一种声音转换方法及装置与流程
本发明涉及一种转换技术,尤其是一种声音转换方法及装置,属于语音信号处理技术领域。
背景技术:
声音转换是声音信号处理领域近年来新兴的研究分支,声音转换技术是指在保持语义内容不变的情况下,通过改变一个源说话人的语音个性特征,使他说的话被听者认为是目标说话人说的话。经过多年发展,声音转换领域已涌现出大量算法,但这些算法只能针对一对一进行转换,转换过程训练阶段需要大量对齐语料,运算复杂度高,这给实际应用带来很大的不便。
技术实现要素:
本发明为解决上述技术问题,提供一种声音转换方法及装置,可以实现将任意一源说话人的声音转换为具有中间说话人音色的声音,并进一步实现将任意一源说话人的声音转换为具有任意一目标说话人音色的声音。
为达到上述目的,本发明公开了一种声音转换方法,为了实现将任意一源说话人的声音转换为具有中间说话人音色的声音,采用的技术方案为:
一种声音转换方法,包括步骤:
对参考源说话人语料和中间说话人第一语料分别提取声音特征系数,并建立第一联合高斯混合模型,其中参考源说话人的数量为2个以上;
提取待转换源说话人语料的声音特征系数,采用待转换源说话人语料的声音特征系数对第一联合高斯混合模型进行自适应得到第一转换模型,所述第一转换模型为待转换源说话人与中间说话人的声音转换模型;
通过第一转换模型将待转换源说话人的声音转换为具有中间说话人音色的声音。
本发明进一步优化,为了实现将任意一源说话人的声音转换为具有任意一目标说话人音色的声音,还包括步骤:
对中间说话人第二语料与参考目标说话人语料分别提取声音特征系数,并建立第二联合高斯混合模型,其中参考目标说话人的数量为2个以上;
提取待转换目标说话人语料的声音特征系数,采用待转换目标说话人语料的声音特征系数对第二联合高斯混合模型进行自适应得到第二转换模型,所述第二转换模型为中间说话人与待转换目标说话人的声音转换模型;
通过第一转换模型将待转换源说话人的声音转换为具有中间说话人音色的声音之后,再通过第二转换模型将具有中间说话人音色的声音转换为具有待转换目标说话人音色的声音。
本发明进一步优化,为了实现将任意一源说话人的声音转换为具有中间说话人音色的声音,具体步骤包括:
提取预存储的S个参考源说话人语料与中间说话人第一语料的梅尔倒谱MCEP系数,S大于20;
采用动态时间规整算法对S个参考源说话人语料与中间说话人第一语料的梅尔倒谱MCEP系数分别进行对齐并组合,构成联合特征矢量,所述S个参考源说话人与中间说话人的语料内容相同;
对S个参考源说话人与中间说话人的联合特征矢量建立参考源说话人无关的联合高斯混合模型;
提取待转换源说话人语料的梅尔倒谱MCEP系数,利用所述梅尔倒谱MCEP系数对参考源说话人无关的联合高斯模型中的参考源说话人均值部分进行自适应,得到待转换源说话人与中间说话人的第一转换模型;
提取待转换源说话人的待转换声音的梅尔倒谱MCEP系数后,并通过自适应后的第一转换模型进行转换,得到转换后的梅尔倒谱MCEP系数;
将转换后的梅尔倒谱MCEP系数与待转换源说话人的梅尔倒谱MCEP系数作差分并构建梅尔对数谱MLSA滤波器,利用所述滤波器对待转换源说话人声音信号进行滤波,得到具有中间说话人音色的声音。
本发明进一步优化,所述“利用所述梅尔倒谱MCEP系数对与参考源说话人无关的联合高斯模型中的源说话人均值部分进行自适应,得到待转换源说话人与中间说话人的转换模型”包括:
将参考源说话人无关的联合高斯模型拆分,抽取联合高斯模型中的参考源说话人均值部分以及参考源说话人协方差部分,构建参考源说话人无关的高斯混合模型;
利用待转换源说话人语料的梅尔倒谱MCEP系数对参考源说话人无关的高斯混合模型做MLLR均值自适应得到待转换源说话人均值矢量;
将待转换源说话人均值矢量替换联合高斯混合模型中的参考源说话人均值部分,得到待转换源说话人与中间说话人的联合高斯模型。
本发明进一步优化,为实现将任意一源说话人的声音转换为具有任意一目标说话人音色的声音,具体步骤还包括:
提取预存储的中间说话人第二语料与S个参考目标说话人语料的梅尔倒谱MCEP系数,S大于20;
采用动态时间规整算法对中间说话人第二语料与S个参考目标说话人语料的梅尔倒谱MCEP系数分别进行对齐并组合,构成联合特征矢量,所述中间说话人与S个参考目标说话人的语料内容相同;
对中间说话人与参考目标说话人联合特征矢量建立参考目标说话人无关的联合高斯混合模型;
提取待转换目标说话人语料的梅尔倒谱MCEP系数,利用所述梅尔倒谱MCEP系数对参考目标说话人无关的联合高斯模型中的参考目标说话人均值部分进行自适应,得到中间说话人与待转换目标说话人的第二转换模型;
在通过第一转换模型将待转换源说话人的声音转换为具有中间说话人音色的声音后,提取具有中间说话人音色的声音的梅尔倒谱MCEP系数,并通过自适应后的第二转换模型进行转换,得到转换后的梅尔倒谱MCEP系数;
将转换后的梅尔倒谱MCEP系数与具有中间说话人音色的声音的梅尔倒谱MCEP系数作差分并构建梅尔对数谱MLSA滤波器,利用所述滤波器对具有中间说话人音色的声音信号进行滤波,从而得到具有待转换目标说话人音色的声音。
本发明进一步优化,所述“利用所述梅尔倒谱MCEP系数对与参考目标说话人无关的联合高斯模型中的参考目标说话人均值部分进行自适应,得到中间说话人与待转换目标说话人的转换模型”包括:
将参考目标说话人无关的联合高斯模型拆分,抽取联合高斯模型中的参考目标说话人均值部分以及目标说话人协方差部分,构建参考目标说话人无关的高斯混合模型;
利用待转换目标说话人的梅尔倒谱MCEP系数对参考目标说话人无关的高斯混合模型做MLLR均值自适应得到待转换目标说话人的均值矢量;
将待转换目标说话人的均值矢量替换联合高斯混合模型中的参考目标说话人均值部分,得到中间说话人与待转换目标说话人的联合高斯模型。
本发明进一步优化,所述提取梅尔倒谱MCEP系数步骤包括:利用STRAIGHT分析合成器对声音按帧分析,得到静态频谱包络,根据所述静态频谱包络提取梅尔倒谱MCEP系数。
为达到上述目的,本发明还公开了一种声音转换装置,为了实现将任意一源说话人的声音转换为具有中间说话人音色的声音,采用的技术方案为:
第一提取模块,用于提取参考源说话人、中间说话人和待转换源说话人的声音特征系数;
第一联合高斯混合模型建立模块,用于通过提取模块得到的参考源说话人语料和中间说话人第一语料的声音特征系数,来建立参考源说话人和中间说话人的第一联合高斯混合模型;
第一自适应模块,用于通过第一提取模块得到的待转换源说话人语料的声音特征系数对第一联合高斯混合模型自适应,得到第一转换模型,所述第一转换模型为待转换源说话人与中间说话人的声音转换模型;
第一转换模块,用于通过第一转换模型将待转换源说话人的声音转换为具有中间说话人音色的声音。
本发明进一步优化,为了实现将任意一源说话人的声音转换为具有任意一目标说话人音色的声音,还包括:
第二提取模块,用于提取中间说话人、参考目标说话人、待转换目标说话人的声音特征系数;
第二联合高斯混合模型建立模块,用于通过所述第二提取模块得到的中间说话人第二语料和参考目标说话人语料的声音特征系数建立中间说话人和参考目标说话人的第二联合高斯混合模型;
第二自适应模块,用于通过第二提取模块得到的待转换目标说话人语料的声音特征系数对第二联合高斯混合模型自适应,得到第二转换模型,所述第二转换模型为中间说话人与待转换目标说话人的声音转换模型;
第二转换模块,用于通过第一转换模型把待转换源说话人的声音转换为具有中间说话人音色的声音之后,再通过第二转换模型把具有中间说话人音色的声音转换为具有待转换目标说话人音色的声音;
本发明进一步优化,所述第一联合高斯混合模型建立模块,具体用于:
通过第一提取模块,提取预存储的S个参考源说话人语料与中间说话人第一语料的梅尔倒谱梅尔倒谱MCEP系数,S大于20;
采用动态时间规整算法对S个参考源说话人语料与中间说话人第一语料的梅尔倒谱MCEP系数分别进行对齐并组合,构成联合特征矢量,所述S个参考源说话人与中间说话人的语料内容相同;
对S个参考源说话人与中间说话人的联合特征矢量建立参考源说话人无关的联合高斯混合模型。
所述第一自适应模块,具体用于:
通过第一提取模块,提取待转换源说话人语料的梅尔倒谱MCEP系数,利用所述梅尔倒谱MCEP系数对参考源说话人无关的联合高斯模型中的参考源说话人均值部分进行自适应,得到待转换源说话人与中间说话人的第一转换模型;
所述第一转换模块,具体用于:
通过第一提取模块,提取待转换源说话人的待转换声音的梅尔倒谱MCEP系数,并通过第一转换模型进行转换,得到转换后的梅尔倒谱MCEP系数;
将转换后的梅尔倒谱MCEP系数与待转换源说话人的梅尔倒谱MCEP系数作差分并构建梅尔对数谱MLSA滤波器,利用所述滤波器对待转换源说话人声音信号进行滤波,得到具有中间说话人音色的声音;
本发明进一步优化,所述第一自适应模块,具体还用于:
将参考源说话人无关的联合高斯模型拆分,抽取联合高斯模型中的参考源说话人均值部分以及参考源说话人协方差部分,构建参考源说话人无关的高斯混合模型;
利用待转换源说话人语料的梅尔倒谱MCEP系数对参考源说话人无关的高斯混合模型做MLLR均值自适应得到待转换源说话人均值矢量;
将待转换源说话人均值矢量替换联合高斯混合模型中的参考源说话人均值部分,得到待转换源说话人与目标说话人的联合高斯模型;
本发明进一步优化,所述第二联合高斯混合模型建立模块,具体用于:
通过第二提取模块,提取预存储的中间说话人第二语料与S个参考目标说话人语料的梅尔倒谱MCEP系数,S大于20;
采用动态时间规整算法对中间说话人第二语料与S个参考目标说话人语料的梅尔倒谱MCEP系数分别进行对齐并组合,构成联合特征矢量,所述中间说话人与S个参考目标说话人的语料内容相同;
对中间说话人与参考目标说话人联合特征矢量建立参考目标说话人无关的联合高斯混合模型;
所述第二自适应模块,具体用于:通过第二提取模块,提取待转换目标说话人语料的梅尔倒谱MCEP系数,利用所述梅尔倒谱MCEP系数对参考目标说话人无关的联合高斯模型中的参考目标说话人均值部分进行自适应,得到中间说话人与待转换目标说话人的第二转换模型;
所述第二转换模块,具体用于:
通过第一转换模型将待转换源说话人的声音转换为具有中间说话人音色的声音之后,再通过第二提取模块提取具有中间说话人音色的声音的梅尔倒谱MCEP系数,并将所述梅尔倒谱MCEP系数通过第二转换模型进行转换,得到转换后的梅尔倒谱MCEP系数;
将转换后的梅尔倒谱MCEP系数与具有中间说话人音色的声音的梅尔倒谱MCEP系数作差分并构建梅尔对数谱MLSA滤波器,利用所述滤波器对具有中间说话人音色的声音信号进行滤波,从而得到具有待转换目标说话人音色的声音。
本发明进一步优化,所述第二自适应模块,具体还用于:
将参考目标说话人无关的联合高斯模型拆分,抽取联合高斯模型中的参考目标说话人均值部分以及目标说话人协方差部分,构建参考目标说话人无关的高斯混合模型;
利用待转换目标说话人的梅尔倒谱MCEP系数对参考目标说话人无关的高斯混合模型做MLLR均值自适应得到待转换目标说话人的均值矢量;
将待转换目标说话人的均值矢量替换联合高斯混合模型中的参考目标说话人均值部分,得到中间说话人与待转换目标说话人的联合高斯模型;
本发明进一步优化,所述第一提取模块或所述第二提取模块,具体还用于:利用STRAIGHT分析合成器对声音按帧分析,得到静态频谱包络,根据所述静态频谱包络提取梅尔倒谱MCEP系数;
本发明的有益效果为:
1、提出一种多对一声音转换方法,即将任意一源说话人的声音转换为具有中间说话人(特定目标说话人)音色的声音;同时提出一种多对多声音转换方法,即将任意一源说话人的声音转换为具有任意一目标说话人音色的声音;本发明方法也适用于歌唱声音的转换。
2、现有技术大都只能将某一个特定源说话人的声音转换成另一个特定目标说话人的声音,且需要大量对称语料才能训练得到转换模型,运算复杂度极高,而本发明的算法自适应过程不需要对称语料即可得到转换模型,且要求的语料数据量不多,估计的参数少,运算复杂度低,便于实际应用。
3、利用STRAIGHT分析合成器进行分析并提取梅尔倒谱系数,可提高重建声音的自然度。
4、声音合成采用MLSA滤波器,可以极大提高转换后声音的质量。
附图说明
图1为本发明实施例1所述声音转换方法的流程图;
图2为本发明实施例2所述声音转换方法的流程图;
图3为本发明实施例3所述声音转换装置的模块图。
图4为本发明实施例4所述声音转换装置的模块图。
具体实施方式
为详细说明本发明的技术内容、构造特征、所实现目的及效果,以下结合实施方式并配合附图详予说明。
实施例1
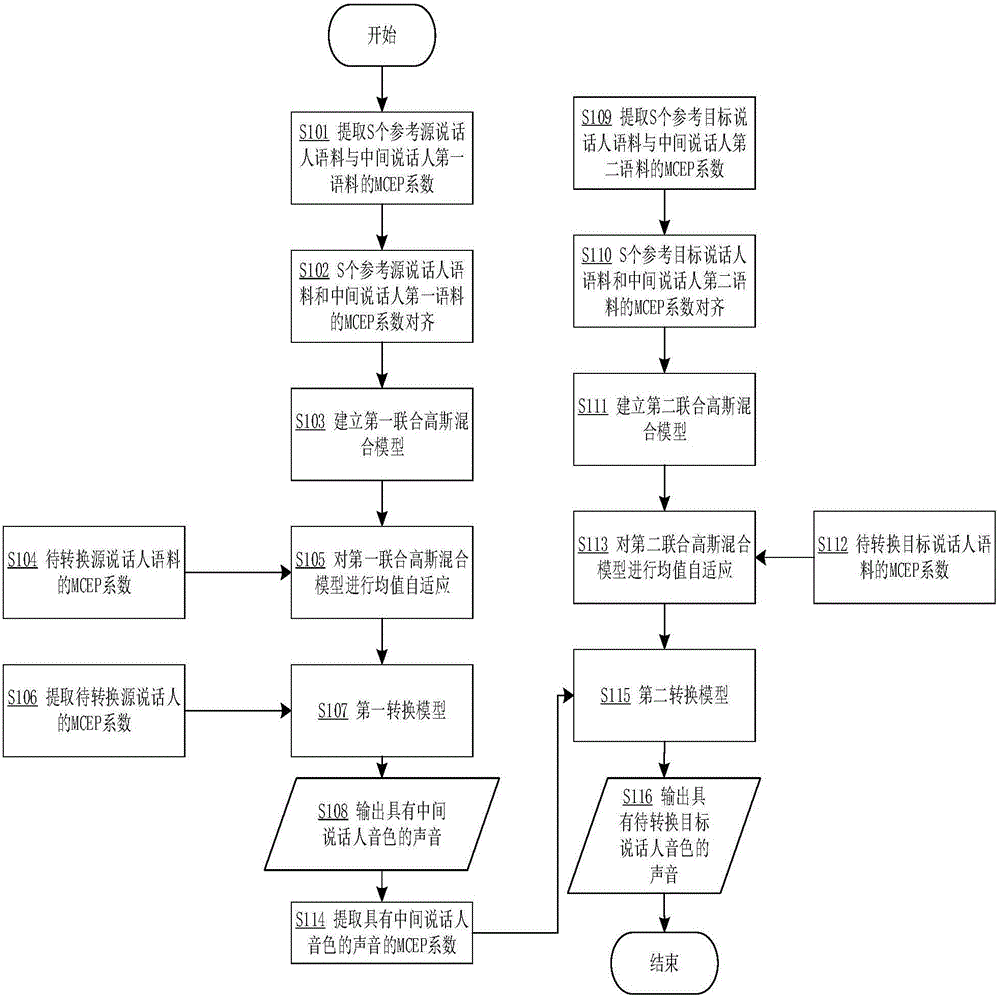
本实施例可以实现将任意一源说话人的声音转换为具有中间说话人(特定目标说话人)音色的声音,请参阅图1,包括训练阶段、自适应阶段以及转换阶段。
训练阶段:对参考源说话人语料和中间说话人第一语料分别提取声音特征系数,并建立第一联合高斯混合模型,其中参考源说话人的数量为2个以上,包括步骤S101-S103。
步骤S101:
利用STRATIGHT分析合成器分别对预存储的S个参考源说话人语料和中间说话人第一语料按帧分析,得到静态频谱包络,并根据静态频谱包络提取梅尔倒谱MCEP系数。本实施例梅尔倒谱MCEP系数取40维。S通常大于20。
步骤S102:
采用动态时间规整算法(DTW)对S个参考源说话人语料和中间说话人第一语料的梅尔倒谱MCEP系数Xt与Yt分别进行对齐并组合,构成联合特征矢量S个参考源说话人与中间说话人的语料是对称的,即内容相同。
步骤S103:
建立第一联合高斯混合模型,具体如下:
对S个参考源说话人与中间说话人联合特征矢量建立第一联合高斯混合模型JDGMM:其中Ts是总的帧数,λ1(0)是与参考源说话人无关的联合高斯混合模型。M为高斯混合度,αi为混合权值,μi与∑i分别为第i个混合成分对应的均值和协方差矩阵,其中:分别为多参考源说话人和中间说话人第i个混合成分的均值向量;为多参考源说话人第i个混合成分的协方差矩阵,为多参考源说话人和中间说话人第i个混合成分的互协方差矩阵。
自适应阶段:提取待转换源说话人的语料的声音特征系数,采用待转换源说话人语料的声音特征系数对第一联合高斯混合模型进行自适应得到第一转换模型,所述第一转换模型为待转换源说话人与中间说话人的声音转换模型,包括步骤S104-S105。
步骤S104:
如步骤S101的方法提取待转换源说话人语料的梅尔倒谱MCEP系数。
步骤S105:
利用步骤S104提取的梅尔倒谱MCEP系数对第一联合高斯模型中的参考源说话人均值部分进行自适应,从而得到待转换源说话人与中间说话人的频谱特征转换模型,既第一转换模型。自适应过程如下:
将参考源说话人无关的联合高斯模型拆分,抽取联合高斯模型中的参考源说话人均值部分以及参考源说话人协方差部分,构建参考源说话人无关的高斯混合模型GMM:λ'1(α,μX,∑XX),
接着利用待转换源说话人语料的梅尔倒谱MCEP系数对GMM做MLLR均值自适应得到待转换源说话人的均值矢量
然后将待转换源说话人的均值矢量替换联合高斯混合模型中的参考源说话人均值部分,得到新联合均值矢量:从而得到待转换源说话人与中间说话人的联合高斯模型λ1o(α,μo,∑)。在其他实施方式中,也可以采用MAP算法做均值自适应。
本发明自适应的过程对声音内容没有限制,即待转换源说话人与中间说话人的声音内容可以不同,可以在非平行文本条件下进行,而且自适应过程需要估计的参数较少,要求的数据量不多,因此运算速度较快。
转换阶段:通过第一转换模型将待转换源说话人的声音转换为具有中间说话人音色的声音,包括步骤S106-S108。
步骤S106:
如步骤S101的方法提取待转换源说话人的待转换声音的梅尔倒谱MCEP系数。
步骤S107:
通过自适应后的模型λo进行转换。转换函数为:其中pi(X)为频谱特征X属于模型(α,μX,∑XX)第i个混合成分的概率。
步骤S108:
将转换后的中间说话人梅尔倒谱MCEP系数与待转换源说话人的梅尔倒谱MCEP系数作差分并构建MLSA滤波器,使用这个滤波器直接对待转换源说话人的待转换声音信号进行滤波,从而得到高质量的具有中间说话人音色的声音。
声音转换一般要求在转换频谱包络的同时也要转换基频,但基频在提取以及用于合成声音时,会引起误差的存在,从而影响转换声音的自然度,本发明用一种新的合成方法来提高转换声音的质量,即将转换后的频谱特征与源说话人的声音频谱特征作差分并构建MLSA滤波器,使用这个滤波器直接对源说话人声音信号进行滤波,可以极大的提高合成声音的自然度。本实施例采用开源工具SPTK中的MLSA滤波器。
本实施例采用上述方法,可实现将任意一源说话人的声音转换为具有中间说话人(特定目标说话人)音色的声音。
实施例2
本实施为了实现将任意一源说话人的声音转换为具有任意一目标说话人音色的声音,参阅图2,包括训练阶段、自适应阶段以及转换阶段。
训练阶段:包括训练得到第一联合高斯模型与第二联合高斯模型(不分先后顺序),具体如下:
对参考源说话人语料和中间说话人第一语料分别提取声音特征系数,并建立第一联合高斯混合模型,其中参考源说话人的数量为2个以上,包括步骤S101-S103。
对中间说话人第二语料与参考目标说话人语料分别提取声音特征系数,并建立第二联合高斯混合模型,其中参考目标说话人的数量为2个以上,包括步骤S109-S111。
本实施例中,中间说话人第一语料与中间说话人第二语料可以相同,也可以不同。
步骤S109:
利用STRAIGHT分析合成器分别对中间说话人第二语料和S个参考目标说话人的语料按帧分析,得到静态频谱包络,并根据静态频谱包络提取梅尔倒谱MCEP系数。本实施例梅尔倒谱MCEP系数取40维。S通常大于20。
步骤S110:
采用动态时间规整算法(DTW)对中间说话人第二语料和S个参考目标说话人语料的梅尔倒谱MCEP系数Xt与Yt分别进行对齐并组合,构成联合特征矢量S个参考目标说话人与中间说话人的语料是对称的,即语料内容相同。
步骤S111:
建立第二联合高斯混合模型,具体如下:
对中间说话人和S个参考目标说话人联合特征矢量建立第二联合高斯混合模型JDGMM:其中Ts是总的帧数,λ2(0)是与参考目标说话人无关的联合高斯混合模型。M为高斯混合度,αi为混合权值,μi与∑i分别为第i个混合成分对应的均值和协方差矩阵,其中分别为中间说话人和多参考目标说话人第i个混合成分的均值向量;为中间说话人第i个混合成分的协方差矩阵,为中间说话人和多参考目标说话人第i个混合成分的互协方差矩阵。
自适应阶段:训练阶段结束后进入自适应阶段,包括自适应生成第一转换模型与第二转换模型(不分先后顺序),具体如下:
提取待转换源说话人的语料的声音特征系数,采用待转换源说话人的语料的声音特征系数对第一联合高斯混合模型进行自适应得到第一转换模型,所述第一转换模型为待转换源说话人与中间说话人的声音转换模型,包括步骤S104-S105。
提取待转换目标说话人语料的声音特征系数,采用待转换目标说话人语料的声音特征系数对第二联合高斯混合模型进行自适应得到第二转换模型,所述第二转换模型为中间说话人与待转换目标说话人的声音转换模型,包括步骤S112-S113。
步骤S112:
如步骤S101的方法提取待转换目标说话人语料的梅尔倒谱MCEP系数。
步骤S113:
利用步骤S112提取的梅尔倒谱MCEP系数对联合高斯模型中的待转换目标说话人均值部分进行自适应,从而得到中间说话人与待转换目标说话人的频谱特征转换模型,既第二转换模型。自适应过程如下:
将参考目标说话人无关的联合高斯模型拆分,抽取联合高斯模型中的参考目标说话人均值部分以及目标说话人协方差部分,构建参考目标说话人无关的高斯混合模型GMM:λ'2(α,μY,∑YY);
利用待转换目标说话人的梅尔倒谱MCEP系数对参考目标说话人无关的高斯混合模型做MLLR均值自适应得到待转换目标说话人的均值矢量
将待转换目标说话人的均值矢量替换联合高斯混合模型中的参考目标说话人均值部分,得到新联合均值矢量:从而得到中间说话人与待转换目标说话人的联合高斯模型λ2o(α,μo,∑)。在其他实施方式中,也可以采用MAP算法做均值自适应。
本发明自适应的过程对声音内容没有限制,即待转换目标说话人与中间说话人的声音内容可以不同,可以在非平行文本条件下进行,而且自适应过程需要估计的参数较少,要求的数据量不多,因此运算速度较快。
转换阶段:自适应阶段完成之后,即可将待转换源说话人的声音进行转换得到具有待转换目标说话人音色的声音,转换过程需要先后通过第一转换模型以及第二转换模型,具体如下:
通过第一转换模型将待转换源说话人的声音转换为具有中间说话人音色的声音之后,包括步骤S106-S108;再通过第二转换模型将具有中间说话人音色的声音转换为具有待转换目标说话人音色的声音,包括步骤S114-S116。
步骤S114:
在经过步骤S108得到具有中间说话人音色的声音后,如步骤S101的方法提取具有中间说话人音色的声音的梅尔倒谱MCEP系数,
步骤S115:
根据自适应后的模型λo,对该梅尔倒谱MCEP系数进行转换。转换函数为:其中pi(X)为频谱特征X属于模型(α,μX,∑XX)第i个混合成分的概率。
步骤S116:
将转换后的梅尔倒谱MCEP系数与具有中间说话人音色的声音的梅尔倒谱MCEP系数作差分并构建MLSA滤波器,使用这个滤波器直接对具有中间说话人音色的声音信号进行滤波,从而得到高质量的具有待转换目标说话人音色的声音。
声音转换一般要求在转换频谱包络的同时也要转换基频,但基频在提取以及用于合成声音时,会引起误差的存在,从而影响转换声音的自然度,本发明用一种新的合成方法来提高转换声音的质量,即将转换后的频谱特征与中间说话人的声音频谱特征作差分并构建MLSA滤波器,使用这个滤波器直接对中间说话人声音信号进行滤波,可以极大的提高合成声音的自然度。本实施例采用开源工具SPTK中的MLSA滤波器。
本实施例中,所述步骤S101-S108的操作与实施例1相同。
本实施例采用上述的技术方案,可实现将任意一源说话人的声音转换为具有任意一目标说话人音色的声音,无需每次音色转化都建一次转化模型,针对多个音色的转化,大大减少了计算量。
在其他实施例中,可省略步骤S108与步骤S114,即不需要重建具有中间说话人音色的声音,而直接将步骤S107转换后的梅尔倒谱MCEP系数输入到步骤S115,并调整步骤S116如下:
将转换后的梅尔倒谱MCEP系数与待转换源说话人声音的梅尔倒谱MCEP系数作差分并构建MLSA滤波器,使用这个滤波器直接对待转换源说话人的声音信号进行滤波,从而得到高质量的具有待转换目标说话人音色的声音。
实施例3
本实施例提供一种声音转换装置,将任意一源说话人的声音转换为具有中间说话人(特定目标说话人)音色的声音,请参阅图3,具体包括:
第一提取模块201:
用于提取参考源说话人、中间说话人和待转换源说话人的声音特征系数,具体如下:
利用STRATIGHT分析合成器分别对预存储的S个参考源说话人语料和中间说话人第一语料按帧分析,得到静态频谱包络,并根据静态频谱包络提取梅尔倒谱MCEP系数。本实施例梅尔倒谱MCEP系数取40维。S通常大于20。
第一联合高斯混合模型建立模块202:
用于通过第一提取模块得到的参考源说话人语料和中间说话人第一语料的声音特征系数,建立参考源说话人和中间说话人的第一联合高斯混合模型,具体如下:
采用动态时间规整算法(DTW)对S个参考源说话人语料和中间说话人第一语料的梅尔倒谱MCEP系数Xt与Yt分别进行对齐并组合,构成联合特征矢量S个参考源说话人与中间说话人的语料是对称的,即内容相同。
对S个参考源说话人与中间说话人联合特征矢量建立第一联合高斯混合模型JDGMM:其中Ts是总的帧数,λ1(0)是与参考源说话人无关的联合高斯混合模型。M为高斯混合度,αi为混合权值,μi与∑i分别为第i个混合成分对应的均值和协方差矩阵,其中:分别为多参考源说话人和中间说话人第i个混合成分的均值向量;为多参考源说话人第i个混合成分的协方差矩阵,为多参考源说话人和中间说话人第i个混合成分的互协方差矩阵。
第一自适应模块203:
用于通过第一提取模块,提取待转换源说话人语料的梅尔倒谱MCEP系数,利用所述梅尔倒谱MCEP系数对第一联合高斯模型中的参考源说话人均值部分进行自适应,从而得到待转换源说话人与中间说话人的频谱特征转换模型,既第一转换模型。自适应过程如下:
将参考源说话人无关的联合高斯模型拆分,抽取联合高斯模型中的参考源说话人均值部分以及参考源说话人协方差部分,构建参考源说话人无关的高斯混合模型GMM:λ'1(α,μX,∑XX),
接着利用待转换源说话人语料的梅尔倒谱MCEP系数对GMM做MLLR均值自适应得到待转换源说话人的均值矢量
然后将待转换源说话人的均值矢量替换联合高斯混合模型中的参考源说话人均值部分,得到新联合均值矢量:从而得到待转换源说话人与中间说话人的联合高斯模型λo1(α,μo,∑)。在其他实施方式中,也可以采用MAP算法做均值自适应。
本发明自适应的过程对声音内容没有限制,即待转换源说话人与中间说话人的声音内容可以不同,可以在非平行文本条件下进行,而且自适应过程需要估计的参数较少,要求的数据量不多,因此运算速度较快。
第一转换模块204:
用于通过第一提取模块,提取待转换源说话人的待转换声音的梅尔倒谱MCEP系数,通过自适应后的模型λo进行转换。转换函数为:其中pi(X)为频谱特征X属于模型(α,μX,∑XX)第i个混合成分的概率。
将转换后的中间说话人梅尔倒谱MCEP系数与待转换源说话人的梅尔倒谱MCEP系数作差分并构建MLSA滤波器,使用这个滤波器直接对待转换源说话人的待转换声音信号进行滤波,从而得到高质量的具有中间说话人音色的声音。
声音转换一般要求在转换频谱包络的同时也要转换基频,但基频在提取以及用于合成声音时,会引起误差的存在,从而影响转换声音的自然度,本发明用一种新的合成方法来提高转换声音的质量,即将转换后的频谱特征与源说话人的声音频谱特征作差分并构建MLSA滤波器,使用这个滤波器直接对源说话人声音信号进行滤波,可以极大的提高合成声音的自然度。本实施例采用开源工具SPTK中的MLSA滤波器。
实施例4
为了实现将任意一源说话人的声音转换为具有任意一目标说话人音色的声音,在实施例3的基础上,还包括以下模块,参阅图4,具体如下:
第二提取模块205:
用于对中间说话人第二语料与参考目标说话人语料分别提取声音特征系数,具体如下:
利用STRAIGHT分析合成器分别对中间说话人第二语料和S个参考目标说话人的语料按帧分析,得到静态频谱包络,并根据静态频谱包络提取梅尔倒谱MCEP系数MCEP。本实施例梅尔倒谱MCEP系数取40维。S通常大于20。
第二联合高斯混合模型建立模块206:
采用动态时间规整算法(DTW)对中间说话人第二语料和S个参考目标说话人语料的梅尔倒谱MCEP系数Xt与Yt分别进行对齐并组合,构成联合特征矢量S个参考目标说话人与中间说话人的语料是对称的,即语料内容相同。
对中间说话人和S个参考目标说话人联合特征矢量建立第二联合高斯混合模型JDGMM:其中Ts是总的帧数,λ2(0)是与参考目标说话人无关的联合高斯混合模型。M为高斯混合度,αi为混合权值,μi与∑i分别为第i个混合成分对应的均值和协方差矩阵,其中为分别中间说话人和多参考目标说话人第i个混合成分的均值向量;为中间说话人第i个混合成分的协方差矩阵,为中间说话人和多参考目标说话人第i个混合成分的互协方差矩阵。
第二自适应模块207:
用于通过第二提取模块,提取待转换目标说话人语料的梅尔倒谱MCEP系数,利用所述梅尔倒谱MCEP系数对联合高斯模型中的待转换目标说话人均值部分进行自适应,从而得到中间说话人与待转换目标说话人的频谱特征转换模型,既第二转换模型。自适应过程如下:
将参考目标说话人无关的联合高斯模型拆分,抽取联合高斯模型中的参考目标说话人均值部分以及目标说话人协方差部分,构建参考目标说话人无关的高斯混合模型GMM:λ'2(α,μY,∑YY);
利用待转换目标说话人的梅尔倒谱MCEP系数对参考目标说话人无关的高斯混合模型做MLLR均值自适应得到待转换目标说话人的均值矢量
将待转换目标说话人的均值矢量替换联合高斯混合模型中的参考目标说话人均值部分,得到新联合均值矢量:从而得到中间说话人与待转换目标说话人的联合高斯模型λo2(α,μo,∑)。在其他实施方式中,也可以采用MAP算法做均值自适应。
本发明自适应的过程对声音内容没有限制,即待转换目标说话人与中间说话人的声音内容可以不同,可以在非平行文本条件下进行,而且自适应过程需要估计的参数较少,且要求的数据量不多,因此运算速度较快。
第二转换模块208:
用于通过第一转换模型将待转换源说话人的声音转换为具有中间说话人音色的声音之后,通过第二提取模块提取具有中间说话人音色的声音的梅尔倒谱MCEP系数,通过自适应后的模型λo对所述梅尔倒谱MCEP系数进行转换。转换函数为:其中pi(X)为频谱特征X属于模型(α,μX,∑XX)第i个混合成分的概率。
将转换后的梅尔倒谱MCEP系数与具有中间说话人音色的声音的梅尔倒谱MCEP系数作差分并构建MLSA滤波器,使用这个滤波器直接对具有中间说话人音色的声音信号进行滤波,从而得到高质量的具有待转换目标说话人音色的声音。
声音转换一般要求在转换频谱包络的同时也要转换基频,但基频在提取以及用于合成声音时,会引起误差的存在,从而影响转换声音的自然度,本发明用一种新的合成方法来提高转换声音的质量,即将转换后的频谱特征与中间说话人声音的频谱特征作差分并构建MLSA滤波器,使用这个滤波器直接对中间说话人声音信号进行滤波,可以极大的提高合成声音的自然度。本实施例采用开源工具SPTK中的MLSA滤波器。
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!