方法获取机械手的掩膜mr,并从中采样m个像素,在mo中采样n个像素,然后分别记录所选像素在原始图像中的坐标,记为pr和po;
17、r2.计算了pr和po之间的距离,并选择距离手最近的物体像素,记为po*:
18、po*=argmin(||po,pr||2),
19、r3.计算了这些像素po*在整个图像中所属的k个补丁索引:通过预训练编码器e提取图像特征f,通过从f中提取与这k个补丁相对应的特征并计算它们的平均值,得到局部交互特征
20、r4.当某一帧中没有机器手或物体出现时,使用该帧的全局特征。
21、进一步地,所述步骤s2中人手演示轨迹到机械手演示轨迹的重映射包括以下内容:
22、s21.处理人手演示轨迹,定义了人类抓握演示:其中第i个演示是第t步人类手部全局姿态gt、关节姿态qt和物体6d姿态ot的集合;
23、s22.优化机械手关节角,优化目标函数定义为:
24、
25、其中,和是通过正向运动学计算出的关节角度,和分别表示机械手和人手在第t步中的手指到手指向量、手指到手腕向量和手指到物体向量,ki是机械手和人手之间每个向量的比例系数,mg是附着在机械手上的手臂的全局平移和旋转;
26、s23.利用相关性扰动微调动作,具体如下:
27、首先,对于优化后的手臂全局动作在初始时刻t0增加扰动:
28、
29、
30、其中,c1=0.1,pmax=0.1,pmin=-0.1;
31、然后,对于手指关节动作在末尾时刻t增加扰动:
32、
33、其中,c2为常数,实验中设置为1,初始时刻到末尾时刻之间对动作进行插值;a为微调后的动作,在mujoco仿真器中执行微调后的动作序列,收集由状态-动作对(s,a)组成的机械手演示该演示用于下一阶段的行为克隆。
34、进一步地,所述步骤s3中行为克隆阶段和强化学习阶段的策略网络结构一致,策略学习阶段先使用行为克隆初始化抓取策略,并采用强化学习进行策略微调;策略网络是一个三层感知机,其输入包括手物交互表征和机械手本体状态,输出为机械手各个关节的控制量。
35、进一步地,针对行为克隆阶段,其损失函数为:
36、
37、其中,是演示数据,θ是行为克隆策略网络要优化的参数;对策略网络预测的输出数据进行反标准化处理。
38、进一步地,针对强化学习阶段,将演示引入强化学习训练中,添加额外的项计算梯度更好地辅助网络学习:
39、
40、其中,ρπ是由策略πθ采样的数据,是收集到的演示,是优势函数,λ0=0.1和λ1=0.95是超参数,k是迭代计数器;采用gae作为优势函数并设置奖励函数为:r=αrdis+βrlift+γrsucc,,其中,rdis是接近奖励,激励手部接近物体;rlift是抬高奖励,激励手抓起物体;rsucc是成功奖励。
41、进一步地,所述步骤s4中实物机器人验证平台包括视觉感知和控制执行两个部分:
42、视觉感知部分采用一个kinect azure相机感知操作对象的位置信息,拍摄物体后通过图像分割得到物体的部分点云,并与物体的cad模型匹配,拟合出物体的空间位姿;
43、控制执行部分执行策略网络预测的机械手抓取轨迹,规划路径,协同控制机械臂和机械手运动。
44、与现有技术相比,本发明有以下优点:
45、(1)本方法仅借助二维图像信息就能够实现多种物体的高效灵巧抓取,相较于现有的机械手抓取物体的方法输入表征大多需要利用物体三维点云信息,抓取策略在新物体上更具有泛化性,以及适用不同场景;
46、(2)本方法从预训练的表征中进一步提取机械手操作过程中的动态交互表征,可在原有预训练模型输出表征的基础上大幅度提高抓取成功率和泛化性,不需要消耗资源重新预训练新模型;
47、(3)本方法能够在40多个不同种类的物体上实现高效抓取且训练好的抓取策略能够很好地泛化到未见过的新物体,不仅能够适用于不同机械爪型包括五指、四指和夹爪,还能够应用于不同任务类型,包括抓取和开抽屉等,同时可以很好地迁移到实际机器人上。
- 还没有人留言评论。精彩留言会获得点赞!