语音情感辨识系统及方法与流程
本发明涉及一种语音情感辨识系统及方法。
背景技术:
语音情感辨识是指机器接收人类发出的语音信号,并对该语音信号中的情感进行辨识,从而更加灵活地执行人类发出的指令。
目前,语音情感辨识系统通常采用对语音信号的声学特征进行统计计算与分析,从而判断出语音信号的情感,其缺点在于,情感辨识率低。
技术实现要素:
本发明要解决的技术问题是提供一种语音情感辨识系统及方法,从语音信号的声学韵律特征对语音信号的情感进行辨识,同时还将语音信号转换成文本序列,并从文本序列中提取语义标签以实现对语音信号进行情感辨识,再将通过声学韵律特征获得的辨识结果与通过语义标签获得的辨识结果进行加权和计算,以获得最终的语音信号的辨识结果,从多个角度对语音信号进行分析,可以提高语音情感辨识率。
为解决上述技术问题,本发明提供的技术方案是:
一方面,提供一种语音情感辨识系统,包括:语音接收器,第一情感辨识子系统,第二情感辨识子系统,情感输出器;语音接收器,用于接收语音信号;第一情感辨识子系统,用于根据语音信号获取第一情感辨识结果;第二情感辨识子系统,用于根据语音信号获取第二情感辨识结果;情感输出器,用于根据第一情感辨识结果和第二情感辨识结果,确定出语音信号的情感状态。
进一步地,第一情感辨识子系统,具体包括,情感显著性分割器,第一情感辨识器;情感显著性分割器,用于对语音接收器的语音信号提取声学韵律特征;第一情感辨识器,用于根据声学韵律特征获取语音信号的第一情感辨识结果;第二情感辨识子系统,具体包括,语音识别器,语义标签提取器,第二情感辨识器;语音识别器,用于将语音接收器的语音信号转换成文字序列;语义标签提取器,用于提取文字序列中的语义标签;第二情感辨识器,用于根据语义标签获取语音信号的第二情感辨识结果;情感输出器,用于根据第一情感辨识结果和第二情感辨识结果的加权和,确定出语音信号的情感状态。
进一步地,第一情感辨识器,包括,预先训练好的分类器和分类器选择模块;分类器包括GMM分类器,SVM分类器和MLP分类器;分类器选择模块,用于根据GMM分类器,SVM分类器,MLP分类器分别对语音信号的情感识别置信度,从GMM分类器,SVM分类器,和MLP分类器中确定出一个最佳分类器;分类器,用于根据声学韵律特征获取语音信号的第一情感辨识结果。
进一步地,第二情感辨识器,根据语义标签获取语音信号的第二情感辨识结果,具体包括,第二情感辨识器,根据语义标签提取文字序列的情感关联规则,并将情感关联规则与预先获取的情感关联规则库进行匹配,以获得语音信号的第二情感辨识结果。
进一步地,声学韵律特征包括,音高、强度、音质,声谱和倒谱。
进一步地,语义标签为根据互联网数据库的语义标签库提取的文字序列的语义信息。
进一步地,还包括人格特征存储器,人格特征存储器连接于第一情感辨识子系统和第二情感辨识子系统,用于存储说话者的人格特征信息。
另一方面,提供一种语音情感辨识方法,包括:
语音接收器接收语音信号;第一情感辨识子系统根据语音信号获取第一情感辨识结果;第二情感辨识子系统根据语音信号获取第二情感辨识结果;情感输出器根据第一情感辨识结果和第二情感辨识结果,确定出语音信号的情感状态。
进一步地,第一情感辨识子系统根据语音信号获取第一情感辨识结果,具体包括:对语音接收器的语音信号提取声学韵律特征;根据声学韵律特征获取语音信号的第一情感辨识结果;第二情感辨识子系统根据语音信号获取第二情感辨识结果,具体包括:将语音接收器的语音信号转换成文字序列;提取文字序列中的语义标签;根据语义标签获取语音信号的第二情感辨识结果;情感输出器根据第一情感辨识结果和第二情感辨识结果,确定出语音信号的情感状态,具体包括:根据第一情感辨识结果和第二情感辨识结果的加权和,确定出语音信号的情感状态。
进一步地,声学韵律特征包括,音高、强度、音质,声谱和倒谱;语义标签为根据互联网数据库的语义标签库提取的文字序列的语义信息。
本发明提供的语音情感辨识系统及方法,语音接收器接收语音信号;第一情感辨识子系统根据语音信号获取第一情感辨识结果,且与此同时,第二情感辨识子系统根据语音信号获取第二情感辨识结果;最后情感输出器,根据第一情感辨识结果和第二情感辨识结果,确定出语音信号的情感状态。
本发明中,第一情感子系统是通过提取语音信号的声学韵律特征对语音信号的情感进行辨识;第二情感子系统是通过将语音信号转换成文本序列,并从文本序列中提取语义标签以实现对语音信号进行情感辨识;最后情感输出器将通过声学韵律特征获得的辨识结果与通过语义标签获得的辨识结果进行加权和计算,以获得最终的语音信号的辨识结果,从多个角度对语音信号进行分析,可以提高对语音信号的情感辨识率。
附图说明
图1是本发明提供的语音情感辨识系统的框图;
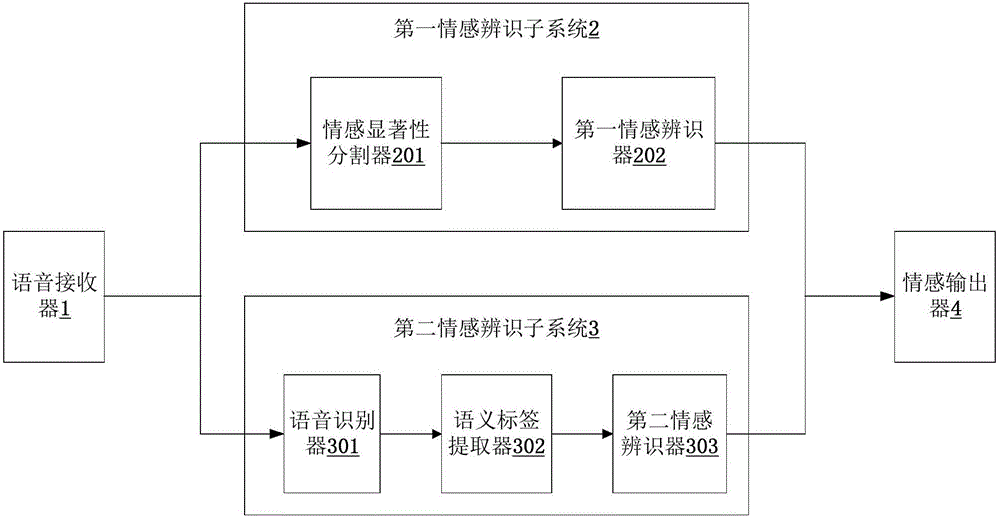
图2是本发明提供的语音情感辨识系统的又一框图;
图3是本发明提供的语音情感辨识方法的流程图;
图4是本发明提供的语音情感辨识方法的又一流程图。
具体实施方式
下面通过具体的实施例进一步说明本发明,但是,应当理解为,这些实施例仅仅是用于更详细具体地说明之用,而不应理解为用于以任何形式限制本发明。
实施例一
结合图1,本实施例提供的语音情感辨识系统,包括:语音接收器1,第一情感辨识子系统2,第二情感辨识子系统3,情感输出器4;语音接收器1,用于接收语音信号;第一情感辨识子系统2,用于根据语音信号获取第一情感辨识结果;第二情感辨识子系统3,用于根据语音信号获取第二情感辨识结果;情感输出器4,用于根据第一情感辨识结果和第二情感辨识结果,确定出语音信号的情感状态。
优选地,如图2所示地,第一情感辨识子系统2,具体包括,情感显著性分割器201,第一情感辨识器202;情感显著性分割器201,用于对语音接收器1的语音信号提取声学韵律特征;第一情感辨识器202,用于根据声学韵律特征获取语音信号的第一情感辨识结果;第二情感辨识子系统3,具体包括,语音识别器301,语义标签提取器302,第二情感辨识器303;语音识别器301,用于将语音接收器1的语音信号转换成文字序列;语义标签提取器302,用于提取文字序列中的语义标签;第二情感辨识器303,用于根据语义标签获取语音信号的第二情感辨识结果;情感输出器4,用于根据第一情感辨识结果和第二情感辨识结果的加权和,确定出语音信号的情感状态。
本发明实施例提供的语音情感辨识系统,语音接收器1接收语音信号;第一情感辨识子系统2根据语音信号获取第一情感辨识结果,且与此同时,第二情感辨识子系统3根据语音信号获取第二情感辨识结果;最后情感输出器4,根据第一情感辨识结果和第二情感辨识结果,确定出语音信号的情感状态。
本发明实施例中,第一情感子系统是通过提取语音信号的声学韵律特征对语音信号的情感进行辨识;第二情感子系统是通过将语音信号转换成文本序列,并从文本序列中提取语义标签以实现对语音信号进行情感辨识;最后情感输出器4将通过声学韵律特征获得的辨识结果与通过语义标签获得的辨识结果进行加权和计算,以获得最终的语音信号的辨识结果,从多个角度对语音信号进行分析,可以提高对语音信号的情感辨识率。
进一步优选地,第一情感辨识器202,包括,预先训练好的分类器和分类器选择模块;分类器包括GMM分类器,SVM分类器和MLP分类器;分类器选择模块,用于根据GMM分类器,SVM分类器,MLP分类器分别对语音信号的情感识别置信度,从GMM分类器,SVM分类器,和MLP分类器中确定出一个最佳分类器;分类器,用于根据声学韵律特征获取语音信号的第一情感辨识结果。
本实施例中,分类器是通过采用公用的语料库中的声学韵律特征训练而成,用于对语音情感状态进行分类识别,从而实现情感辨识。本实施例中训练了三种分类器,高斯混合模型(Gaussian Mixture Model,GMM)分类器,支持向量机(Support Vector Machine,SVM)分类器和多层感知(MultiLayer Perceptron,MLP)分类器,由于一种分类器不能对所有的情感状态都表现出很好的鲁棒性。例如,GMM分类器不能识别中性情感状态,但是MLP分类器却对中性情感状态表现了较高的鲁棒性。也就是说,将多种方法进行一定程度的融合能够比单一方法取得更佳的情感辨识效果。
进一步优选地,第二情感辨识器303,根据语义标签获取语音信号的第二情感辨识结果,具体包括,第二情感辨识器303,根据语义标签提取文字序列的情感关联规则,并将情感关联规则与预先获取的情感关联规则库进行匹配,以获得语音信号的第二情感辨识结果。
本实施例中,在训练阶段,通过采用语料库进行训练,获取一个情感关联规则库,从而在对语音信号进行测试时,只需要提取出文字序列的语义标签,并提取语义标签中的情感关联规则,并将所提取的情感关联规则与情感关联规则库进行匹配计算,从而确定出被测语音信号所对应的情感状态。
优选地,声学韵律特征包括,音高、强度、音质,声谱和倒谱。此外,需要说明的是,还可以采用其他的声学韵律特征,例如,共振峰(Formants),需要结合实际需要进行声学韵律特征的提取,本实施例不做具体限定。
进一步优选地,语义标签为根据互联网数据库的语义标签库提取的文字序列的语义信息。本实施例在训练阶段,是根据互联网数据库(例如,中国知网),提取出一个语义标签库,如此,在对语音信号进行情感辨识测试时,通过提取与语义标签库吻合的语义标签即可。同时,利用所提取的语义标签进行后续的语音情感辨识。
进一步优选地,还包括人格特征存储器,人格特征存储器连接于第一情感辨识子系统2和第二情感辨识子系统3,用于存储说话者的人格特征信息。
本实施例中的人格特征存储器,用于存储某些特定的说话者的人格特征信息,其中,该人格特征信息的获取是通过让说话者完成艾森克人格问卷(Eysenck Personality Questionnaire,EPQ),从而自动判断说话者的独特的人格特征。本实施例中,存储说话者的人格特征信息的作用在于,可以在对某一个说话者个体事先进行EPQ测试从而获得该说话者个体的人格特征,并将该人格特征进行存储,之后,当对该说话者发出的语音信号进行测试时,通过结合所存储的人格特征,可以更好地辨识该说话者发出的语音的情感状态,情感辨识率更高。
实施例二
结合图3,本实施例提供一种语音情感辨识方法,包括:
步骤S1:语音接收器1接收语音信号;
步骤S2:第一情感辨识子系统2根据语音信号获取第一情感辨识结果;
步骤S3:第二情感辨识子系统3根据语音信号获取第二情感辨识结果;
步骤S4:情感输出器4根据第一情感辨识结果和第二情感辨识结果,确定出语音信号的情感状态。
优选地,如图4所示地,第一情感辨识子系统2根据语音信号获取第一情感辨识结果,具体包括:
步骤S2.1:对语音接收器1的语音信号提取声学韵律特征;
步骤S2.2:根据声学韵律特征获取语音信号的第一情感辨识结果;
第二情感辨识子系统3根据语音信号获取第二情感辨识结果,具体包括:
步骤S3.1:将语音接收器1的语音信号转换成文字序列;
步骤S3.2:提取文字序列中的语义标签;
步骤S3.3:根据语义标签获取语音信号的第二情感辨识结果;
情感输出器4根据第一情感辨识结果和第二情感辨识结果,确定出语音信号的情感状态,具体包括:
步骤S4:根据第一情感辨识结果和第二情感辨识结果的加权和,确定出语音信号的情感状态。
本发明实施例提供的语音情感辨识方法,语音接收器1接收语音信号;第一情感辨识子系统2根据语音信号获取第一情感辨识结果,且与此同时,第二情感辨识子系统3根据语音信号获取第二情感辨识结果;最后情感输出器4,根据第一情感辨识结果和第二情感辨识结果,确定出语音信号的情感状态。
本发明实施例中,第一情感子系统是通过提取语音信号的声学韵律特征对语音信号的情感进行辨识;第二情感子系统是通过将语音信号转换成文本序列,并从文本序列中提取语义标签以实现对语音信号进行情感辨识;最后情感输出器4将通过声学韵律特征获得的辨识结果与通过语义标签获得的辨识结果进行加权和计算,以获得最终的语音信号的辨识结果,从多个角度对语音信号进行分析,可以提高对语音信号的情感辨识率。
进一步优选地,声学韵律特征包括,音高、强度、音质,声谱和倒谱;语义标签为根据互联网数据库的语义标签库提取的文字序列的语义信息。
需要说明的是,还可以采用其他的声学韵律特征,例如,共振峰(Formants),需要结合实际需要进行声学韵律特征的提取,本实施例不做具体限定。
此外,语义标签为根据互联网数据库的语义标签库提取的文字序列的语义信息。本实施例在训练阶段,是根据互联网数据库(例如,中国知网),提取出一个语义标签库,如此,在对语音信号进行情感辨识测试时,通过提取与语义标签库吻合的语义标签即可。同时,利用所提取的语义标签进行后续的语音情感辨识。
进一步优选地,还包括人格特征存储器,人格特征存储器连接于第一情感辨识子系统2和第二情感辨识子系统3,用于存储说话者的人格特征信息。
本实施例中的人格特征存储器,用于存储某些特定的说话者的人格特征信息,其中,该人格特征信息的获取是通过让说话者完成艾森克人格问卷(Eysenck Personality Questionnaire,EPQ),从而自动判断说话者的独特的人格特征。本实施例中,存储说话者的人格特征信息的作用在于,可以在对某一个说话者个体事先进行EPQ测试从而获得该说话者个体的人格特征,并将该人格特征进行存储,之后,当对该说话者发出的语音信号进行测试时,通过结合所存储的人格特征,可以更好地辨识该说话者发出的语音的情感状态,情感辨识率更高。
尽管本发明已进行了一定程度的描述,明显地,在不脱离本发明的精神和范围的条件下,可进行各个条件的适当变化。可以理解,本发明不限于所述实施方案,而归于权利要求的范围,其包括所述每个因素的等同替换。
- 还没有人留言评论。精彩留言会获得点赞!