基于冗余特征和多词典表示的语音情感识别方法及系统与流程
本发明属于语音情感识别领域,涉及一种基于冗余特征和多词典表示的语音情感识别方法及系统。
背景技术:
语音作为最主要的交流手段之一,在新型的人机交互领域受到越来越广泛的关注。若想让计算机理解人类的意思,就要让计算机模仿人们最常见的沟通方式。如今人类的沟通方式已经变得多种多样,而人们最主要的交流方式就是说话。人在说话时,便将自己的情感隐藏在语音信号之中,所以语音是人在表达自己情感和想法的最好媒介。语音情感识别是实现基于语音的智人工交互的重要步骤之一,因此让计算机有效地识别人类话语中的情感,对于更好地实现人机交互是一个行之有效的方法。
我国在语音情感识别领域的研究还是取得了重大的进展,国内许多高校和国家重点实验室都对语音情感识别进行了深入的分析与研究。从2000年起,清华大学的蔡红莲教授对超音段特征进行了深入的研究,并使用高斯混合模型(GMM)和概率神经网络(PNN)分类器对汉语的普通话情感进行识别。最后的结果表明,超音段特征能较好地将不同的情感状态区分开来,他们的实验中识别结果准确率达到了76.7%。从2001年起,东南大学的赵力教授针对惊奇、悲伤、高兴、愤怒4种语音情感信号的小样本数据,提出了将语音情感的全局特征和时序基频(F0)特征相结合的方式来进行语音情感识别,并取得了较好的识别结果,识别率达到80%。
在情感特征提取方面,由于某些情感的相似性,单一类型的特征不能将语音情感进行很好的区分,因而寻找合适的情感特征组合有利于系统性能的进一步改善。
在特征表示或分类方面,基于词典的表示方法受到了广泛的关注,这是因为词典具有强大的表示能力并且具有自适应学习能力。然而,在当前基于词典表示的方法中,绝大多数方法都只使用一个词典,因而表示能力受到限制。
为了解决当前方法中存在的特征抽取和表示的不足,本发明提出了冗余特征抽取方案和多词典表示方法,并提出了基于冗余特征和多词典表示的语音情感识别系统。一些词典用于分解,另一些词典用于综合表示。利用多个词典,从而可以充分挖掘冗余特征中的区分性特征,又可以适当地削除特征冗余带来的不利影响;同时基于多词典的表示使分类更容易,可以基于类别重构误差最小化来简单地完成分类识别任务。
技术实现要素:
本发明的目的是针对当前单一类型特征的有限区分能力和单词典表示的有限表示能力,提供一种基于冗余特征和多词典表示的语音情感识别方法。该方法提取基音频率特征(F0)、超音段响度(Loudness)特征、谱特征中的MEL频率子带能量系数(MFBECS)特征、线性谱频率(LSF)特征以及小波变换后的多尺度特征,并将这些特征组合在一起形成冗余特征,然后基于这些冗余特征学习多类多个分析和综合词典对,并选取具有最小重构误差的那一对词典的类别作为测试语音的情感类别,最终提高语音情感识别率。
为实现上述目的,本发明采用的技术方案是:
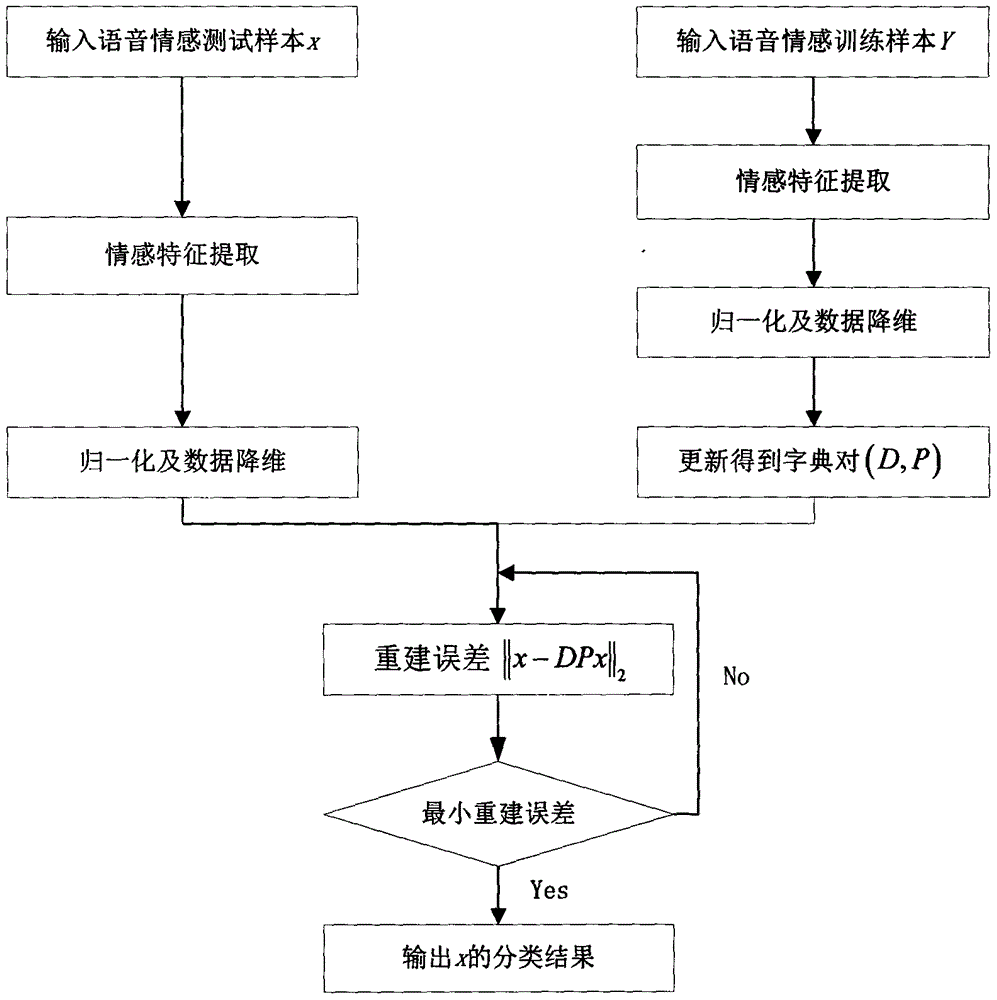
一种基于冗余特征和多词典表示的语音情感识别系统,包括以下步骤:
(1)对训练样本库中每个语音情感信号进行预处理,得到语音情感数据帧。
(2)对(1)中的语音情感数据帧进行基音频率特征、超音段响度特征、谱特征中的MEL频率子带能量系数特征、线性谱频率特征以及多尺度小波变换特征抽取,并进行特征组合,得到训练样本的冗余特征向量。
(3)对(2)中所提取的情感冗余特征向量进行归一化并用主成分分析法(PCA)进行降维,再进行表示词典和分析词典学习,得到多词典对。
(4)对测试样本语音情感信号进行预处理,如(2)中的特征提取,并形成冗余特征向量,再进行归一化以及PCA降维。
(5)使用学习到的多类多字典对来对(4)中的测试样本冗余特征向量进行重构,并根据最小重构误差所对应的词典对的类别来对该语音情感样本的类别进行判别。
所述步骤(1)中的预处理步骤如下:
(11)对语音情感信号的音频文件进行解码处理,将其转换成PCM格式的波形文件,再对语音情信号进行重采样处理。
(12)对(11)中得到的语音信号预加重处理,提高情感信号的高频分量。
(13)对(12)中得到的语音信号进行汉明窗分帧处理。
所述步骤(2)中的冗余特征抽取以及归一化和PCA降维具体步骤如下:
对预处理后的语音情感信号进行响度(Loudness)特征、谱特征中的MFBECS特征和LSF特征提取。
对(13)中预处理后的每一帧情感信号进行傅里叶变换,求得时域点对应的频谱,并对每个频率及其所有倍频谐波成分进行叠加。叠加公式如下所示:
其中,R为要考虑的谐波数量,本发明中该参数取15;参数c的作用是在统计谐波总和能量时,降低谐波能量的影响,本发明中该值取0.85。
针对谐波叠加的能量,在给定的基频范围内(fmin,fmax)进行极大值的寻找。为了提取更准确的F0特征,为了消除二倍频的影响,本发明提出改进的谐波和计算公式如下:
利用上述公式从而完成F0特征提取。
(24)使用Gabor带通滤波器对(13)中预处理后的语音情感数据帧进行十七个临界带的滤波处理。Gabor带通滤波器的具体公式如下所示:
其中,Sx为输入的语音情感信号的方差,Sy的取值为1。
(25)对每个情感数据帧的每一个临界带进行三层小波包变换(WPT),从而获得相应的小波系数。
(26)对17个临界带的每个小波系数进行自相关系数的计算,从而得到多尺度小波变换特征,共136维。
完成基于小波变换的多尺度特征提取。
(27)直接将以上得到的不同的情感特征首尾相连形成一个较长的列向量,从而得到情感特征组合,也就是冗余情感特征。
所述步骤(3)中的多类多词典对学习的具体步骤如下:
对所提取的冗余情感特征向量进行归一化以及PCA降维。
(31)使用训练样本的语音情感的冗余特征数据构建情感模型。本发明引进变量XK,使得Xk=PkYk,对目标函数进行优化。目标函数为:
其中Dk=[d1,d2…dl]∈Rd×l,Pk∈Rl×d分别表示第k类训练样本得到的合成字典和分析字典。D=[D1,…Dk,…DC]是合成字典,P=[P1,…Pk,…PC]是分析字典。其中C类的训练样本数据d表示训练样本的特征维数,NK表示第k类的样本总个数,λ为标量参数,N表示训练样本的总个数di是合成矩阵D的第i个列向量。
(33)使用训练样本数据训练字典对,得到合成字典D以及分析字典P。具体步骤如下:
步骤1.输入:C个目标类的训练语音情感样本构成的数据矩阵Y=[Y1,…YK,…YC],所需的参数λ、λ1及/(字典的个数)。
步骤2.初始化:随机初始化Dk∈Rd×l和Pk∈Rl×d,这两个矩阵均具有归一化的F范数。
步骤3.固定D与P,使用公式对X进行更新。
步骤4.固定D与X,使用公式对P进行更新。
步骤5.固定X与P,使用公式对D进行更新。
步骤6.断定是否收敛。若收敛,则转到步骤7;否则步骤3,继续对D、P、X进行更新。
步骤7.输出:分析字典P,合成字典D。
所述步骤(4)中的测试样本语音情感信号预处理、冗余特征提取、归一化以及PCA降维的具体步骤如下:
对测试样本语音情感信号进行预处理并抽取响度(Loudness)特征、MFBECS特征、LSF特征、F0特征以及小波变换特征,将得到的情感特征首尾相接形成一个列向量,也就是冗余特征,再进行归一化以及PCA降维。
所述步骤(5)中使用得到的字典对对测试样本进行重构的具体步骤如下:
使用得到的字典对来对测试样本进行重构,并根据最小重构误差来对该语音情感样本的类别进行判别。
具体的基于多类多词典对表示的分类过程如下:
步骤1.输入:C个目标类的语音情感训练样本构成的数据为Y=[Y1,Y2…YJ,…YC],以及测试样本数据矩阵A=[x1,x2…xk,…xN]∈Rd×N。
步骤2.使用式Yk≈DPY=D1P1Tk+D2P2Yk+…DkPkYk+…DCPCYk进行求解合成字典D与分析字典P。对于测试样本数据中的每一个测试样本x∈Rd,重复进行如下步骤3与步骤4。
步骤3.对于每一类k,k=1,2,…,C,重复进行下面两个步骤
(1)计算重构的样本xrecons(k)=DkPkx。
(2)计算原测试样本x与重构样本之间的残差rk(x)=||x-xrecons(k)||2。
步骤4.输出:
本发明的创新之处在于:
本发明提出冗余特征抽取方案,包括小波特征、F0特征、响度(Loudness)特征、谱特征中的MFBECS特征和LSF特征;然后利用抽取的冗余特征进行多类多词典表示学习,最后利用重构误差最小的词典对所对应的类别对输入语音情感进行分类识别。与传统使用单一或少数特征进行情感识别的方法不同,本发明综合利用了各种特征的区分能力,有利于提高系统的识别准确度;同时与传统的基于单个词典的表示方法不同,本发明提出了综合词典和分析词典的多词典对学习方法,并利用多词典的较强表示能力来进一步提高语音情感识别的准确度。总之,本发明既能综合利用冗余特征的区分能力,又能利用多词典的强大表示能力来提高语音情感的识别准确率。
附图说明
图1是小波特征提取流程图
图2是语音情感识别流程图
具体实施方式
以下将结合附图所示的各实施方式对本发明进行详细描述。但这些实施方式并不限制本发明,本领域的普通技术人员根据这些实施方式所做出的结构、方法、或功能上的变换均包含在本发明的保护范围内。
本发明公开了一种基于冗余特征和多词典表示的语音情感识别系统,具体实施步骤包括:
(1)对训练样本库中每个语音情感信号进行预处理,得到语音情感数据帧。
(2)对(1)中的语音情感数据帧进行小波特征、F0特征、响度特征、MFBECS特征和LSF特征抽取,并进行特征首尾相接而形成冗余特征,从而得到训练样本特征向量。
(3)对(2)中所提取的情感特征向量进行归一化以及使用主成分分析法进行降维,再进行多词典对表示学习,从而得到词典对。
(4)对测试样本语音情感信号进行预处理,如(2)中的特征提取,并时行特征向量组合,再进行归一化以及PCA降维。
(5)使用得到的词典对来对(4)中得到的测试样本进行重构,并根据最小重构误差来对该语音情感样本的类别进行判别。
所述步骤(1)中的预处理步骤如下:
(11)对语音情感信号的音频文件进行解码处理,将其转换成PCM格式的波形文件,再对语音情信号进行重采样处理。
(12)对(11)中得到的语音信号预加重处理,提高情感信号的高频分量。
(13)对(12)中得到的语音信号进行汉明窗分帧处理。
所述步骤(2)中的特征提取及特征组合以及归一化以及PCA降维具体步骤如下:
对预处理后的语音情感信号进行响度特征、MFBECS特征和LSF特征提取。
对(13)中预处理后的每一帧情感信号进行傅里叶变换,求得时域点对应的频谱,并对每个频率及其所有倍频谐波成分进行叠加。叠加公式如下所示。
其中,R为要考虑的谐波数量,本发明中该参数取15;参数c的作用是在统计谐波总和能量时,降低谐波能量的影响,本发明中该值取0.85。
针对谐波叠加的能量,在给定的基频范围内(fmin,fmax)进行极大值的寻找。为了提取更准确的F0特征,为了消除二倍频的影响,改进的谐波和计算公式如下:
完成基于改进算法的F0特征提取。
(24)使用Gabor带通滤波器对(13)中预处理后的语音情感数据帧进行十七个临界带的滤波处理。Gabor带通滤波器的具体公式如下所示:
其中,Sx为输入的语音情感信号的方差,Sy的取值为1。
(25)对每个情感数据帧的每一个临界带进行三层小波包变换,从而获得相应的小波系数。
(26)对17个临界带的每个小波系数进行自相关系数的计算并作为特征,从而得到小波特征,共136维特征。
完成基于临界带多分辨率分析的小波特征提取。
(27)直接将以上得到的不同的情感特征组成一个列向量,从而得到冗余的情感特征组合。
所述步骤(3)中的基于多词典对表示的语音情感识别的具体步骤如下:
对所提取的冗余情感特征向量进行归一化以及PCA降维。
(32)使用训练样本的语音情感的特征数据构建情感模型。使用训练样本的语音情感的特征数据构建情感模型。本发明引进变量XK,使得Xk=PkYk,对目标函数进行优化。目标函数为。
其中Dk=[d1,d2…dl]∈Rd×l,Pk∈Rl×d分别表示第k类训练样本得到的合成字典和分析字典。D=[D1,…Dk,…DC]是合成字典,P=[P1,…Pk,…PC]是分析字典。其中C类的训练样本数据d表示训练样本的特征维数,NK表示第k类的样本总个数,λ为标量参数,N表示训练样本的总个数di是合成矩阵D的第i个列向量。
(33)使用训练样本数据训练词典对,得到合成词典D以及分析词典P。具体步骤如下:
步骤1.输入:C个目标类的训练语音情感样本构成的数据矩阵Y=[Y1,…YK,…YC],所需的参数λ、λ1及/(字典的个数)。
步骤2.初始化:随机初始化Dk∈Rd×l和Pk∈Rl×d,这两个矩阵均具有归一化的F范数。
步骤3.固定D与P,使用公式对X进行更新。
步骤4.固定D与X,使用公式对P进行更新。
步骤5.固定X与P,使用公式对D进行更新。
步骤6.断定是否收敛。若收敛,则转到步骤7;否则步骤3,继续对D、P、X进行更新。
步骤7.输出:分析字典P,合成字典D。
所述步骤(4)中的测试样本语音情感信号进行预处理,特征提取,并进行特征向量组合,再进行归一化以及PCA降维的具体步骤如下:
对测试样本语音情感信号行预处理,并抽取响度(Loudness)特征、谱特征中的MFBECS特征、LSF特征、F0特征和基于临界带多分辨率分析的小波特征,并将得到的冗余情感特征组成一个列向量,再进行归一化以及PCA降维。
所述步骤(5)中的使用得到的词典对来对测试样本进行重构的具体步骤如下:
(51)使用得到的词典对来对测试样本进行重构,并根据最小重构误差来对该语音情感样本的类别进行判别。
具体基于多类多字典对表示的分类过程如下:
步骤1.输入:C个目标类的语音情感训练样本构成的数据为Y=[Y1,Y2…Yj,…YC],以及测试样本数据矩阵A=[x1,x2…xk,…xN]∈Rd×N。
步骤2.使用式Yk≈DPY=D1P1Yk+D2P2Yk+…DkPkYk+…DCPCYk进行求解合成字典D与分析字典P。对于测试样本数据中的每一个测试样本x∈Rd,重复进行如下步骤3与步骤4。
步骤3.对于每一类k,k=1,2,…,C,重复进行下面两个步骤
(1)计算重构的样本xrecons(k)=DkPkx。
(2)计算原测试样本x与重构样本之间的残差rk(x)=||x-xrecons(k)||2。
步骤4.输出:
本发明效果可以通过以下实验进一步说明:
1)实验条件
实验仿真环境为:Matlab(R14a),主频3.01GHZ的处理器上RAM为4GB的PC机上。
2)实验内容
2.1)实验数据来源
本实验使用三个公开且被广泛使用的语音情感数据库来进行语音情感识别问题的研究,即Emodb语音情感数据库和Polish语音情感数据库及eNTERFACE’05情感数据库。
Emodb语音情感数据库由10位演员(5男5女)对七种常见的情感进行模拟,得到的音频文件格式为单通道、采样精度为16比特、采样率为16HKZ的wav音频文件。这些情感语句的语义皆为中性,不带情感倾向,并且使用日常口语化的风格。该数据库有535个德语语句,包含七种情感,即愤怒(anger)、难过(sadness)、快乐(happy)、恐惧(fear)、平静(neutral)、厌恶(disgust)、无聊(bordem),这七种情感的个数分别为127、62、71、69、79、46,该数据库中每种情感样本数据不是均等分配的。
Polish语音情感数据库,由8位演员(4男4女)对六种情感进行模拟,得到的音频文件格式为单通道、采样精度为16比特、采样率为44.1HKZ的wav音频文件。该数据库有240个波兰语语句,包含六种情感,即愤怒(anger)、难过(sadness)、快乐(happy)、恐惧(fear)、平静(neutral)、无聊(bordem),这六种情感的个数均为40。
eNTERFACE’05情感数据库是一个音视频结合的情感数据库,由42位演员(34男8女)对六种情感进行模拟。本文采用ffmpeg将其进行转换,得到音频文件格式为单通道、采样精度为16比特、采样率为16HKZ的wav音频文件。该数据库有1260个英语语句,包含六种情感,即愤怒(anger)、难过(sadness)、快乐(happy)、恐惧(fear)、吃惊(surprise)、厌恶(disgust),这六种情感的个数均为210。
2.2)实验步骤:
首先对训练样本库中每个语音情感信号进行预处理,得到语音情感数据帧。然后对语音情感数据帧抽取小波特征、F0特征提取、响度(Loudness)特征、MFBECS特征和LSF特征。并进行特征组合形成冗余特征向量,从而得到训练样本特征向量。之后用情感特征向量进行多类多词典对表示学习,得到多词典对。再对测试样本语音情感信号进行预处理,如之前训练样本一样的特征提取,并形成特征向量组合,再进行归一化以及PCA降维。使用得到的多词典对对测试样本进行重构,并根据最小重构误差来对该语音情感样本的类别进行判别。采用的是五次交叉验证的方法对时间性能进行测试。
实验结果分析
以下是本发明方法与基于稀疏表示的方法(SRC)、支持向量机方法(SVM)、联合稀疏低秩方法(Joint Sparse Low-Rank Representation(JSLRR))、协同表示方法(collaborative representation(CRC))的比较结果。
表1 Emodb语音情感数据库上的不同识别方法的带权重的平均准确率(WA)结果比较(%)
表2 Emodb语音情感数据库上的不同识别方法的不带权重的平均准确率(UA)结果比较(%)
表3Polish语音情感数据库上的不同识别方法的识别结果比较(%)
表4 eNTERFACE’05语音情感数据库上的不同识别方法的识别结果比较(%)
从表1,2,3,4中的结果可以看出本发明方法在在不同的语音情感数据库上的识别率高于其他的识别方法。
以下结果是采用五次交叉验证的方法对不同的识别方法时间性能的测试:
表5不同识别方法在Emodb语音情感数据库的时间性能比较
表6不同识别方法在Polish语音情感数据库的时间性能比较
表7不同识别方法在eNTERFACE’05语音情感数据库的时间性能比较
从表5,6,7中可以看出在对识别率有一定要求的条件下,本发明方法的训练时间相比SVM与JLSRR方法的训练时间少,而且本发明方法的测试时间也比SRC、CRC、SVM、JSLRR的测试时间要少,从而就可以说明本发明方法在解决语音情感识别问题上,不仅在识别准确率方面具有较好的性能,在运算时间方面上同样具有较好的性能。
应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施方式中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
上文所列出的一系列的详细说明仅仅是针对本发明的可行性实施方式的具体说明,它们并非用以限制本发明的保护范围,凡未脱离本发明技艺精神所作的等效实施方式或变更均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!