基于深度学习和光场成像的显微成像系统及方法
1.本发明涉及基于深度学习和光场成像的显微成像系统及方法,属于光场显微成像技术领域。
背景技术:
2.光场成像系统主要是通过光学装置采集捕捉到空间分布的四维光场,再根据不同的应用需求来计算出相应的图像。计算光场成像技术基于四维光场,旨在建立光在空域、视角、光谱和时域等多个维度的关系,实现耦合感知、解耦重建与智能处理,用于面向大范围动态场景的多维多尺度成像。光场成像技术正逐渐应用于生命科学、工业探测、国家安全、无人系统和虚拟现实/增强现实等领域,具有重要的学术研究价值和产业应用前景。
3.光场显微(light-field microscopy,lfm)是通过在传统光学显微镜的中继像面上插入一块能够捕获光场信息的微透镜阵列来实现的。通过4d光场数据的反演能重建多视角图像和多层焦平面图像,引入去卷积算法和断层重建能实现三维显微成像。由于这些后续处理都可通过一次曝光实现,因而对观察运动的微生物和光敏感样品有其独特优势。光学显微镜凭借其非接触、无损伤等优点,长期以来是生物医学研究的重要工具。但是,自1873年以来,人们一直认为,光学显微镜的分辨率极限约为200nm,无法用于清晰观察尺寸在200nm以内的生物结构。
4.利用光场显微镜得到高分辨率图像在生物研究和医疗方面都有重要意义,其中数字显微成像技术有别于传统光学显微成像,可根据重建全息图获取细胞的生物学参数与形貌信息,是一种有效的非接触无损三维成像技术。随着图像传感器的发展与硬件计算能力的提升,数字全息显微成像技术在活体生物细胞检测尤其在血红细胞检测领域取得了显著进展和突破。如今数字显微成像技术已广泛运用于细胞迁移分析和异常细胞行为研究,同时也大量使用于描绘医学图像的仪器中。
5.但是,一方面,由于受设备以及成像技术的限制,数字显微成像技术获得的图像并不能有非常高的准确度;另一方面,由于传感器分辨率(传感器可感受到的被测量的最小变化的能力)的限制,光场相机通常通过牺牲空间分辨率(能够详细区分的最小单元的尺寸或大小)来换取角度分辨率(成像系统或系统元件能有差别地区分开两相邻物体最小间距的能力),导致图像不清晰。因此,有限的空间分辨率是光场相机发展的难处所在。
6.为了解决上述问题,yoon等人首次提出基于卷积神经网络的光场数据超分辨率重建(yoon y,jeon h g,yoo d,et al.light field image superresolution using convolutional neural network[j].ieee signal processing letters,2017.),其网络可分为空间分辨率重建卷积神经网络和角度分辨率重建卷积神经网络,但该模型并没有充分利用多视角图像间的有效信息,导致无法获得较高分辨率的重建图像,也无法快速获得无伪影、强度分布均匀的重建图像。
技术实现要素:
[0007]
为了解决目前显微成像中存在的伪影、非均匀分辨率以及重建速度慢等问题,本发明提供了基于深度学习和光场成像的显微成像系统及方法,所述技术方案如下:
[0008]
本发明的第一个目的在于提供一种基于深度学习和光场成像的显微成像系统,所述显微成像系统包括依次连接的:显微系统、深度学习网络模块、图像输出模块;
[0009]
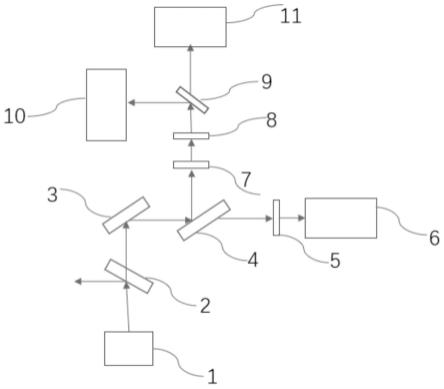
所述显微系统用于采集图像的多个二维数据,包括:显微镜头1、第一分色镜2、透镜3、第二分色镜4、带通滤波器5、第一相机传感器6、微透镜阵列7、中继透镜8、第二分色镜9、第二相机传感器10、第三相机传感器11;
[0010]
所述显微镜头1采集图像数据,经过所述第一分色镜2过滤去除干扰光线,再经过所述透镜3折射使光线聚焦,再经过所述第二分色镜4,使采集到的信号一部分聚集到用于宽场成像的第一相机传感器6,进行宽场成像;另一部分分别经过所述微透镜阵列7、中继透镜8、第二分色镜9,分别在所述第二相机传感器10和第三相机传感器11上进行光场成像;
[0011]
所述深度学习网络模块,用于将所述第一相机传感器6、第二相机传感器10和第三相机传感器11成像的二维图像数据重构成高分辨率三维图像;
[0012]
所述图像输出模块用于输出重构后的高分辨率三维图像。
[0013]
可选的,所述深度学习网络模块采用训练好的vcd深度网络vcd-net进行高分辨率三维图像的重构。
[0014]
可选的,第一相机传感器6、第二相机传感器10和第三相机传感器11采用scmos相机。
[0015]
可选的,所述vcd深度网络vcd-net的训练过程包括:
[0016]
步骤1:初始化vcd-net,包括:网络参数和损失函数;
[0017]
步骤2:从真实静态样本及合成数据的共聚显微镜中获取高分辨率三维图像;
[0018]
步骤3:构建波动光学模型,将步骤2中获取的高分辨率三维图像输入所述波动光学模型,输出相应的二维图像;
[0019]
步骤4:基于步骤3获取的二维图像和步骤2获取的高分辨率三维图像构建训练集和测试集,将所述二维图像作为输入,将所述高分辨率三维图像作为输出,对所述vcd-net进行训练,直至收敛,得到最优的vcd-net网络模型。
[0020]
可选的,对样本进行光场成像时,利用1:1的中继透镜8将所述第二相机传感器10、第三相机传感器11对焦在所述微透镜阵列7的后焦平面。
[0021]
可选的,所述波动光学模型为:
[0022]
f=hg
[0023]
其中,矢量f表示采集到的原始光场图像,矢量g表示重建的物体3d离散点云,h是成像过程的点扩散函数矩阵表示。
[0024]
本发明的第二个目的在于提供一种基于深度学习和光场成像的显微成像方法,包括:
[0025]
步骤一:采用显微镜头采集图像数据,将所述图像数据输入显微系统中的多个相机传感器和由微透镜阵列和ccd构成的传感器分别进行宽场成像和光场成像,得到多个二维图像;
[0026]
步骤二:将所述步骤一中获取的二维图像输入训练好的深度神经网络,通过所述
训练好的深度神经网络得到重构的高分辨率三维图像。
[0027]
可选的,所述显微系统包括:显微镜头1、第一分色镜2、透镜3、光束分离器4、带通滤波器5、第一相机传感器6、微透镜阵列7、中继透镜8、第二分色镜9、第二相机传感器10、第三相机传感器11;
[0028]
所述显微镜头1采集图像数据,经过所述第一分色镜2过滤去除干扰光线,再经过所述透镜3折射使光线聚焦,再经过所述光束分离器4,使采集到的信号一部分聚集到用于宽场成像的第一相机传感器6,进行宽场成像;另一部分分别经过所述微透镜阵列7、中继透镜8、第二分色镜9,分别在所述第二相机传感器10和第三相机传感器11上进行光场成像。
[0029]
可选的,所述深度神经网络采用vcd-net网络,将所述第一相机传感器6、第二相机传感器10和第三相机传感器11成像的二维图像数据重构成高分辨率三维图像。
[0030]
可选的,所述vcd-net网络的训练过程包括:
[0031]
步骤1:构建并初始化vcd-net;
[0032]
步骤2:从真实静态样本及其合成数据的共聚显微镜中获取高分辨率三维图像;
[0033]
步骤3:构建波动光学模型,将步骤2中获取的高分辨率三维图像输入所述波动光学模型,输出相应的二维图像;
[0034]
步骤4:基于步骤3获取的二维图像和步骤2获取的高分辨率三维图像构建训练集和测试集,将所述二维图像作为输入,将所述高分辨率三维图像作为输出,对所述vcd-net进行训练,直至收敛,得到最优的vcd-net网络模型。
[0035]
本发明有益效果是:
[0036]
本发明基于光场成像和深度学习网络构建光场显微成像系统,通过由微透镜阵列和相机传感器构成的显微系统获取多个二维图像,然后深度学习网络从这些二维图像中获取多视角图像信息对图像进行超分辨率重构,获得高分辨率的三维图像,相比于现有的基于卷积神经网络的超分辨率重构方法,本发明产生的图像具有更高的空间分辨率(1.0+0.15um)、较小的重建伪影和更大的重建吞吐量(200hz),从而有效地提升成像清晰度;且在透镜阵列系统下,本发明的基于深度神经网络的超分辨率光场图像生成模型还具备低成本、低系统复杂度、无需扫描的超分辨率成像的优势,有效提升了重构速度。
附图说明
[0037]
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0038]
图1是本发明实施例的一种显微成像系统的平面示意图。
[0039]
其中,1-显微镜头;2-第一分色镜;3-反射镜;4-光束分离器;5-带通滤波器;6-第一相机传感器;7-微透镜阵列;8-中继透镜;9-第二分色镜;10-第二相机传感器;11-第三相机传感器。
具体实施方式
[0040]
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方
式作进一步地详细描述。
[0041]
首先对本发明涉及的基础理论知识介绍如下:
[0042]
vcd-net网络:
[0043]
vcd网络为:在一般的卷积神经网络(cnn)中,某个第n卷积层从前(n-1)层接收特征图,并使用不同的卷积核生成新的特征图。网络最终产生多通道输出。其中每个通道都是原始输入的非线性组合,这个概念与光场摄影中的数字重聚算法有相似之处,其中重建体积的每个合成平面都可以理为从光场中提取的不同视图的叠加。通过级联层,我们的模型有望逐渐将原始角度信息从光场原始图像转换为深度特征,最终形成传统的3d图像堆栈并重建场景。在实现过程中,定制的vcd-net基于修改后的u-net架构(参考https://cloud.tencent.com/developer/article/1520224)。其中包含下采样路径和对称上采样路径,沿着两条路径,每一层有三个参数:n、f和s,分别表示输出通道数、卷积核的滤波器大小和移动核的步长。
[0044]
实施例一:
[0045]
本实施例提供一种基于深度学习和光场成像的显微成像系统,所述显微成像系统包括依次连接的:显微系统、深度学习网络模块、图像输出模块;
[0046]
所述显微系统用于采集图像的多个二维数据,参见图1,包括:显微镜头1、第一分色镜2、反射镜3、光束分离器4、带通滤波器5、第一相机传感器6、微透镜阵列7、中继透镜8、第二分色镜9、第二相机传感器10、第三相机传感器11;
[0047]
所述显微镜头1采集图像数据,经过所述第一分色镜2过滤去除干扰光线,再经过所述反射镜3使光线从竖直方向进入水平方向,再经过所述光束分离器4,使采集到的信号一部分聚集到用于宽场成像的第一相机传感器6,进行宽场成像;另一部分分别经过所述微透镜阵列7、中继透镜8、第二分色镜9,分别在所述第二相机传感器10和第三相机传感器11上进行光场成像;
[0048]
所述深度学习网络模块,用于将所述第一相机传感器6、第二相机传感器10和第三相机传感器11成像的二维图像数据重构成高分辨率三维图像;
[0049]
所述图像输出模块用于输出重构后的高分辨率三维图像。
[0050]
实施例二:
[0051]
本实施例一种基于深度学习和光场成像的显微成像系统,所述显微成像系统包括依次连接的:显微系统、深度学习网络模块、图像输出模块;
[0052]
所述显微系统用于采集图像的多个二维数据,参见图1,包括:显微镜头1、第一分色镜2、反射镜3、光束分离器4、带通滤波器5、第一相机传感器6、微透镜阵列7、中继透镜8、第二分色镜9、第二相机传感器10、第三相机传感器11;三个相机传感器均采用scmos相机。
[0053]
显微镜头1采集图像数据,经过所述第一分色镜2过滤去除干扰光线,再经过所述的反射镜3使收集到的光线从垂直方向进入水平方向,再经过所述光束分离器4,使采集到的信号一部分聚集到用于宽场成像的第一相机传感器6,进行宽场成像;另一部分分别经过所述微透镜阵列7、中继透镜8、第二分色镜9,分别在所述第二相机传感器10和第三相机传感器11上进行光场成像;进行光场成像时,利用1:1的中继透镜8将所述第二相机传感器10、第三相机传感器11对焦在所述微透镜阵列7的后焦平面。
[0054]
深度学习网络模块采用训练好的vcd深度网络vcd-net,根据第一相机传感器6、第
二相机传感器10和第三相机传感器11成像的二维图像数据重构成高分辨率三维图像;
[0055]
vcd-net的训练过程包括:
[0056]
步骤1:构建并初始化vcd-net,本实施例在window10环境中使用tensorflow 1.15.0,tensorlayer 1.8.5和python 3构建vcd-net深度学习模型;
[0057]
步骤2:从静态样本或合成数据的共聚显微镜中获取高分辨率三维图像;
[0058]
步骤3:构建波动光学模型,将步骤2中获取的高分辨率三维图像输入所述波动光学模型,输出相应的二维图像;
[0059]
波动光学模型为:f=hg,其中矢量f表示光场,矢量g表示正在重建的离散体积,h是正向成像过程的测量矩阵建模,h主要由光场显微镜的点扩散函数决定。
[0060]
使用波动光学对光学显微镜的空间变化点扩散函数进行建模,光场点扩散函数映射了从三维物体到二维平面的转变,并且也是空间上的变化,对于感兴趣区域的每一个点都有一个独特的点扩散函数被考虑。为了生成点扩散函数,使用标量衍射理论计算通过微透镜阵列对体积中的多个点进行波前成像。
[0061]
步骤4:基于步骤3获取的二维图像和步骤2获取的高分辨率三维图像构建训练集和测试集,将所述二维图像作为输入,将所述高分辨率三维图像作为输出,对所述vcd-net进行训练,通过迭代最小化其中间输出和参考高分辨率图像之间的差异来逐步训练,通过设置适当损失参数,例如像素强度的均方误差,为每一层获得优化的核参数,并有效地收敛到一个得到最优的vcd-net网络模型。
[0062]
通过将显微系统采集的多个二维图像(本实施例采集的是秀丽隐杆线虫的图像)输入到训练好的vcd-net网络模型中,可以得到最终的高分辨率重构图像。
[0063]
图像输出模块用于输出重构后的高分辨率三维图像。
[0064]
实施例三:
[0065]
本实施例提供一种基于深度学习和光场成像的显微成像方法,采用实施例二记载的基于深度学习和微透镜阵列的显微成像系统实现,包括以下步骤:
[0066]
步骤一:采用显微镜头采集图像数据,将所述图像数据输入显微系统中的多个相机传感器和微透镜阵列分别进行宽场成像和光场成像,得到多个二维图像;
[0067]
步骤二:将所述步骤一中获取的二维图像输入训练好的vcd-net网络模型,通过所述训练好的vcd-net网络模型得到重构的高分辨率三维图像。
[0068]
本发明实施例中的部分步骤,可以利用软件实现,相应的软件程序可以存储在可读取的存储介质中,如光盘或硬盘等。
[0069]
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1