一种声音重录攻击的识别方法与流程
本发明涉及多媒体信息安全领域,具体是涉及一种声音重录攻击的识别方法。
背景技术:
声音重录攻击是指事前录制好目标人物的语音片段,然后重播此片段以骗过说话人识别系统。现在有很多便捷的录音设备,例如手机、录音笔等,很方便就可以在目标人物不知情下将其声音录制下来。并且,由于录制的语音几乎仍包含说话人的所有最主要特征,而这些特征正是说话人识别系统的判断依据,当今的识别系统都无法抵抗这种攻击。因此,声音重录攻击对不少已投入使用的商业或其它应用场合的系统带来严重威胁,是亟待解决的安全问题。
技术实现要素:
本发明针对现有技术的不足,提供一种声音重录攻击的识别方法;该方法能区分重录声音及原始声音,具有巨大的现实意义和广阔的应用场景。
本发明一种声音重录攻击的识别方法,主要包括以下步骤:
首先,提取MFCC;
其次,对语音片段x(n)分帧;
所述语音片段x(n)分帧分成N帧,则每帧分别提取前L维MFCC系数、前L维一次差分MFCC系数(ΔMFCC)和前L维二次差分MFCC系数(ΔΔMFCC),获得3个L维向量,记x(n)第i帧的MFCC向量的第j个元素为vij,则x(n)所有帧的MFCC向量的第j个元素Vj可表示为
Vj={v1j,v2j,…,vNj},j=1,2,…,L (1)
第三,提取语音识别特征;
使用两种统计矩,即向量Vj的均值Ej和Vj与Vj′的相关系数Cjj′,即
Ej=E(Vj),j=1,2,…,L (2)
两种统计特征联合组成基于MFCC的统计特征向量,即
FMFCC=[E1,E2,…,EL,C12,C13,…,C(L-1)L] (4)
其中,FMFCC的维数为
L+1+2+…+(L-1)=L+L*(L-1)/2=(L2+L)/2,
对ΔMFCC向量和ΔΔMFCC向量计算相同的统计特征向量FΔMFCC和FΔΔMFCC,将FMFCC、FΔMFCC和FΔΔMFCC连在一起组成x(n)的特征向量F,即
F=[FMFCC,FΔMFCC,FΔΔMFCC] (5)
其中,F的维数为3*(L2+L)/2;F即为本发明采用的识别特征;
第四,训练出SVM分类器;输入原始语音作为正例训练样本,输入录制语音作为反例训练样本,从正反例样本中提取特征F以训练出SVM分类器;
最后,测试识别;提取特征测试语音的特征F并输入SVM分类器进行判别。所提的识别方法中使用支持向量机(SVM)作为分类方法,以公式(5)中的特征F作为SVM的输入。
作为上述方案的进一步改进,所述提取MFCC主要包括以下步骤:
首先,加窗和计算频谱,窗长度为N,
其中的MFCC采用了N=1024点的海明窗:
对源信号x(n)加窗后作FFT变换:
其次,Mel分段和对数变换,Mel分段为三角滤波,
加权窗口使用三角窗,其公式如下:
其中,km=f(m)·N/Fs,Fs为抽样频率,利用三角窗对FFT的能量谱加权后作对数变换:
再次,得出MFCC,
利用余弦反变换,即可得到Mel倒谱系数,即MFCC。
本发明的有益效果为:本发明技术方案在识别性能上能达到99.67%,能在大多数应用场合中成功识别重录声音。
附图说明
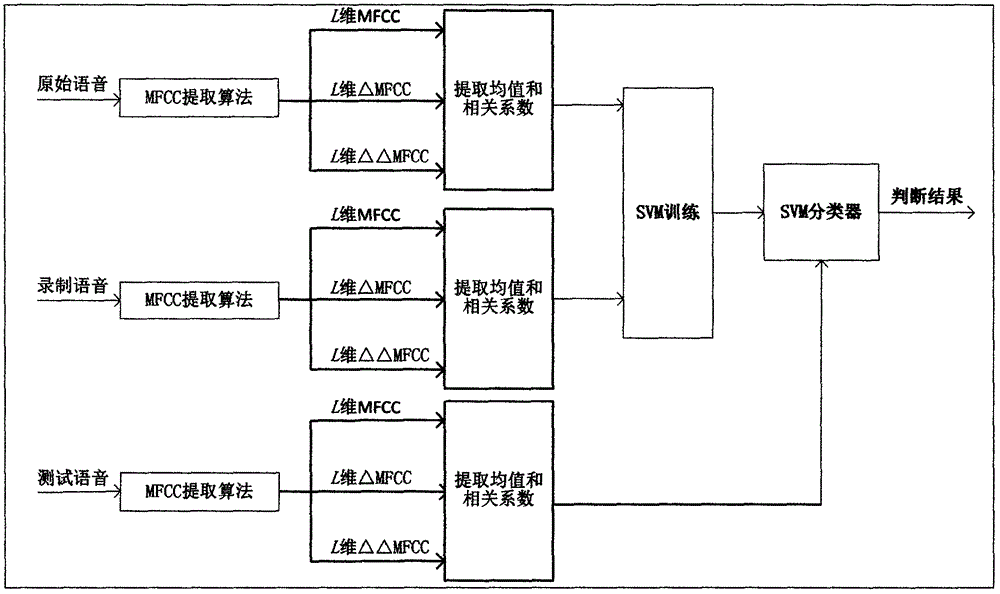
图1为本发明识别声音的流程图。
具体实施方式
以下结合附图和具体实施例对本发明进行详细描述,但不作为对本发明的限定。
参照图1,本发明实施例一种声音重录攻击的识别方法,主要包括以下步骤:
首先,提取MFCC;
其次,对语音片段x(n)分帧;
所述语音片段x(n)分帧分成N帧,则每帧分别提取前L维MFCC系数、前L维一次差分MFCC系数(ΔMFCC)和前L维二次差分MFCC系数(ΔΔMFCC),获得3个L维向量,记x(n)第i帧的MFCC向量的第j个元素为vij,则x(n)所有帧的MFCC向量的第j个元素Vj可表示为
Vj={V1j,v2j,…,vNj},j=1,2,…,L (1)
第三,提取语音识别特征;
使用两种统计矩,即向量Vj的均值Ej和Vj与Vj′的相关系数Cjj′,即
Ej=E(Vj),j=1,2,…,L (2)
两种统计特征联合组成基于MFCC的统计特征向量,即
FMFCC=[E1,E2,…,EL,C12,C13,…,C(L-1)L] (4)
其中,FMFCC的维数为
L+1+2+…+(L-1)=L+L*(L-1)/2=(L2+L)/2,
对ΔMFCC向量和ΔΔMFCC向量计算相同的统计特征向量FΔMFCC和FΔΔMFCC,将FMFCC、FΔMFCC和FΔΔMFCC连在一起组成x(n)的特征向量F,即
F=[FMFCC,FΔMFCC,FΔΔMFCC] (5)
其中,F的维数为3*(L2+L)/2;F即为本发明采用的识别特征;
第四,训练出SVM分类器;输入原始语音作为正例训练样本,输入录制语音作为反例训练样本,从正反例样本中提取特征F以训练出SVM分类器;
最后,测试识别;提取特征测试语音的特征F并输入SVM分类器进行判别。
所提的识别方法中使用支持向量机(SVM)作为分类方法,以公式(5)中的特征F作为SVM的输入。
所述提取MFCC主要包括以下步骤:
首先,加窗和计算频谱,窗长度为N,
其中的MFCC采用了N=1024点的海明窗:
对源信号x(n)加窗后作FFT变换:
其次,Mel分段和对数变换,Mel分段为三角滤波,
加权窗口使用三角窗,其公式如下:
其中,km=f(m)·N/Fs,Fs为抽样频率,
利用三角窗对FFT的能量谱加权后作对数变换:
再次,得出MFCC,
利用余弦反变换,即可得到Mel倒谱系数,即MFCC。
现给出利用本发明方法所采用的语音库和一些实验结果。
原始语音库由3000段语音组成,每段语音时长2秒,抽样频率16kHz,量化精度16bits。对原始语音库播放并录制7次,由此获得7个录制语音库,它们分别包含3000段语音。7次录制的情况如表1语音库录制所示。
表1
考虑到实验分为训练及测试阶段,以上语音库需要划分为不同的子库作为不同用途。具体划分为:1)原始语音库分为S1、S2、S3三个子库,每个子库包含1000段互不相同的语音;2)Sn(n=1,2,3)对应的录制语音库记为Sn_k(k=1,2…,6,7)。
实验需要衡量录制环境、录音设备和录制距离对检测结果的影响,因此,考虑以下四种情况:
(1)不同录制环境对算法检测性能的影响。
利用原始语音库S1(作为正样本)与录制语音库S1_2、S1_5(作为负样本)分别训练出两个SVM分类器,剩余语音库作为测试,比较两个分类器的性能。其结果如表2所示,安静环境(S1+S1_2)和有噪声环境(S1+S1_5)下对算法检测性能的影响(正确率:%)。表2中,安静环境下的平均识别率达到了87.45%,而有噪声的环境下平均识别率为83.436%。
表2
(2)不同录制设备对算法检测性能的影响。
利用原始语音库S1(作为正样本)与录制语音库S1_1、S1_2(作为负样本)分别训练出两个SVM分类器,剩余的语音库用作测试,比较两个分类器的性能。其结果如表3所示,电脑录制设备(S1+S1_1)和智能手机录制(S1+S1_2)对算法检测性能的影响(正确率:%)。表3中,利用电脑设备录制的语音训练出来的分类器平均识别率为70.927%,而利用智能手机则达到了87.45%。可以看出,利用电脑录制的语音训练的分类器和利用智能手机录制的语音训练的分类器在识别用智能手机录制的语音库时,识别性能要低很多。也就是说,不同录制设备对识别性能有很大的影响。在安静环境下,利用电脑录制的语音训练的分类器能较好地检测出用智能手机录制的语音,但在有噪声的情况下,检测率也很低;相反,用智能手机录制的语音训练的分类器检测用电脑录制的语音检测率很低。
表3
(3)不同录制距离(20cm和40cm)对算法检测性能的影响。
本发明主要考虑安静及有噪两种环境下算法的检测性能。利用原始语音库S1(作为正样本)与录制语音库S1_2、S1_3(作为负样本)分别训练出两个SVM分类器,比较两个分类器的性能。其结果如表4所示,安静环境下,不同距离(20cm:S1+S1_2,40cm:S1+S1_3)对算法检测性能的影响(正确率:%)。表4中,用录制距离为20cm的语音训练出来的分类器的平均识别率为87.45%,而录制距离为40cm的情况下为89.127%。从平均识别率可以看出,在安静环境下,利用在40cm的距离录制的语音比在20cm录制的语音训练出来的分类器性能更好。
表4
利用原始语音库S1(作为正样本)与录制语音库S1_5、S1_6(作为负样本)分别训练出两个SVM分类器,比较两个分类器的性能。其结果如表5所示,有噪声环境下,不同距离(20cm:S1+S1_5,40cm:S1+S1_6)对算法检测性能的影响(正确率:%)。表5中,用录制距离为20cm的语音训练出来的分类器的平均识别率为83.436%,而录制距离为40cm的情况下为85.959%。从平均识别率可以看出,在有噪声的环境下,利用在40cm的距离录制的语音比在20cm录制的语音训练出来的分类器性能更好。
表5
(4)全局性能
全局性能即是在训练分类器时,综合考虑录音设备、录音距离及录音环境,利用原始语音库S1(作为正样本)与录制语音库S1_1、S1_2、S1_5(作为负样本)训练出SVM分类器,即负样本将录音设备、录音距离和录音环境都考虑在内。检测结果如表6所示,不同录音设备、录音距离和录音环境下对算法检测性能的影响(正确率:%)。表6中,平均识别率达到了99.67%。可以看出,在训练SVM分类器时,负样本中整体考虑录音设备、录音距离和录音环境的情况得到的分类器性能很好。
表6
本发明技术方案在识别性能上能达到99.67%,能在大多数应用场合中成功识别重录声音。
以上已将本发明做一详细说明,但显而易见,本领域的技术人员可以进行各种改变和改进,而不背离所附权利要求书所限定的本发明的范围。
- 还没有人留言评论。精彩留言会获得点赞!