分析受试者的方法和系统与流程
本申请案与2014年6月23日公告并共有的美国专利临时申请号第62/015,555号「分析受试者的方法和系统」有关,并主张优先权。本发明于此所列的参考文献均引用作为本说明书的揭示内容。
技术领域
本发明涉及分析受试者并为面试评分的方法和系统。
背景技术:
员工透过亲自或通电话的方式面试无数的受试者。由于现职员工和企业主都必须放下手边工作以进行面试,因此这个过程所需的间接成本相当高。此外,使用传统的表格进行面谈,常导致聘雇不佳的结果,造成公司得花钱重新面试、重新雇用,并训练受雇员工。
技术实现要素:
本发明实施例的目的在于提供一种用计算机评估受试者的方法,该受试者可为访客、受试者等。该方法包含提供一以预录方式传送的通讯网络(如因特网、行动网络、广域网(wide area network,WAN)、区域网络(local area network,LAN),以及这些网络组合)到与受试者相关联的显示设备;提供至少一个将声音和影像整合在一起的陈述给受试者;同时将受试者响应陈述的声音和影像记录下来;分析声音和影像,以获得受试者的至少一项特质;以及根据该至少一项特质的分析结果,对受试者进行评价。
选择性地,该至少一个陈述包含至少一个预录面试问题,由看得见的面试人员录制,并使用于和受试者面试时。
选择性地,该至少一个预录面试问题包含数个预录面试问题,由看得见的面试人员录制。
选择性地,该数个预录面试问题由一张清单定义,且包含数个类型。进行面试前,根据所面试的职位选择面试问题。
选择性地,该预录面试问题的顺序按照前一个面试问题的答案的分析结果呈现;该答案包含声音和影像。
选择性地,该预录面试问题的呈现,按照前一个面试问题的答案的分析结果终止;该答案包含声音和影像。
选择性地,该预录面试问题的呈现或终止可实时进行。
选择性地,可当场分析受试者回答问题时的声音和影像,以获得受试者的至少一项特质。
选择性地,受试者的评价以至少以下其中一种方式呈现:受试者身为受试者的分数,以及推荐/不推荐受试者担任其所面试的职位。
选择性地,与受试者相关联的显示设备包含一屏幕、一摄影机,以及一麦克风。该屏幕连接到通讯网络。该摄影机用于记录受试者的影像。该麦克风用于记录受试者的声音。
本发明实施例旨在提供一系统,用于评价受试者(如计算机访客、受试者等)。该系统包含一第一存储介质、一处理器,以及一第二存储介质。第一存储介质用于存储至少一职位的面试,包含数个预录问题。该数个预录问题同时具有声音和影像,透过通讯网络传送到受试者的该显示与声音及影像纪录装置上。第二存储介质与处理器通联,用于存储处理器所执行的指令。这些指令包含:将同时具有声音和影像的预录问题,经由通讯网络传送到受试者的该显示与声音及影像纪录装置上;同时记录受试者回答预录问题时的声音和影像;分析声音和影像以获得受试者的至少一项特质;以及根据该至少一项特质的分析结果,对受试者进行评价。
本发明实施例旨在提供一计算机可用非暂时性存储介质。该计算机可用非暂时性存储介质内建一计算机程序,以便能以一合适的程序系统对受试者进行评价。这类计算机程序在系统中运作时需执行以下步骤。这些步骤包含:从存储介质中获取至少一职位的至少一预录面试,且该至少一预录面试包含将数个具有声音和影像的预录问题经由一通讯网络,传送到受试者的显示设备与声音和影像纪录器上;将具有声音和影像的预录问题经由通讯网络传送到受试者的显示设备与声音和影像纪录器上,让受试者知道;同时记录受试者回答预录问题时的声音和影像;分析声音和影像以获得受试者的至少一项特质;以及根据该至少一项特质的分析结果,提出受试者的评价结果。
本发明其他实施例旨在提供一个面试受试者的方法。该方法包含:获得数个同时具有声音和影像格式的预录问题,整合成一声音影像后,透过连接通讯网络的装置提供给受试者;透过该装置提供数个预录问题的第一个问题给受试者;至少分析受试者答完第一个问题的声音并利用连接通讯网络的装置收录;根据该分析,执行以下其中一种方式任务:提供其余数个预录问题的下一个问题给受试者,或者终止提供预录问题给受试者。
选择性地,该分析包含进一步至少分析受试者作答的声音,并根据该进一步分析,决定要将其余数个预录问题中的哪一个问题提供给受试者。
选择性地,该分析包含进一步至少分析受试者作答的声音,并根据该进一步分析,决定是否终止将预录问题提供给受试者。
选择性地,该进一步分析包含分析受试者所回答的预录问题的上下文。
选择性地,将数个预录问题的第一个问题透过装置提供给受试者,以及至少分析受试者答完第一个问题的声音并利用连接通讯网络的装置收录,这两个动作可实时进行。
选择性地,受试者所使用的装置为一部计算机。该计算机包含一连接通讯网络的屏幕、一摄影机及一麦克风。
本发明其他实施例旨在提供一个评价受试者的系统。该系统包含:该系统包含一第一存储介质、一处理器,以及一第二存储介质。第一存储介质用于存储至少一职位面试,包含数个预录问题。该数个预录问题同时具有声音和影像,整合成一声音影像后,透过通讯网络传送到受试者的该显示与声音及影像纪录装置上。第二存储介质与处理器通联,用于存储处理器所执行的指令。这些指令包含:透过该装置提供数个预录问题的第一个问题给受试者;至少分析受试者答完第一个问题的声音并利用连接通讯网络的装置收录;根据该分析,执行以下其中一种方式任务:将其余数个预录问题的下一个问题提供给受试者,或者终止提供预录问题给受试者。选择性地,该指令还包含:至少分析受试者作答的声音,并根据该进一步分析,决定要将其余数个预录问题中的哪一个问题提供给受试者。
选择性地,该指令还包含:至少分析受试者作答的声音,并根据该进一步分析,决定是否终止将预录问题提供给受试者。
选择性地,该进一步分析包含分析受试者所回答的预录问题的上下文。
本发明实施例旨在提供一计算机可用非暂时性存储介质。该计算机可用非暂时性存储介质内建一计算机程序,以便能以一合适的程序系统对受试者进行评价。这类计算机程序在系统中运作时需执行以下步骤。这些步骤包含:获得数个同时具有声音和影像格式的预录问题,整合成一声音影像后,透过连接一通讯网络的装置,提供该数个预录问题给一受试者;透过该装置提供数个预录问题的第一个问题给受试者;至少分析受试者答完第一个问题的声音并利用连接通讯网络的装置收录;根据该分析,执行以下其中一种方式任务:提供其余数个预录问题的下一个问题给受试者,或者终止提供预录问题给受试者。
本文件在这里使用一致或可互换使用的用语或说法。这些用语或说法可能有其他说法或变化,如下所示。
在本文件中,「网站」(web site)是关于全球信息网(World Wide Web)档案的集合。这些档案包含一开启档或称为「主页」的网页,以及典型的其他档案或「网页」。「网站」这个说法总共包含「网站」和「网页」。
档案都有一个独一无二的统一资源定位符(uniform resource locator,URL),例如「网站」和「网页」,可透过网络(包含因特网)汲取。
一部「计算机」包含装置、计算机和计算或计算机系统(如物理上分离的地区和装置)、服务器、计算机和计算装置、处理器、处理系统、计算核心(如共享装置),以及类似系统、工作站、模块及上述组合。该上述「计算机」可具有各种型态,如个人计算机(如笔记本电脑、桌面计算机、平板计算机等),或是任何类型的计算装置,包含可轻易从一地移动到另一地的携带型装置(如智能型手机、个人数字助理、移动电话等)
一服务器通常是一远程计算机或远程计算机系统,或为本文中的计算机程序。该服务器与上述对于「计算机」的定义一致,可经由通讯介质汲取,如通讯网络或其他计算机网络(包含因特网)。一「服务器」在相同或不同计算机中对其他计算机程序(和其访客)提供服务或执行功能。一服务器也可包含一虚拟设备及仿真计算机的软件。
一「应用程序」包含可执行软件,并弹性包含任何图形访客接口(graphical user interfaces,GUI)。某些功能可此软件执行。
一「客户」是一个在计算机、工作站等上运作的应用程序,并依赖一服务器执行部分操作或功能。
除非本文另有定义,否则本文所有技术及/或科学用语或说法都和该技术领域具有通常技术者所认知的意思相同。
虽然类似或相当于本文所述的方法和材料可用于本发明实施例的施行或测试中,例示性方法及/或材料的说明如下。为了避免分歧,本专利说明书连同定义都会加以控制。此外,材料、方法、范例仅用于解释,并不表示必备。
图式简单说明
以下参考附图详述一些本发明实施例,仅作为范例。特定附图会详细介绍,但要强调的是,本发明实施例的特点藉由范例呈现出来,并以图示方便讨论。在此一方面,说明及相关附图让该技术领域具有通常技术者容易明了并落实。
请将注意力转到图上。相似的参考编号或字母符号表示对应或相似的组件。在图上:
图1A及图1B绘示提供给系统的示范性环境,本发明实施例所揭示的主要内容在该环境中进行。
图2A绘示图1A及图1B中的首页服务器与系统的架构。
图2B绘示图2A中的口语分析引擎。
图2C绘示图2A中的非口语分析引擎。
图2D绘示图2A中的声音分析引擎。
图3根据本发明实施例所揭示的主要内容绘示流程图。
图4A绘示图3中方块304的流程图。
图4B绘示图3中方块308的流程图。以及
图5根据本发明实施例之一装置学习系统所执行的示范性过程及评分模块绘示流程图。
流量图的惩罚性程序由装置学习系统及评分模块符合有形的发明。
表1(2页)接续在图之后。
具体实施方式
在详细解说本发明的至少一个实施例之前,应了解本发明在应用上未必受限于结构的细节及组件的排列,及/或下列说明中详细介绍的方法,及/或图示上所绘的内容。本发明可应用在其他实施例,或以各种方式实施或进行,涵盖各式企业的各种商业应用程序。
正如同该技术领域具有通常技术者都会了解,本发明可以落实在一系统、一方法或一计算机程序产品上。因此,本发明的实施例可为全然硬件、全然软件(包含韧体、常驻软件、微码等),或者结合软件及硬件,在此可衍生称为「电路」、「模块」或「系统」。此外,本发明可应用在一种计算机程序产品中。该计算机程序产品内建一或数个非暂时性计算机可读取(存储)介质,而该介质则内建计算机可读取程序代码。
在本文件中,许多文字及图表的参照标记为商标和域名。这些商标和域名是其各自拥有者的财产,在这里仅做参照说明之用。
本发明利用自然语言处理(natural language processing,NLP)技术、语音识别技术、语意分析技术、空间(非口语)人类生物辨识分析的科学与技术,来进行受试者的面试,并根据受试者在面试中的多个特质,提供受试者表现的分析结果与分数。本发明提供一种自动互动通讯系统、方法与软件应用程序,一般人可藉此交谈、互动并进行对话,同时搭配数个默认录制影像。关于个人提供及系统分析的情境输入,这些默认录制影像使用人声语音作为其主要输入来源,并且透过声音-影像录像,该系统会输出智能型定时、同步并编纂自然类人类回应。
本发明的部分实施例包含一多维引擎、方法和系统,可以让人类和计算机进行交流,进行以智慧内容为本的对话模拟,也就是个人(访客或受试者)及一或数个预录的(面试官)影像。本发明主要使用于(但不限于)高度互动及全自动化工作面试仿真。本发明的实施例提供多种应用程序。
举例来说,本发明实施例根据系统分析的各种口语和非口语(空间)生物辨识输入,除了让个人(求职者,如受试者)接受综合表现分析和评比/分数外,还提供个人演练工作面试技巧以提升能力并使用系统的自动面试平台。
另外,举例来说,根据系统产生的综合口语和非口语应征表现分析(评比/分数),并根据系统运作的其他所有分析工具与方法进行,本发明可以让专业组织(私人/上市公司/公司/企业/招募人员)利用此平台让求职者进行全自动化工作面试(远程和实况皆可),以协助招募人员决定该职务最适合哪位求职者。
另外,举例来说,根据系统产生的综合口语和非口语应征表现分析(评比/分数),并根据系统运作的其他所有分析工具与方法进行,本发明可以让专业组织(私人/上市公司/公司/企业/招募人员)利用此平台让求职者进行实况远程视频会议的工作面试,以协助招募人员决定该职务最适合哪位求职者。
该系统与方法根据软件应用程序,可采以网页/浏览器为本及/或个人计算机/平板计算机/手机客户的方式运作。这可使本发明的系统的访客透过先进的在线及脱机技术平台选项,即透过个人计算机、笔记本电脑或行动装置(平板计算机或掌上型/智能型手机)上以网站为本的浏览器,存取系统数据,并透过在先进的操作系统上执行、以行动客户为本的应用程序执行,例如的iOS、Android或
系统可能会使用第三方网站(提供应用程序编程接口(application programming interface,API)者,例如Linkedin、Google+、Twitter等,提供登入机制与账户认证验证。这些第三方网站也可用来撷取受试者的数据,并将这些信息整合在系统内,以产生访客的简介或在任何系统引擎中进行评分。系统引擎用于分析并提供受试者(受试者)表现的评分结果。
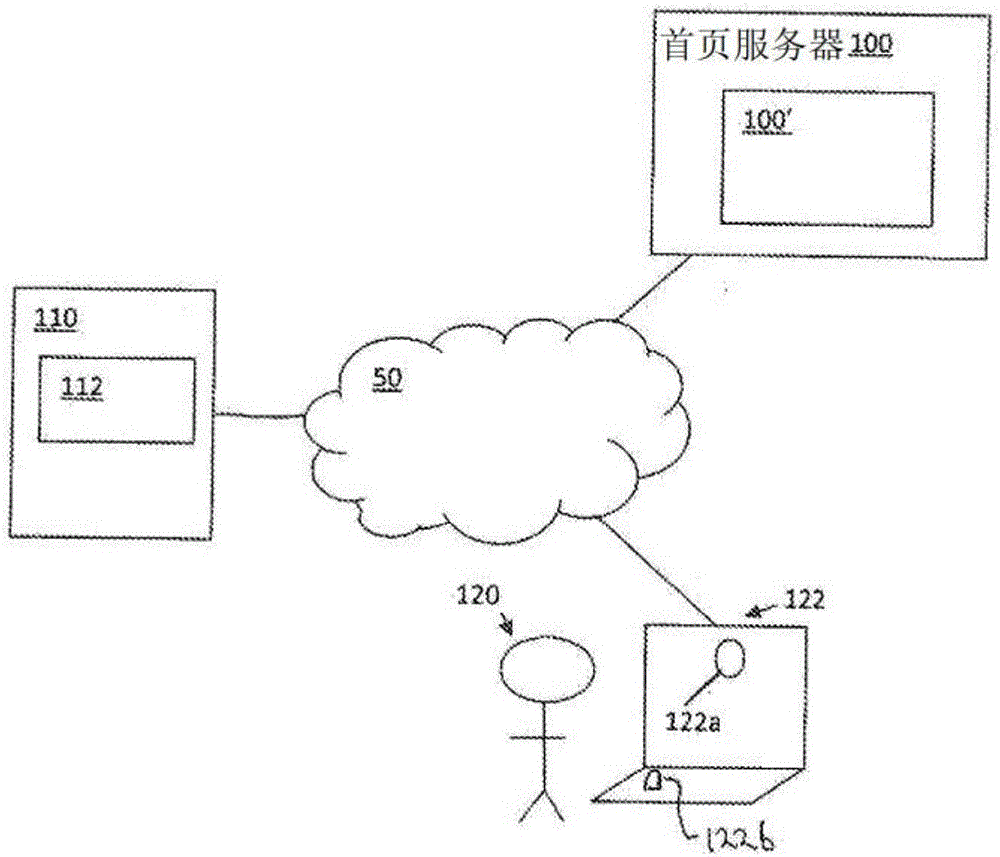
请参考图1A。图1A显示一个自动化面试的范例性作业环境。该作业环境包含一连接首页服务器100(也称为主服务器)的网络50。首页服务器100也对系统100’进行定义,无论只有系统100’本身或连同其他计算机(包含服务器、组件和应用程序,其中应用程序可为与首页服务器100相关的客户应用程序),下面会详述。网络50是通讯网络(如局域网络或广域网,其中广域网包含像因特网等的公共网络)之类。如图1A所示,单一网络可能是一种结合网络及/或多重网络包含像是移动电话网络。「连结」在此处包含直接或间接的有线及无线的链接,并将计算机(包含服务器、组件之类)放置在电子及/或数据通讯中。
各种服务器链接到网络50,并包含云端服务器110等。交互式应用程序112(即所谓的人资管理应用程序)存储在云端服务器110中。应用程序112可为系统100’的一部分。
访客或受试者120经由其计算机122也会连到网络50。利用电话(如移动电话)或透过数据、计算机(如桌面计算机、笔记本电脑、平板计算机、等)等连接到网络50。访客120的计算机122包含像摄影机122a及麦克风122b。
图1B绘示本发明提供给实况受试者的替代环境。这个替代环境与图1A绘示的环境相同。唯一不同的是图1B中有一位面试官140并配有一部计算机142。访客120配有一部计算机122。面试官140与访客120都透过计算机进行实况面试。面试官140的计算机142也包含一台摄影机142a、一个麦克风142b等。
首页服务器(home server,HS)100这个架构包含一或数个组件、引擎、模块等,用于提供许多额外的服务器功能与运作,并用于执行本发明的系统100’的作业流程。首页服务器100可能会连接额外的存储空间、内存、高速缓存及数据库的内部和外部。为了说明功能,首页伺服100可能具有一个统一资源定位符(uniform resource locator,URL),例如www.hs.com.。当单独一个首页服务器100显示时,首页服务器100可能会由数个服务器、计算机及/或组件组成。
现在将注意力转到图2A,图2A绘示系统100’的架构,例如首页服务器100。该系统架构100'包含一中央处理器202,该中央处理器202由一或多个电性连接的处理器组成。该处理器包含电子及/或数据通讯与存储器/内存204。中央处理器202和/或数据也可电性传送到引擎,包含像口语分析引擎210、非口语分析引擎212、声音分析/语调引擎214、互动引擎216等。每个引擎210、212、214、216与一或多个应用程序编程接口(application programming interface,API)210x、212x、214x、216x进行电子和/或数据通讯。存储介质,包含数据库及/或数据,也可以电性连接到中央处理器202,并且包含存储访客(受试者)的输入220、讲稿222,以及各种职位的各种面试者(例如工作或受雇)的面试录像视像224。也有机器学习组件-一机器学习系统230和一机器学习评分模块232。上述系统100’的所有组件和/或数据彼此进行直接或间接的电性通讯。这也是真实的人力资源管理。交互式应用程序112与上述系统100’的所有组件都在云端服务器110中。
人资管理112(例如在云端服务器110中)存储像公司(正在进行面试)数据、受试者(访客或受试者)数据、受试者简介(例如从网页、社交介质等取得)、客户(例如公司)账户细节、面试影片、对受试者的回馈与意见等。
存储介质220也适合存储像对受试者(以及面试官,例如在实况面试等一些情况下)所做的语音到文字交谈纪录、分析、受试者的简介及公司信息。
中央处理器(central processing unit,CPU)202由一或数个处理器组成,包含微处理器。微处理器用于执行这里所详述的首页服务器100和系统100’的功能和操作。这些功能和操作包含控制引擎210、212、214、216、存储介质220、222、224及机器学习组件230、232。该处理器(例如传统的处理器)为使用于服务器、计算机和其他计算装置。例如处理器可能包含超威(AMD)和英特尔(Intel)、的x86处理器与英特尔(Intel)的奔腾处理器,以及两者的任何组合。
存储/内存204可为任何传统存储介质。存储/内存204存储中央处理器(central processing unit,CPU)202执行的机器可执行指令,以执行本发明的流程。存储/内存204也包含与组件执行有关的机器可执行指令,包含引擎210、212、214、216及存储介质220、222、224。应用程序编程接口210、通讯模块212、讯息管理模块214、数据库216、应用程序220,以及于图3和图4中所有执行该流程的指令。存储/内存204也存储系统100’和首页服务器100的规则和方针。虽然中央处理器202的处理器和存储/内存204做为用于代表性用途的单一组件,但可能会有数个组件,并可能独立于家庭服务器100和/或系统100’之外,并连到网络50。
口语分析引擎210
口语分析引擎210的功能是例如,(透过说话到文字)分析和解释所有的人类口语输入,如访客(如受试者)提供的口语输入并个别评价该输入,以提供访客在面试的口语分析部分的表现分数。口语分析引擎分析重要口语度量的各类清单。该重要口语度量用于决定(总面试分数的)口语分析分数。有需要时,该口语分析分数只做为整体面试分数。或者,在某些情况下,访客(受试者)为说障或听障人士,口语分析引擎210的分数可以完全不采计,只采计非口语参数的分数。另外,口语分析引擎210的分数和至少一个其他引擎212、214的分数合并后可加权。举例来说,此加权可能出现在一特定参数的关键因素优于其他因素时。
口语分析引擎210包含应用程序编程接口210x。面试时应用程序编程接口210x会在一开始就从存储器220内的面试声音档案中,将存储的语音(声音)进行转换,例如在自动面试时的第一位受试者,及在实况面试的面试者。该应用程序编程接口201,以自然语言处理(natural language processing,NLP)、其他语音识别技术及文字分析方法,将语音转化成文字,透过至少一个应用程序编程接口,如网页语音识别应用程序编程接口(web speech recognition API)、细微龙自然说话(Nuance dragon naturally speaking,SDK)、IBM Watson语音识别应用程序编程接口。前述将语音转成文字的工具将访客(受试者)及/或响应(人类声音/音效输入)转成文字语句。系统100’的访客(受试者)不需要也并不一定要与系统100’互动。系统100’使用一般影像指令(播放/暂停/停止)与系统100’的自动面试官。相反地,分析后的访客声音输入使系统100’做最佳响应与反应。另外,访客的音效/语音输入可以任何类型的使用麦克风,注册到系统100’,通常是内建/整合式的麦克风,如麦克风122b,该麦克风安装在面试者使用的计算机122上。接着,口语分析引擎210侦查/剖析声音输入的文字语句,此来自于特定字词、关键词、印迹及/或一及/或多个关键词组合与自然语言处理技术,以将文字语句转换成有意义的指令,让引擎210可以解读及了解并可以分析转换后的文字,如此所述。
其他应用程序编程接口210x和口语分析引擎210包含像Alchemy应用程序编程接口情绪,来判断访客(如受试者)的情绪或表情,例如快乐、悲伤、关心、好斗之类。此外,Whitesmoke应用程序编程接口用于评估访客(如受试者)的语言等级。IBM Watson Personality Insights应用程序编程接口,根据「大五(Big5)」、「数值」及「需求」模式,评估心理特点或特质、「值」的模式。这些结果提供给评分模块210d并计入口语分析引擎210的整体分数。
口语分析引擎210透过模块210a-210d及应用程序编程接口210x分析访客(如受试者)的口语/声音/语音输入的内容,这些内容存储在面试的音讯档案中。数个参数中的至少一个参数的分析立即列于下。每一种用来分析访客表现的口语分析参数,相对系统的面试官所问的问题,都有自己的特殊评分方法与相关调整分量(重要性和/或优先级)。进行最后分析时,该评分结果将会列入计算。口语分析参数包含下列参数(如下列模块)等。细节参阅图2B:
1.特质比较模块210a
此模块210a的理论基础是结合人资(人力资源)田野方法与心理学田野方法来进行评估,并分析以计算法及无偏差方法所搜集的资料。
模块210a会使用专业评估数据进行心理评估,以提供更高的可靠性及准确度。此外,这个新增的数据分析工具的组合,建立有用的数据让引擎210分析。模块210a的学习能力允许每个工作的预测模型进行开发。这些工作的面试任务由系统100’执行。举例来说,招募时该模型可辨别出:对比于常用规范,若要顺利工作,则对一特定职务具备广泛知识,比创意技巧较不重要。
为了建立模型,假设不同的工作需要不同的诊断流程。这意味着,根据每个职业,不建立只是其中一种诊断工具及互换判断标准和预测,针对每个职业自定义诊断。这里根据一详细工作分析流程,该工作分析流程根据该特定工作产生预测准则。稍后,准则转换成一组特定问题和任务。另外,可针对每个工作开发某一特定方法来评估所获得的答案。此外,制作各种不同数据分析工具,以进行分析。例如,产生对问题、语调、眼睛视线、脸部表情及表达力进行分析后的数据(非口语引擎212)。为了产生更多数据,再分析答案本身的语意。有一种数据无法由人力预估而产生和编码。此外,从所有求职者那里搜集到的信息,可以进行相对比较。此种比较无法用人力预估,因为会发生忽略部分重要信息,也会对部分重要信息有偏见。
工作分析方法发展于20世纪早期且属于工业组织(I-O)心理领域之一。它是一系列的流程,用来识别该工作内容所涉及的活动和属性或执行活动时的工作需求。它受人资主管和心理学家广泛使用,包含公共和私人领域。该流程需考虑关于该工作的相关资料及专家意见,以扣除主要知识、技术、能力和其他特性(knowledge,skill,ability and others,KSAOs),以完成工作顺利(Delegated Examining Operations Handbook,2007),尤其是每个类别中的最佳特色。这些最佳特色都是跨领域的,所以才能取得简洁和清晰的画面;这是根据美国人事管理局(Office of Personnel Management,OPM)法及O*NET数据库中的职业信息的建议。工作知能特色是根据行为与非行为功能来分类。其他组织公民行为准则根据所收集到的资料(Kristof-Brown,A.,&Guay,R.P.(2011).Person–environment fit)来分析。
下一步是在评估每个工作知能时,了解其与哪个应用程序编程接口工具相关。例如,脸部表情的技术工具可能会和受试者整体干劲评估相关。此乃根据许多心理评估工具与方法,像大五、情感智能、自我效能等(Furnham,A,1996)。大五对比大四:在Myers-Briggs型指示器(MBTI)和个性NEO-PI五规格型号之间(Personality and Individual Differences,21(2),303-307;Furnham,A.,Jackson,C.J.,&Miller,T.,1999)、性格、学习风格与工作绩效、特色与个别差异(Personality and Individual Differences,27(6),1113-1122)及其实施方式。在同一时间工作知能的特色都会转换成可测量的特色,即到深入的面试问题。最后,一组差异化与综合问题和任务的特定组合的收益最能反映出职业的工作知能,并可对该工作进行最精准且有效的面试(Campion,M.A.,Campion,J.E.,&Hudson,J.P.,1994)。标准化面试是:注意增量有效性和其他问题类型(Journal of Applied Psychology,79(6),998)。
与职业有关的额外任务组也会进行开发。这组任务是为了预估受试者关于特定工作的能力。请记得,进行此组任务可以提供不同类型的资料及面试问题部分。再一次,相关的应用程序编程接口会进行配对。收集在这里的数据会做分析,以进行更全面的评估。
之后,针对面试每一项评估与衡量的答案/表显的方法开发出来了(Structured Interviews:A Practical Guide,美国,2007)。开发过程是根据以下假设:评估应反映答案是否清楚展现问题原先确认的目的。然后,必须通过分解分析,才能产生出一种可以翻译成机器学习技术的评估等级,以让流程雾化。每个工作知能的特色受所有工具评估,这些工具可评估答案分数、API、任务成绩(例如,企业技巧受Big Five责任心分数、测量此技巧的高质量答案,以及和工作知识任务中所呈现的工作型态的评估),以产生综合最后分数。
非直接功能的进一步分析用于辨别和了解面试时额外执行的流程,这些流程做为一个整体问题及每个问题或每项任务。亦即,在评估特定的工作知能(知识、技术、能力和其他特性)之余,还可产生面试过程的意识。
从各领域来的方法组合是上述流程的结果,其方法组合使用各种不同的应用程序编程接口。该应用程序编程接口具有分析更多相关、可靠、大量数据的能力,且以准确、比较及无偏见的方式进行,且结合持续学习与模型微调,是结果中所述的流程。
这里提供一个等级范例。
职能:人际交往技巧(取自2008年美国联邦政府人事管理局)
定义:一个展现了解、友善、礼貌、机智、同理心及礼貌给其他人的人。发展及维持与其他人的实质关系。可能包含有效应付难搞、有敌意或忧伤的人。和不同背景的人建立良好关系。
问题:描述你以前应付难搞、有敌意或忧伤的人时所遇到的情况。谁有参与了?你采取了什么特别行动,以及结果为何?
专业比较模块210b:访客回复的口语内容是测量与答案相关的上下文,也就是相较于或就其他访客回答相同或类似的问题时,访客就预期答案,在口头回答上回答得有多好或多接近,或就履历上对于某特定职位的数据集。回答内容是以(但不限于)下列的方法测量:
1.内容架构:组织、架构及/或至少一个字词或组合字词放在单一或多个句子或词组的位置,如系统针对系统面试者的问题所预期的位置。例如,如果访客被要求说出其专业背景,答案的正确结构应该是(根据研究所做的比较和评分):访客应先说明其专业背景(从最近或相关的经历谈起,再谈到最早或最不相关的经历),接着访客应该说明其学术背景(从最近的开始),最后则是关于他们的专业及个人成就及最后且选择性地说明其个人兴趣。注意:对于某些像这里所介绍的问题,系统或许可以点击到第三方的在线社交网络(即访客的LinkedinTM简历),以验证或更加了解访客答案的相关度。
2.职业兼容性:对于系统和访客所面试的职位/角色,答案可以评估访客的专业及个人经验是否适合。例如,如果访客被问及其在销售职位上是否具有专业优点,系统会预期访客回答以下特点(根据比较和评分后的研究):具说服力、善交际及为人外向,然后系统会认定这些特质符合系统设定的答案。同样地,这些特质可能无法反映一名老练销售人员的特质,可能会个别影响分数。注意职业兼容性可能还需要考虑到个人/心理的特点/质量。
3.专业等级:在与访客接受系统面试时直接相关的头衔/职位/角色,评估访客的专业能力等级或特征。例如说,工作经验年资、访客对于各种已处理过的专业状况的所采用的形式或方法,以及访客所面试的特定领域/职业上所展现的直接专业性向或熟练度。
专业比较模块210b也可执行称为「语意混乱」的流程。语意杂乱让每个文字文件和二维(two dimension,2D)或三维(three dimension,3D)表现连接起来。此算法由此模块210b使用深度自编码器(AutoEncoder)来计算表现的点数。接着一张列表记录最小距离相对于理想简介点的点。此简要清单会是候选理想名单。
用于语意混乱的工具,内建从网站上撷取约三万份履历,该具有三万份履历的数据库由深度自编码器校准。这些履历从不同的工作类别及子类别(约30个子类别)中取出。
数据处理
这些数据转换成可被接受的格式以进行计算,例如向量。字词袋(Bag Of Words)创造出来。这个字词袋包含所有文件上的所有字词,不过被视为无意义的字词则排除,例如定冠词the、不定冠词a、介系词over等。
使用一算法,将所有履历都比拟成字词袋。在数向量创造出来后,每份履历上出现在字词袋上一次的字便计算一次。数向量(例如2000字)接着会被压缩成两位双倍数,且该两位双倍数构成一个候选点的坐标。
深度自编码器的目的类似于一主成分分析(principal component analysis,PCA)。主成分分析是一种统计技术,可让登录资料呈现在统计上有意义的轴(该轴上有更多变化)
与登录资料相关的只有贡献在最有意义轴上。反主成分分析流程用来重新产生一个十分接近原点的登录数据点。此流程对应到信息遗失的压缩,如以下所述的两个阶段:编码(从原始登录数据到多数相关轴的贡献),以及译码(从贡献到一类似原始数据点的数据点)。
深度自编码器以类似的方式运作,虽然不能精确提供相同的坐标轴,但仍可让我们进行数据压缩。
深度自编码器是使用深度信念网络,以及如同神经元的受限玻尔兹曼机(restricted Boltzmann machine,RBM)而制作出来的,用以简化流程。这意味神经网络与受限玻尔兹曼机的四层或五层代表编码部分(类神经网络的一半)与一个由几个神经元所组成的瓶颈(bottleneck),以维持有意义的贡献。
例如,只保留两个提供点坐标的贡献。点坐标代表受试者。
若要校正整个深度自编码器、所撷取的数据用来校准系统。一组文件从字词袋的字(例如2000字)组成。每份文件上的字只要和2000字数向量吻合一次便计算一次。数向量做为自动编码器的项目。每一层的每个神经元都有其特定校准的分量。为了要校准这些神经元的分量,由自动编码器计算的重建数据和原始数据做比较。一错误功能用于计算每个登录数据的错误,并尝试尽量降低改变神经元分量的错误。根据杰弗里·辛顿(Geoffrey Hinton),一种有效率的解决方案是使用受限玻尔兹曼机(restricted Boltzmann machine,RBM)校正来计算重量的编码部分,然后对译码部分使用反向传播(Backpropagation,BP)(以对称方式将神经元的分量初始化,以计算并将RBM解碼)。套用机器学习普通考虑以启用快速并确实整合,以防止过度拟合(该型号会详细校正测试资料。任何其他处理过输出的数据有很高的可能性出错出错)或在接头上。取自网络的数据会完成校正。
美丽汤(BeautifulSoup)及Python用于进行数据撷取/剖析。用于设计神经网络的DeepLearning4j及Java,用来对图形处理器(graphics processing unit,GPU)进行数据处理、向量化、神经网络设计及分布式计算。Octave用来测试给深度自编码器的Hinton码。
完成上述校准后,新的正文数据跟着出现。编码器提供两个作为坐标点的数字。图示和所选取的正文文件有关。该所选取的正文文件会译成地图。
文法模块210C。文法模块根据下列流程分析正文中的文法:
1.对于访客所响应的口语内容,测量语用和/或语意上是否精确。
2.对于访客所响应的口语内容,测量每个字的平均字母数。
3.对于访客所响应的口语内容,测量每个字的平均音节数。
4.对于访客所响应的口语内容,测量每一句的平均字数。
5.可能使用应用程序编程接口者210x来存取口语文法。引擎210对此口头文法进行评分。
引擎210执行多种语言分析评估方法。虽然上述系统所使用的一些口语分析参数可依据第三方(商业或开放原始码)技术,例如自然语言处理技术和其他语音识别技术,也可依据文字分析工具,例如网页语音识别应用程序编程接口(web speech recognition API)、细微龙自然说话、Whitesmoke Writer等。引擎210透过应用程序编程接口210x评估,也包含一评分模块210d,该评分模块210d作为一记分系统。该评分模块210d评分时会提供一表现评分和分数。如上所述,该评分有部分是基于模块210a、210b的输出及上面列出的应用程序编程接口210x。该系统内的每一题内及其相关回答分析是根据各种算法、每个问题及其本身方法,以分析回答质量(如上面的范例)。此算法对系统提出每个问题后所获得的答案进行定义,以解释每个问题可能的动机及/或意图。因此口语分析可更好地评估所要的答案结果。此外,口语分析引擎210可提供标准或控制,用来代表每个职业获得最佳或最高评分的答案及其结构设定,或回答每个特定问题的方式。
非口语分析引擎212
非口语分析引擎212用于分析访客(例如受试者)的各种人格特质、习惯及行为,并对这些非口语动作和行为评分。非口语分析引擎212使用下列参数来决定分数:
1.非口语分析变量:
a)物理回馈:任何肌肉骨骼身体的姿势或动作(包含细微脸部),可能会对可能未说出口的意图或感觉透露线索,这可藉由评估受试者的表现来分析。访客的非口语输入,经由至少一个参数来分析。该参数包含,但不限于下列清单中。
1)眼睛视线(纪录受试者视线移动的点)
2)脸部表情(追踪受试者的脸部表情并解释其情绪)和姿势分析
3)移动分析包含手势分析
2.生理回馈意见
a)生物回馈意见
b)呼吸速率
c)心跳速率
d)血压
e)皮肤接点
用于分析眼睛视线的模块212a位于引擎212内。眼睛视线或眼神接触是一种非口语沟通形式,非口语沟通可传达下列任何相关参数的讯息(非完整列表)。从访客(例如受试者)的摄影机122a接收的影像,引擎212根据系统的眼睛物体侦测机制或应用程序编程接口212x(如Camgaze.js),预测访客的眼睛视线(眼观测方向)。眼睛视线数据是基于一组二维向量,该二维向量代表每位受试者眼睛的方向。眼睛视线方向数据作为样本并存储在存储装置。这里提供一参数列表,可评估眼睛视线:可靠(真实)及与聚焦或分散。
对眼睛视线分析评分取决于下列其中一或数个原则:
a)「视线偏差值」:视线向量的强度的数值和/或测量值。注意,此测量值可能以可变量学公式的变化为基本,以计算最佳眼睛视线的价值。
b)任何特定临界值(已在系统中定义),在此之上,视线偏差值可能比时间量大。除非另有说明,眼睛视线测量系统监视受试者凝视某特定方向的时间或变更视线的方向,例如(往下;往上)。
脸部表情。非口语分析参数中的一模块212b。脸部表情是定义是脸部皮肤下肌肉的位置。系统会追踪细微脸部动作(例如脸部表情)并输出一连串的相关坐标。坐标反映描述受试者情绪的看法。该系统主要根据应用程序编程接口212x如clmtrackr、Affdex应用程序编程接口、Emotient应用程序编程接口,可侦测并定义细微脸部表情。细微脸部坐标与对应的情绪数据会存储在存储器210并由存储器210进行分析。受试者的脸部表情可传达下列任何一项示范性的情绪状态的信息:生气、喜悦、悲伤、惊讶、自豪、恐惧、厌恶及无聊。
这项分析的分数,由评分模块212f计算,其依据是:a)受试者答题时展现的情绪;b)时间和感情的表达;及c)表达每种情绪状态所需的时间。
姿势分析模块212c分析姿势:姿势的定义是一特定身体部位或整个身体方向的位置和方向。评估个人特质及/或情绪状态是否要扣分时,会纳入与姿势有关的身体部位,正如清单中包含的头、胸、肩、手臂、手等。
受试者的姿势可能会传达有关下列个人特质的信息,包含个性、自信、顺从和坦率等。
受试者的姿势可能传达关于下列情绪状态的信息:生气、喜悦、伤心、惊讶、骄傲、恐惧、厌恶和无聊。
根据身体空间坐标系统,该系统可以了解并判断受试者的姿势。藉由比较系统自己分析的受试者姿势与存储在系统里的姿势分析研究(计算公式、模型、理论),系统可以解释上述至少一项特质或情绪状态。评分模块212f根据身体姿势的比较结果评分,例如访客的姿势更接近所接受存储的姿势愈接近,所获得的分数愈高。每次侦测到这类情绪状态或基因,便会存储在存储器并触发系统,并可个别响应,例如触发其他预录的影像片段,以进行简报。之后当情绪状态或特点出现时,评分模块212f也会收集其元资料(metadata),以根据下列列表调整分数。该清单包含:a)(姿势)发生的原因;b)情绪状态或特点的幅度;c)侦测到情绪状态或特点的时间点;d)侦测到情绪状态所需的时间。
系统100’能因应面试时侦测到的情绪状态做回应。经由这种分析所产生的分数,会纳入受试者表现的报告中。
运动分析模块212d分析动作:运动的定义是身体部位经过一段时间的动作,包含手势。当身体部位移动时,将评估个人特质或情绪状态是否要扣分。
由运动分析模块212d分析该列表主体的运动,且该清单包含头、手臂、手等。
受试者身体的运动传达出其情绪状态的一些信息,例如:生气、喜悦、悲伤、焦虑、兴趣、恐惧、拘谨、沮丧、自豪、羞耻。
根据身体空间坐标、模块212d可了解并决定该运动。根据该运动,系统能解释上述至少一种情绪状态。每次这类情绪状态都经侦测出来,它存储在存储器220并在引擎212内触发事件让。在情绪状态或人格特质发生的背后,模块e212d产生一清单。此清单包含:a)发生的原因(这里是运动);b)情绪状态或特点的幅度;c)侦测到情绪状态或特点的时间点;以及d)侦测到情绪状态所需的时间。
运动分析模块212d可以根据面试中所侦测到的情绪状态做不同反应。这个分析由评分模块212f做解释,且会产生一个分数,该分数会列入受试者表现的报告中。运动分析的分数会以上述变量为基准,并加到整体实况分数(由中央处理器202计算)。该整体实况分数根据上述变量而得出。
生理回馈模块212e。任何身体的生理表现都可测量出来。根据这些参数,系统可评估受试者的感觉或情绪状态,列出如下。此列表包含像压力等级、谎言、焦虑、恐惧、生气等。
在感觉或情绪状态背后,系统100’也会在这些心理表现上收集元数据,包含像a)事件的原因(这里指生理上);b)情绪状态或特质的强度;c)情绪状态或特点受侦测时的时间;d情绪状态受侦测时所需的时间。
引擎212可以根据面试中所侦测到的情绪状态做不同反应。这个分析由评分模块212f做解释,且会产生一个分数,该分数会列入受试者表现的报告中(整体实况分数,由中央处理器202产生)。
构成受试者表现报告整体分数的引擎212分数,可强化这种特性的重要性变大或变小。
系统100’可依客户需求,无论是对口语或非口语分析、实体或生理等参数,都科设定一引擎/模块或参数的重要性/重要意义超过另一引擎/模块或参数。因为这类的系统100’提供一后端办公室(即管理系统),该后端办公室可允许系统100’进行调整与管理。
声音分析(腔调)引擎214
声音分析(语调)引擎214功能透过声音部分的面试,分析存储在声音档案中的访客(例如受试者)的各种人格特质、习惯及行为,并提供的声音分析的分数。V声音分析(语调)引擎214采用下列参数决定分数。
声音语调-模块214a。访客声音的音速特征和韵律特色经分析后用来评估访客的情绪状态,包含但不限于快乐、伤心、自信、焦虑或兴奋。这里可能像应用程序编程接口来评估声音腔调。系统经由声音语调-模块214a对声音语调评分。
声音重音模块214b。分析访客声音的音速特征,以评估所说内容的真实性与可靠性,例如真相。这或可透过应用程序编程接口214x评估声音压力后做分析。引擎214经由评分模块214d为此声音压力评分。
口语清晰度及一致性-模块214c。口语清晰度和一致性是平均音量的测量标准,也是访客语音和/或发音清晰度的音波动态范围的测量标准。这里举例,请使用应用程序编程接口214x来评估口语清晰度和一致性。该评分模块214d对口语清晰度及一致性进行评分。
其他由声音分析引擎214分析的参数包含如下:
响应时间-响应时间为系统面试官问了一个问题之后及访客开始回答该特定问题的时间长度的测量值。
答案长度-答案长度为每个响应每个个别问题的整体字数的测量值。
回答时长-回答时长包含a)访客需完整回答时间的测量值;b)针对每个问题,访客从回答的第一个字算起到最后一个字的测量值;及c)针对某一特定问题,访客从回答的第一个字起,直到预先分配的时间长度完成。
说话速度-说话速度是在每一定时长内测量访客说话文字的平均速率,包含但不限于分及/或秒。说话速度是比较先前所定义的回答长度和回答时间。例如说,可利用可评估口语说话速度的应用程序编程接口214x。
流畅度-流畅度包含a)针对访客回答的口语内容,测量其话语中的停顿,及/或字词的重复或非字词的声音的重复;b)将先前定义的响应时间、答案长度、答案时长,及/或说话速度和其他受试者相比较。流畅度可利用一应用程序编程接口等来评估口语流畅度。系统100’经由评分模块214d对此口语流畅度进行评分。
互动引擎216
当面试官向访客(如受试者)122询问专业且相关的问题时,互动引擎216负责提供访客(如受试者)逼真的面试经验。这些问题选出来后依职位相关度做成清单,给人资管理人员或其他负责者于面试时使用。面试时引擎216根据访客(如受试者)122的声音实时以程序编纂、运作,例如透过访客(如访客的计算机122)的麦克风(如麦克风122b)输入到引擎216来实时以程序编纂、运作。引擎216侦查/剖析访客120输入的声音,此声音来自特定字词、关键词、印迹及/或至少一个关键词组合。引擎216可以将这些字词转换成指令,以触发下一个问题、选择下一个问题,及/或决定何时结束问答。此外,引擎216编排以决定声音的停顿、安静时间、静音及说话变慢,暗示回答即将结束,或是其他声音语调,暗示回答结束或表示访客122变厌倦或无聊了。之后引擎216就产生并发出触发下个问题的指令、从中选择题目,以及结束面试问题。此外,互动引擎以程序编纂来分析前述访客122的声音,例如分析访客回答的上下文,并选取下一题。下一题从可能问题列表中选出(当面试开始时建立)。藉由分析访客122答案的上下文,系统100’面试时会进行与上下文相关的对话,在面试官(即面试官的录音和录像)和实况面试官140之间。其录音录像和实况面试官都显示在访客120的计算机122上。上述声音输入的分析,例如由口语分析引擎210备份。口语分析引擎210在面试声音的文字上执行类似作业。文字是口语分析引擎210从声音透过应用程序编程接口210x转换而来的,如上所述。
互动引擎216会使用访客的声音输入(例如回答、意见、反应、响应、逆响应)与选择问题类型(根据从访客接收到的上下文分析,即同时使用问答式和交互式独白。接着,引擎216再播放从系统100’中选出的适当面试问题,面试问题已经请面试者预录好。互动引擎216从全部选取的问题(例如录制好的影像问题),使用以下指令来拉/触发最相关的预填、预录的面试官问题(例如录制好的影像问题)。这些问题从可能问题列表中选出。制定此列表是为了面试。互动引擎216有系统地(播放最相关的预录的影像片段,问答式独白或交互式独白),然后根据如表1中以逻辑结构和规则为基础的系统,以最访客的响应做最好的逆响应,并以个别指导面试模拟,进行看似内容相关的面试对话框。
设定并进行面试
为了提供访客(求职者或工作受试者)进行全自动化且交互式工作面试的可能性,系统100’首次使用/播放预录真人面试官的声音-影像(及/或真人招聘经理、演员扮演的招聘经理,或公众人物),向访客询问专业相关问题。注意:上述系统100’的真人面试官的预填声音-影像包含两组/种独白,共同提供上下文聪明且逼真的交互式面试经验给系统的访客。这些两组独白、问题类型和交互式独白如下所述。
问答独白类型很常见,但较少出现的面试中关于专业的问题。问答独白类包含庞大的通用与职业特定问题组合。附注、通用类型面试问题是更广义的问题形式,这可能与几乎所有的职业字段与专业角色/职位相关。系统所使用的所有独白类型是基于广泛且持续性的研究,在对人力资源产业,特别是对聘雇专业人士与招聘经理在面试时所呈现的问题及互动上。该研究是根据两个在线和脱机资源,即私人及/或公开文章、书籍、研究论文及影像,以及实体实况观察到的情况。问题类型的独白在面试时不只强调问题的不同类型,还包含面试官问每个问题时所传达或应传达的方式,例如表情、语气、身体语言、问题的系统阶层等。该问题的系统阶层像是哪些问题应该在面试一开始时就提出,哪些在中间、结尾时提出。
交互式独白是用来建立更逼真的面试经验。互动引擎216采用预录的面试官反应,这称为「未知数」(wild card)反应。这些声音-影像反应是基于以逻辑结构和规则为基础的系统,该系统是用来向访客的各种典型和主要口语陈述/意见/反应/响应(不视为答案)做逆反应,而且会发生在真实对话及专业面试对话的设定中。交互式独白计划不只要能更自然地逆响应访客的语言和非语言输入,还要能实时调整系统的响应时间,并能提高交谈的真实感。以「未知数」规则为基础的系统详述于表1。
为了提供回头访客(例如访客利用系统100’多次)合法面试经验,所呈现的两种独白类型上面包含数种不同预先录制的声音-影像选项,代表类似类别问题,或逆反应,但包含系统面试者不同的讲稿独白和行事风格。上述这些各种预录的影像选项都能准确及按计划地以程序编纂在互动引擎216中,以让系统更具自然真实性与现实,这样一来同一问题便不可能多次拿来询问访客,访客也不会多次收到相同的逆响应。
本系统所提出的两种独白,即问答式和交互式,由系统的面试官100’用英语进行(以预先录制的影像)。然而,这里未刻意限制使用何种语言。系统100’是用来容纳大地理区的观众,以及能否同时使用英文及许多其他语言工作。系统100’的语言兼容性不仅表示录像录音下来的系统的面试官100’的独白,还可能表示文字讯息、(与技术/非技术或营销相关)指示、解释及系统100’展现的其他图形访客接口元素。
真人面试官所有预录的声音-影像是专门拍摄的,以符合实时/逼真的专业面试所需的效果/背景/设定。
面试官和面试官的录音(个人扮演部分面试官),不限于单一个人。系统100’使用不同个人预录像像(例如真人招聘经理、扮演招聘经理的演员、公众人物,以提供访客(例如受试者)120更真实且多元的面试经验。系统100’使用最合适的真人面试官可因此(也)取得真实性。系统100’内,可扮演最适合该角色及/或模仿所需面试官类型及面试设定。这些扮演决定包含但不限于面试官的性别(男或女)、年龄(年轻或老年)、服装(正式或休闲)、所说语言的种类,及任何相关种族。上述面试官类型/角色代表最好的梦想职业/位置/专业角色,出现在访客面试时。求职者可在系统利用这些角色(使用系统前可预选)来练习其面试技巧,或是一组织(私人/上市公司/公司/企业/招募人员)为了对求职者进行/主办专业面试等目的而利用这些角色,藉以决定求职者是否适合该职位/角色,并根据面试的期望结果及/或目标,决定由哪位求职者到哪个职务/角色/职位(例如访客或受试者120)工作或实习。
设定/背景:面试发生的地点/位置(可在某一特定地方内或指定的录音室内,以描述某一特定位置)引导整体气氛/环境,以及与面试相符的氛围。访客经由录像录音观看这种拍摄给系统100’使用的面试地点,此面试地点包含但不限于下列地点:专业办公室、咖啡厅/餐厅、会议室、休息室,或任何其他客制、用于真实情况的面试地点。
电话面试设定都是完全自动化面试,进行方式是让访客观看系统100’,并与系统100’透过预录像像进行互动/对话。重要的是,本说明所预期的面试经验未限制访客在这个主要和独特但单一的面试经验形式。此外,系统100’也可让访客进行电话面试(面试采两方通话方案),由求职者利用系统练习其电话面试技巧,或由组织(私人/上市公司/公司/企业/招募人员)为了对求职者进行/主办专业电话面试的目的而利用,藉以决定求职者是否适合该职位/角色。
电话面试也经常特别用来判断初次/首次求职者兼容性的过滤方法,通常在在过滤履历的流程后进行,以评估要邀请/通知哪位求职者前来做正式面试。
一个电话面试的方法如下。第一、系统100’启动自动化交互式电话面试。相对于一般面试官-受试者选项,系统100’允许访客(如受试者)选择电话面试。接着,当访客选择一般面试官-受试者选项,就可以选择该职业类型及可能设定和系统语言,并使用电话面试设定。最后,一旦访客选择了电话面试,访客便能取得电话号码。
应注意的是,访客可输入系统设定的地理涵盖范围内的所有电话号码。访客可以输入任何类型的工作电话号码。这里的「电话」是指任何装置,且该装置提供以因特网通讯协议(Internet Protocol,IP)或公共交换电话网络(Public switched telephone network,PSTN)为基础的电话解决方案,无论是透过专线、透过3/4K G LTE,或是其他任何可以达到双向沟通的基础架构。
统上可以使用任何一种掌上型装置来进行面试,例如智能型手机、平板计算机、笔记本电脑等。访客120根据营运商及/或其居住地的法规,可能必须应邀求加入系统100’。根据立法主体/管理,选择加入选项可能会出现在文字讯息的表格中、及/或短码回复、及/或任何视为自由选择的方式。年龄限制措施也会遵循法规措施由营运商及/或访客的居住地订定。
选择加入流程也会验证访客输入的号码属于访客本人,并确认号码输入时不会出现无任何错误。访客输入的选择加入及/或电话号码通常会连接到访客的特定系统简历/帐户,以方便辨识及其他用途使用,即电话面试表现分析。
在选择加入(若有必要)之后,访客可以开始进行电话面试。面试可为系统拨打访客所提供的电话号码,及/或播放面试官打电话的影像,并试图拨打电话(暗示这是一通打给访客的电话)。系统100’将会采取许多措施来验证访客(如受试者)已接通电话,否则系统100’将会重试几次,及/或采取其他行动方案以完美解决此状况。
一旦访客接听电话,访客能够听到和看到(如果其正在计算机屏幕前)面试官正在和自己进行面试。访客现在可以用电话和面试官交谈。系统所使用的独白类型和方法的响应,也可适用于及用于进行电话面试期间。电话面试期间时,访客将能证明表现分析。
该分析是根据同一口语评量法,该口语评量法在一般面试官-受试者的时段进行。
现在请看图3、图4A及图4B为本发明实施例的流程图,绘示详细的计算机实作流程。请一并参考图1A、图1B和图2。图3、图4A及图4B的流程与子流程由系统100’进行计算器计算。上述图3、图4A及图4B的流程与子流程可采手动、自动或结合手动及自动方式实时进行。
流程自区块302开始,表示面试正式开始。人力资源主管透过人力资源管理系统112负责面试工作,这也标示面试正式开始:1)定义要面试的职位;2)设定准则,如面试的问题类型,例如包含存储器222的讲稿及可能的特定问题清单:以及3)提供受试者清单,如收到通知并受邀使用自己的计算机来参加面试的受试者,例如图1A中计算机122进行(自动)录制,或例如图1B中计算机122进行实况录制。
该流程会移到进行面试的区块304,例如透过访客计算机122进行,并以录制影像和声音。请见图1B,若为实时面试,面试官140与受试者120的面试会透过面试官140的计算机142进行,并录制影像和声音。实时面试时,受试者120和面试官140的影像和声音会录制起来并会存储在区块306。视情况,在区块307,面试官140的影像和声音以声音和图像文件案存储在存储器220(图2)。
该流程从区块306和弹性选择区块307移到区块308。关于受试者(面试官在实况面试的情况下)面试时的影像及声音在区块308分析。分析后的评价结果在区块310发出。该评价结果包含至少一个:给受试者的分数、推荐/不推荐访客(例如受试者)120,以及该相关分析的展示,例如报告的表格。
现在请看图4,区块304提供更多细节。从区块302、流程移至区块304a。在区块304,系统100(即互动引擎216)透过访客计算机122的麦克风122b,从访客(如受试者)那里接收到声音,并侦测受试者回答问题的结束处,例如侦测声音的停顿、安静时间、静音及说话变慢,暗示回答即将结束,或是其他声音语调,暗示回答结束或表示访客变厌倦或无聊了。
接着,在区块304b分析答案。此项分析(如上下文分析)是根据受试者的回答的上下文。该流程移至区块304c,在区块304c中,根据前述分析,例如上下文分析,引擎216决定是否还有更多问题须问受试者。如果引擎216从上述区块304b中的分析确定没有其他问题要问,或已经问完本面试问题清单上的问题(且没有任何更多问题提供给本面试),则流程移至区块306。
然而,在区块304c,当提出更多问题时,该流程会移到区块304d。在区块304d,根据前述分析选择下一个问题。例如在区块302,安排面试时,从问题清单中选择适合面试的问题。接着,在区块304e,面试官会向受试者提问这些问题。根据面试类型(自动化或实况),选出的问题会录起来后提问或实况提出。流程从区块304e回到区块304a。区块304a后会重新开始。
现在请看图4B。区块308显示更多分析细节。在区块308a-1、308a-2和308a-3中,口语分析引擎210、非口语分析引擎212及声音分析引擎214都分别进行分析。接着,该分析会传送给内部评分模块210d、212f、214d,分别如区块308b-1、308b-2及308b-3所示。接着,对应的分数会传送到区块308c中的中央处理器并计算受试者的分数。接着,该流程移到图3的区块310。
机器学习
机器学习概述
在面试期间,将不同模块的众多功能收集起来并送入机器学习系统330(图2A)。接着,机器学习系统330预测受试者是否适合所申请的工作。特色通常是在面试的过程中分析各种类型的参数,即说话语调、细微脸部表情、口语分析等。
数据集标签
系统230(图2A)根据前述特色及其各自得分,评估受试者在面试时的整体表现。在各种模块里的特色,构成全球化系统的不同引擎210、212。不同引擎210、212和系统230直接连接。为了教导机器学习系统330取得各个功能的所需分数结果,个人考官,如具有一特定领域知识者,在检视受试者的面试纪录时,根据是固定式或加权等级系统(范例1~7)的每项特色,有时用来为这些个别功能进行标记/评分。因此,根据上述标记/评分,机器学习系统330透过其评分模块232(图2),可以调整并改善其评分输出。
学习
机器学习系统是一种具有可见单位层的神经网络。神经网络的特色是里面具有至少一个隐藏/内部单元层,以和输出单元层。该神经元彼此连接,并具有一定集合概率(激活概率)。在学习过程中,这些概率会自适应,以使新进功能产生较接近上方(输出)层的卷标/分数的预测。系统330使用反向传播算法以训练该系统,但不只限于本方法。
评分逻辑
根据相对加权分数算法并个别衡量这些模块里的每个特色,口语和非口语引擎内的每个模块进行个别评分。在预测一受试者是否适合一特定工作时,一项特色基于其有效性、可靠性、适用性和可能性的程度,可能会获得较高分量。一权衡算法可能会套用到有助于判断每个特色所需的分量等级,因此该系统可能会使用这类外部算法应用程序编程接口(即IBM权衡分析应用程序编程接口)。权衡分析不仅可以协助判断与凸显不同分量等级,还可以用来判断一受试者是否比其他受试者更合适。机器学习藉由自动调整分量相应地应用到评分逻辑上。该评分模块232评估机器学习与引擎210、212所产生的任何分数后,对受试者评分。
图5为一流程图,绘示范例性流程。该流程由机器学习系统230和评分模块232执行。受试者在面试时的录像(区块502a)及受试者在面试时的录音(区块502b)都会进行分析,并将录像和录音里的特色撷取出来(区块504)。这些撷取出来的特色,包含例如脸部表情、眼睛视线及声音表现语调、所说的语词及其语序,都会定义为原始数据(区块506)。这些原始数据会输入像是神经网络等的机器学习系统来处理(区块508)。处理这些原始数据的目的是用来判断受试者的各种特质,如开放度、参与度、积极度、社交能力等。
该流程移至区块510。在区块510中,决定性特质的分数由评分模块232评估。在区块512中,评分模块232将面试所需的职位(工作)要求纳入考虑后,提供每个特质的权重。该流程移至区块514。在区块514中,评分模块232会产生受试者面试后的分数。
虽然上述提及本发明应用于专业人才招募业的聘雇及工作安排上,但是该引擎、该方法及该系统也能应用在其他行业和目的上,包含但不限于下列项目:企业训练、运动,包含运动心理、教育训练、业务、法律的制定及安全。
本发明实施例的方法及/或系统的落实,可涉及执行或完成所选的工作,无论手动、自动或结合两者皆可。此外,根据本发明实施例的方法及/或系统实际使用的仪器及设备,数个所选的工作可使用具有硬件、软件或韧体或结合以上三种的操作系统来落实。
举例来说,根据本发明实施例,执行所选任务的硬件可为一芯片或一电路上。根据本发明实施例所选的任务,软件可为数个软件指令,且该数个软件指令由一具有一合适操作系统的计算机来执行。在本发明的范例性实施例中,根据这里所介绍的方法及/或系统的范例性实施例所述,至少一个任务由数据处理器执行,例如执行数个指令的计算机运算平台。可弹性的是,该数据处理器包含一挥发性内存(volatile memory)来存储指令及/或数据及/或非挥发性内存。该非挥发性内存可为非暂时性存储介质,例如磁硬式磁盘驱动器及/或可抽取式介质,以存储指令及/或数据。可弹性的是,也可以提供以网络进行联机。可弹性的是,也可以提供一显示器及/或一访客输入设备(例如一键盘或一鼠标)。
例如,至少一个非暂时性计算机可读取(存储)介质的任何组合可根据上述所列的本发明实施例来使用。非暂时性计算机可读取(存储)介质可能为一计算机可读取讯号或一计算机可读取介质。一计算机可读取介质可为(但不限于)一电子、磁性、光学、电磁、红外线或半导体系统、仪器或装置,或是任何前面提到的组合。更多关于计算机可读取存储介质的特定范例(非详尽列表)包含:一电源联机,具有至少一个线材、一便携计算机磁盘、一硬盘、一随机存取内存(RAM)、一只读存储器(ROM)、一抹除式只读存储器(EPROM)或一闪存、一光纤、一可携式光盘只读存储器(CD-ROM)、一光学存储装置、一磁存储装置,或是上述任何适当的组合。在本文件的上下文中,一计算机可读取存储介质可为任何实质介质。该实质介质可包含或存储一程序,用于连接一脚本执行系统、仪器或装置。
一台计算机可读取讯号的介质可包含一传播数据讯号。一计算机可读取程序代码内建在该传播数据讯号内,例如在基频里或作为部分载波。这样的传播讯号可能会有任何一种形式,包含(但不限于)电磁、光学或任何合适的组合。一台计算机可读取讯号的介质可能为任何计算机可读取介质(非一计算机可读取存储介质),且于使用时或与一指令执行系统、仪器及装置连接时,可以沟通、传播或传输程序。
参考如上所述的段落与参考图示,并参考这里采用计算机执行方法的各种实施例,便能对本发明有深入了解。其中有些运用各种实施例中所介绍的仪器或系统便可实施,有些则根据存储在非暂时性计算机可读取存储介质内的指令来实施。但仍然有些采用计算机执行方法的实施例,可利用其他仪器或系统来实施,也可根据这里未提及,但存储在计算机可读取存储介质内的指令来实施;这对于看过上述介绍后的该技术领域具有通常技术者来说,应可轻易理解。任何对系统和计算机可读取存储介质的标示,都是为了对下列计算机实作方法进行解说,并非用来限制上述任何这类系统与任何该类非暂时性计算机可读取存储介质。同样地,任何对与系统和计算机可读取存储介质相关的下列计算机实作方法,都是为了解说之用,并非用来限制任何在这里所揭露的计算机实作方法。
图中的流程方块图根据本发明各种实施例,绘示系统方法及计算机程序产品的架构、功能及可能的实作方式。在这方面,流程图或方块图上的每个区块可能代表一种模块、区段或是部分程序代码,其包含至少一个可执行指令,以实际执行特定的逻辑功能。同时应该注意的是,在其他一些实际例中,区块里的功能可能不是案照图上的顺序。例如说,两个接连运作的区块事实上可能同时运作或有时以相反的方向运作,端赖所使用的功能。也要注意的是,方块图及/或流程图上的每个区块,以及方块图及/或流程图上组合的区块,可由以特殊目的硬件为基础的系统或以特殊目的硬件和计算机指令的组合,执行特定功能或行为。
本发明的各种实施例已针对图示的目的进行介绍,但并非特意穷尽或限制所揭露的实施例。该技术领域具有通常技术者应明白,未来很多修改与变化都不会背离所揭露的实施例的范围和精神。这里所选用的用语和说法可以详尽解释本发明实施例的原则、实际应用程序,或市场上科技方面的技术发展。这里所选用的用语和说法也可以让该技术领域具有通常技术者可以理解这里所介绍的实施例。
此处所用的单数字词「一」、「该」、「本」等,包含数个参考物,除非上下文有清楚表示出来。
「范例性」这个词在这里用来表示「作为范例、例子或图标」。任何实施例描述为「范例性」未必要解释为优先或优于其他实施例及/或排除把其他实施例的特色结合在一起的情况。
必须明白的是,为了清楚介绍本发明的某些特色,便在各别实施例中程述陈述,但也可以在单一实施例中陈述。相反地,为了精简介绍本发明的各种特色,便在单一实施例中陈述,但也可以在各别实施例、任何合适的子组合或任何其他本发明所介绍的实施例中陈述。在各种实施例介绍的某些特色,不应被视为这些实施例不可或缺的特色,除非当该实施例缺少这些组件便无效时例外。
上述部分流程可由软件、硬件及其组合执行。这些流程可以由计算机、计算机输入型设备、工作站、处理器、微型处理器,以及其他相关的电子搜寻工具和内存和其他非暂时性存储型装置。其部分流程也可在可程序化的非暂时性存储介质中进行,这些介质包含光盘(compact discs,CD)或机器可读取的磁性光盘、光学光盘等。其他非暂时性存储介质,包含磁性、光学、半导体存储器,或其他电子讯号来源等,也可读取这些光盘。
关于流程(方法)与系统,包含其组件,本发明已对特定硬件和软件使用范例性的参考标记加以详述。流程(方法)都是示范说明而已,该技术领域具有通常技术者可以省略及/或变更来减少这些实施例,以进行未预期的试验。由于流程(方法)和系统已充分叙述,该技术领域具有通常技术者应可轻易将该流程(方法)和系统应用到其他硬件和软件上,也或许可能需要以减少实施例,以进行未预期的试验并使用传统技术。
虽然本发明已搭配其独特的实施例进行详述,但对于该技术领域具有通常技术者而言,显然还有许多替代方案、修改及变化。因此,本发明的目的是要接纳所有这类替代方案、修改及变化。这些替代方案、修改及变化皆属于本发明附带的权利要求的精神和范围里。
表1
求职者的回答/回复型式:
求职者主要具有以下两种回答型式/类别:
1.良好的回答:任何没有落入表1列出的奇怪反应。
2.奇怪反应:如表1所描述的求职者回答。
面谈流程:
1.面试官发问
2.使用者有下情形:
a)回答
b)以奇怪反应回复
3.面试官设定回复
a)倘若是好的回答=>系统面试官会继续问下一个问题。
b)倘若是奇怪反应=>请见表1。
- 还没有人留言评论。精彩留言会获得点赞!