用于测量话语信号质量的系统和方法与流程
本申请案涉及主张2013年6月26日申请的美国临时专利申请案第61/839,807号“SYSTEMSANDMETHODSFORMEASURINGSPEECHSIGNALQUALITY”、2013年10月9日申请的美国临时专利申请案第61/888,945号“SYSTEMSANDMETHODSFORMEASURINGSPEECHSIGNALQUALITY”、2013年6月26日申请的美国临时专利申请案第61/839,796号“SYSTEMSANDMETHODSFORINTRUSIVEFEATUREEXTRACTION”、2013年6月26日申请的美国临时专利申请第61/839,800号“SYSTEMSANDMETHODSFORNON-INTRUSIVEFEATUREEXTRACTION”及2013年9月10日申请的美国临时专利申请第61/876,177号“SYSTEMSANDMETHODSFORFEATUREEXTRACTION”的优先权。
技术领域:
本发明大体上涉及电子装置。更确切地说,本发明涉及用于测量话语信号质量的系统和方法。
背景技术:
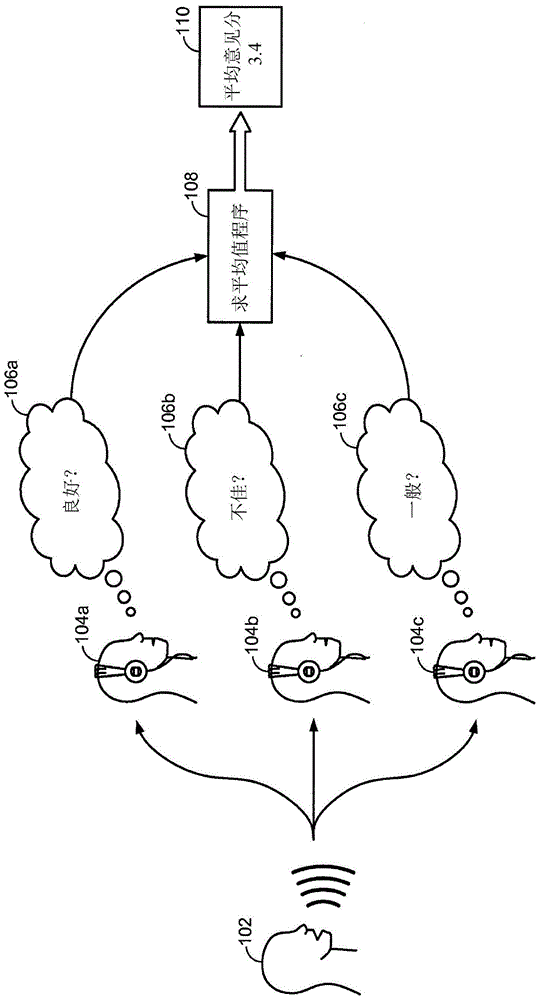
:最近几十年中,电子装置的使用已变得普遍。具体来说,电子技术的进步已降低了越来越复杂且有用的电子装置的成本。成本降低和消费者需求已使电子装置的使用剧增,使得其在现代社会中几乎随处可见。由于电子装置的使用已推广开来,因此需要电子装置的新的且改进的特征。更具体来说,人们常常寻求执行新功能及/或更快、更有效且以更高质量执行功能的电子装置。一些电子装置(例如,蜂窝式电话、智能手机、录音机、摄录影机、计算机等)捕获或利用音频信号。举例来说,智能手机可捕获话语信号。可能难以量化话语信号质量。此外,可能难以识别及/或量化影响人们如何感知话语信号的话语信号的特性。评价话语信号质量可能费时同时且昂贵。正如由此论述可能观察到,改善话语信号评价的系统和方法可为有益的。技术实现要素:本发明描述一种通过电子装置测量话语信号质量的方法。获得修改后的单声道话语信号。基于修改后的单声道话语信号估计多个客观失真。多个客观失真包含至少一个前景失真和至少一个背景失真。基于多个客观失真估计前景质量和背景质量。基于前景质量和背景质量估计整体质量。测量话语信号质量可根据包含多个分层层次的分层结构而执行。每一分层层次可取决于任何及每一相对较低分层层次。多个分层层次可包含三个层次。第一分层层次可包含估计多个客观失真。第二分层层次可包含估计前景质量和背景质量。第三分层层次可包含估计整体质量。估计整体质量可进一步直接基于多个客观失真。多个客观失真中的每一者可表示话语质量的独立维度。前景失真可包含粗糙度、不连续性、枯燥及薄度。背景失真可包含呼啸和变化性。修改后的单声道话语信号可基于原始话语信号。可在无需原始话语信号的情况下估计多个客观失真。原始话语信号可获得且多个客观失真可进一步基于原始话语信号。本发明还描述用于测量话语信号质量的电子装置。电子装置包含基于修改后的单声道话语信号估计多个客观失真的计算失真估计器。多个客观失真包含至少一个前景失真和至少一个背景失真。电子装置还包含耦合到计算失真估计器的计算前景质量估计器。计算前景质量估计器基于多个客观失真估计前景质量。电子装置进一步包含耦合到计算失真估计器的计算背景质量估计器。计算背景质量估计器基于多个客观失真估计背景质量。电子装置另外包含耦合到计算失真估计器的计算整体质量估计器。计算整体质量估计器基于前景质量和背景质量估计整体质量。本发明还描述用于测量话语信号质量的计算机程序产品。计算机程序产品包含具有指令的非暂时性有形计算机可读媒体。指令包含用于使电子装置获得修改后的单声道话语信号的代码。指令还包含用于使电子装置基于修改后的单声道话语信号估计多个客观失真的代码。多个客观失真包含至少一个前景失真和至少一个背景失真。指令还包含用于使电子装置基于多个客观失真估计前景质量和背景质量的代码。指令进一步包括用于使电子装置基于前景质量和背景质量估计整体质量的代码。本发明还描述用于测量话语信号质量的设备。设备包含用于获得修改后的单声道话语信号的装置。设备还包含用于基于修改后的单声道话语信号估计多个客观失真的装置。多个客观失真包含至少一个前景失真和至少一个背景失真。设备进一步包含用于基于多个客观失真估计前景质量和背景质量的装置。设备另外包含用于基于前景质量和背景质量估计整体质量的装置。附图说明图1说明使用主观方法的质量分析;图2为说明用于客观确定话语信号的质量的两种方法的框图;图3为说明使用感知客观收听质量评估(P.OLQA)的现行ITU标准预测MOS的精确性的图表;图4为说明用于测量话语信号质量的方法的一个配置的流程图;图5为说明经配置以用于测量话语信号质量的电子装置的一个配置的框图;图6为说明可根据本文所公开的系统和方法实施的分层结构的一个实例的框图;图7为说明可根据本文所公开的系统和方法实施的分层结构的另一实例的框图;图8为说明基于所提取的特征和训练话语样本预测主观质量测量得分的一个单一维度的框图;图9为说明对应于图9A至9C的实例的多个部分的框图;图9A为说明特征矩阵的框图;图9B为说明额外特征的框图;图9C为说明权重应用的框图;图10为说明可实施以用于测量话语信号质量的分层结构的一个实例的流程图;图11为说明经配置以用于测量话语信号质量的网络设备和两个电子装置的一个配置的框图;图12为说明经配置以用于测量话语信号质量的电子装置的一个配置的框图;图13为说通过电子装置实施以用于测量话语信号质量的方法的流程图;图14为说明通过网络设备实施以用于测量话语信号质量的方法的流程图;图15为说明用于特征提取的电子装置的一个配置的框图;图16为说明用于特征提取的方法的一个配置的流程图;图17为说明生理耳蜗模型输出的一个实例的图表;图18为说明侵入性特征提取模块的一个配置的框图;图19为说明非侵入性特征提取模块的一个配置的框图;图20为说明被拆分成区段A至D的耳蜗模型的输出的一个实例的框图。图21为说明从耳蜗模型输出的部分提取基于位置的分析向量的一个实例的框图;图22为说明从耳蜗模型输出的部分A提取基于位置的分析向量的另一实例的框图;图23为说明从耳蜗模型输出的部分提取基于时间的分析向量的一个实例的框图;图24为说明从耳蜗模型输出的部分A提取基于时间的分析向量的另一实例的框图;图25包含说明特征确定模块的配置的框图;图26说明特征确定的实例;图27说明特征确定的另一实例;图28说明根据本文所公开的系统和方法的客观预测的一个实例;图29说明根据本文所公开的系统和方法的客观预测的另一实例;图30说明根据本文所公开的系统和方法的客观预测的另一实例;图31为说明对应于图31A至31D的实例的多个部分的框图;图31A为说明使用侵入性特征提取估计或预测粗糙度失真的一个实例的部分的框图;图31B为说明使用侵入性特征提取估计或预测粗糙度失真的一个实例的另一部分的框图;图31C为说明使用侵入性特征提取估计或预测粗糙度失真的一个实例的另一部分的框图;图31D为说明使用侵入性特征提取估计或预测粗糙度失真的一个实例的又另一个部分的框图;图32为说明对应于图32A至32D的实例的多个部分的框图;图32A为说明使用非侵入性特征提取估计或预测粗糙度失真的一个实例的部分的框图;图32B为说明使用非侵入性特征提取估计或预测粗糙度失真的一个实例的另一部分的框图;图32C为说明使用非侵入性特征提取估计或预测粗糙度失真的一个实例的另一部分的框图;图32D为说明使用非侵入性特征提取估计或预测粗糙度失真的一个实例的又另一个部分的框图;图33为说明用于特征提取的方法的更特定配置的流程图;图34为说明用于侵入性特征提取的方法的配置的流程图;图35为说明用于非侵入性特征提取的方法的配置的流程图;图36为说明侵入性特征提取的更特定配置的框图;图37为说明无线通信装置的一个配置的框图,其中可实施用于测量话语信号质量的系统和方法及/或特征提取;及图38说明可包含于电子装置/无线装置内的某些组件。具体实施方式本文所公开的系统和方法的一些配置利用诊断话语失真和整体质量的分层系统。话语信号的质量由人类收听者最精确地测量。然而,就时间和金钱两者而言,通过多个收听者采取此类评价代价较大。因此,能够精确复制人类收听者反应(关于话语质量)的系统和方法(例如,算法、计算系统等)将是有益的。举例来说,这些系统和方法可取代对多个人类收听者的需求。本文所公开的系统和方法提供模仿人类耳蜗的液压机械功能、人类耳蜗至听觉神经的机械神经分布和内/外毛细胞的功能性的计算引擎。内毛细胞(从计算引擎)的输出可用于推断人类话语感知的各种方面。人类收听过程极其复杂,涉及用来在上听觉通路和中枢神经系统(CNS)中神经处理电转换信号(后耳蜗功能)的耳蜗中的流体力学。已尝试预测整体质量(作为单维度量)的已知途径已无法涵盖广泛范围失真或无法达到高精确性。举例来说,现行国际电信联盟(ITU)标准感知客观收听质量评估(P.OLQA)(预测平均意见分(MOS)的P.863)在估计已通过P.OLQA针对其而设计的系统降低的话语的质量时并不精确。具体来说,现有系统和方法可从人类耳蜗的计算模型的输出提取特征。所述特征可随后被进一步分析以预测话语质量。虽然在预测话语质量的上下文中论述本文所描述的特征,但所述特征可用于任何适合的应用且不限于话语质量预测。所使用的耳蜗的计算模型为将话语信号精确地转换为内毛细胞反应的液压机械生理模型。具体来说,功能性耳蜗模型可在无需理解耳蜗如何工作的情况下查看耳蜗的输入及输出且试图模仿耳蜗的功能。相反,现有系统和方法的生理耳蜗模型尝试模仿耳蜗的特定生理反应(例如,耳膜、耳道、耳蜗内部的流体、各种膜上的力/位移/速度、内毛细胞及解释例如质量、弹性及/或摩擦特性的这些结构的生理性质)且其中建模通过基础物理学且不限于使用近似物(例如使用类似于海因茨(Heinz)、鲍姆加特(Baumgarte)、迈迪斯(Meddis)或兹维克(Zwicker)的研究中的电子电路建模)而执行以产生输出。因此,应用生理耳蜗模型来预测话语质量为本文所公开的系统和方法的一个独特特征。本文所公开的系统和方法的一些配置利用“分治”策略。举例来说,本文所公开的系统和方法可首先试图诊断话语质量的个别属性/维度(例如,失真)且随后合并这些个别属性以预测信号的整体质量。举例来说,可利用分层途径,其中首先执行多个失真诊断,随后执行前后台失真诊断且最后利用计算模型估计整体质量。本文所公开的系统和方法提供话语质量的客观测量。传统上,执行主观收听测试以确定平均意见分(MOS)。这些主观收听测试可耗钱、费时且不可重复。话语质量的客观测量可克服主观收听测试的缺点。尽管主观量度可能是最精确的,但可利用客观量度来预测主观量度的输出。在话语质量测试的客观测量期间,原始话语可提供至编码器(例如,增强型可变速率声码器(EVRC)编解码器)。可对原始话语和经编码话语执行心理声学分析。可比较结果以估计MOS。此途径的实例包含国际电信联盟(ITU)标准,例如P.861、P.862及P.863。所有这三者试图预测如ITU标准P.800中所描述的主观MOS测试的结果。噪声可注入原始话语中。可将噪声受困扰话语提供至增强算法(例如,噪声抑制器)。可对原始话语和经强化话语(例如,噪声受抑制话语)执行心理声学分析。可比较结果以估计MOS。此途径的一个实例根据欧洲电信标准协会(ETSI)而提供,所述实例尝试预测如ITU标准P.835中所描述的主观测试的结果。话语质量的客观测量的已知途径可为一维。然而,话语质量为多维。一个维度可能不充分或不精确。举例来说,现行ITU标准P.OLQA(预测MOS的P.863)并不完全精确。其可不正确的预测EVRC编解码器的MOS。此的一个实例为ITUQ9WP2ContributionCOM12-C270rev1-E(201110)。与已知途径相比,本文所公开的系统和方法可在预测MOS中提供更高的精确性。在一些配置中,本文所公开的系统和方法可并入预期ITU标准(例如,P.TCA、P.ONRA及P.AMD)中。表1说明用于测量话语质量的一些途径(例如,规范化且在发展中)。本文所公开的系统和方法可应用至在标准化的发展中的标准。表1可应用本文所公开的系统和方法以取代具有检测多个独立失真的能力的一维话语信号质量测试。一旦获得多维‘检测能力’,可因此预测整体质量。本文所公开的系统和方法可采用“分治”策略。举例来说,提供新颖框架和特征(例如,高级感知特征)。可利用分层系统或结构来诊断话语失真和整体质量。此可导致改善整体质量预测的精确性。额外优势包含提供关于话语信号的诊断信息、潜在地提供关于网络疾病的诊断信息、提供用于研发译码/增强算法的可能工具及提供关于质量的实时反馈。现在参考图描述各种配置,其中相同的参考标号可以指示功能上类似的元件。可以广泛多种不同配置来布置及设计如本文中在诸图中所大体描述及说明的系统和方法。因此,对如各图中所表示的若干配置的以下更详细描述并不希望限制如所主张的范围,而仅表示系统和方法。图1说明使用主观方法的话语信号质量分析。主观方法为用来基于人类收听者104a至104c的感知测量一或多个话语信号的质量的途径。主观模型可包含将一或多个话语信号提供至一或多个人类收听者104a至104c的话语信号源102。一或多个人类收听者104a至104c可收听一或多个话语信号,且基于人类收听者的104a至104c感知的质量对一或多个话语信号的质量进行评定。举例来说,人类收听者104a可决定话语信号的质量为良好106a;另一人类收听者104b可决定同一话语信号的质量为不佳106b;第三人类收听者104c可决定同一话语信号的质量为一般106c。在主观测试中,三个等级将通过求平均值程序108求平均值且给出公平的平均意见分(MOS)110。归因于此方法对于一或多个人类收听者104a至104c和测试仪两者是费时的,主观方法难以不断地使用。使用此主观方法的另一可能不利方面为主观方法可代价较大。此主观方法可使人类收听者104a至104c通过他们的时间得到报酬;其还可能需要用于测试的专用区域以使得结果更一致。主观方法还可能难以获得可重复结果。由于人类收听者104a至104c在确定话语信号的质量时可具有巨大差别。举例来说,同一话语信号可用于两种不同主观方法测试。第一主观方法测试可导致话语信号具有普通的话语信号质量等级,且第二主观方法测试可导致同一话语信号具有良好的话语信号质量等级。算法或计算系统可能能够精确复制人类收听者的104a至104c反应。此可减少花费在测试上的金钱。举例来说,可模拟人类收听者的104a至104c感知话语的计算引擎可为生理耳蜗模型。生理耳蜗模型可使用本文所描述的方法预测话语信号的整体话语质量。生理耳蜗模型可复制耳蜗中的流体力学及在人类耳朵的上听觉通路及中枢神经系统中完成的神经处理。生理耳蜗模型可诊断话语质量的个别维度且随后合并这些个别属性以更精确地预测话语信号的整体话语质量。用于话语信号质量分析的生理耳蜗模型的使用可改善整体质量的预测、提供关于话语信号的诊断信息及提供用于使用实时质量反馈的增强算法的可能工具。图2为说明用于以计算方式预测话语信号的质量的主观确定因此产生客观得分的两种方法的框图。原始话语信号212a至212b可(例如)在通过译码器214及/或增强222之后变为失真话语信号。P.835为专门用于已失真及随后使用各种算法接着强化的信号的ITU主观测试标准。P.800为在范畴中比P.835更常用的ITU主观测试标准且对于任何失真信号都有效。图2中展示的两种方法可基于模拟人类听觉感知提供失真话语信号的质量(在译码及/或增强214、222之后)的客观得分。两种方法展示使用MOS(P.800)和P.835主观测试方法的主观评价的产生计算预测(客观得分)。方法P.800产生整体评分MOS,且方法P.835产生三个得分:S-MOS、N-MOS及G-MOS。S-MOS为话语信号的前景质量的得分、N-MOS为话语信号的背景噪声的得分和G-MOS为话语信号的整体质量的得分。两种测试方法可使用侵入性或非侵入性方法。为了清晰起见,关于主观话语质量的ITU标准的一些阐释给出如下。对于话语信号,P.800仅产生一个整体得分,被称作MOS。P.835产生三个得分:S-MOS、N-MOS及G-MOS。S-MOS仅为前景/信号的得分且N-MOS仅为背景/噪声质量的得分。G-MOS为整体质量的得分,所述得分实际上与P.800中的MOS相同。P.806(其在2014年初最终形成ITU标准)产生8个得分。图2中的方法可仅使用失真话语信号(例如,在译码及/或增强214、222之后)或失真/修改后的话语信号(由译码器214或增强模块222输出)及原始话语信号212a至212b(用作参考以进行比较)的组合完成。前者(当原始话语信号212a至212b不存在时)为非侵入性方法,而后者(当修改后的/失真信号和原始话语信号212a至212b两者存在时)为侵入性方法。修改后的话语信号可包含原始话语212a至212b信号的变化,包含处理。经处理话语信号可为修改后的话语信号的一个实例。预测MOS得分的方法可获得原始话语212a信号。原始话语212a信号可用作尝试模拟人类感知的心理声学分析216a的输入。原始话语212a信号还可用作译码器214的输入以模拟可通过无线网络完成的信号压缩和其它类型的信号处理。译码器214可输出修改后的话语信号且允许预测MOS得分的方法包含测试的非侵入性方法。修改后的话语信号可用作尝试模拟人类感知的心理声学分析216b的输入。来自原始话语信号和修改后的话语信号的心理声学分析216a至216b的结果可随后被比较218a。原始话语信号和修改后的话语信号的比较可提供整体MOS220a。MOS得分可从一到五变动。得分一可具有“不良”的质量;二可具有“不佳”的质量;三可具有“一般”的质量;四可具有“良好”的质量;及五可具有“极佳”的质量。用于评价话语信号的包含噪声抑制算法的客观测试方法还可获得原始话语212b信号和噪声224以用于分析。此方法可产生可包含S-MOS、N-MOS及G-MOS得分的P.835得分。原始话语212b信号和噪声224可用作尝试模拟人类听觉感知的心理声学分析216c的输入。原始话语212b信号和噪声224可用作增强模块222的输入。举例来说,增强模块222可减小可能在原始话语212b信号中的噪声或回声。增强模块222可输出修改后的话语信号且允许P.835预测方法包含测试的非侵入性方法。修改后的话语信号可用作尝试模拟人类听觉感知的心理声学分析216d的输入。来自原始话语212b信号和修改后的话语信号的心理声学分析216c至216d的结果可随后被比较218b。原始话语212b信号和修改后的话语信号的比较可提供P.835220b测试的质量等级中的一或多者。P.835得分可具有三个评分;S-MOS用于前景话语质量、N-MOS用于背景噪声质量和G-MOS用于整体话语质量。所有三个等级可从一到五变动。S-MOS的得分一可具有“极其失真”;二可具有“相当失真”的等级;三可具有“略微失真”的等级;四可具有“稍微失真”的等级;及五可具有“不失真”的等级。N-MOS的得分一可具有“极其干扰”的等级;二可具有“略微干扰”的等级;三可具有“明显但不干扰”的等级;四可具有“稍微明显”的等级;及五可具有“不明显”的等级。G-MOS的得分一可具有“不良”的等级;二可具有“不佳”的等级;三可具有“一般”的等级;四可具有“良好”的等级;及五可具有“极佳”的等级。图3为说明使用感知客观收听质量评估(P.OLQA)的现行ITU标准的预测MOS的精确性的图表。图表的X轴对应于话语信号的MOS319等级且Y轴对应于话语信号的P.OLQA317等级。P.OLQA为用于通过数字分析预测话语信号的质量的标准。图3中的图表比较话语信号的P.OLQA得分与P.800得分(MOS)。如果P.OLQA分析正确地预测得分,那么得分应匹配或接近话语信号的MOS。图表中的对角线指示如果P.OLQA得分与MOS接近点应在的位置。图3中的图表指示现行P.OLQA分析并未始终与话语信号的MOS等级一致。通常,已经历增强型可变速率声码器(EVRC)修改的话语信号的P.OLQA等级可如图表中所展示的进行预测。EVRC修改后的话语信号结果经展示为菱形和正方形。图4为说明用于测量话语信号质量的方法400的一个配置的流程图。方法400可通过电子装置执行。电子装置的实例包含移动装置(例如、智能手机、蜂窝式电话、平板计算机裝置、膝上型计算机等)、桌上型计算机、个人数字助理(PDA)、电气设备、电视、游戏系统及服务器(例如,包含于网络装置中的服务器)。电子装置可任选地获得原始话语信号402。举例来说,电子装置可通过一或多个麦克风捕获话语信号或可从另一装置(例如,存储装置、计算机、电话、头戴式耳机等)接收话语信号。原始话语信号可为未加工或未修改的信号。举例来说,原始话语信号可为尚未编码及/或压缩的话语信号的电子采样版本。获得原始话语信号的途径可被称为侵入性途径或方法。举例来说,侵入性途径可包含原始话语信号与修改后的话语信号(例如失真话语信号)之间的明确差分。在其它途径中,可能未获得原始话语信号。这些途径可被称为非侵入性途径或方法。在非侵入性途径中,举例来说,可能不可获得原始话语信号(例如,可能没有修改后的话语信号与原始话语信号之间的明确差分)。举例来说,在一些实施及/或情形中,方法400可在无需获得原始话语信号的情况下执行。具体来说,当没有‘原始’或‘纯净’信号可用于比较时,特征可尤其易受到预测质量的影响。不需要原始/纯净信号的此类系统被称为非侵入性系统。如上文所描述,耳蜗的计算模型可为将话语信号精确地转换为内毛细胞反应的液压机械模型。因此,非侵入性特征可从耳蜗模型提取以用于感知域中的话语和音频信号分析。还可使用其它类似模型。在一些配置中,电子装置可处理原始话语信号以获得修改后的话语信号。举例来说,电子装置可对原始话语信号进行编码(例如,及/或对所得经编码话语信号进行解码)以获得修改后的话语信号。另外或或者,电子装置可增强原始话语信号以获得修改后的话语信号。举例来说,电子装置可对原始话语信号的噪声注入版本执行噪声抑制。电子装置可获得修改后的单声道话语信号404。“单声道”话语信号可表示在任何一个时间作为(例如,压力的)单一样本的话语信号。举例来说,修改后的单声道话语信号可不含有提供空间辨别信息的多个信号。在一些配置中,举例来说,修改后的单声道话语信号可基于通过单一麦克风捕获的原始话语信号。在其它配置中,电子装置可从另一装置(例如,存储装置、计算机、电话、头戴式耳机、编码器、等)获得修改后的话语信号。举例来说,电子装置可从连网电子装置接收修改后的话语信号。修改后的话语信号可基于原始话语信号。举例来说,修改后的话语信号可为原始话语信号的失真版本。原始话语信号的增强、编码、解码、噪声抑制、扩展及压缩可使原始话语信号失真,使得修改后的话语信号的一或多个特性与原始话语信号的那些不同。在一些配置中,电子装置可使用如本文所描述的生理模型(例如,生理耳蜗模型)处理修改后的话语信号。使用生理模型处理修改后的话语信号可更准确地近似于通过人类听觉系统执行的处理(例如,与功能模型相比)。此可有助于更精确地估计如通过人类收听者感知的话语信号质量。举例来说,使用生理模型处理修改后的话语信号可提供内毛细胞数据。内毛细胞数据与基底膜数据之间的差异在于内毛细胞数据从人类听觉系统中比基底膜数据靠后的数据采集点采集,且因此经受进一步处理,除在基底膜处发现的内容以外。大部分功能模型基本上近似于基底膜反应且几个其它功能模型延续到以连续方式近似于的内毛细胞反应,但这些功能模型中的无一者以整体方式处理整个耳蜗(生理结构、流体等)系统,其中生理组分的每一部分以前馈和后馈方式取决于彼此。本文所公开的系统和方法可使用内毛细胞数据、基底膜数据或两种数据类型应用。电子装置可基于修改后的话语信号估计多个客观失真406。举例来说,客观失真可为表示修改后的话语信号中的失真的一或多个度量值(例如,原始话语信号与修改后的话语信号之间的差异)。在一些实施方案中,电子装置可另外基于原始话语信号估计多个客观失真。举例来说,多个客观失真中的一或多者可基于修改后的话语信号、原始话语信号或修改后的话语信号和原始话语信号两者。举例来说,在一些方法中,可同时估计多个客观失真。在一些配置中,多个客观失真中的每一者可表示话语质量的独立维度。举例来说,失真中的每一者可根据人类收听者反馈与彼此近似地不相关。举例来说,人类收听者可检测话语信号中的单独失真。换句话说,考虑到用来描述失真的许多描述词,人类收听者往往会将类似得分指派至话语质量的相关维度。在一个实例中,提供给人类收听者描述词“混乱”、“刺耳”、“发颤”、“间断”、“沉闷”、“低沉”、“稀疏”、“微弱”、“呼啸”、“轰鸣”、“咆哮”、“断续”、“间歇”及“可变”以描述失真。在此实例中,人类收听者往往会将类似得分指派至“混乱”和“刺耳”;“发颤”和“间断”;“沉闷”和“低沉”;“稀疏”和“微弱”;“呼啸”、“轰鸣”及“咆哮”;及“断续”、“间歇”及“可变”。因此,这些描述词可分组到话语质量的不相关或独立维度中。在一些配置中,“粗糙度”失真可对应于“混乱”和“刺耳”描述词。话语信号的粗糙度可为话语信号的快速暂时局部衰减。粗糙度可为时间前景失真。“不连续性”失真可对应于“发颤”和“间断”描述词。话语信号的不连续性可为话语信号的缓慢暂时局部衰减。不连续性可为时间前景失真。“枯燥度”失真可对应于“沉闷”和“低沉”描述词。话语信号的枯燥可为话语信号的高频段中的衰减。枯燥可为频谱(例如频率)前景失真。“稀薄度”失真可对应于“稀疏”和“微弱”描述词。话语信号的稀疏度可为话语信号的低频段中的衰减。稀薄度可为频谱前景失真。“呼啸”失真可对应于“呼啸”、“轰鸣”及“咆哮”描述词。话语信号的呼啸可为归因于话语信号中的背景噪声的程度的衰减。“变化性”失真可对应于“断续”、“间歇”及“可变”描述词。话语信号的变化性可为归因于话语信号中的噪声的变化性的衰减。这些失真中的每一者可表示话语质量的独立维度。多个客观失真中的每一者可经评定且经提供得分。得分可指示失真的程度,多个客观失真中的每一者可导致话语信号。应注意,其它术语可用于话语质量的独立维度。举例来说,ITU标准P.806提供密切对应于多个客观失真的感知质量(PQ)量表。PQ量表包含S-FLT、S-RUF、S-LFC、S-HFC、B-LVL及B-VAR。S-FLT是指话语信号中的缓慢变化衰减(不连续性)。S-RUF是指话语信号中的快速变化衰减(粗糙度)。S-LFC是指话语信号中的低频着色的衰减(枯燥度)。S-HFC是指话语信号中的高频着色的衰减(稀薄度)。B-LVL是指归因于话语信号中的背景噪声的程度的衰减(呼啸)。B-VAR是指归因于话语信号中的背景噪声的变化性的衰减(变化性)。还可注意到,P.806包含响度的LOUD得分且OVRL为整体质量的得分。OVRL可与P.800中的MOS及P.835中的G-MOS相同。在一些配置中,多个客观失真可包含至少一个前景失真及/或至少一个背景失真。举例来说,多个客观失真可包含四个前景失真和两个背景失真。四个前景失真可包含“粗糙度”、“不连续性”、“枯燥度”及“稀薄度”。两个背景失真可包含“呼啸”和“变化性”。前景失真可为归因于话语信号中的话语的衰减的话语信号的失真。背景失真可为归因于话语信号中发现的噪声的话语信号的失真。因此,本文所公开的系统和方法可利用时间和频谱失真两者。电子装置可基于多个客观失真估计前景质量和背景质量408。前景失真可为由计算前景质量估计器接收,且随后计算前景质量估计器可使用本文所描述的方法和程序计算话语信号的前景质量。前景质量为指示对应于前景失真的修改后的话语信号的质量的度量值,所述度量值可对应于ITU标准P.835的S-MOS得分。背景失真可由计算背景质量估计器接收,且随后计算背景质量估计器可使用本文所描述的方法和程序计算话语信号的背景质量。背景质量为指示对应于背景失真的修改后的话语信号的质量的度量值,所述度量值可对应于ITUP.835的N-MOS得分。电子装置可基于前景质量和背景质量估计整体质量410。举例来说,电子装置可产生使用本文所公开的方法和程序估计修改后的话语信号的整体质量的度量值。此整体质量可为基于前景质量和背景质量的客观量度。此整体质量还可近似于话语质量的主观量度。举例来说,整体质量可近似于主观收听者的平均意见分(MOS)。举例来说,整体质量可近似于根据国际电信联盟(ITU)标准P.800、及/或P.835及/或P.806取得的主观量度。在一些配置中,估计整体质量可进一步直接基于多个客观失真。举例来说,电子装置可直接基于除前景质量和背景质量以外的多个客观失真(例如,而非通过前景质量和背景质量仅间接基于多个客观失真)估计整体质量。换句话说,整体质量可基于前景质量、背景质量、粗糙度得分、不连续性得分、枯燥度得分、稀薄度得分、呼啸得分及变化性得分。换句话说,如果整体质量基于前景质量、背景质量、粗糙度得分、不连续性得分、枯燥度得分、稀薄度得分、呼啸得分及变化性得分,那么整体质量可取决于这些不同因素。可以一或多个方式应用整体质量。举例来说,可利用整体质量来评价编码器、编码器/解码器(例如,编解码器)及/或噪声抑制器(例如噪声抑制算法)的质量。在一些配置中,可利用整体质量来自动调整通信系统(例如,蜂窝式电话网络)的网络及/或装置设定以改善语音质量。可利用整体质量来设计编码器、编码器/解码器(例如,编解码器)及/或噪声抑制器(例如,噪声抑制算法)。举例来说,整体质量可用于测试某些操作参数以比较解码、编码及噪声抑制。本文所公开的系统和方法可提供近似主观量度的整体质量的客观量度。本文所公开的系统和方法的一些优势包含成本降低。举例来说,可更快速且在无需人类收听者的情况下估计整体质量。另外,此处整体质量估计可重复,然而主观方法可能不提供一致结果。根据本文所公开的系统和方法确定的整体质量估计可基于多个客观失真(例如,话语质量的多个维度),然而其它客观途径为单维度。因此,与其它客观途径(例如,ITU标准P.863(P.OLQA))相比,根据本文所公开的系统和方法的整体质量估计可更精确地近似于主观量度(例如,MOS)。测量话语信号质量(如结合图4所描述)可根据分层结构而执行。分层结构可包含多个分层层次,其中每一分层层次取决于任何及每一相对较低分层层次。举例来说,多个分层层次可包含三个层次。第一分层层次(例如,最低分层层次)可包含估计多个客观失真。第二分层层次可包含估计前景质量和背景质量。第三分层层次(例如,最高分层层次)可包含估计整体质量。因此,第二分层层次可基于第一分层层次,且第三分层层次可基于第二分层层次且(至少间接基于)第一分层层次。因此,基于多个客观失真估计前景质量和背景质量,且基于前景质量和背景质量估计整体质量。根据本文所公开的系统和方法使用多个分层层次可在诊断及解决话语信号发射问题的方面产生改善。举例来说,如果话语信号质量可接受,那么整体质量经提供且为用来验证的数据的单一点。然而,如果话语信号质量不可接受,那么话语信号可使用前景质量数据和背景质量数据经进一步分析。如果背景质量数据指示背景质量不可接受,那么对应于前景质量的四个多个客观失真立即被排除。可随后使用对应于背景质量的多个客观失真进一步分析话语信号。应注意,如通过本文所公开的系统和方法提供的测量话语信号质量(及/或包含其中的一或多个程序)本质上可具有预测性。举例来说,如果实际上执行主观收听测试,那么“估计”整体质量可包含预测主观质量量度(例如,MOS)将是什么。还应注意,然而收听测试不必根据本文所公开的系统和方法。换句话说,本文所公开的系统和方法可在无需与客观结果比较的主观收听测试的情况下执行。图5为说明经配置以用于测量话语信号质量的电子装置556的一个配置的框图。电子装置可执行结合图4所描述的方法400的程序中的一或多者。电子装置556包含与任选的计算前景质量估计器540和任选的计算背景质量估计器542耦合的计算失真估计器526及/或计算整体质量估计器552。当硬件耦合时,组件直接或间接地连接。举例来说,如果第一组件耦合到第二组件,那么所述组件可具有直接连接或所述连接中的介入组件可存在。电子装置556及/或其一或多个组件可在硬件(例如,电路)、软件或两者的组合中实施。电子装置556的实例包含移动装置(例如,智能手机、蜂窝式电话、平板计算机裝置、膝上型计算机等)、服务器(例如,包含于网络装置中的服务器)及软件电话裝置(例如,讯佳普、FaceTime等)。电子装置556(例如,及/或计算失真估计器526)可获得修改后的单声道话语信号524。在一些实施及/或情形中,电子装置556可另外获得原始话语信号512。在其它实施方案及/或情形中,电子装置556可不获得原始话语信号512。此操作可如上文结合图4所描述来实现。计算失真估计器526可基于修改后的单声道话语信号524(及/或任选地基于原始话语信号512)估计多个客观失真。失真为客观的,因为收听者未主观地评价失真。在一些实施及/或情形中(例如,在非侵入性途径中),计算失真估计器526可在无需原始话语信号512的情况下估计多个客观失真。此操作可如上文结合图4所描述来实现。举例来说,计算失真估计器526可基于修改后的单声道话语信号524及/或原始话语信号512估计粗糙度528、不连续性530、枯燥度532、稀薄度534、呼啸536及/或变化性538。计算失真估计器526可利用计算算法来执行客观失真估计。此可为“客观”的,因为主观人类收听者并不确定失真估计。在一些配置中,多个客观失真中的一或多者可提供至计算前景质量估计器540。此操作可如上文结合图4所描述来实现。举例来说,粗糙度528、不连续性530、枯燥度532及稀薄度534失真可提供至计算前景质量估计器540。计算前景质量估计器540可基于多个客观失真(例如,粗糙度528、不连续性530、枯燥度532及稀薄度534失真)估计前景质量550。前景质量550可提供至计算整体质量估计器552。在一些配置中,多个客观失真中的一或多者可提供至计算背景质量估计器542。此操作可如上文结合图4所描述来实现。举例来说,呼啸536及变化性538失真可提供至计算背景质量估计器542。计算背景质量估计器542可基于多个客观失真(例如,呼啸536和变化性538失真)估计背景质量548。背景质量548可提供至计算整体质量估计器552。计算整体质量估计器552可基于前景质量550和背景质量548估计整体质量554。此操作可如上文结合图4所描述来实现。举例来说,计算整体质量估计器552可基于前景质量550和背景质量548估计整体质量554。在另一实例中,计算整体质量估计器552可直接基于除前景质量550和背景质量548以外的粗糙度528、不连续性530、枯燥度532、稀薄度534、呼啸536及/或变化性538失真估计整体质量554。应注意,电子装置556可根据如结合图4所描述的分层结构测量话语信号质量。图6为说明可根据本文所公开的系统和方法实施的分层结构600的一个实例的框图。图6中所图示的分层结构600为侵入性途径的一个实例。在一些配置中,可从原始话语信号612和修改后的话语信号624提取656特征。举例来说,原始话语信号612和修改后的话语信号624可提供至将人类耳蜗模型化的耳蜗建模器。耳蜗模型修改原始话语信号612修改后的话语信号624以接近人类耳蜗在听觉处理中的效果。在此分层结构600中,可基于原始话语信号612(例如,耳蜗模型化原始话语信号)和修改后的话语信号624(例如耳蜗模型化修改后的话语信号)估计多个客观失真。在一个实例中,失真可包含粗糙度628、不连续性630、枯燥度632、稀薄度634、呼啸636及/或变化性638失真。如上文所描述,粗糙度628失真可对应于“混乱”和“刺耳”描述词。粗糙度628失真可由粗糙度模块658确定。不连续性630失真可对应于“发颤”和“间断”描述词。不连续性630失真可由不连续性模块660确定。枯燥度632失真可对应于“沉闷”和“低沉”描述词。枯燥度632失真可由枯燥度模块662确定。稀薄度634失真可对应于“稀疏”和“微弱”描述词。稀薄度634失真可由稀薄度模块664确定。呼啸636失真可对应于“呼啸”、“轰鸣”及“咆哮”描述词。呼啸636失真可由呼啸模块666确定。变化性638失真可对应于“断续”、“间歇”及“可变”描述词。变化性638失真可由变化性模块668确定。粗糙度628、不连续性630、枯燥度632及稀薄度634失真可被分类为前景失真。呼啸636和变化性638失真可被分类为背景失真。如上文所描述,可基于粗糙度628、不连续性630、枯燥度632及稀薄度634失真任选地估计前景质量650。此外,可基于呼啸636和变化性638失真任选地估计背景质量648。如结构中所图示,整体质量654可直接基于前景质量650和背景质量648。任选地,整体质量654可直接基于除前景质量650和背景质量648以外的多个客观失真。个别失真的客观得分可合成为两个整体得分:一者针对前景质量650且另一者针对背景质量648。举例来说,前景质量650可表示信号质量(SIG、SGN)且背景质量648可表示为背景质量436(BGN)。前景质量650和背景质量648得分可合成为一个最终整体质量654得分。整体质量654可表示为整体质量654(MOS)。一些可能合成途径作为(但不限于)以下内容提供:线性回归(例如,MOS=b2×SIG+b1×BGN+b0)或非线性回归(例如,MOS=b4×SGN2+b3×SGN+b2×BGN2+b1×BGN+b0)。本文所公开的统和方法可针对受测试的每一话语信号提供三个层次的客观得分,所述客观得分可提供关于话语质量失真的较多细节,例如高频失真和背景噪声的程度。另外,本文所公开的系统和方法可使算法的开发更容易。举例来说,开发者可集中于某些类型的属性/失真且因此减小探究的因素范围。本文所公开的系统和方法还可提供关于整体质量654的改善的预测的精确性。举例来说,当从若干个别得分合成时,与直接基于单一得分预测其相比,整体质量654的预测可更精确。分层结构600可通过电子装置556实施,所述电子装置例如无线通信装置,也称为移动装置、移动台、订户台、客户端、客户端站、用户设备(UE)、远程站、接入终移动终终端用户终订户单元等。电子装置556的其它实例包含膝上型计算机或桌上型计算机、蜂窝式电话、智能手机、无线调制解调器、电子书阅读器、平板计算机裝置、游戏系统等。此外,现有系统和方法可用于基站、执行自适应噪声抵消的电子装置556等。由分层结构600确定的整体质量654可针对提供的话语部分模拟人类主观评分。换句话说,分层结构600可基于经训练的数据而不是需要人类收听者140a至140c实时提供主观得分而确定整体质量654。为了做到这一点,分层结构600可使用从修改后的话语信号或原始话语信号612提取的特征656来分离不同失真。所述特征可用于确定多个客观失真维度中的每一者的预测得分。图7为说明可根据本文所公开的系统和方法实施的分层结构700的另一实例的框图。图7中所图示的分层结构700为非侵入性途径的一个实例。在此实例中所描述的元件可类似于如结合图6所描述的对应元件。在此实例中,然而,特征可被提取且失真可基于修改后的话语信号724(例如,无需原始话语信号612)而确定。在此分层结构700中,可基于修改后的话语信号724(例如,耳蜗模型化修改后的话语信号)估计多个客观失真。在一个实例中,失真可包含粗糙度728、不连续性730、枯燥度732、稀薄度734、呼啸736及/或变化性738失真。如上文所描述,粗糙度728失真可对应于“混乱”和“刺耳”描述词。粗糙度728失真可由粗糙度模块758确定。不连续性730失真可对应于“发颤”和“间断”描述词。不连续性730失真可由不连续性模块760确定。枯燥度732失真可对应于“沉闷”和“低沉”描述词。枯燥732失真可由枯燥度模块762确定。稀薄度734失真可对应于“稀疏”和“微弱”描述词。稀薄度734失真可由稀薄度模块764确定。呼啸736失真可对应于“呼啸”、“轰鸣”及“咆哮”描述词。呼啸736失真可由呼啸模块766确定。变化性738失真可对应于“断续”、“间歇”及“可变”描述词。变化性738失真可由变化性模块768确定。粗糙度728、不连续性730、枯燥度732及稀薄度734失真可被分类为前景失真。呼啸736和变化性738失真可被分类为背景失真。如上文所描述,可基于粗糙度728不连续性730、枯燥度732及稀薄度734失真任选地估计前景质量750。此外,可基于呼啸736和变化性738失真任选地估计背景质量748。如结构中所图示,整体质量754可直接基于前景质量750和背景质量748。任选地,整体质量754可直接基于除前景质量750和背景质量748以外的多个客观失真。个别失真的客观客观可合成为两个整体得分:一者针对前景质量750且另一者针对背景质量748。举例来说,前景质量750可表示信号质量(SIG,SGN)且背景质量748可表示为背景质量436(BGN)。前景质量750和背景质量748得分可合成为一个最终整体754得分。整体质量754可表示为整体质量754(MOS)。一些可能合成途径作为(但不限于)以下内容提供:线性回归(例如,MOS=b2×SIG+b1×BGN+b0)或非线性回归(例如,MOS=b4×SGN2+b3×SGN+b2×BGN2+b1×BGN+b0)。本文所公开的统和方法可针对受测试的每一话语信号提供三个层次的客观得分,所述客观得分可提供关于话语质量失真的较多细节,例如高频失真和背景噪声的程度。另外,本文所公开的系统和方法可使算法的开发更容易。举例来说,开发者可集中于某些类型的属性/失真且因此减小探究的因素范围。本文所公开的系统和方法还可提供关于整体质量654的改善的预测的精确性。举例来说,当从若干个别得分合成时,与直接基于单一得分预测其相比,整体质量754的预测可更精确。分层结构700可通过电子装置556实施,所述电子装置例如无线通信装置,也称为移动装置、移动台、订户台、客户端、客户端站、用户设备(UE)、远程站、接入终移动终终端用户终订户单元等。电子装置556的其它实例包含膝上型计算机或桌上型计算机、蜂窝式电话、智能手机、无线调制解调器、电子书阅读器、平板计算机裝置、游戏系统等。此外,现有系统和方法可用于基站、执行自适应噪声抵消的电子装置556等。由分层结构700确定的整体质量754可针对提供的话语部分模拟人类主观评分。换句话说,分层结构700可基于经训练的数据而不是需要人类收听者140a至140c实时提供主观得分而确定整体质量754。为了做到这一点,分层结构700可使用从修改后的话语信号或原始话语信号712提取的特征756来分离不同失真。所述特征可用于确定多个客观失真维度中的每一者的预测得分。图8为说明用于基于所提取的特征856a和一或多个训练语音样本868预测主观质量测量得分的一个单一维度的方法800的框图。训练数据库882可包含一或多个训练语音样本868,从所述语音样本提取特征856a。训练数据库882还可包含一或多个训练语音样本868的对应主观得分872。这些可使用主观人类收听者方法采集,即,其中许多人类收听者104a至104c分别被要求收听一或多个训练语音样本868,且随后要求以一或多个类别对一或多个训练语音样本868进行评定。在一个配置中,训练数据库882可包含针对一或多个训练语音样本868在图5中所图示的失真维度(即,粗糙度528、不连续性530、枯燥度532、稀薄度534、呼啸536及变化性538)中的每一者方面的得分。此外,训练数据库882可具有用于许多不同条件(例如,不同编解码器、不同网络技术、不同调制方案等)的一或多个训练语音样本868以及对应主观得分872。可随后基于从一或多个训练语音样本868所提取的特征856a和对应主观得分872估计估计权重870。换句话说,可确定将使从一或多个训练语音样本868所提取的特征856a的估计权重870以产生对应于一或多个训练语音样本868的估计权重870。此训练可在计算整体质量估计器552(例如,如图5中所图示)判定原始话语信号512的一部分的整体质量554之前离线执行。特征的权重874可随后(例如)使用线性回归878算法应用至从一或多个测试语音样本876(即,原始话语512或需要整体质量554的退化话语)所提取的特征856b。一或多个测试语音样本876可位于测试数据库884中。在一个配置中,可通过用于失真维度(即,粗糙度528、不连续性530、枯燥度532、稀薄度534、呼啸536及变化性538)中的每一者的训练数据确定特征的权重874的集合。因此,可通过将特定失真维度的特征的权重874应用至测试语音样本876的所提取的特征856b来确定特定维度的主观得分的预测880。图9为说明对应于图9A至9C的实例的多个部分的框图。权重996(表示为图9C中的向量b)可在训练时间期间确定(例如,在确定整体质量554之前离线)。权重996可在运行时间期间应用至图9B中所展示的话语特征992a至992n(侵入性或非侵入性)以确定话语的整体质量554。具体来说,可为每一失真维度确定权重996(b)的集合。训练数据库882可包含用于如图9A中所展示的N个条件988a至988n的训练语音样本868,每一条件988a至988n对应于不同情况(在所述情况下,接收话语,例如,不同编解码器、不同网络技术、不同调制方案等)的集合。训练数据库882还可包含用于N个条件中的每一者的每一失真维度的主观得分986a至986n。换句话说,对于每一条件,训练数据库可具有6个主观得分872,一者针对每一失真维度。共同地,针对特定失真维度(图9C中的粗糙度)的全部N个条件的主观得分可被称为S。可为特定条件988a至988n确定特征矩阵994中的每一特征向量(例如,FM中的每一列),即,通过分析耳蜗模型输出990a至990n的系列所选部分使用侵入性或非侵入性特征提取。特征向量放置于特征矩阵(FM)994中。因此,如果使用N个条件988a至988n,那么特征向量可具有N列。具体来说,在此实例中,FM994为54xN矩阵,但数据的特定大小可变化。可随后基于特征矩阵994FM和已知主观得分986a至986n(S)估计权重996。换句话说,可确定将使特征矩阵(FM)986产生对应于N个条件988a至988n的主观得分986a至986n(S)的权重996(b)。因此,如图9C中所展示的权重996(b)经计算满足等式(1):FM×b=S(1)其中FM为确定用于训练话语的N个条件988a至988n的特征矩阵994、b为特定失真维度的所需权重996及S为特定失真维度的主观得分986a至986n向量。因此,权重996可根据等式(2)计算:b=FM-1×S(2)其中FM-1为特征矩阵994的倒数。可为每一失真维度确定且为将来预测每一失真维度(即,粗糙度528、不连续性530、枯燥度532、稀薄度534、呼啸536及变化性538)的预测得分保存权重集合996(b)。应注意,等式(2)为理论解决方案。实际上,可存在发现使FM×b最佳地匹配S的“b”的其它方式,例如,多个线性回归。即使此训练可在计算整体质量估计器552(例如,如图5中所图示)判定原始话语信号512的一部分的整体质量554之前离线执行,权重996可随后应用至从整体质量554所需的测试语音样本876提取的特征。图10为说明可实施以用于测量话语信号质量的分层结构1000的一个实例的流程图。分层结构1000可通过电子装置556执行。电子装置556可通过估计修改后的话语信号524的多个客观失真或基于原始话语信号512执行第一分层结构层次1002。举例来说,客观失真可为表示修改后的话语信号524中的失真的一或多个度量值。多个客观失真可表示话语质量的独立维度。举例来说,多个客观话语失真可为粗糙度528、不连续性530、枯燥度532、稀薄度534、呼啸536及变化性538。电子装置556可随后通过估计前景质量550和背景质量548执行第二分层结构层次1004。前景质量550和背景质量548可基于第一分层结构层次中所估计的多个客观失真。换句话说,在第一分层结构层次之前不可执行第二分层结构层次。前景质量550可由前景质量估计器540估计且背景质量548可由背景质量估计器542估计。前景质量550可基于客观失真中的一或多者。举例来说,粗糙度528、不连续性530、枯燥度532及稀薄度534可为前景客观失真。前景质量550可仅使用枯燥度532和稀薄度534或前景客观失真的任何其它可能组合来确定。背景质量548可基于客观失真中的一或多者。背景客观失真可为呼啸536和变化性538。可使用呼啸536和变化性538两者或仅呼啸536或变化性538发现背景质量548。本文所公开的系统和方法可使用客观失真的任何组合。客观失真可不仅仅包含粗糙度528、不连续性530、枯燥度532、稀薄度534、呼啸536或变化性538。电子装置556可随后通过估计话语信号的整体质量554执行第三分层结构层次1006。话语信号的整体质量554可基于前景质量550、背景质量548且和任选地直接基于多个客观失真。换句话说,在第一分层结构层次或第二分层结构层次之前可不执行第三分层结构层次。可通过前景质量550和背景质量548间接使用客观失真以确定整体质量554。另外,客观失真可直接用于确定除前景质量550和背景质量548以外的整体质量554。整体质量554可近似于话语质量的主观量度。图11说明经配置以用于测量话语信号质量的网络装置1101和两个电子装置1156a至1156b的一个配置的框图。网络装置1101可包含话语评估器1198b、自适应模块1103b和反馈模块1105b。网络装置1101无线路由器、服务器、基站、蜂窝电话塔或计算机系统。话语评估器1198b可用于执行本文所公开的方法。话语评估器1198b可包含计算失真估计器526、计算前景质量估计器540、计算背景质量估计器542及计算整体质量估计器552。网络装置1101可从一或多个电子装置1156a至1156b获得一或多个话语信号1107a至1107b。话语信号1107a至1107b可为修改后的话语信号524、原始话语信号512或修改后的话语信号524和原始话语信号512两者。网络装置1101可使用话语评估器1198b来确定在话语信号1107a至1107b中发现的多个客观失真。多个客观失真可用于确定话语信号1107a至1107b的前景质量550和背景质量548。随后可使用前景质量550和背景质量548确定话语信号1107a至1107b的整体质量554。根据话语信号1107a至1107b的整体质量554,网络装置1101可确定需要对处理结构进行更改。更改可由自适应模块1103b进行。举例来说,自适应模块1103b可能能够修改通过网络装置1101完成的编码、解码或转码。自适应模块1103b还可能能够更改为话语信号1107a至1107b分配的带宽或更改网络装置1101的位速率。对于另一实例,电子装置1156a至1156b可将话语信号1107a至1107b发送至网络装置1101。网络装置1101可将相同话语信号1107a至1107b发送至另一电子装置1156a至1156b,在此之后话语评估器1198b可在网络装置1101接收到话语信号1107a至1107b时确定其整体质量554,且在网络装置1101将话语信号1107a至1107b发送至其它电子装置1156a至1156b时确定其整体质量554。如果所发送的话语信号1107a至1107b的整体质量554过低,那么网络装置1101可使用话语评估器1198b来确定由网络装置1101执行的可能已引起衰减的编码。网络装置1101可随后使用自适应模块1103b来将编码方法更改为更好地利用话语信号1107a至1107b执行的一种方法。自适应模块1103b可能仅能够进行此实例中的这些更改,但自适应模块1103b可进行的特定更改可在其它配置方面不同。当网络装置1101连接至一或多个电子装置1156a至1156b时,网络装置1101可进行更改。网络装置1101还可确定可需要进行更广泛的更改,且在电子装置1156a至1156b未连接至网络装置1101时可离线进行这些更改。网络装置1101还可将话语信号1107a至1107b的整体质量554的得分储存在反馈模块1105b中。当网络装置1101的维护及保养完成时,反馈模块1105b可提供话语信号1107a至1107b的整体质量554的得分。使用所存储的整体质量554的得分,可在维护及保养期间对硬件进行某些更改。举例来说,如果在蜂窝电话塔处始终确定话语信号1107a至1107b的整体质量554过低,那么可更新蜂窝电话塔的硬件或替换为更新的硬件。反馈模块1105b还可将反馈提供至连接至网络装置1101的一或多个电子装置1156a至1156b。反馈可包含网络装置1101接收到话语信号1107a至1107b时其整体质量554的得分,且还可包含网络装置1101将话语信号1107a至1107b发送至另外电子装置1156a至1156b时其整体质量554的得分。反馈可指示网络装置1101可能不是话语信号1107a至1107b的话语信号衰减的原因。提供至一或多个电子装置1156a至1156b的反馈还可展示话语信号在最初从电子装置1156a至1156b发射时整体质量554较低,可能指示网络装置1101可能不是信号衰减的原因。反馈可指示电子装置1156a至1156b可改善所发射的话语信号1107a至1107b的整体质量554的方式。举例来说,反馈可指示由电子装置1156a至1156b执行的话语信号1107a至1107b的压缩并未正确地运行。电子装置1156a可包含话语评估器1198a、自适应模块1103a及反馈模块1105a。话语评估器1198a可用于执行本文所公开的方法。电子装置1156a可获得话语信号1107a或将其发射至网络装置1101。话语信号1107a可为修改后的话语信号524、原始话语信号512或修改后的话语信号524和原始话语信号512两者。电子装置1156a可使用话语评估器1198a来确定话语信号1107a的多个客观失真和整体质量554。自适应模块1103a可基于话语信号1107a的整体质量554更改电子装置1156a的性能。反馈模块1105a可将关于整体质量554和由电子装置1156a正在执行的处理的类型的运营商反馈提供至网络装置1101。因此,本文所公开的系统和方法可提供智能手机及/或其它装置的客观质量(及话语质量缺陷的相关诊断)的量度(例如,使得用户及/或网络提供商可能能够得到其语音会话的质量的‘度量值’)。与上文类似,质量的这些度量值还可包含于软件电话应用(例如讯佳普)中。图12为说明经配置以用于测量话语信号质量的电子装置1256一个配置的框图。电子装置1256可为计算机系统、游戏系统、服务器或移动装置。电子装置1256还可为在一起工作的一或多个电子装置1256。即蓝牙头戴式耳机、噪声消除头戴式耳机、移动装置或扬声器。电子装置1256可包含话语评估器1298、自适应模块1203及显示器1205。话语评估器1298可包含计算失真估计器526、计算前景质量估计器540、计算背景质量估计器542及计算整体质量估计器552。话语评估器1298可用于确定电子装置1256正在发送及接收的一或多个话语信号的多个客观失真、前景质量550、背景质量548及整体质量554。举例来说,电子装置1256可为正在接收来源于不同无线通信服务提供商的话语信号的移动装置。话语评估器1298可在由电子装置1256接收时确定话语信号的整体质量554。话语评估器1298可随后将反馈发送至网络装置1101,以比较由移动装置接收的话语信号的整体质量554与当话语信号首先由无线通信服务提供商的网络内的网络装置1101接收时话语信号的整体质量554。电子装置1256还可能能够使用自适应模块1203调整其性能及处理参数。自适应模块1203可能能够修改由电子装置1256完成的编码、解码或转码。自适应模块1203还可能能够更改为一或多个话语信号分配的带宽或更改电子装置1256的位速率。举例来说,话语信号的整体质量554可能过低且自适应模块1203可确定电子装置1256应增大天线功率。增大天线功率可改善蜂窝塔与电子装置1256之间的连接。话语评估器1298可确定整体质量554的新得分可接受,且自适应模块1203可指示电子装置1256继续使用增大的天线功率。对于另一实例,电子装置1256可为噪声消除头戴式耳机的集合。噪声消除头戴式耳机可执行有源噪声消除,其中头戴式耳机确定使用多个客观失真正在抑制什么噪声及允许什么噪声。如果失真中的一或多者使话语信号衰减,那么噪声消除头戴式耳机可使用位于自适应模块1203内的有源噪声抑制来调整正在取消的噪声及允许什么噪声。电子装置1256可在电子装置1256处使用显示器1205来展示整体质量554的得分。显示器1205可展示话语信号的多个客观失真得分、前景质量550、背景质量548或整体质量554。此信息可由电子装置1256的操作员或在维护期间使用,以修改或升级电子装置1256的硬件或处理参数。显示器1205上提供的信息还可用于展示话语信号由网络装置1101接收到时其整体质量554。此信息可允许电子装置1256的操作员了解话语信号的衰减正在电子装置1256上发生或其正在网络装置1101上发生,或当话语信号由网络装置1101接收到时其已经衰减。图13为说明通过电子装置1256实施以用于测量话语信号质量的方法1300的流程图。方法1300可通过电子装置1256(例如,结合图11和图12所描述的电子装置)执行。电子装置1256的实例包含移动装置(例如,智能手机、蜂窝式电话、平板计算机裝置、膝上型计算机等)、桌上型计算机、个人数字助理(PDA)、电气设备、电视、游戏系统及服务器(例如,包含于网络装置中的服务器)。电子装置1256可获得话语信号1302。话语信号可为修改后的话语信号524、原始话语信号512或修改后的话语信号524和原始话语信号512两者。电子装置1256可基于话语信号使用话语评估器1298来确定多个客观失真1304。即粗糙度528、不连续性530、枯燥度532、稀薄度534、呼啸536及变化性538。电子装置1256可随后任选地将运营商反馈发送至网络装置1101(1306)。运营商反馈可包含多个客观失真分析或可为仅多个客观失真得分。运营商反馈可通过电子装置1256、网络装置1101或电子装置1256和网络装置1101两者上的适应过程用于改善话语信号的质量。图14为说明通过网络装置1101实施以用于测量话语信号质量的方法1400的流程图。方法可通过网络装置1101(例如结合图11所描述的网络装置)执行。网络装置1101的实例包含桌上型计算机、服务器及蜂窝塔。网络装置1101可获得话语信号1402。话语信号可为修改后的话语信号524、原始话语信号512或修改后的话语信号524和原始话语信号512两者。网络装置1101可基于话语信号使用话语评估器1198b来确定多个客观失真1404。即粗糙度528、不连续性530、枯燥度532、稀薄度534、呼啸536及变化性538。网络装置1101可随后基于多个客观失真任选地确定适应话语信号处理的一个或多个方面1406。举例来说,网络装置1101可确定由网络装置1101在首先获得话语信号时执行的解码并不充分。网络装置1101可随后任选地将反馈提供至连接至网络装置1101的电子装置1156a至1156b(1408)。反馈可指示网络装置1101为改善多个客观失真中的一或多者正在进行的调适。电子装置1156a至1156b可随后相应地进行调适以允许在网络装置1101与电子装置1156a至1156b之间继续通信。图15为说明用于特征提取的电子装置的一个配置的框图。电子装置1507可包含特征提取模块1529。电子装置1507及/或其一或多个组件可在硬件(例如,电路)或硬件与软件的组合中实施。另外或或者,术语“模块”可表示在硬件(例如,电路)或硬件与软件的组合中实施的组件。举例来说,特征提取模块1529可在硬件(例如,电路)中或在硬件与软件的组合(例如,具有可执行指令的处理器)中实施。图中的一或多者中所描绘的线或箭头可表示组件及/或模组之间的耦合。“耦合”可为导向或间接。举例来说,一个模块可直接(无需任何介入组件)或间接(利用一或多个介入组件)耦合到另一模块。电子装置1507的实例包含移动装置(例如,智能手机、蜂窝式电话、平板计算机裝置、膝上型计算机等)、计算机(例如,桌上型计算机)、网络装置(例如,基站、路由器、交换机、网关、服务器等)、电视、机动车电子装置(例如,整合到机动车的控制台的电子装置)、游戏系统、电子电气设备等。在一些配置中,电子装置1507可包含结合图5所描述的电子装置556的组件中的一或多者,及/或可执行所述电子装置的功能中的一或多者。特征提取模块1529可基于修改后的话语信号1511确定一或多个特征1527。在一些配置中,确定一或多个特征1527可基于修改后的话语信号1511和原始话语信号1509两者。电子装置1507可任选地获得原始话语信号1509。举例来说,电子装置1507可通过麦克风捕获话语信号或可从另一装置(例如,存储装置、计算机、电话、头戴式耳机等)接收话语信号。原始话语信号1509可为未加工或未处理的信号。举例来说,原始话语信号1509可为尚未修改(例如,衰减、失真、编码、压缩、解码、处理等)的话语信号的电子采样版本。获得原始话语信号1509的途径可被称为侵入性途径或方法。举例来说,侵入性途径可包含原始话语信号1509与修改后的话语信号1511(例如,已处理、衰减、失真、增强等的话语信号)之间的明确差分。在其它途径中,可不获得原始话语信号1509。这些途径可被称为非侵入性途径或方法。在非侵入性途径中,举例来说,可能不可获得原始话语信号1509(例如,可能没有修改后的话语信号1511与原始话语信号1509之间的明确差分)。举例来说,在一些实施及/或情形中,可在无需获得原始话语信号1509的情况下利用本文所公开的系统和方法。可利用侵入性及/或非侵入性途径以客观地测量话语质量(例如,失真-维度)。可如本文所描述的根据所提供的应用提取话语的有声及/或无声部分的特征。举例来说,两组特征可位于感知域中且因此可自然地适合于话语质量测量。应注意,并非所有特征对于本文所公开的系统和方法的应用可为必需的。简单合成过程可用于训练和预测及/或复杂过程可用于改善。描述的大量特征考虑广泛范围的话语失真。可利用映射模型来将所提取的特征映射至某些类型失真得分。一个简单途径使用线性回归,如本文所描述。高次线性回归或更复杂的模型(例如神经网路)还可用来将所提取的特征映射至预测得分。对于所提供的应用,可利用训练过程来设定恰当映射模型的参数及/或权重。举例来说,可达到优化权重,其产生具有最少针对主观得分的错误的预测。经训练模型可随后直接应用至失真信号(例如,不在训练池中)。举例来说,经训练映射模型可被提供从待测试话语提取的特征以实现话语质量得分的预测。电子装置1507可获得修改后的话语信号1511。在一些配置中,电子装置1507可处理原始话语信号1509以获得修改后的话语信号1511。举例来说,电子装置1507可对原始话语信号1509进行编码(例如,及/或对所得经编码话语信号进行解码)以获得修改后的话语信号1511。另外或或者,电子装置1507可增强原始话语信号1509以获得修改后的话语信号1511。举例来说,电子装置1507可对原始话语信号1509的噪声注入版本执行噪声抑制。“单声道”话语信号可表示在任何一个时刻作为(例如,压力的)单一样本的哦话语信号。举例来说,单声道话语信号可不含有提供空间辨别信息的多个信号。在一些配置中,举例来说,修改后的话语信号1511可基于通过单一麦克风捕获的原始话语信号1509。在一些配置中,电子装置1507可从另一装置(例如,存储装置、计算机、电话、头戴式耳机、编码器等)获得修改后的话语信号1511。举例来说,电子装置1507可从连网电子装置接收修改后的话语信号1511。修改后的话语信号1511可基于原始话语信号1509。举例来说,修改后的话语信号1511可为原始话语信号1509的失真版本。增强、编码、解码、转码、发射、接收及/或错误校正原始话语信号1509可使原始话语信号1509失真,使得修改后的话语信号1511的一或多个特性与原始话语信号1509的那些不同。在一些配置中,修改后的话语信号1511及/或原始话语信号1509可拆分成时段(例如,“帧”)。举例来说,修改后的话语信号1511的每一时段可随时间包含的一定数目的样本。时段或帧可为统一长度或可为不同长度。特征提取模块1529可获得修改后的话语信号1511。任选地,特征提取模块1529可另外获得原始话语信号1509。特征提取模块1529可包含生理耳蜗模型1513、区段分析模块1517、向量提取模块1521及/或特征确定模块1525。在一些配置中,特征提取模块1529可包含于结合图5所描述的计算失真估计器526中。在其它配置中,特征提取模块1529可与计算失真估计器526分离或包含所述计算失真估计器。在一些配置中,特征提取模块1529可为结合图6所描述的特征提取模块656的实例及/或可为结合图7所描述的特征提取模块756的实例。电子装置1507(例如,特征提取模块1529)可使用一或多个生理耳蜗模型1513处理话语(例如,修改后的话语信号1511及/或原始话语信号1509)。生理耳蜗模型1513可将耳蜗的一或多个实体组分的反应模型化。举例来说,生理耳蜗模型1513可将耳蜗的内毛细胞(IHC)、耳蜗长度及/或流体力学模型化。使用生理耳蜗模型1513处理话语(例如,修改后的话语信号1511)可更精确地近似于由人类听觉系统执行的处理(例如,与功能模型相比)。此可有助于更准确地估计如通过人类收听者感知的话语信号质量。举例来说,使用生理模型处理修改后的话语信号1511可提供内毛细胞数据。此不同于(例如)使用功能模型粗略估计的基底膜数据。在一些配置中,生理耳蜗模型可为以下等式及描述中的一或多者实施。格林函数积分方程保证在基底膜(BM)速度上的积分等于镫骨质点速度us乘以阶梯高度H(在上壁上正常速度为零)。解算格林函数积分方程为本文所公开的系统和方法的起点。格林函数积分方程通过以下公式给出:其中φ为可能的速度且Vn为利用框内的+定义的速度阶梯的法线分量。以下变量列表可用于本文所公开的方程中:p(x,t);2p(x,t)关于蜗孔的压力;整个BM的压力x沿BM可变的位置,从镫骨测量f频率(Hz)ω弧频率=2πfρ水的密度η水的黏度Kp(x)BM分区硬度参数Rp(x)BM分区电阻mpBM分区质量VohcOHC电压T(Vohc)BM张力xLBM的长度yH耳蜗的高度X(f)耳蜗映射函数(BM位置与频率)Xz(f)第二耳蜗映射函数i√-1ξ(x,t),ξ˙(x,t),ξ¨(x,t)BM质点位移、速度、加速度ζ(x,t),ζ˙(x,t),ζ¨(x,t)纤毛位移、速度、加速度f(x,t)TM力us(t),u˙s(t)镫骨质点速度和加速度(n+1,n,n-1)离散时间(将来、现在、过去)*空间卷积L(t)“瞬时”响度Im,Ip屏蔽器和探测器的强度基本耳蜗方程通过以下公式给出:其中ρ为水的密度、为BM质点加速度、*为空间卷积及为镫骨质点加速度。此方程类似于由艾伦(Allen)和颂提(Sondhi)创建的方程,但经过修改以包含覆膜(TM)力。覆膜力由以下函数定义:其中为BM质点速度。考虑到镫骨加速度方程(4)的积分允许人们发现BM位移ξ(x,t)。然而,由于最终方程不易求解,当继续进行此严格途径时存在严重问题。在艾伦和颂提的方程中,阻抗Zt不存在(即,无穷大)。本公式中新增的TM阻抗产生方程(3)中的四次时间项其具有较小首项系数。此类方程通常被称为僵化微分方程,其具有单一性质。确定p与(即,zp(t))之间的传递函数的次的方式为通过使用拉普拉斯变换。通过忽略纤毛阻抗Zc(x,f)获得近似分区阻抗上标(1)指示修改后的(即,近似)Ztc。写出关于横跨BM的压力-2P(x,s)的随BM位移Ξ(x,s)的完整分区阻抗,得到sZp(x,s):由此表明去除纤毛阻抗仅导致BM阻抗5%的更改。因此,当其将方程的次数从二升高至四时,方程本身充当时间方程中的二次。此产生极不良的数字性质,其必须加入到方程的公式中。此时,平行的TM和纤毛阻抗ztc(x,t)必须被近似估计。在从方程(4)降低相对较大(即,刚性)阻抗zc>>zt之后,可获得最终方程的解。在方程(7)中,Ztc≡Zt||Zc≈Zt的近似值由Zc>>Zt的观测得出。核心函数F(x)作用于BM加速度。还存在与BM加速度成比例的BM阻抗的分量。这两个加速度项必须在可解出方程之前被分组。当阻抗为二次形式时,我们将看到此重组易于完成。在常用案例中如何继续进行不大显而易见,且因此必需求得产生方程(7)的BM阻抗函数的近似值,所述方程为二次因此显示阻抗中的加速度项。阻抗函数为最小相位,且每一最小相位函数(比方说M(S))可以以下形式书写:其中且其中R(s)为对应于通过解算关于R(s)的以上方程发现的M(s)/m0的反射系数。通过以此形式写入阻抗(即,M),且将其以时域表示,有可能形成关于m(t)的递归时域卷积方程,其以及格林函数方程(3)定义耳蜗反应。此表面上复杂的途径为必需的,由于在反相核心函数F时最终耳蜗方程必须考虑阻抗中的加速度分量。经扩增核心由以下方程定义:其中mp≈mO+g2mt和质量项被重写为在空间上具有BM加速度的卷积。此允许质量项和核心被分组。此表示取决于卷积关系:此方程易于验证。由于两者作用于BM加速度可定义经扩增核心以包含核心的阻抗质量项此扩增需要在两个奇异点处的2个差量函数处将质量展开,每一者具有总质量的一半,遵循实数奇调和对称性。就经扩增核心而言,运动的BM方程变成:此通过反相Q(x)求解,其得到:一旦通过方程(13)的积分发现BM位移,考虑到BM位移可通过解算纤毛位移计算纤毛位移,如通过BM至纤毛位移传递函数所描述:或在时域中;[zt(x,t)+zc(x,t)]xθ(x,t)=g(x)zt(x,t)xξ(x,t)(15)为了清晰起见我们重复,尽管当解算方程(13)中的BM位移ξ时忽略zt,在此方程中忽略其是不必要或不恰当的。就方程(13)而言,其为合理化忽略的较小项。在纤毛方程中,其为较大且极其重要的阻抗。有限差离散时间耳蜗方程为:当通过傅里叶变换进行数字空间卷积时,元件的dx长度被定义为Δ≡L/K,其中整数K为两者的功率且L为耳蜗的长度。因此,基底膜座标x=0…L为:xk=kΔ,k=0...K(17)超过长度4L的“奇调和”环形卷积的公式,即对于核心函数样本值Qk与测试函数样本值ξk之间的离散情形,其中k表示空间索引(时间索引n对于此实例为抑制)通过以下公式给出:对于有限频带函数,样本值为在样本时间所求得的函数的简单值,即yξk≡ξ(xk)。当k=0(即x=0)时,核心样本值F0为无穷大幸而此对数奇点为可积分的。因此,我们通过对对数奇点积分、除以Δ定义零点处的样本值。积分可通过扩展泰勒级数中的指数及随后对最低次项积分来完成,得到:以类似方式,经扩增核心中的两个奇异质量项的样本值必须被类似地定义为:从定义中我们发现:而对于1≤k≤K-1:由于奇调和对称性,Qk=Q-k=-Q2K-k。最后核心Q-1的倒数经计算为:Q-1≡F-1[1/FQ](25)其中F为FFT的长度4L。由于流体体积的守恒必须保持,沿BM的体积积分必须等于镫骨体积速度此重要的数值控制可在最终程序中通过将镫骨输入设定为零(即,),且将t=0处的体积速度设定为x=L/2处的一者且传播此起始条件来测试。对于此测试,BM的体积速度必须保持为一直至脉冲达到x=L。解算ξn+1的方程(16),得到:ξn+1=2ξn-ξn-1-T2Q-1*bn(26)其中:方程(26)和(27)为耳蜗反应的最终数字解且表示耳蜗递归方程(BM与流体之间的反馈回路)。可最后通过方程(13)计算出纤毛位移,其为:或以离散时间形式:解算关于Xn的方程(29):在共同项总重新排列:θn=-a1θn-1-a2θn-2+b[ξn+b1ξn-1+b2ξn-2](31)其通过检测定义系数a≡[a1,a2]及b≡[b,b1,b2]:应注意系数向量b与由方程(27)定义的bn不相关。基于脉冲不变性变换,最好通过从s位置至z平面的变换而采取上一个步骤,如拉宾纳(Rabiner)和戈尔德(Gold)所描述。此变换基于数字和类比样本值的不变性。换句话说,ξn≡ξ(nT)确定s至Z域之间的映射。这些脉冲恒定系数更精确,且将数字解扩展至更高频率(即,更接近最高频率、尼奎斯特(Nyquist)取样率的二分之一)。就模拟s平面的极点sp和零点sz而言,二次数字谐振器通常通过脉冲恒定锥形形式定义。此系统具有通过sp=σp±iwp和sz=σz±iwz确定的一对复共轭极点和零点弧频率,且具有由Rp=eσpT和Rz=eσzT定义的阻尼参数。尼奎斯特频率通过fNyquist=1/T与样本时段T相关。这两个系数a、b的集合最好通过模拟域中所定义的辅助参数定义:σp=-0.5(rc+rt)/(mc+mt)(38)σz=-0.5rt/mt(39)g=1(42)基于脉冲不变性产生数字谐振器系数定义:有限差与脉冲不变性系数之间存在简单关系。如果基于脉冲不变性的a2在T至次1的泰勒级数中扩展,那么不大精确的有限差a2产生:为发现系数kt、kc、mt及mc,我们解算以下三个方程,所述方程通过从文献已知的wp(x)、wx(x)及wcf(x)的定义确定:及判定在尾部中的调谐曲线斜率的方程:来自泊肃叶公式的纤毛参数:及最后TM质量方程:(mc+mt)=.02(55)在一些配置中,生理耳蜗模型1513可提供耳蜗长度内的反应数据(例如,内毛细胞数据)。举例来说,一定数目的位置点(例如,样本)可针对话语的每一样本(例如,针对修改后的话语信号1511的每一样本)在耳蜗长度内将生理耳蜗模型1513的反应模型化。位置点可对应于沿耳蜗的长度的位置。沿耳蜗的长度的位置可对应于且响应于特定频率的声音。举例来说,位置点集合中的可对应于第一位置点大约20千赫兹(kHz)范围内的声音,而最后一个位置点可对应于极低频率(例如,12赫兹(Hz))的声音。因此,生理耳蜗模型1513可“重复取样”以便其可产生用于每一话语样本的多个位置点。在一些配置中,生理耳蜗模型1513可产生用于修改后的话语信号1511的每一样本的位置点集合。生理耳蜗模型1513可提供输出1515。输出1515可包含一时间长度内的位置点。举例来说,输出1515可包含用于一时间长度内的每一话语样本的位置点集合。输出1515可提供至区段分析模块1517。区段分析模块1517可分析生理耳蜗模型1513的输出1515的区段。举例来说,区段分析模块1517可将输出1515(例如,输出的部分)分组(例如,拆分)为多个区段1519。区段1519中的每一者可对应于沿耳蜗长度的位置范围。在一些配置中,区段分析模块1517可将输出1515分组为四个区段1519。举例来说,第一区段可包含从1到150的位置点、第二区段可包含从151到275的位置点、第三区段可包含从276到450的位置点及第四区段可包含从451到512的位置点。区段中的每一者可包含一时间长度内的位置点(例如,N个样本)。应注意,可利用其它区段1519大小。区段1519可提供至向量提取模块1521。向量提取模块1521可针对每一区段1519提取向量1523。具体来说,向量提取模块1521可针对每一区段1519提取基于位置的分析向量和基于时间的分析向量。“基于位置的分析向量”为随位置包含多个值的向量。举例来说,向量提取模块1521可通过计算区段1519随时间的平均值(例如,其随位置产生具有多个值的向量)来确定基于位置的分析向量。“基于时间的分析向量”为随时间包含多个值的向量。举例来说,向量提取模块1521可通过计算区段1519随位置的平均值(例如,其随时间产生具有多个值的向量)来确定基于时间的分析向量。向量1523(例如,一或多个基于时间的分析向量和一或多个基于位置的分析向量)可提供至特征确定模块1525。特征确定模块1525可根据每一向量1523(例如,分析向量)确定一或多个特征1527。特征1527可为量化向量1523特性的度量值。特征1527的实例包含平均值(例如,均值)、中值、几何偏移、调和均值、标准差、偏度、变化等。特征确定模块1525可根据每一向量1523确定这些类别的特征1527中的一或多者。在一些配置中,特征确定模块1525可确定每一向量1523的均值、中值、几何偏移、调和均值、标准差及偏度。在一些配置中,电子装置1507可基于一或多个特征1527估计失真。举例来说,电子装置1507可包含基于一或多个特征1527估计一或多个失真的失真估计模块(图中未展示)。举例来说,失真估计模块可基于特征1527中的一或多者及一或多个权重执行回归(例如,线性回归、多项式回归、二次回归、非线性回归等)以估计失真。在一些配置中,电子装置1507可基于如本文所描述的一或多个失真估计一或多个质量(例如,前景质量、背景质量、整体质量等)。图16为说明用于特征提取的方法1600的一个配置的流程图。电子装置1507可执行方法1600的一或多个步骤、功能及/或程序。电子装置1507可使用一或多个生理耳蜗模型1513处理话语(例如,修改后的话语信号1511及/或原始话语信号1509)1602。可如上文所描述而实现此操作。举例来说,电子装置1507可基于修改后的话语信号1511及/或原始话语信号1509确定一或多个生理耳蜗模型1513的反应。举例来说,电子装置1507可确定用于话语信号(例如,修改后的话语信号1511)的每一样本的位置点集合(例如,样本)。生理耳蜗模型1513的输出1515可包含一时间长度内的位置点集合(例如,N个样本)。电子装置1507可分析生理耳蜗模型1513的输出1515的区段1604。可如上文所描述而实现此操作。举例来说,电子装置1507可将输出1515的部分分组(例如,拆分)为多个区段1519(例如,四个区段或另一数目的区段)。区段1519中的每一者可具有特定大小(例如,位置点的数目乘N个样本的数目)。电子装置1507可针对每一区段1519提取向量1523(1606)。具体来说,电子装置1507可针对每一区段1519提取基于位置的分析向量和基于时间的分析向量。可如上文所描述而实现此操作。举例来说,电子装置1507可计算区段1519随时间的平均值以产生基于位置的分析向量1523,且可计算区段1519随位置的平均值以产生基于时间的分析向量1523。电子装置1507可根据每一向量1523(例如,分析向量)确定一或多个特征1527(1608)。可如上文所描述而实现此操作。举例来说,电子装置1507可确定每一向量1523的均值、中值、几何偏移、调和均值、标准差及偏度。图17为说明生理耳蜗模型输出的一个实例的图表。具体来说,图表说明话语的有声部分的生理耳蜗模型输出的一个实例。图表的轴包含位置(在样本中)1735、时间(以毫秒(ms)计)1731及内毛细胞1733(输入语音信号的振幅)。生理耳蜗模型(CM)比心理声学掩蔽模型(PMM)更精确。具体来说,生理耳蜗模型可提供高得多的时空分辨率。生理耳蜗模型实现近似人类感知的声音的测量。此可使得能够确定更好地反映关于话语失真的人类感知的话语质量得分。CM输出的趋势由包含于图表中的两个线1737a至1737b指示。在图17中所图示的实例中,CM输出具有三个轴。时间轴较简单,其中每一输入具有一个输出。图17说明3900至4150毫秒(ms)之间的时间曲线1731。对于具有8千赫兹(kHz)取样率的输入话语,此实际上产生8个点/ms。位置轴1735提供在一起的512个点,其映射(非线性)至15至20000赫兹(Hz)。为了更好地说明,沿位置轴1735从300至400绘制图17。IHC轴1733为输入振幅。图18为说明侵入性特征提取模块1829的一个配置的框图。侵入性特征提取模块1829可为结合图15所描述的特征提取模块1529的一个实例。侵入性特征提取模块1829可包含延迟估计模块1837、耳蜗模型A1813a至B1813b、部分选择模块1843、区段分析模块1817、向量提取模块1821及/或特征确定模块1825。原始话语信号1809和修改后的话语信号1811(例如原始话语信号1809的衰减版本)可用作特征提取的输入。换句话说,侵入性特征提取模块1829可确定一或多个特征1827。一或多个特征1827可用于估计(例如,预测)修改后的话语信号1811的一或多个失真1849。原始话语信号1809的长度及/或修改后的话语信号1811的长度可为一个帧、多个帧或任何合适的时长(例如,1秒、2秒、5秒、10秒等)。另外或或者,原始话语信号1809及/或修改后的话语信号1811的长度可基于话语自身(例如,整个句子)。举例来说,原始话语信号及/或修改后的话语信号1811的长度可为可配置的(例如,由无线网络的运营商及/或用户配置)。原始话语信号1809和修改后的话语信号1811可任选地提供至延迟估计模块1837。延迟估计模块1837可估计原始话语信号1809和修改后的话语信号1811之间的延迟。举例来说,延迟估计模块1837可执行原始话语信号1809与修改后的话语信号1811之间的相关以确定延迟(例如,如果存在延迟)。延迟估计模块1837可延迟修改后的话语信号1811、原始话语信号1809或两者,以将修改后的话语信号1811与原始话语信号1809对齐。举例来说,如果延迟估计模块1837估计修改后的话语信号1811相对于原始话语信号1809延迟一定数目的样本,那么延迟估计模块1837可延迟原始话语信号1809以将原始话语信号1809与修改后的话语信号1811对齐。因此,延迟估计模块1837可提供对齐的原始话语信号1839和对齐的修改后的话语信号1841,其中对齐的原始话语信号1839和对齐的修改后的话语信号1841在时间上对齐(例如,样本)。对齐的原始话语信号1839可提供至耳蜗模型A1813a。对齐的修改后的话语信号1841可提供至耳蜗模型B1813b。耳蜗模型A1813a至B1813b可为结合图15所描述的生理耳蜗模型1513的实例。耳蜗模型A1813a至B1813b可如结合图15所描述的起作用。因此,耳蜗模型A1813a可产生输出A1815a,且耳蜗模型B1813b可产生输出B1815b。人类耳蜗的平均长度大约为3.5厘米(cm),其中耳蜗上的每个点对不同频率起反应。举例来说,上一个位置点可对应于接近于最低可察觉频率且第一位置点可对应于接近于最高可察觉频率。在一些配置中,耳蜗模型A1813a至B1813b可使耳蜗的长度离散为一定数目的位置点(例如,512个位置点或样本)。举例来说,对于原始话语信号1809的每一样本,耳蜗模型A1813a可产生512个位置点,且对于修改后的话语信号1811的每一样本,耳蜗模型B1813b可产生512个位置点。输出A1815a至B1815b可包含样本(例如,N个)范围内的位置点集合。举例来说,输出A1815a可包含对应于原始话语信号1809(例如,对齐的原始话语信号1839)的N个位置点集合,且输出B1815b可包含对应于修改后的话语信号1811(例如,对齐的修改后的话语信号1841)的N个位置点集合。输出A1815a至B1815b可提供至部分选择模块1843。部分选择模块1843可从耳蜗模型A1813a至B1813b的输出A1815a至B1815b中选择部分A1845a至B1845b(例如,“感兴趣的部分”)。举例来说,可选择原始话语信号1809和修改后的话语信号1811的有声部分。举例来说,话语信号的有声部分可包含元音声音,其可明显地促进感知的话语质量。在一些配置中,部分选择模块1843可确定输出A1815a及/或输出B1815b的能量。可选择部分A1845a作为输出A1815a的样本的范围,其中输出A1815a的能量大于第一阈值。可选择部分B1845b作为输出B1815b的样本的范围,其中输出B1815b大于第二阈值。第一和第二阈值可彼此相同或不同。部分选择模块1843可利用其它静音检测(VAD)途径或模块来确定部分A1845a至B1845b。输出A1815a至B1815b或部分A1845a至B1845b可提供至区段分析模块1817。区段分析模块1817可为结合图15所描述的区段分析模块1517的一个实例。区段分析模块1817可分析耳蜗模型A1813a至B1813b的输出A1815a至B1815b或部分A1845a至B1845b的区段。举例来说,区段分析模块1817可将输出A1815a至B1815b或部分A1845a至B1845b分组(例如,拆分)为多个区段A1819a至B1819b。在一些配置中,区段分析模块1817可将输出A1815a至B1815b或部分A1845a至B1845b中的每一者分组为四个区段A1819a至B1819b每一者。举例来说,第一区段可包含从1到150的位置点、第二区段可包含从151到275的位置点、第三区段可包含从276到450的位置点及第四区段可包含从451到512的位置点。区段A1819a至B1819b中的每一者可包含一时间长度内的位置点(例如,N个样本)。区段A1819a至B1819b可提供至向量提取模块1821。向量提取模块1821可为结合图15所描述的向量提取模块1521的一个实例。向量提取模块1821可提取区段A1819a至B1819b的向量1823。具体来说,向量提取模块1821可针对区段A1819a至B1819b提取基于位置的分析向量和基于时间的分析向量。向量1823(例如,一或多个基于时间的分析向量和一或多个基于位置的分析向量)可提供至特征确定模块1825。特征确定模块1825可为结合图15所描述的特征确定模块1525的一个实例。特征确定模块1825可根据每一向量1823(例如,分析向量)确定一或多个特征1827。举例来说,特征确定模块1825可确定每一向量1823的均值、中值、几何偏移、调和均值、标准差及偏度。在一些配置中,特征1827可提供至失真估计模块1847。失真估计模块1847可为结合图15所描述的失真估计模块的一个实例。失真估计模块1847可基于一或多个特征1827估计一或多个失真1849。举例来说,失真估计模块1847可包含基于一或多个特征1827估计一或多个失真1849的线性回归模块1851。举例来说,线性回归模块1851可基于特征1827中的一或多者及权重1853(例如,一或多个权重)执行线性回归以估计一或多个失真1849。可基于如本文所描述的训练(例如,如结合图8至9中的一或多者所描述)确定权重1853。在一些配置中,失真估计模块1847可另外或或者执行多项式回归、二次回归、非线性回归等以估计失真1849。在一些配置中,可基于如本文所描述的一或多个失真1849估计一或多个质量(例如,前景质量、背景质量、整体质量等)。结合本文所公开的系统和方法所描述的侵入性途径的一些优势可包含以下各者中的一或多者。途径可为人类感知定向的。其可提供话语质量测量的高精确性。其可提供对不同类型的话语失真的领会(例如,描述)。途径可利用液压机械耳蜗模型输出(而其它已知解决方案不可)。图19为说明非侵入性特征提取模块1929的一个配置的框图。举例来说,图19说明用于通过用于在感知域中话语和音频信号分析的耳蜗模型的非侵入性特征提取的途径。非侵入性特征提取模块1929可为结合图15所描述的特征提取模块1529的一个实例。非侵入性特征提取可与特征提取的侵入性模型类似,但原始话语(非失真)可为不可获得的。非侵入性特征提取模块1929可包含耳蜗模型1913、部分选择模块1943、区段分析模块1917、向量提取模块1921及/或特征确定模块1925。修改后的话语信号1911(例如原始话语信号的衰减版本)可用作特征提取的输入。换句话说,非侵入性特征提取模块1929可确定一或多个特征1927。一或多个特征1927可用于估计(例如,预测)修改后的话语信号1911的一或多个失真1949。原始话语信号1909的长度及/或修改后的话语信号1911的长度可为一个帧、多个帧或任何合适的时长(例如,1秒、2秒、5秒、10秒等)。另外或或者,修改后的话语信号1911的长度可基于话语自身(例如,整个句子)。举例来说,修改后的话语信号1911的长度可为可配置的(例如,由无线网络的运营商及/或由用户配置)。修改后的话语信号1911可提供至耳蜗模型1913。耳蜗模型1913可为结合图15所描述的生理耳蜗模型1513的实例。耳蜗模型1913可如结合图15所描述的起作用。因此,耳蜗模型1913可产生输出1915。如上文所描述,人类耳蜗的平均长度大约为3.5cm,其中耳蜗上的每个点对不同频率(例如,范围为接近于最低可察觉频率至接近于最高可察觉频率)起反应。在一些配置中,耳蜗模型1913可使耳蜗的长度离散为一定数目的位置点(例如,512个位置点或样本)。举例来说,对于修改后的话语信号1911的每一样本,耳蜗模型1913可产生512个位置点。输出1915可包含样本范围(例如,N个)内位置点集合。举例来说,输出1915可包含对应于修改后的话语信号1911的N个位置点集合。输出1915可提供至部分选择模块1943。部分选择模块1943可从耳蜗模型1913的输出1915选择部分1945(例如,“感兴趣的部分”)。举例来说,可选择修改后的话语信号1911的有声部分(例如,包含元音声音的有声部分)。在一些配置中,部分选择模块1943可确定输出1915的能量。可选择部分1945作为输出1915的样本的范围,其中输出1915的能量大于阈值。部分选择模块1943可利用其它静音检测(VAD)途径或模块来确定部分1945。或者,可检测及/或选择无声部分。输出1915或部分1945可提供至区段分析模块1917。区段分析模块1917可为结合图15所描述的区段分析模块1517的一个实例。区段分析模块1917可分析耳蜗模型1913的输出1915的区段或部分1945。举例来说,区段分析模块1917可将输出1915或部分1945分组(例如,拆分)为多个区段1919。在一些配置中,区段分析模块1917可将输出1915或部分1945分组为四个区段1919。举例来说,第一区段可包含从1到150的位置点、第二区段可包含从151到275的位置点、第三区段可包含从276到450的位置点及第四区段可包含从451到512的位置点。区段1919中的每一者可包含一时间长度内的位置点(例如,N个样本)。区段1919中的每一者可提供至向量提取模块1921。向量提取模块1921可为结合图15所描述的向量提取模块1521的一个实例。向量提取模块1921可提取区段1919中的每一者的向量1923。具体来说,向量提取模块1921可针对每一区段1919提取基于位置的分析向量和基于时间的分析向量。向量1923(例如,一或多个基于时间的分析向量和一或多个基于位置的分析向量)可提供至特征确定模块1925。特征确定模块1925可为结合图15所描述的特征确定模块1525的一个实例。特征确定模块1925可根据每一向量1923(例如,分析向量)确定一或多个特征1927。举例来说,特征确定模块1925可确定每一向量1923的均值、中值、几何偏移、调和均值、标准差及偏度。在一些配置中,特征1927可提供至失真估计模块1947。失真估计模块1947可为结合图15所描述的失真估计模块的一个实例。失真估计模块1947可基于一或多个特征1927估计一或多个失真1949。举例来说,失真估计模块1947可包含基于一或多个特征1927估计一或多个失真1949的线性回归模块1951。举例来说,线性回归模块1951可基于特征1927中的一或多者及权重1953(例如,一或多个权重)执行线性回归以估计一或多个失真1949。可基于如本文所描述的训练(例如,如结合图8至9中的一或多者所描述)确定权重1953。在一些配置中,失真估计模块1947可另外或或者执行多项式回归、二次回归、非线性回归等以估计失真1949。在一些配置中,可基于如本文所描述的一或多个失真1949估计一或多个质量(例如,前景质量、背景质量、整体质量等)。结合本文所公开的系统和方法所描述的非侵入性途径的一些优势可包含以下各者中的一或多者。途径可为人类感知定向的。其可提供话语质量测量的高精确性。其可提供对不同类型的话语失真的理解(例如,描述)。途径可利用液压机械耳蜗模型输出(而其它已知解决方案不可)。应注意,非侵入性途径不可访问像侵入性方法一样多的信息。因此,与侵入性途径相比,其可能在质量测量方面不大精确。图20为说明被拆分成区段A2019a至D2019d的耳蜗模型的输出2015的一个实例的框图。在此实例中,耳蜗模型可输出每一样本输入的512个位置点(例如,样本),其中512个位置点中的每一者对应于人类耳蜗上的一点。因此,如果输入N个样本,那么耳蜗模型可输出512xN个样本(例如,耳蜗模型输出2015具有512xN的大小。如图20中所图示,横轴说明时间2057。如图20中所图示,纵轴说明位置2055(例如,沿耳蜗的长度的位置或位点,所述位置可映射至频率)。在此实例中,输出2015包含话语信号的N个样本中的每一者的512个位置点。如上文所描述,输出2015可分组或拆分成较小区段。举例来说,区段分析模块(例如,区段分析模块1517、1817、1917)可将耳蜗模型的输出2015拆分成四个较小区段A2019a至D2019d。区段A2019a可包含横跨时间轴2057的N个样本的位置点1至150(例如,产生位置点范围(K1=150))。区段B2019b可包含横跨时间轴2057的N个样本的位置点151至275(例如,产生位置点范围(K2=125))。区段C2019c可包含横跨时间轴2057的N个样本的位置点276至450(例如,产生位置点范围(K3=175))。区段D2019d可包含横跨时间轴2057的N个样本的位置点451至512(例如,产生位置点范围(K4=62))。虽然以特定值说明区段2019,但任何合适的划定可用于定义区段2019。此外,术语“区段”和“区域”可互换使用以指代耳蜗模型输出的部分。将输出2015拆分成较小区段可实现用于管理大量数据及/或用于频率相关分析的途径。图21为说明从耳蜗模型输出2115的区段2119提取基于位置的分析向量2123的一个实例的框图。具体来说,图21说明基于原始话语的耳蜗模型输出A2115a的区段A2119a和修改后的(例如,衰减)话语的耳蜗模型输出B2115b的区段E2119e来提取基于位置的(例如,“类型1”)分析向量的实例。可由结合图15所描述的电子装置1507(例如,特征提取模块1529)执行结合图21所描述的操作中的一或多者。具体来说,此实例说明基于原始话语信号的耳蜗模型的输出A2115a。输出A2115a包含区段A2119a至D2119d。此外,此实例说明基于修改后的话语信号的耳蜗模型的输出B2115b。输出B2115b包含区段E2119e至H2119h。区段分析模块A2117a将输出A2115a拆分成区段A2119a至D2119d且将区段A2119a提供至求平均值模块A2159a。换句话说,区段分析模块A2117a将耳蜗模型输出A2115a的K1xN个样本(例如,区段A2119a)提供至求平均值模块A2159a。求平均值模块A2159a计算区段A2119a随时间的平均值。此平均值提供至求对数模块A2161a,所述求对数模块对平均值执行log10操作。平均值的对数(例如,第一平均值的对数)提供至求和器2163。区段分析模块B2117b将输出B2115b拆分成区段E2119e至H2119h且将区段E2119e提供至求平均值模块B2159b。换句话说,区段分析模块B2117b将耳蜗模型输出B2115b的K1xN个样本(例如,区段E2119e)提供至求平均值模块B2159b。求平均值模块B2159b计算区段E2119e随时间的平均值。此平均值提供至求对数模块B2161b,所述求对数模块对平均值执行log10操作。平均值的对数(例如,第二平均值的对数)提供至求和器2163。求和器采用第一平均值的对数与第二平均值的对数的差来产生分析向量2123(例如,“类型1”分析向量)。此分析向量2123(例如,“类型1”分析向量)可被称为基于位置的分析向量或侵入性基于位置的分析向量。举例来说,可在侵入性途径中确定基于位置的分析向量2123,所述途径利用原始话语信号和修改后的话语信号。虽然这些操作图示为用于输出A2115a至B2115b的第一区段(区段A2119a和区段E2119e),但可针对图20和21中的一或多者中所图示的四个区段中的任一者及/或全部确定分析向量2123。如本文中所使用,术语“分析序列”和“分析向量”可互换使用以指代通过其提取话语的特征的中间向量。图22为说明从耳蜗模型输出2215的区段A2219a提取基于位置的分析向量2223的另一实例的框图。具体来说,图22说明基于修改后的(例如,衰减)话语的耳蜗模型输出2215的区段A2219a提取基于位置的(例如,“类型2”)分析向量的实例。应注意,可利用类似途径来提取原始话语的基于位置的分析向量。可由结合图15所描述的电子装置1507(例如,特征提取模块1529)执行结合图22所描述的操作中的一或多者。具体来说,此实例说明基于修改后的话语信号的耳蜗模型的输出2215。输出2215包含区段A2219a至D2219d。区段分析模块2217将输出2215拆分成区段A2219a至D2219d且将区段A2219a提供至求平均值模块2259。换句话说,区段分析模块2217将耳蜗模型输出2215的K1xN个样本(例如,区段A2219a)提供至求平均值模块2259。求平均值模块2259计算区段A2219a随时间的平均值。此平均值提供至求对数模块2261,所述求对数模块对平均值执行log10操作。平均值的对数(例如,平均值对数)为分析向量2223(例如,“类型2”分析向量)。此分析向量2263(例如,“类型2”分析向量)可被称为基于位置的分析向量或非侵入性基于位置的分析向量。举例来说,可在非侵入性途径中确定基于位置的分析向量2223,所述途径利用修改后的话语信号(例如,及不利用原始话语信号)。虽然这些操作图示为用于输出2215的第一区段(区段A2219a),可针对图20和22中的一或多者中所图示的四个区段的任一者及/或全部确定分析向量2223。图23为说明从耳蜗模型输出2315的区段2319提取基于时间的分析2323的一个实例的框图。具体来说,图23说明基于原始话语的耳蜗模型输出A2315a的区段A2319a和修改后的(例如,衰减)话语的耳蜗模型输出B2315b的区段E2319e来提取基于时间的(例如“类型3”)分析向量的实例。可由结合图15所描述的电子装置1507(例如,特征提取模块1529)执行结合图23所描述的操作中的一或多者。具体来说,此实例说明基于原始话语信号的耳蜗模型的输出A2315a。输出A2315a包含区段A2319a至D2319d。此外,此实例说明基于修改后的话语信号的耳蜗模型的输出B2315b。输出B2315b包含区段E2319e至H2319h。区段分析模块A2317a将输出A2315a拆分成区段A2319a至D2319d且将区段A2319a提供至求平均值模块A2359a。换句话说,区段分析模块A2317a将耳蜗模型输出A2315a的K1xN个样本(例如,区段A2319a)提供至求平均值模块A2359a。求平均值模块A2359a计算区段A2319a随位置的平均值。此平均值提供至求对数模块A2361a,所述求对数模块对平均值执行log10操作。平均值的对数(例如,第一平均值的对数)提供至求和器2363。区段分析模块B2317b将输出B2315b拆分成区段E2319e至H2319h且将区段E2319e提供至求平均值模块B2359b。换句话说,区段分析模块B2317b将耳蜗模型输出B2315b的K1xN个样本(例如,区段E2319e)提供至求平均值模块B2359b。求平均值模块B2359b计算区段E2319e随位置(例如,沿耳蜗的位置,其可对应于频率)的平均值。此平均值提供至求对数模块B2361b,所述求对数模块对平均值执行log10操作。平均值的对数(例如,第二平均值的对数)提供至求和器2363。求和器采用第一平均值的对数与第二平均值的对数的差来产生分析向量2323(例如,“类型3”分析向量)。此分析向量2323(例如“类型3”分析向量)可被称为基于时间的分析向量或侵入性基于时间的分析向量。举例来说,可在侵入性途径中确定基于时间的分析向量2323,所述途径利用原始话语信号和修改后的话语信号。虽然这些操作图示为用于输出A2315a至B2315b的第一区段(区段A2319a和区段E2319e),但可针对图20和23中的一或多者中所图示的四个区段的任一者及/或全部确定分析向量2323。图24为说明从耳蜗模型输出2415的区段A2419a提取基于时间的分析向量2423的另一实例的框图。具体来说,图24说明基于修改后的(例如,衰减)话语的耳蜗模型输出2415的区段A2419a提取基于时间的(例如,“类型4”)分析向量的实例。应注意,可利用类似途径来提取原始话语的基于时间的分析向量。可由结合图15所描述的电子装置1507(例如,特征提取模块1529)执行结合图24所描述的操作中的一或多者。具体来说,此实例说明基于修改后的话语信号的耳蜗模型的输出2415。输出2415包含区段A2419a至D2419d。区段分析模块2417将输出2415拆分成区段A2419a至D2419d且将区段A2419a提供至求平均值模块2459。换句话说,区段分析模块2417将耳蜗模型输出2415的K1xN个样本(例如区段A2419a)提供至求平均值模块2459。求平均值模块2459计算区段A2419a随位置(例如,沿耳蜗的位置,所述位置可对应于频率)的平均值。此平均值提供至求对数模块2461,所述求对数模块对平均值执行log10操作。平均值的对数(例如,平均值对数)为分析向量2423(例如,“类型4”分析向量)。分析向量2463(例如,“类型4”分析向量)可被称为基于时间的分析向量或非侵入性基于时间的分析向量。举例来说,可在非侵入性途径中确定基于时间的分析向量2423,所述途径利用修改后的话语信号(例如,及不利用原始话语信号)。虽然这些操作图示为用于输出2415第一区段(区段A2419a),可针对图20和24中的一或多者中所图示的四个区段的任一者及/或全部确定分析向量2423。图25包含说明特征确定模块2525的配置的框图。结合图25所描述的特征确定模块2525可为本文所描述的特征确定模块1525、1825、1925中的一或多者的一个实例。特征确定模块2525可包含特征计算模块2563、正值模块2565及/或负值模块2569。在一些配置中,可在侵入性途径中实施及/或利用正值模块2565和负值模块2569。在一些配置中,正值模块2565和负值模块2569为任选的及/或不可在非侵入性途径中实施及/或利用。向量2523a可提供至特征确定模块2525。具体来说,向量2523a可提供至特征计算模块2563、正值模块2565及/或负值模块2569。正值模块2565可确定向量2523a的正值部份2567。举例来说,正值模块2565可将向量2523a中的任何负值更改为零。正值模块2565还可使向量2523a中的任何正值不变。负值模块2569可确定向量2523a的负值部份2571。举例来说,负值模块2569可将向量2523a中的任何正值更改为零。负值模块2569还可使向量2523a中的任何负值不变。向量2523a、正值部份2567及/或负值部份2571可提供至特征计算模块2563。特征计算模块2563可确定(例如,计算)向量2523a、正值部份2567及/或负值部份2571中的每一者的一或多个特征。举例来说,特征计算模块2563可计算向量2523a、正值部份2567及/或负值部份2571中的每一者的平均值(例如,均值)、中值、几何偏移、调和均值、标准差、偏度及/或其它特征。图25中图示用于确定向量2523b的正值部份和负值部分的一个途径。具体来说,图25提供正值部份和负值部份确定2573的一个实例。向量2523b(例如分析向量或分析序列)可具有n个值或条目:P1至Pn。正值部份2575(例如,正向量、分析序列正值)和负值部份2577(例如,负向量、分析序列负值)可创建。可基于具有同一索引的向量2523b中的对应值创建正值部份2575中的每一值(例如,正值部份2575中的第一条目基于向量2523b中的第一条目)。举例来说,如果在向量2523b中P1>0,那么正值部份2575中的P1为P1。然而,如果在向量2523b中P1<=0,那么正值部份2575中的P1为0。相反地,如果在向量2523b中P<0,那么负值部份2577中的P1为P1。然而,如果在向量2523b中P1>=0,那么负值部份2577中的P1为0。此可为向量2523b中的每个值或条目进行以填入正值部份2575及/或负值部份2577,从所述正值部份及/或负值部份可提取特征(例如,特征2527)。图26说明特征确定的实例。在一些配置中,图26中所图示的特征确定可由本文所描述的特征确定模块1525、1825、2525中的一或多者执行。具体来说,图26中所图示的特征确定可在侵入性途径中(例如,针对侵入性基于位置的向量(“类型1”)及针对侵入性基于时间的向量(“类型3”))执行。在此实例中,单一侵入性基于位置的向量或单一侵入性基于时间的向量可产生18个特征(例如,特征值):6个来自向量2623自身、6个来自分析向量2623的正值部份2667及6个来自分析向量2623的负值部份2671。在一些配置中,特征或特征值中的每一者可由对应模块确定(例如,计算)。举例来说,每一模块可产生单一特征或特征值。在一些配置中,特征确定模块(例如,结合图25所描述的特征确定模块2525)可确定向量2623的正值部份2667的平均值A2679a、中值A2681a、几何偏移A2683a、调和均值A2685a、标准差A2687a及偏度A2689a。另外或或者,特征确定模块可确定向量2623自身的平均值B2679b、中值B2681b、几何偏移B2683b、调和均值B2685b标准差B2687b及偏度B2689b。另外或或者,特征确定模块可确定向量2623的负值部份2671的平均值C2679c、中值C2681c、几何偏移C2683c、调和均值C2685c、标准差C2687c及偏度C2689c。对于正值部份2667,特征确定模块可确定一或多个其它特征A2691a或特征值。对于向量2623,特征确定模块可另外或或者确定一或多个其它特征B2691b或特征值。对于负值部份2671,特征确定模块可另外或或者确定一或多个其它特征C2691c或特征值。一或多个特征或特征值可被一起分组在特征集合中。举例来说,平均值B2679b、中值B2681b、几何偏移B2683b、调和均值B2685b、标准差B2687b及偏度B2689b可分组到特征集合中。图27说明特征确定的另一实例。在一些配置中,图27中所图示的特征确定可由本文所描述的特征确定模块1525、1825、1925、2525中的一或多者执行。具体来说,图27中所图示的特征确定可在非侵入性途径中(例如,针对非侵入性基于位置的向量(“类型2”)及针对非侵入性基于时间的向量(“类型4”))及/或在侵入性途径中(例如,针对侵入性基于位置的向量(“类型1”)及针对侵入性基于时间的向量(“类型3”))执行。在此实例中,单一侵入性基于位置的向量或单一侵入性基于时间的向量可根据向量2723产生6个特征(例如,特征值)。在一些配置中,特征或特征值中的每一者可由对应模块确定(例如,计算)。举例来说,每一模块可产生单一特征或特征值。在一些配置中,特征确定模块(例如,结合图25所描述的特征确定模块2525)可确定向量2723的平均值2779、中值2781、几何偏移2783、调和均值2785、标准差2787及偏度2789。对于向量2723,特征确定模块可另外或或者确定一或多个其它特征2791或特征值。一或多个特征或特征值可被一起分组在特征集合中。举例来说,平均值2779、中值2781、几何偏移2783、调和均值2785、标准差2787及偏度2789可分组到特征集合中。图28说明根据本文所公开的系统和方法的客观预测的一个实例。具体来说,图28包含图表A2893a和图表B2893b。图表A2893a图示有S-MOS预测2895得分的纵轴,所述得分具有1至5的范围且说明话语信号的前景质量的客观预测得分或S-MOS的预测(例如,前景得分的SIG均值预测)。图表A2893a还图示有主观S-MOS2897得分的横轴,所述横轴还具有1-5的范围且为使用已知途径的前景质量的量度的实例。图表A2893a为在已知途径中P.835SIG得分与客观预测的散布图。如可观察到,已知途径对于小于2.5的主观得分无法很好地预测。在图28至30中,点越接近对角线,它们表示预测更精确。应注意,图28至30中的所有A图表用于一个数据库(例如,SIG(2893a)、BAK(2993a)及OVR(3093a))。还应注意,图28至30中的所有B图表用于另一数据库(例如,SIG(2893b)、BAK(2993b)及OVR(3093b))。图表B2893b图示有客观SIG2899得分的纵轴,所述得分具有1至5的范围且为使用ITU标准P.835的话语信号的前景质量预测得分。图表B2893b还图示有主观SIG2802得分的横轴,所述横轴还具有1至5的范围且为本文所公开的根据系统和方法的客观预测值的实例。如可观察到,与已知途径相比,本文所公开的系统和方法可预测具有较高精确性的主观MOS。图29说明根据本文所公开的系统和方法的客观预测的另一实例。具体来说,图29包含图表A2993a和图表B2993b。图表A2993a图示有以客观P.835BAK2904得分形式的纵轴,所述得分具有1至5的范围且为使用ITU标准P.835的话语信号的背景噪声的预测得分。图表A2993a还图示有以主观N-MOS2906得分为单位的横轴,所述横轴还具有1至5的范围且为使用已知途径的背景噪声的量度的实例。图表A2993a为在已知途径中P.835BAK得分与客观预测的散布图。如可观察到,已知途径相当严密地预测主观得分。图表B2993b图示有以客观P.385NMOS(BAK)2908得分形式的纵轴,所述得分具有1至5的范围且为使用ITU标准P.835的话语信号的背景噪声的预测得分。图表B2993b还图示有以主观NMOS2910得分为单位的横轴,所述横轴还具有1至5的范围且为根据本文所公开的系统和方法的客观预测值的实例。如可观察到,与已知途径相比,本文所公开的系统和方法可预测具有稍低精确性的得分,尽管两个结果相当接近于主观得分。图30说明根据本文所公开的系统和方法的客观预测的另一实例。具体来说,图30包含图表A3093a和图表B3093b。图表A3093a图示有以客观OVRLP.8353012形式的纵轴,所述得分具有1至5的范围且为使用ITU标准P.835的话语信号的整体质量的预测得分。图表A3093a还图示有以主观G-MOS3014得分形式的横轴,所述得分还具有1至5的范围且为实例使用已知途径的整体质量的量度。图表A3093a为在已知途径中P.835BAK得分与客观预测的散布图。如可观察到,已知途径相当严密地预测主观得分。图表B3093b图示有以客观GMOS(OVR)3016得分形式的纵轴,所述得分具有1至5的范围且为使用ITU标准P.835的话语信号的整体质量的预测得分。图表B还图示有以主观GMOS(OVR)3018得分形式的横轴,所述横轴还具有1至5的范围且为根据本文所公开的系统和方法的客观预测值的实例。如可观察到,与已知途径相比,本文所公开的系统和方法可预测具有更高精确性的得分。表2中提供本文所公开的系统和方法预测P.835得分的能力的一些基本结果。举例来说,本文所公开的系统和方法可应用至P.ONRA的模型。在本文所描述的途径中,液压机械耳蜗模型可用于将话语转换到感知域中。耳蜗模型输出(内毛细胞(IHC)电压)可实质上为话语信号在时间和空间(例如,沿基底膜的距离)轴中的表示。与传统心理声学模型相比,所述表示具有更高的时间分辨率和更精确的空间精确性。IHC电压的进一步处理产生‘突出特征集合’,所述集合可接着通过简单线性欧洲电信标准协会(ETSI)TS103106回归模型馈入以预测(例如)SMOS、NMOS及GMOS。在此处提出的基本结果中,本文所描述的途径仅利用3个主观数据库(每一者具有60个条件)训练;而相比而言,已知途径利用7个数据库训练。举例来说,出于验证目的,本文所公开的系统和方法已对一些P.835数据库进行测试。使用四个数据库。每一数据库包含60个条件、2个说话者及4个语句。三个数据库用于训练且一个用于测试。如同本文所描述,可利用特征的线性回归执行训练及/或预测。应注意,还可根据本文所公开的系统和方法应用复杂的训练模型(例如,神经网络)。举例来说,可改善训练过程。表2提供相较于已知途径(“已知”)的本文所公开的系统和方法(“新”)的一些基本结果的实例。“RMSE”表示“均方根错误”。表2表2说明一个主观测试数据库的预测结果。由TS103106对同一数据库的预测(利用7个主观数据库重新训练)在此处列为“已知”途径以用于比较。结果展示本文所公开的系统和方法更善于能够预测S-MOS和G-MOS。图28中展示详述比较。对于具有小于3的主观S-MOS的条件,TS103106的性能降低。图29中展示N-MOS性能的详述比较。就相关系数(两者展示0.99)而言不存在差异。可根据S-MOS和N-MOS合成G-MOS。与TS103106相比,本文所公开的系统和方法提供稍好的预测。主观与客观得分之间的相关系数为0.99与0.97。当前模型还展示较小的RMSE(0.16与0.36)和RMSE*(0.09与0.23)。图30中展示G-MOS的比较。图31为说明对应于图31A至31D的实例的多个部分的框图。图31A至31D展示说明使用侵入性特征提取估计或预测粗糙度失真的一个实例的框图。虽然特定数目可用于说明,现有系统和方法的任一点处的各种数据的实际大小可变化。如图31A中所展示原始话语信号3109和修改后的(例如,衰减)话语信号3111(每一者经图示为1000个样本的长度)可馈入至耳蜗模型。耳蜗模型可针对每一样本输入输出512个样本。具体来说,输出A3115a可对应于原始话语信号3109,且输出B3115b可对应于修改后的话语信号3111。根据输出A3115a至B3115b,第一有声部分可拆分成四个区段3119a至3119b(例如,基于原始话语信号3109的耳蜗模型的输出A3115a的四个区段3119a及基于基于修改后的话语信号3111的耳蜗模型的输出B3119b的四个区段3119b)。可根据区段3119a至3119b确定一或多个分析向量或分析序列(AS)3123。如所说明,可根据第一区段确定R1AS1,其中R1指根据第一有声部分的第一区段确定其的事实及AS1指其为类型1分析向量的事实。除R1AS1以外,可确定以下分析向量3123:R1AS3、R2AS1、R2AS3、R3AS1、R3AS3、R4AS1、R4AS3、R3AS2及R3AS4。可如结合图15至16、18及21至24中的一或多者中所描述确定这些向量。因此,所提取的每一所选区段的分析向量3123的类型可根据表3确定,所述表3说明话语质量的侵入性测量的类型:区段输入信号所提取的分析向量区段A(R1)原始和修改后的类型1和3区段B(R2)原始和修改后的类型1和3区段C(R3)原始和修改后的类型1和3区段D(R4)原始和修改后的类型1和3区段C(R3)原始类型2和4SFP原始和修改后的类型1表3此外,可提取根据原始话语和修改后的(例如,衰减)话语确定的突出特征点(SFP)向量3124的类型1分析向量。SFP向量涉及时间局部失真。获得SFP向量的过程可为:(1)获得CM输出及获取有声部分;(2)在有声部分中发现一或多个(例如,所有)音轨;(3)使用其中振幅较高的一或多个区段;及(4)根据有声部分中的一或多个音轨计算SFP向量3124。因此,可使用11个向量(10个分析向量3123及SFP3124)(每一者产生6或18个特征)来确定所选区段的特征3127(例如,特征向量)。SFP可被考虑“感知音高”且可不同于传统的音高概念。这是因为SFP可为三维,意味着SFP中的每个点具有时间、位置及振幅。传统的音高概念在感知域中可能不具有振幅。具体来说,类型1或类型3分析向量可分别产生18个特征3127(例如,如结合图25至26中所描述)。如所说明,可利用AS1和AS3向量来获得正值部分(例如,RS1AS1正值)和负值部分(例如,RS1AS1负值)。类型2或类型4分析向量可分别产生6个特征(例如,如结合图25和27中所描述)。特征3127可放入在此实例中具有174个条目的特征向量中。可对原始话语和修改后的话语的耳蜗输出的第二部分(例如,有声部分)执行特征提取的相同处理以产生另一174条目特征向量。可为任何合适数目的部分(例如,有声部分)重复相同处理,每一部分产生与第一所选区段类似的特征向量。一旦确定全部所选区段的特征向量,可计算特征3127的平均值,如图31B和图31C中所图示。换句话说,可计算特征向量中的每一者的第一条目(展示为平均值)的平均值。类似地,每一索引处的条目与彼此计算平均值以产生单一平均值特征向量3120,在此实例中展示为174条目向量。单一平均值特征向量3120在训练期间(例如,如结合图8至9中的一或多者所描述)乘以先前得知的权重3153(例如,可使用权重加权)。在加权之后,可对单一平均值特征向量中的特征中的每一者求和以产生如图31D中所展示的粗糙度失真3149(例如,预测得分)。可遵循其它失真的类似程序。用于话语质量的客观测量的已知途径将直接解决整体质量,例如ITU标准PESQ/P.OLQA。在已知途径中,从心理声学掩蔽模型或类似者提取特征,所述特征为人类感知的粗略近似值。感知共振峰类特征已从液压机械耳蜗模型的输出提取出,且用于时间局部失真测量。在一些配置中,系统和方法的一或多个程序可按以下执行。在一个途径中,此处所介绍的新特性集合具有侵入性(使用衰减和原始话语信号两者)。采用原始和对应衰减话语(Sori和Sdis,对齐和水平)。Sori和anSdis可通过听觉的计算模型(例如液压机械耳蜗模型或心理声学模型)。此类模型可被称为CM,且归因于原始和失真信号的输出将被称作CMori和CMdis。原始和失真话语可通过液压机械耳蜗模型(CM),且输出具有沿时间和频率域两者的高精度。输出表示感知域中的话语。可从感兴趣的区段提取分析序列(AS)。根据分析的目的,可通过本文所描述的相同算法从话语的有声区段(VS)及无声(SIL)区段提取特征VSF144。假设存在K个感兴趣的区段。频率相关分析序列可按以下描述。对于kth感兴趣的区域,衰减CM输出及对应原始CM输出分别具有P×T的大小。对于不同感知模型,CM可具有不同大小。在以下部分中,我们采用耳蜗模型。应注意,可调整特定输出的数目。在此实例中P具有范围1至512,且切割成四个区域:(A)1至150、(B)151至275、(C)a276至450及(D)450至512。由于位置的函数,因此存在四个差函数。另一者针对原始话语进行描述但仅在突出区域(区域C)中:P1k(p)(具有长度N)可分成可对P2k(p)、P3k(p)、P4k(p)应用相同程序以产生及仅P5k(p)自身。这些可被称作分析序列。时间相关分析序列可按以下获得。对于每一有声区段(VS),存在衰减CM输出及对应原始其中每一者具有P×T的大小。可计算以下内容:r1211150215127532764504450512其中r1,2是指“第一行、第二列”(例如,150)。应注意,可利用更多区域(例如,与仅区域C相比)。由于位置的函数,因此,存在四个差函数。另一者针对原始话语进行描述,但仅在突出区域(区域C)中。T1k(t)(具有长度N)可分成可对T2k(p)、T3k(p)、T4k(p)应用相同程序以产生这些也可被称作分析序列。还可获得SFP。如果感兴趣的区段为有声区段,那么从kth有声区段的CM输出提取SFPk。在一些配置中,可如欧洲专利申请公开案第EP2329399A4号中所描述的获得SFT。三个AS在此形成:从AS的特征提取可按以下继续进行。对于每一AS(例如,具有长度N的和T3k),按以下提取特征:FT1=mean(AS)几何偏移。FT3=median(AS),其中,此处中值函数是指且调和均值。FT5=std(AS),标准差(std)。从P1k提取的特征为F1至F18。从P2k提取的特征为F19至F36。从P3k提取的特征为F37至F54。从P4k提取的特征为F55至F72。对于P5k(其为区域C中的原始值),仅存在6个特征:F73至F78。从T1k提取的特征为F79至F96。从T2k提取的特征为F97至F114。从T3k提取的特征为F115至F132。从T4k提取的特征为F133至F150。对于P5k(其为区域C中的原始值),仅存在6个特征:F151至F156。从SFPk提取的特征为F157至F174。应注意,最终特征得分可包含全部有声区段(例如,)的特征的均值。特征F175可为说话者为男性或女性的二进制指示符(例如,0用于男性且-1用于女性)。为了便于线性回归,特征F176可为常量(例如,通常设定为1)。本文所公开的系统和方法可提供话语质量测量输出。可另外或或者提供译码及/或发射开发者的反馈(例如实时反馈)。可另外或或者提供话语失真的特性及/或理解。本文所公开的系统和方法可提供许多参数以描述给定话语在感知域中的特性(例如失真)。这些特征可构建到常用工具箱中且合并以用于特定目的(例如,频率局部失真测量)。换句话说,本文所描述的系统和方法可提供话语质量测量的高精确性、对关于不同类型的话语失真的描述的深刻理解、人类感知定向途径。应注意,其它已知途径不可使用液压机械耳蜗模型输出。图32为说明对应于图32A至32D的实例的多个部分的框图。图32A至32D为说明使用非侵入性特征提取估计或预测粗糙度失真的一个实例的框图。虽然特定数目可用于说明,现有系统和方法的任一点处的各种数据的实际大小可变化。如图32A中所展示的修改后的(例如,衰减)话语信号3211(图示为1000个样本长度)可馈入至耳蜗模型。耳蜗模型可针对每一样本输入输出512个样本。具体来说,输出3215可对应于修改后的话语信号3211。通过输出3215,第一有声部分可拆分成四个区段3219(例如,基于基于修改后的话语信号3211的耳蜗模型的输出3215的四个区段3219)。可根据区段3219确定一或多个分析向量或分析序列(AS)3223。如所说明,可根据第一区段确定R1AS2,其中R1指根据第一有声部分的第一区段确定其的事实及AS2指其为类型2分析向量的事实。除R1AS2以外,可确定以下分析向量3223:R1AS4、R2AS2、R2AS4、R3AS2、R3AS4、R4AS2及R4AS4。可如结合图15至16、19、22及24中的一或多者中所描述确定这些向量。因此,所提取的每一所选区段的分析向量的类型可根据表4确定,所述表4说明话语质量的非侵入性测量的类型:区段输入信号所提取的分析向量区段A(R1)修改后的类型2和4区段B(R2)修改后的类型2和4区段C(R3)修改后的类型2和4区段D(R4)修改后的类型2和4SFP修改后的类型2表4此外,可提取根据修改后的话语确定的突出特征点(SFP)向量3224类型2分析向量。SFP向量涉及时间局部失真。因此,可使用分别产生6个特征的9个向量(8个分析向量3223和SFP3224)来确定所选区段的特征向量。具体来说,类型2或类型4分析向量可分别产生6个特征3227(例如,如结合图25和27所描述)。特征3227可放入中在此实例中具有54个条目的特征向量中。可对耳蜗输出3215的第二部分(例如,有声部分)执行特征提取的同样处理以产生另一54条目特征向量。可为任何合适数目的部分(例如,有声部分)重复相同处理,每一部分产生与第一所选区段类似的特征向量。一旦确定全部所选区段的特征向量,可计算特征3227的平均值,如图32B和图32C中所图示。换句话说,可计算特征向量中的每一者的第一条目(展示为平均值)的平均值。类似地,每一索引处的条目与彼此计算平均值以产生单一平均值特征向量3220,在此实例中展示为54条目向量。单一平均值特征向量3220可在训练期间(例如,如结合图8至9中的一或多者所描述)乘以先前得知的权重3253(例如,可使用权重加权)。在加权之后,可对单一平均值特征向量中的特征中的每一者求和以产生如图32D中所展示的粗糙度失真3249(例如,预测得分)。可遵循其它失真的类似程序。图31至32说明粗糙度失真3149、3249的预测得分,然而,预测得分可用于失真维度中的任一者。举例来说,当确定枯燥度/低沉度失真维度的预测得分时,使用的权重可对应于枯燥度/低沉度失真维度而不是粗糙度失真维度的主观得分。每一失真维度的预测得分可由客观话语质量模块(例如,如结合图6至7所描述)使用以确定前景质量和背景质量。可随后确定整体质量。整体质量可用于替代或补充根据话语的一部分的人类收听者主观地评分确定的平均意见分(MOS)。在一些配置中,系统和方法的一或多个程序可按以下执行。在一个途径中,此处介绍的新特性具有非侵入性(使用衰减话语信号)。采用衰减话语(Sdis)。Sdis可通过听觉的计算模型(液压机械耳蜗模型或心理声学模型)。此类模型可被称为CM且归因于失真信号的输出将被称为CMdis。输出具有沿时间和频率域两者的高精度。输出表示感知域中的话语。根据分析目的,可通过本文所描述的相同算法从话语的有声区段(VS)和无声(SIL)区段提取分析序列(AS)。假设存在K个感兴趣的区段。频率相关分析序列可按以下描述。对于kth感兴趣的区域,衰减CM输出具有P×T的大小。对于不同感知模型,CM可具有不同大小。在以下部分中,我们采用耳蜗模型。应注意,可调整特定输出的数目。在此实例中P具有范围1至512,且切割成四个区域:(A)1至150、(B)151至275、(C)a276至450及(D)450至512。由于位置的函数,因此存在四个差函数。这些可被称作分析序列。时间相关分析序列可按以下获得。对于每一有声区段(VS),存在衰减CM输出具有P×T的大小。可计算以下内容:r1211150215127532764504450512其中r1,2是指“第一行、第二列”(例如,150)。这些还可被称作分析序列。还可获得SFP。如果感兴趣的区段为有声区段,那么从kth有声区段的CM输出提取SFPk。从AS的特征提取可按以下继续进行。对于每一AS(例如,具有长度N的T3k),按以下提取特征:FT1=mean(AS)几何偏移。FT3=median(AS),其中,此处中值函数是指且调和均值。FT5=std(AS),标准差(std)。从P1k提取的特征为F1至F6。从P2k提取的特征为F7至F12。从P3k提取的特征为F13至F18。从P4k提取的特征为F19至F24。从T1k提取的特征为F25至F30。从T2k提取的特征为F31至F36。从T3k提取的特征为F37至F42。从T4k提取的特征为F43至F48。从SFPk提取的特征为F49至F54。应注意,最终特征得分可包含全部有声区段(例如,)的特征的均值。特征F55可为说话者为男性或女性的二进制指示符(例如,0用于男性且-1用于女性)。为了便于线性回归,特征F56可为常量(例如,通常设定为1)。本文所公开的系统和方法可提供话语质量测量输出。可另外或或者提供译码及/或发射开发者的反馈(例如实时反馈)。可另外或或者提供话语失真的特性及/或理解。本文所公开的系统和方法可提供许多参数以描述给定话语在感知域中的特性(例如失真)。这些特征可构建到常用工具箱中且合并以用于特定目的(例如,频率局部失真测量)。换句话说,本文所描述的系统和方法可提供话语质量测量的高精确性、对关于不同类型的话语失真的描述的深刻理解、人类感知定向途径。应注意,其它已知途径可不使用液压机械耳蜗模型输出。图33为说明用于特征提取的方法3300的更特定配置的流程图。电子装置1507(例如,话语评估器及/或特征提取模块)可执行方法3300的一或多个步骤、功能及/或程序。电子装置可获得原始话语信号及修改后的(例如,衰减)话语信号。原始话语信号和修改后的话语信号可在同一时段内录入以用于侵入性特征提取。换句话说,修改后的话语信号可为原始话语信号的经处理版本。或者,仅修改后的话语信号可获得以用于非侵入性特征提取。电子装置可使用生理耳蜗模型处理话语(3302)。此操作可(例如)如上文结合图15至19及31至32中的一或多者所描述来实现。电子装置可从耳蜗模型的输出中选择部分3304。此操作可(例如)如上文结合图18至19及31至32中的一或多者所描述来实现。所述部分可为原始话语信号的生理耳蜗模型输出的一部分及/或明显地影响话语(例如,有声部分、元音等)的感知质量的修改后的话语信号的耳蜗模型输出的一部分。举例来说,选择所述部分(3304)可包含计算一或多个信号的能量及选择其中能量大于阈值的部分。电子装置可分析生理耳蜗模型的输出的区段(3306)。此操作可(例如)如上文结合图15至16、18至24及31至32中的一或多者所描述来实现。举例来说,电子装置可将输出的部分分组(例如,拆分)为多个区段(例如,四个区段或另一数目的区段)。区段中的每一者可具有特定大小(例如,位置点的数目乘N个样本的数目)。电子装置可针对每一区段提取向量3308。具体来说,电子装置可针对每一区段提取基于位置的分析向量和基于时间的分析向量。此操作可(例如)如上文结合图15至16、18至19及31至32中的一或多者所描述来实现。举例来说,电子装置可计算区段随时间的平均值以产生基于位置的分析向量及/或可计算区段随位置的平均值以产生基于时间的分析向量。在一些配置中,可按照如以上表3中所展示的区段数目提取分析向量(3308)。换句话说,可针对每一区段提取至少一个基于位置的分析向量和一个基于时间的分析向量3308。电子装置可根据每一向量(例如,分析向量)确定一或多个特征(3310)。此操作可如结合(例如)图15至16、18至19、25至27及31至32中的一或多者所描述来实现。电子装置可基于对应于失真维度的一或多个特征及权重(例如,权重集合)估计(例如,预测)失真(3312)。此操作可(例如)如上文结合图15、18至19及31至32中的一或多者所描述来实现。举例来说,电子装置可使用粗糙度失真的权重(例如,先前离线确定的权重集合)来加权特征以产生粗糙度失真(例如,粗糙度维度的预测得分)。可估计一或多个失真(3312)。举例来说,电子装置可估计如上文所描述的粗糙度、不连续性、枯燥度、稀薄度、呼啸及变化性中的一或多者(3312)。电子装置可估计额外及/或替代失真(3312)。在一些配置中,可确定上文结合图4至7所描述的四个前景失真维度和两个背景失真维度的失真(例如,预测得分)。在一些配置中,电子装置可基于失真(例如,客观失真)估计前景质量及/或背景质量。此操作可如上文结合图4至7中的一或多者所描述来实现。另外或或者,可根据前景质量和背景质量估计整体质量。此操作可如上文结合图4至7中的一或多者所描述来实现。整体质量可充当修改后的话语信号的整体客观质量得分,其可用来代替主观平均意见分(MOS)。图34为说明用于侵入性特征提取的方法3400的配置的流程图。电子装置1507(例如,话语评估器及/或特征提取模块)可执行方法3400的一或多个步骤、功能及/或程序。电子装置可获得原始话语信号和修改后的(例如,衰减)话语信号3402。此操作可如上文结合图15所描述来实现。举例来说,电子装置可获得原始话语信号和修改后的话语信号的一或多个帧或时段。原始话语信号和修改后的话语信号可在同一时段内录入以用于侵入性特征提取。换句话说,修改后的话语信号可为原始话语信号的经处理版本。电子装置可使用生理耳蜗模型处理话语3404。此操作可(例如)如上文结合图15至19及31至32中的一或多者所描述来实现。具体来说,电子装置可使用一或多个耳蜗模型处理原始话语信号和修改后的话语信号3404。电子装置可从生理耳蜗模型的输出中选择部分3406。此操作可(例如)如上文结合图18至19及31至32中的一或多者所描述来实现。所述部分可为原始话语信号的生理耳蜗模型输出的一部分及/或明显地影响话语(例如,有声部分、元音等)的感知质量的修改后的话语信号的耳蜗模型输出的一部分。举例来说,选择所述部分3406可包含计算一或多个信号的能量及选择其中能量大于阈值的部分。电子装置可分析生理耳蜗模型的输出的区段3408。此操作可(例如)如上文结合图15至16、18至24及31至32中的一或多者所描述来实现。举例来说,电子装置可将输出的部分分组(例如,拆分)为多个区段(例如,四个区段或另一数目的区段)。区段中的每一者可具有特定大小(例如,位置点的数目乘N个样本的数目)。电子装置可针对每一区段提取向量3410。具体来说,电子装置可针对每一区段提取基于位置的分析向量和基于时间的分析向量3410。此操作可(例如)如上文结合图15至16、18至19及31至32中的一或多者所描述来实现。举例来说,电子装置可计算区段随时间的平均值以产生基于位置的分析向量及/或可计算区段随位置的平均值以产生基于时间的分析向量。在一些配置中,可按照如以上表3中所展示的区段数目提取分析向量3410。换句话说,可针对每一区段提取至少一个侵入性基于位置的分析向量(例如,类型1)和一个基于时间的分析向量(例如,类型3)3410。如表3中所图示,电子装置可任选地及另外提取一或多个区段(例如,区段C)的非侵入性基于位置的向量(例如,类型2)及/或非侵入性基于时间的向量(例如,类型4)。电子装置可根据每一向量(例如,分析向量)确定一或多个特征(3412)。此操作可(例如)如结合图15至16、18至19、25至27及31至32中的一或多者所描述来实现。在一些配置中,可基于每一向量确定6个及/或18个特征(3412)。电子装置可基于一或多个特征及对应于失真维度的权重(例如,权重集合)估计(例如,预测)失真3414。此操作可(例如)如上文结合图15、18至19及31至32中的一或多者所描述来实现。举例来说,电子装置可使用粗糙度失真的权重(例如,先前离线确定的权重集合)来加权特征以产生粗糙度失真(例如,粗糙度维度的预测得分)。可估计一或多个失真3414。举例来说,电子装置可估计如上文所描述的粗糙度、不连续性、枯燥度、稀薄度、呼啸及变化性中的一或多者3414。电子装置可估计额外及/或替代失真3414。在一些配置中,可确定上文结合图4至7所描述的四个前景失真维度和两个背景失真维度的失真(例如,预测得分)。在一些配置中,电子装置可基于失真(例如,客观失真)估计前景质量及/或背景质量。此操作可如上文结合图4至7中的一或多者所描述来实现。另外或或者,可根据前景质量和背景质量估计整体质量。此操作可如上文结合图4至7中的一或多者所描述来实现。整体质量可充当修改后的话语信号的整体客观质量得分,其可用来代替主观平均意见分(MOS)。图35为说明用于非侵入性特征提取的方法3500的配置的流程图。电子装置1507(例如,话语评估器及/或特征提取模块)可执行方法3500的一或多个步骤、功能及/或程序。电子装置可获得修改后的(例如,衰减)话语信号3502。此操作可如上文结合图15所描述来实现。举例来说,电子装置可获得修改后的话语信号的一或多个帧或时段。修改后的话语信号可为原始话语信号的经处理(例如,衰减)版本。在非侵入性途径中,电子装置可不获得原始话语信号。此可允许各种裝置中的话语质量评估,而不必获得、发射或接收话语信号。电子装置可使用生理耳蜗模型处理修改后的话语3504。此操作可(例如)如上文结合图15至17、19及32中的一或多者所描述来实现。具体来说,电子装置可使用耳蜗模型处理仅修改后的话语信号(且不处理原始话语信号)3504。电子装置可从生理耳蜗模型的输出中选择部分3506。此操作可(例如)如上文结合图19及32中的一或多者所描述来实现。所述部分可为明显地影响话语(例如,有声部分、元音等)的感知质量的修改后的话语信号的生理耳蜗模型输出的一部分。举例来说,选择所述部分3506可包含计算修改后的话语信号的能量及选择其中能量大于阈值的部分。电子装置可分析生理耳蜗模型的输出的区段3508。此操作可(例如)如上文结合图15至16、19至20、24及32中的一或多者所描述来实现。举例来说,电子装置可将输出的部分分组(例如,拆分)为多个区段(例如,四个区段或另一数目的区段)。区段中的每一者可具有特定大小(例如,位置点的数目乘N个样本的数目)。电子装置可针对每一区段提取向量3510。具体来说,电子装置可针对每一区段提取非侵入性基于位置的分析向量和非侵入性基于时间的分析向量3510。此操作可(例如)如上文结合图15至16、19、20、24及32中的一或多者所描述来实现。举例来说,电子装置可计算区段随时间的平均值以产生基于位置的分析向量及/或可计算区段随位置的平均值以产生基于时间的分析向量。在一些配置中,可按照如以上表4中所展示的区段数目提取分析向量3510。换句话说,可针对每一区段提取至少一个非侵入性基于位置的分析向量(例如,类型2)和一个非侵入性基于时间的分析向量(例如,类型4)3510。电子装置可根据每一向量(例如,分析向量)确定一或多个特征3512。此操作可(例如)如上文结合图15至16、19、25、27及32中的一或多者所描述来实现。在一些配置中,可基于每一向量确定6个特征3512。电子装置可基于一或多个特征及对应于失真维度的权重(例如,权重集合)估计(例如,预测)失真3514。此操作可(例如)如上文结合图15、19及32中的一或多者所描述来实现。举例来说,电子装置可使用粗糙度失真的权重(例如,先前离线确定的权重集合)来加权特征以产生粗糙度失真(例如,粗糙度维度的预测得分)。可估计一或多个失真3514。举例来说,电子装置可估计如上文所描述的粗糙度、不连续性、枯燥度、稀薄度、呼啸及变化性中的一或多者3514。电子装置可估计额外及/或替代失真3514。在一些配置中,可确定上文结合图4至7所描述的四个前景失真维度和两个背景失真维度的失真(例如,预测得分)。在一些配置中,电子装置可基于失真(例如,客观失真)估计前景质量及/或背景质量。此操作可如上文结合图4至7中的一或多者所描述来实现。另外或或者,可根据前景质量和背景质量估计整体质量。此操作可如上文结合图4至7中的一或多者所描述来实现。整体质量可充当修改后的话语信号的整体客观质量得分,其可用来代替主观平均意见分(MOS)。图36为说明侵入性特征提取的更特定配置的框图。举例来说,图36提供根据IHC电压提取突出特征的实例。应注意,后端处的更复杂的统计模型(例如神经网络)可改善性能且可被另外或或者利用。结合图26所描述的组件中的一或多者可为组件中的一或多者的实例及/或可执行结合图15至27及31至35中的一或多者所描述的程序中的一或多者。具体来说,图36说明延迟估计模块3637、耳蜗模型A3613a至B3613b、减法器3620、部分选择模块3643、随频率计算平均值模块3622、随时间计算平均值模块3624、特征确定模块3625及/或回归模块3651的实例。原始话语信号3609和修改后的话语信号3611(例如,原始话语信号3609的衰减版本)可提供至延迟估计模块3637。延迟估计模块3637可将原始话语信号3609与修改后的话语信号3611对齐,所述信号可提供至耳蜗模型A3613a和耳蜗模型B3613b。耳蜗模型A3613a的输出可由减法器3620从耳蜗模型B3613b的输出减去。差可提供至部分选择模块3643。部分选择模块3643可从差中选择部分。举例来说,可选择差的有声部分。有声部分可提供至随平率计算平均值模块3622及随时间计算平均值模块3624。随频率计算平均值模块3622和随时间计算平均值模块3624可对应地随频率和时间计算有声部分的平均值。随频率计算平均值模块3622可产生一或多个时间区域。随时间计算平均值模块3624可产生一或多个频率区域3626。一或多个频率区域3626可为上文所描述的基于位置的向量的另一表达。随频率计算平均值模块3622可产生一或多个时间区域3628。一或多个时间区域3628可对应于上文所描述的基于时间的向量。频率区域3626及/或时间区域3628可提供至特征确定模块。特征确定模块3625可根据每一区域确定(例如,提取)特征3627(例如,统计特征)。特征3627可分组到特征集合中。在一些配置中,特征3627可提供至回归模块3651。回归模块3651可基于特征3627中的一或多者及权重3653(例如,一或多个权重)执行线性回归以估计一或多个失真3649。在一些配置中,回归模块3651可替代地执行多项式回归、二次回归、非线性回归等以估计失真3649。在一些配置中,可基于如本文所描述的一或多个失真估计一或多个质量(例如,前景质量、背景质量、整体质量等)3649。图37为说明无线通信装置3730的一个配置的框图,其中可实施用于测量话语信号质量及/或特征提取的系统和方法。图37中所图示的无线通信装置3730可为本文所描述的电子装置556、1507中的一或多者的实例。无线通信装置3730可包含应用处理器3742。应用处理器3742通常处理指令(例如,运行程序)以执行无线通信装置3730上的功能。应用处理器3742可耦合到音频译码器/解码器(编解码器)3740。音频编解码器3740可用于对音频信号进行译码及/或解码。音频编解码器3740可耦合到至少一个扬声器3732、听筒3734、输出插孔3736及/或至少一个麦克风3738。扬声器3732可包含一或多个将电或电子信号转换为声学信号的电声转换器。举例来说,扬声器3732可用于播放音乐或输出扬声器电话对话等。听筒3734可为可用于将声学信号(例如,话语信号)输出至用户的另一扬声器或电声转换器。举例来说,可使用听筒3734使得仅用户可确实地听到声学信号。输出插孔3736可用于将其它装置(例如头戴式耳机)耦合到无线通信装置3730以用于输出音频。扬声器3732、听筒3734及/或输出插孔3736可通常用于从音频编解码器3740输出音频信号。至少一个麦克风3738可为将声学信号(例如用户的语音)转换为提供至音频编解码器3740的电或电子信号的声电转换器。在一些配置中,音频编解码器3740可包含话语评估器A3768a。话语评估器A3768a可执行程序及/或功能中的一或多者,及/或可包含结合图4至27及31至36中的一或多者所描述的模块及/或组件中的一或多者。具体来说,话语评估器A3768a可提取一或多个特征及/或可测量话语信号质量。另外或或者,应用处理器3742可包含话语评估器B3768b。话语评估器B3768b可执行程序及/或功能中的一或多者,及/或可包含结合话语评估器A3768a所描述的模块及/或组件中的一或多者。应用处理器3742还可耦合到功率管理电路3752。功率管理电路3752的一个实例为功率管理集成电路(PMIC),其可用于管理无线通信装置3730的电功率消耗。功率管理电路3752可耦合到电池3754。电池3754可通常将电能提供至无线通信装置3730。举例来说,电池3754及/或功率管理电路3752可耦合到包含于无线通信装置3730中的元件中的至少一者。应用处理器3742可耦合到至少一个输入装置3756以用于接收输入。输入装置3756的实例包含红外传感器、图像传感器、加速度计、触摸传感器、小键盘等。输入装置3756可允许用户与无线通信装置3730交互。应用处理器3742还可耦合到一或多个输出装置3758。输出装置3758的实例包含打印机、投影仪、屏幕、触觉裝置等。输出装置3758可允许无线通信装置3730产生可由用户体验的输出。应用处理器3742可耦合到应用存储器3760。应用存储器3760可为能够存储电子信息的任何电子装置。应用存储器3760的实例包含双数据速率同步动态随机存取存储器(DDRSDRAM)、同步动态随机存取存储器(SDRAM)、快闪存储器等。应用存储器3760可提供用于应用处理器3742的存储器。举例来说,应用存储器3760可存储在应用处理器3742上运行的程序的功能的数据及/或指令。应用处理器3742可耦合到显示控制器3762,所述显示控制器又可耦合到显示器3764。显示控制器3762可为用于在显示器3764上产生图像的硬件块。举例来说,显示控制器3762可将来自应用处理器3742的指令及/或数据转译为可呈现在显示器3764上的图像。显示器3764的实例包含液晶显示器(LCD)面板、发光二极管(LED)面板、阴极射线管(CRT)显示器、等离子显示器等。应用处理器3742可耦合到基带处理器3744。基带处理器3744通常处理通信信号。举例来说,基带处理器3744可对所接收的信号进行解调及/或解码。另外或或者,基带处理器3744可对信号进行编码及/或调制以准备发射。基带处理器3744可耦合到基带存储器3766。基带存储器3766可为能够存储电子信息的任何电子装置,例如SDRAM、DDRAM、快闪存储器等。基带处理器3744可从基带存储器3766读取信息(例如,指令及/或数据)及/或将信息写入至所述基带存储器。另外或或者,基带处理器3744可使用存储于基带存储器3766中的指令及/或数据来执行通信操作。基带处理器3744可耦合到射频(RF)收发器3746。RF收发器3746可耦合到功率放大器3748及一或多个天线3750。RF收发器3746可发射及/或接收射频信号。举例来说,RF收发器3746可使用功率放大器3748及至少一个天线3750发射RF信号。RF收发器3746还可使用一或多个天线3750接收RF信号。图38说明可包含于电子装置/无线装置3868内的某些组件。电子装置/无线装置3868可为接入终端、移动台、用户设备(UE)、基站、接入点、广播发射器、节点B、演进节点B、服务器、计算机、路由器、交换机等。电子装置/无线装置3868可根据本文所描述的电子装置556、1507中的一或多者而实施。电子装置/无线装置3868包含处理器3884。处理器3884可为通用单或多芯片微处理器(例如,ARM)、专用微处理器(例如,数字信号处理器(DSP))、微控制器、现场可编程门阵列(FPGA)等。处理器3884可被称为中央处理单元(CPU)。虽然电子装置/无线装置3868中展示单一处理器3884,在替代配置中,可使用处理器(例如,ARM、DSP及FPGA)的组合。电子装置/无线装置3868还包含存储器3870。存储器3870可为能够存储电子信息的任何电子装置。存储器3870可体现为随机存取存储器(RAM)、只读存储器(ROM)、磁盘存储媒体、光学存储媒体、RAM中的快闪存储器裝置、处理器3884包含的机载存储器、EPROM存储器、EEPROM存储器、寄存器等,包含其组合。数据3874a和指令3872a可存储于存储器3870中。指令3872a可能可由处理器3884执行以实施本文所公开的方法中的一或多者。执行指令3872a可涉及存储于存储器3870中的数据3874a的使用。当处理器3884执行指令3872a时,指令3872b的不同部分可载入到处理器3884上,且数据3874b的不同片段可载入到处理器3884上。电子装置/无线装置3868还可包含发射器3876和接收器3878以允许将信号发射至电子装置/无线装置3868且从所述电子装置/无线装置接收信号。发射器3876和接收器3878可统称为收发器3888。一或多个天线3886a至3886n可电耦合到收发器3888。电子装置/无线装置3868还可包含(图中未展示)多个发射器、多个接收器、多个收发器及/或额外天线。电子装置/无线装置3868可包含数字信号处理器(DSP)3880。电子装置/无线装置3868还可包含通信接口3882。通信接口3882可允许用户与电子装置/无线装置3868交互。电子装置/无线装置3868的各种组件可通过一或多个总线耦合在一起,所述总线可包含电源总线、控制信号总线、状态信号总线、数据总线3874等。为清楚起见,各种总线在图38中图示为总线系统3890。在以上描述中,有时结合各种术语而使用参考标号。在术语是结合参考标号使用的情形下,此可意图指代图中的一或多者中所示的特定元件。在无参考标号的情况下使用术语的情形下,此可意在总体上指代术语,而不限于任何特定图。术语“确定”涵盖许多种类的动作,且因此“确定”可包含计算、估算、处理、导出、调查、查找(例如,在表、数据库或另一数据结构中查找)、查实等。又,“确定”可包括接收(例如,接收信息)、存取(例如,在存储器中存取数据)等等。并且,“确定”可包含解析、选择、挑选、建立及类似者。除非以其它方式明确地指定,否则短语“基于”并不意味着“仅基于”。换句话说,短语“基于”描述“仅基于”和“基于至少”两者。应注意,在相容的情况下,结合本文中所描述的配置中的任一者所描述的特征、功能、程序、组件、元件、结构等中的一或多者可与结合本文中所描述的其它配置中的任一者所描述的功能、程序、组件、元件、结构等中的一或多者进行组合。换句话说,可根据本文中揭示的系统和方法来实施本文中所描述的功能、程序、组件、元件等的任何相容的组合。可将本文中所描述的功能作为一或多个指令存储在处理器可读或计算机可读媒体上。术语“计算机可读媒体”是指可由计算机或处理器存取的任何可用媒体。借助于实例而非限制,此类媒体可包括RAM、ROM、EEPROM、快闪存储器、CD-ROM或其它光盘存储装置、磁盘存储装置或其它磁性存储装置或任何其它可用来存储指令或数据结构的形式的期望程序代码并且可由计算机存取的媒体。如本文中所使用,磁盘和光盘包含压缩光盘(CD)、激光光盘、光学光盘、数字多功能光盘(DVD)、软磁盘和光盘,其中磁盘通常以磁性方式再现数据,而光盘用激光以光学方式再现数据。应注意,计算机可读媒体可为有形且非暂时性的。术语“计算机程序产品”是指计算装置或处理器,其与可由计算装置或处理器执行、处理或计算的代码或指令(例如,“程序”)结合。如本文所使用,术语“代码”可指可由计算装置或处理器执行的软件、指令、代码或数据。还可通过传输介质发射软件或指令。举例来说,如果使用同轴电缆、光纤电缆、双绞线、数字订户线路(DSL)或无线技术(例如,红外线、无线电及微波)从网站、服务器或其它远程源传输软件,则同轴电缆、光纤电缆、双绞线、DSL或无线技术(例如,红外线、无线电及微波)包含在传输媒体的定义中。本文中所揭示的方法包含用于实现所描述的方法的一或多个步骤或动作。在不脱离所附权利要求书的范围的情况下,所述方法步骤及/或动作可彼此互换。换句话说,除非正描述的方法的适当操作需要步骤或动作的特定次序,否则,在不脱离权利要求书的范围的情况下,可修改特定步骤及/或动作的次序及/或使用。应理解,权利要求书不限于上文所说明的精确配置和组件。在不脱离权利要求书的范围的情况下,可在本文中所描述的系统、方法及设备的布置、操作及细节方面进行各种修改、改变及变化。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1