基于理想软阈值掩模IRM的多音频对象编、解码方法与流程
本发明属于音频信号处理
技术领域:
,涉及音频编解码,具体涉及一种适合多音频对象的编解码方法。
背景技术:
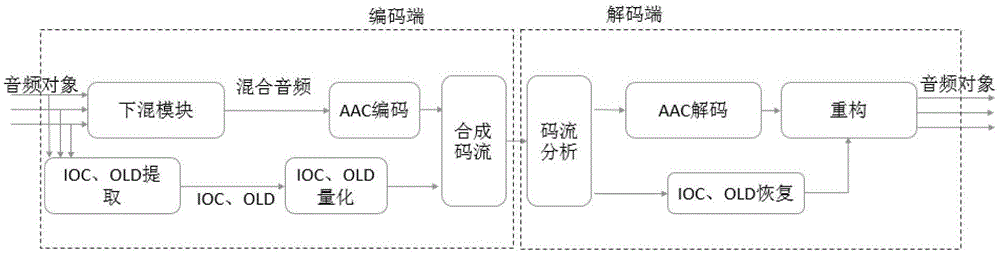
:随着播放设备的飞速发展,由立体声到5.1声道再到几十声道,随之产生了许多种多声道音频编解码技术。多声道编码技术已经能够在高压缩率下高质量的恢复某种特定的音频场景。但面临着人们希望对多种音频混合场景进行自定义渲染的情况,例如将人声放大或缩小,增强某种乐器的强度,多声道音频编解码技术显然不能够满足。针对这样的需求产生了针对多音频对象的编解码技术。多音频对象编码或沿用多声道音频编码技术,求音频对象间的相关系数和强度差;或利用音频对象内部稀疏性。对于多音频对象编解码方法,国内外开展这方面的研究已经有多年的历史。表1总结了近年来的研究发展情况。表1多音频对象编解码的发展以下将简要介绍两种比较有代表性的多音频对象编解码。(1)空间音频对象编解码(SpatialAudioObjectCoding,SAOC)如图1所示,空间音频对象编码沿用多通道编码的提取参数方案,将多个音频对象合成一个下混信号,并提取对象之间的空间参数。下混信号由加和得到;空间参数由通道间的互相关系数和对象强度差异系数构成。空间参数经过量化或熵编码压缩、下混信号通过单通道编码器压缩,一起传送至解码端。解码端通过单通道解码器得到恢复的下混信号,参数部分通过反量化得到空间参数,下混信号和空间参数经过上混过程得到恢复的音频对象。(2)对象内部稀疏性编码(Intra-ObjectSparsityCoding)基于对象内部稀疏性编码方案利用音频信号能量的稀疏性,将音频对象编码成单声道下混信号。不同于SAOC加和方式得到下混信号,这种方式得到的下混信号是不可听的。音频信号能量的稀疏性体现在,每一帧信号的能量主要集中于少量的频带上。因此音频对象经分帧、时频域变换之后,使用VAD技术检测同一帧活跃对象,使用活跃对象主要能量的频带系数重构下混信号;频带位置信息被记录成边信息用于恢复。下混信号经过单通道压缩编码与边信息一同传送至解码端。解码端通过单通道解码得到下混信号,与边信息一起经过上混模块得到重构的音频对象。技术实现要素:类似SAOC对音频对象间提取相关系数及强度差,这种方法不足之处在于音频对象间往往没有很大的相关性,这点不同于多声道之间的相关性,因此提取的相关系数并无实际意义,并不适用于多音频对象编解码。本发明利用音频对象内部自身稀疏性的特点,并结合理想软阈值掩模,对多音频对象进行压缩。本发明所用到的软阈值掩模(IdealRatioMask,IRM),是基于听觉掩蔽和听觉场景分析的机理并结合机器感知研究,由俄亥俄州立大学汪德亮提出的CASA的计算方法。在听觉过程中,信号可以被分解为若干时频单元,这些单元以时间和频率为维度,可构成一个二维矩阵。同时构造一个与该矩阵相对应的矩阵,矩阵中非零值表示相应时频单元中的目标信号与混合信号能量的比值,0表示相应时频单元中的目标能量极小,于是保留软阈值矩阵中非零值所对应的时频单元,而去掉0所对应的时频单元,这一过程即实现了理想软阈值掩模。理想软阈值掩模在提出后即用于语音分离。听觉实验表明,基于理想软阈值掩模的处理方法可以非常显著地提高听力损伤和听力正常被试者的语音可懂度。本发明使用理想软阈值掩模的目的在于从混合音频信号中提取目标音频,因此求得软阈值掩模矩阵的过程在于将每一帧的音频信号分带离散化,保留音频信号主要能量的子带,其掩模值置为目标信号与混合信号能量的比值,反之置为0。本发明所提出的基于理想软阈值掩模的多音频对象编解码策略,包括以下几个部分时频域变换:将目标音频或混合音频进行分帧、时频变换,将目标信号从时域变换到频域。下混模块:多个目标音频频域信号加和取平均取得下混信号。下混信号压缩:单通道编码。下混信号重构:单通道解码。阈值提取:将分帧后信号中的每一帧信号的频域能量排序,由大到小依次相加,直到该帧总能量大部分得以保留,该频率点保留的能量值为该频点的阈值。IRM分析:将所有音频对象信号和混合音频信号做时频变换,当混合音频中一个时频块中包含了多个音频对象的能量信息且混淆程度较大时,求每个音频对象占整个混合时频块的能量比例,并使用此能量比值作为理想软阈值掩模的掩模值,即soft-mask,其他所占能量比极小的频域点掩模置为0,得到各个音频对象的软阈值掩模。IRM重构:下混信号的频域值与某目标音频对象提取出的掩模MASK矩阵相乘,可得到该音频对象恢复的频域信号。子带融合:如果时频变换得到的频率带数较多,掩模的数据会过于庞大,为了进一步压缩掩模参数数据,我们需要对频率带进行压缩融合。由于人耳对较低频率分辨率高,较高频率分辨率低,我们依据听觉临界带对频率进行不均匀的融合,低频区域分带窄,高频区域分带宽,使得在保证音频质量的同时减少频率带个数。掩模量化:采用量化方法将掩模参数量化,量化表为2^n个浮点型数,使得矩阵可以被1到2^n来表示,缩短每个参数位数为nbit。游程编码压缩:由音频信号的稀疏性可知,掩模矩阵中代表0的参数个数占比最多,实验可知占比可达90%。因此我们将掩模矩阵进行对于0的游程编码,可将掩模矩阵进一步压缩,压缩率在1/3以上。与现有技术相比,本发明的积极效果为:本发明充分利用了音频自身稀疏性的特点,压缩更有针对性并且更加有效。除此之外,理想软阈值掩模方法在整体架构上更好的兼容了多声道音频编码。PEAQ评价结果表明,与MPEG的SAOC方法相比,本发明解码的音频信号听感知效果有明显的提高。附图说明下面结合附图对本发明进一步详细地说明:图1是SAOC方法编解码流程图;图2是本发明的基于理想软阈值掩模编码方法流程图;图3是本发明的基于理想软阈值掩模编码方法流程图;图4是采用本发明的基于理想软阈值掩模编码方法中IRM分析模块流程图;图5是采用本发明的基于理想软阈值掩模解码方法中IRM重构模块流程图;图6是子带融合示意图;图7是游程编码示意图;图8为本发明与aac压缩对比PEAQ评分对比结果;图9为本发明与aac压缩对比SNR对比结果。具体实施方式下面参照本发明的附图,更详细地描述本发明的最佳实施例。图2整体的描述了本发明的基于理想软阈值掩模编码方法各个模块之间的关系。在编码端,输入为描述各音频对象时间信息的元数据以及音频对象信息,在预处理模块中,将形成通道形式的音频对象。通道形式的音频对象进入下混模块,生成一个下混信号,下混信号和各个通道形式的音频对象进入软阈值掩模(IRM)分析模块进行软阈值掩模提取,生成掩模矩阵MASK。掩模矩阵分别进行子带融合、掩模量化和游程编码等掩模压缩方法进行压缩,生成掩模码流(MASK流)。同时,下混信号经过AAC编码器进行编码压缩得到的编码结果和压缩后的掩模码流及元数据一起,进行合成码流,作为编码端的输出。图3整体的描述了本发明的基于理想软阈值掩模解码方法各个模块之间的关系。解码端以合成的码流为输入,首先进行码流分解,得到压缩后的掩模MASK流和压缩后的下混信号及元数据。MASK流分别经游程解码、掩模反量化及子带反融合等掩模恢复方法得到重构的掩模矩阵,同时压缩的下混信号经单通道解码器得到重构的下混信号,下混信号和IRM掩模一起进行IRM重构得到每一个音频对象,恢复出的音频对象再经过渲染模块进行音频场景的重现,在此不作为重点。图4是采用本发明的基于理想软阈值掩模编码方法中IRM分析模块流程图。输入为目标信号和下混信号。目标音频对象和混合音频对象分别进行分帧、加窗、QMF变换,得到QMF域的目标信号(S_target)和混合信号(S_mix)。由实验可知,音频信号的绝大部分能量主要集中少量的QMF频率带中,因此我们对于目标信号进行阈值计算,使得QMF域能量小于阈值的点被舍弃,即其在掩模MASKi中对应值被置为零;QMF域能量大于阈值的点,使用目标信号与下混信号的能量比值作为掩模MASK值,即softmask。再经过MASK合成模块,对得到的掩模进行拼接得到MASK掩模矩阵作为输出。图5采用本发明的基于理想软阈值掩模解码方法中IRM重构模块流程图。输入为下混信号及某目标音频的MASK掩模矩阵,下混信号经分帧、加窗,QMF变换,得到QMF域信号。之后将得到的QMF域信号与该目标音频对象提取出的掩模MASK矩阵相乘,得到该音频对象恢复的QMF域信号。再通过QMF逆变换,得到重构的目标作为输出。图6是子带融合示意图。为了压缩参数的码率,我们需要对QMF域进行压缩,按照人对听觉感知的特点,较低频率分辨率高,较高频率分辨率低的特点,将频域有差别的进行频率点的合并,在保证音频质量的同时降低码率。表2是量化表。为了节约码率,我们需要对求得的掩模参数矩阵进行压缩,即用二进制数码表示量化后的音频采样值。量化位数越多,越能细化参数的幅度变化。而位数过多则会导致压缩率底下。量化位数的选择应权衡压缩率和回复品质。图7是游程编码示意图。RLE(RunLengthEncoding行程编码)算法是一个简单高效的无损数据压缩算法,其基本思路是把数据看成一个线性序列,由于上述稀疏性,序列中数据0的个数比重最大,所以将这些数据序列组织成:数据0之后的数据块为其重复次数,其他数据正常存储。例如某一个文件有如下的数据序列0000123,在未压缩之前占用7个字节,而如果使用了压缩之后就变成了04123,只占用5个字节,节约了码率,并且可无损恢复。评价结果以下是我们针对本发明所做的实验评价结果。测试序列为QUASI音频库中选取的同一乐曲的6个单声道乐器/人声(表2),截取时长22s。采样率为44.1kHz,采样精度为16bit。本实验选取192kbps为码率。单通道编解码器选取AAC编解码器。在实现中,我们选取的时频变换为QMF,采取帧长2048,帧移1024。每个音频文件分配给参数5kbps码率。我们使用SAOC方法作为对比试验。表2测试序列序号与序列文件名对应表序号123456名称acoustik_gtr.wavalto.wavkick.wavorgan.wavtenor.wavvox2.wav评价分为PEAQ评价和SNR信噪比。PEAQ评分对比如图8所示。由评分结果可知,在六个音频文件中,除了第四个音频对象本发明的PEAQ评分略低于SAOC方法,其他音频文件本方法PEAQ评分显著高于SAOC方法。SNR对比如图9所示。由SNR大小可以看出,在六个音频文件中,除了第五个音频对象本发明的SNR与SAOC方法信噪比持平,其他音频文件本方法信噪比显著高于SAOC方法。比较传统方法,基于IRM理想软阈值掩模的突出优点在于它充分利用了音频自身稀疏性的特点,压缩更有针对性并且更加有效。该问题的解决尤其对音频对象编码的发展具有重要意义。除此之外,理想软阈值掩模IRM在理想二值掩模IdBM的基础上增加能量比作为掩模值,不仅提高了音频恢复质量,并且在整体架构上更好的兼容了多声道音频编码。通过对音频编码前和恢复出的音频信号使用模拟主客观评价表明,与传统方法相比,新方法对SNR和感知效果均有明显的提高。同时研究表明,由于新方法能够更好地体现声音频谱,因此它能够有效地提高听众感受到的声音质量,经过后续的渲染操作,使得听众有更好的听觉体验。尽管为说明目的公开了本发明的具体实施例和附图,其目的在于帮助理解本发明的内容并据以实施,但是本领域的技术人员可以理解:在不脱离本发明及所附的权利要求的精神和范围内,各种替换、变化和修改都是可能的。因此,本发明不应局限于最佳实施例和附图所公开的内容。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1