一种基于深度神经网络模型的情感合成方法与流程
本发明涉及语音识别领域,尤其涉及一种基于深度神经网络模型的情感合成方法。
背景技术:
语音合成,又称文语转换(Text to Speech)技术,是一种能够将文字信息转化为语音并进行朗读的技术。其涉及声学、语言学、数字信号处理、计算机科学等多个学科技术,是中文信息处理领域的一项前沿技术,解决的主要问题是如何将文字信息转化为可听的声音信息。
语音合成系统大多是建立在中立朗读方式的语音之上,为解决中立语音的单调无趣,在语音合成系统中引入的情感模型,使得语音合成具有情感特征,增强合成语音的人性化。在对语音合成系统的个性化要求下,语音合成系统会适应生成与发音人对应的声学模型,即需要录制大量的发音人的语音数据和对应该语音数据的文本标注数据进行模型训练,在加入情感模型后,又需要录音大量的发音人的带有不同情感的语音数据和对应该语音数据的文本标注数据进行情感模型的训练,但有多个不同的发音人时,数据量会非常庞大,使得开发时间较长,且研发费用过高。
技术实现要素:
本发明所要解决的技术问题是提供一种基于深度神经网络模型的情感合成方法,解决现有情感模型生成时数据量庞大使得开发时间较长且研发费用过高的问题,目的在于针对多个不同发音人,能够利用少量中立数据,快速构建对应的情感模型。
为实现上述技术效果,本发明公开了一种基于深度神经网络模型的情感合成方法,包括步骤:
获取第一发音人的中立声学特征数据和情感声学特征数据;
利用深度神经网络模型建立所述第一发音人的中立声学特征数据和情感声学特征数据的情感转换模型;
获取第二发音人的中立语音数据,建立第二发音人的中立语音合成模型;以及
利用深度神经网络模型将所述第二发音人的中立语音合成模型与所述情感转换模型串联,得到所述第二发音人的情感语音合成模型。
所述基于深度神经网络模型的情感合成方法进一步的改进在于,通过以下方法获取第一发音人的中立声学特征数据和情感声学特征数据,包括步骤:
提供第一发音人的一定数量的语句文本,所述语句文本包括文本内容一致的中立语句文本和情感语句文本;
从所述中立语句文本中获取第一发音人的中立语音数据;从所述情感语句文本中获取第一发音人的情感语音数据;
从所述中立语音数据中提取第一发音人的中立声学特征数据;
从所述情感语音数据中提取第一发音人的情感声学特征数据。
所述基于深度神经网络模型的情感合成方法进一步的改进在于,通过以下方法获取第一发音人的中立声学特征数据和情感声学特征数据,包括:
获取第一发音人的中立语音数据和情感语音数据;
利用所述第一发音人的中立语音数据进行深度神经网络模型训练,得到所述第一发音人的中立语音合成模型;
利用所述第一发音人的情感语音数据进行深度神经网络模型训练,得到所述第一发音人的情感语音合成模型;
提供一定数量的语句文本,将所述语句文本分别输入到所述第一发音人的中立语音合成模型和情感语音合成模型,获得对应的所述第一发音人的中立声学特征数据和情感声学特征数据。
所述基于深度神经网络模型的情感合成方法进一步的改进在于,在获取第二发音人的中立语音数据后,通过以下方法建立所述第二发音人的中立语音合成模型,包括:
利用第二发音人的中立语音数据,对第一发音人的中立语音合成模型进行重训练,得到第二发音人的中立语音合成模型。
所述基于深度神经网络模型的情感合成方法进一步的改进在于,在获取第二发音人的中立语音数据后,通过以下方法建立所述第二发音人的中立语音合成模型,包括:
利用第二发音人的中立语音数据进行深度神经网络模型训练,得到第二发音人的中立语音合成模型。
所述基于深度神经网络模型的情感合成方法进一步的改进在于,通过以下方法利用深度神经网络模型建立所述第一发音人的中立声学特征数据和情感声学特征数据的情感转换模型,包括:
以第一发音人的中立声学特征数据作为深度神经网络模型的输入数据;
以第一发音人的情感声学特征数据作为深度神经网络模型的输出数据;
训练所述深度神经网络模型,得到第一发音人的中立声学特征数据和情感声学特征数据的情感转换模型。
所述基于深度神经网络模型的情感合成方法进一步的改进在于,通过以下方法训练所述深度神经网络模型,得到第一发音人的中立声学特征数据和情感声学特征数据的情感转换模型,包括:
利用深度神经网络模型中的神经网络构建回归模型,隐层使用S型生长曲线激励函数,输出层使用线性激励函数;
以随机化网络参数作为初始参数,基于公式1的最小均方差准则进行模型训练;
L(y,z)=||y-z||2 (1)
其中,y是情感声学特征数据,z是深度神经网络模型预测的情感声学特征参数,训练的目标是更新深度神经网络模型、使得L(y,z)最小。
所述基于深度神经网络模型的情感合成方法进一步的改进在于,通过以下方法将所述第二发音人的中立语音合成模型与所述情感转换模型串联,得到所述第二发音人的情感语音合成模型,包括:
在合成阶段,对待合成的文本,使用合成前端对文本分析,获取对应的文本特征,所述文本特征包括音素信息、韵律信息、0/1编码信息及当前帧在当前音素中相对的位置信息;
将音素信息、韵律信息、0/1编码信息作为深度神经网络模型的输入,预测出音素时长信息;
将音素信息、韵律信息、0/1编码信息及当前帧在当前音素中相对的位置信息作为深度神经网络模型的输入,预测出频谱信息、能量信息及基频信息;
将预测出的所述频谱信息、所述能量信息及所述基频信息作为声学参数,对所述声学特征,通过公式2进行参数生成,以得到平滑的声学特征;
其中,W为计算一阶差分和二阶差分的窗函数矩阵,C为待生成的声学特征,M为深度神经网络模型预测出的声学参数,U为从训练音库中统计得到的全局方差;
使用声学特征C,通过声码器合成出情感语音合成模型。
所述基于深度神经网络模型的情感合成方法进一步的改进在于,所述中立语音数据包括中立语音的声学特征序列和对应的文本数据信息,所述中立语音的声学特征序列包括频谱、能量、基频和时长。
本发明由于采用了以上技术方案,使其具有以下有益效果:
本发明情感合成方法是通过获取一个发音人的中立声学特征数据和情感声学特征数据,利用深度神经网络模型建立该发音人的中立和情感声学特征的转换关系,由此在输入其他发音人的少量中立语音数据的情况下,即可获得对应的情感模型;
在获取发音人的中立声学特征数据和情感声学特征数据时,可利用发音人的中立和情感语音模型输出同一批语句的合成声学特征,利用该合成声学特征数据建立中立和情感声学特征的转换关系;也可通过录制文本内容一致的中立语句和情感语句获取发音人的中立语音数据和情感语音数据,再从中提取出中立和情感的合成声学特征,建立中立和情感声学特征的转换关系;
采用本发明,基于一个发音人的情感模型即可获得其他任何人的情感模型,利用一个发音人的中立和情感的转换关系模型即可实现,具有数据量少,构件情感模型速度快,成本低等优势。
附图说明
图1为本发明一种基于深度神经网络模型的情感合成方法的操作流程图。
图2为本发明一种基于深度神经网络模型的情感合成方法的第一种实施例的数据形成图。
图3为本发明一种基于深度神经网络模型的情感合成方法的第二种实施例的数据形成图。
图4为本发明一种基于深度神经网络模型的情感合成方法的高兴情感的合成流程图。
图5为本发明一种基于深度神经网络模型的情感合成方法的第一发音人的中立语音合成模型的结构示意图。
图6为本发明一种基于深度神经网络模型的情感合成方法的情感转换模型的结构示意图。
图7为本发明一种基于深度神经网络模型的情感合成方法的第二发音人的情感语音合成模型的结构示意图。
具体实施方式
下面结合附图及具体实施方式对本发明作进一步详细的说明。
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。
需要说明的是,本说明书所附图式所绘示的结构、比例、大小等,均仅用以配合说明书所揭示的内容,以供熟悉此技术的人士了解与阅读,并非用以限定本发明可实施的限定条件,故不具技术上的实质意义,任何结构的修饰、比例关系的改变或大小的调整,在不影响本发明所能产生的功效及所能达成的目的下,均应仍落在本发明所揭示的技术内容得能涵盖的范围内。同时,本说明书中所引用的如“上”、“下”、“左”、“右”、“中间”及“一”等的用语,亦仅为便于叙述的明了,而非用以限定本发明可实施的范围,其相对关系的改变或调整,在无实质变更技术内容下,当亦视为本发明可实施的范畴。
本发明旨在提出一种基于深度神经网络模型的情感合成方法,解决现有情感模型生成时数据量庞大使得开发时间较长且研发费用过高的问题,目的在于针对多个不同发音人,能够利用少量中立数据,快速构建对应的情感模型。
首先,请参阅图1所示,图1为本发明基于深度神经网络模型的情感合成方法的操作流程图,本发明的基于深度神经网络模型的情感合成方法主要包括有以下步骤并实现以下功能:
S001:获取第一发音人(发音人A)的中立声学特征数据和情感声学特征数据;
S002:利用深度神经网络模型建立第一发音人(发音人A)的中立声学特征数据和情感声学特征数据的情感转换模型;
S003:获取第二发音人(发音人B)的中立语音数据,建立第二发音人(发音人B)的中立语音合成模型;
S004:利用深度神经网络模型将第二发音人(发音人B)的中立语音合成模型与情感转换模型串联,得到第二发音人(发音人B)的情感语音合成模型。
本发明的基于深度神经网络模型的情感合成方法是通过获取一个发音人的中立声学特征数据和情感声学特征数据,利用深度神经网络模型建立该发音人的中立和情感声学特征的转换关系,由此在输入其他发音人的少量中立语音数据的情况下,即可获得对应的情感模型。其中,在获取发音人的中立声学特征数据和情感声学特征数据时,既可利用发音人的中立和情感语音模型输出同一批语句的合成声学特征,利用该合成声学特征数据建立中立和情感声学特征的转换关系;也可通过录制文本内容一致的中立语句和情感语句获取发音人的中立语音数据和情感语音数据,再从中提取出中立和情感的合成声学特征,建立中立和情感声学特征的转换关系。因此,采用本发明,基于一个发音人的情感模型即可获得其他任何人的情感模型,利用一个发音人的中立和情感的转换关系模型即可实现,具有数据量少,构件情感模型速度快,成本低等优势。
针对上述步骤S001,本发明提供了两种可获取第一发音人(发音人A)的中立声学特征数据和情感声学特征数据的方式,具体如下:
方式一:
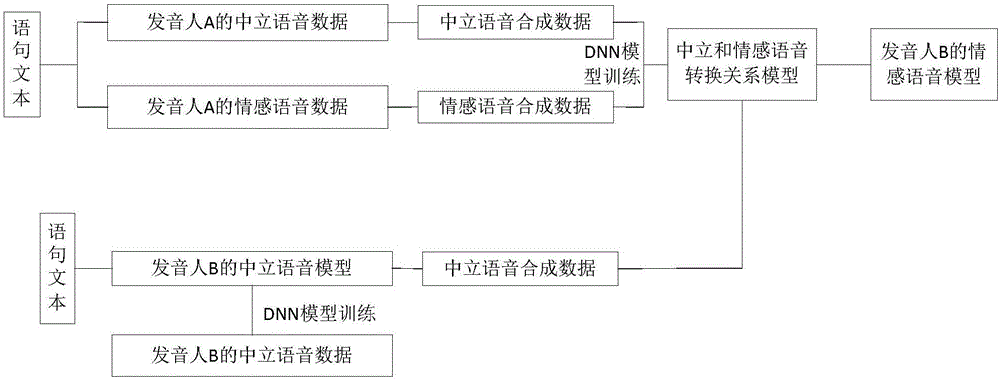
配合图2所示,图2为本发明基于深度神经网络模型的情感合成方法的第一种实施例的数据形成图,其包括:
提供第一发音人(发音人A)的一定数量的语句文本(比如2000句),该些语句文本中包括文本内容一致的中立语句文本(比如2000句)和情感语句文本(比如2000句);
从该些中立语句文本中获取第一发音人(发音人A)的中立语音数据;如采用录制该些中立语句文本,从中获取第一发音人(发音人A)的中立语音数据;
从该些情感语句文本中获取第一发音人(发音人A)的情感语音数据;如采用录制该些情感语句文本,从中获取第一发音人(发音人A)的情感语音数据;
从获取的第一发音人(发音人A)的中立语音数据中提取第一发音人的中立声学特征数据;
从获取的第一发音人(发音人A)的情感语音数据中提取第一发音人的情感声学特征数据。
方式二:
再配合图3所示,图3为本发明基于深度神经网络模型的情感合成方法的第二种实施例的数据形成图,其包括:
获取第一发音人(发音人A)的中立语音数据和第一发音人(发音人A)的情感语音数据,如采用录音获取第一发音人(发音人A)的中立语音数据和第一发音人(发音人A)的情感语音数据;
利用第一发音人(发音人A)的中立语音数据进行深度神经网络模型(Deep Neural Networks,简称DNN)模型训练,得到第一发音人(发音人A)的中立语音合成模型;
利用第一发音人(发音人A)的情感语音数据进行深度神经网络模型(DNN)模型训练,得到第一发音人(发音人A)的情感语音合成模型;
提供一定数量的语句文本(比如5000句),将该些语句文本分别输入到第一发音人(发音人A)的中立语音合成模型和第一发音人(发音人A)的情感语音合成模型,获得对应的第一发音人(发音人A)的中立声学特征数据和第一发音人(发音人A)的情感声学特征数据。
采用上述两种方式均可获取第一发音人(发音人A)的中立声学特征数据和第一发音人(发音人A)的情感声学特征,方式一较为直接,直接从录制的一定数量的语句文本中获取第一发音人(发音人A)的中立语音数据和情感语音数据,再从该些中立语音数据和情感语音数据中提取出对应的中立声学特征数据和情感声学特征数据,但是在该些语句文本的录制上,必须要求包含文本内容一致的中立语句文本和情感语句文本;而对于方式二,则不作该要求,不需要对在录制语句文本时对文本内容作要求,将一定数量的任意语句文本分别输入到中立语音合成模型和情感语音合成模型中,便可利用该中立语音合成模型和该情感语音合成模型获得对应的中立声学特征数据和情感声学特征数据,借助中立语音合成模型和情感语音合成模型获取的数据精度更高、严密性更好。
针对上述步骤S003,本发明在获取第二发音人(发音人B)的中立语音数据后,又可通过以下两种方式来建立该第二发音人(发音人B)的中立语音合成模型,请参阅图3所示,其具体包括:
方式一、该方式需基于以上述第二种方式获取第一发音人(发音人A)的中立声学特征数据和情感声学特征数据的方式:
利用录制的第二发音人(发音人B)的中立语音数据,对第一发音人(发音人A)的中立语音合成模型进行重训练(retain),得到第二发音人(发音人B)的中立语音合成模型,该步骤基于深度神经网络模型(DNN)的模型训练实现。
方式二、该方式可同时适用于上述两种获取第一发音人(发音人A)的中立声学特征数据和情感声学特征数据的方式:
利用录制的第二发音人(发音人B)的中立语音数据进行深度神经网络模型(DNN)模型训练,得到第二发音人的中立语音合成模型。
上述步骤S002是本发明的基于深度神经网络模型的情感合成方法的创新点,通过利用获取的第一发音人(发音人A)的中立声学特征数据和情感声学特征数据构建两种数据的声学转换关系,再利用深度神经网络模型(DNN)得到对应于该两种数据的声学转换关系的情感转换模型。利用该情感转换模型便可基于深度神经网络模型(DNN)获得对应发音人的情感模型(即情感语音合成模型,简称情感模型)。
本发明的基于深度神经网络模型的情感合成方法适用的情感模型包括高兴、生气、愤怒、伤心等情感模型。
本发明基于一个发音人的情感模型即可获得其他任何人的情感模型,利用一个发音人的中立和情感的转换关系模型即可实现,具有数据量少,构件情感模型速度快,成本低等优势。
本发明的基于深度神经网络模型的情感合成方法,是通过一个发音人的中立和情感语音模型输出同一批语句的合成声学特征,利用该合成声学特征数据建立中立和情感声学特征的转换关系,由此在输入其他发音人的少量中立语音数据即可获得对应的情感模型。
下面以获得高兴情感模型(即高兴情感的情感语音合成模型)为例进行说明,如图4所示,图4为本发明的基于深度神经网络模型的情感合成方法的高兴情感的合成流程图,包含有如下步骤:
(一)录制获取发音人A的中立语音数据和高兴语音数据;
(二)利用中立语音数据进行DNN(深度神经网络模型)模型训练得到发音人A的中立语音合成模型,如图5所示,图5为发音人A的中立语音合成模型的结构示意图;其中,中立语音合成数据包括中立语音的声学特征序列和对应的文本数据信息,其中的中立语音的声学特征序列包括频谱、能量、基频和时长,具体如下:
步骤一:获取输入数据:
对应文本特征,具体的,获取文本对应的传统音素和韵律等信息、并进行0\1编码,共得到1114维二值数字;同时,加入当前帧在当前音素中相对位置信息(规整到0和1之间),包括前向位置和后向位置,共2维;音素\韵律等信息0\1编码和位置信息共1116维,作为DNN网络输入;
步骤二:获取输出数据:
包括频谱、能量、基频和时长等声学特征,我们将声学特征分成两类,分别进行建模,1)频谱、能量和基频,其中频谱40维、能量1维、基频1维、基频清浊标记1维,对基频进行了考虑前面4帧和后面4帧的帧扩展,对频谱和能量参数考虑了其一阶差分和二阶差分信息,共133维;2)时长,这里为音素时长,即音素中含有的帧数,1维;
步骤三:训练DNN模型:
这里使用经典的BP(Back Propagation)神经网络构建回归模型,隐层使用sigmoid激励函数(S型生成曲线激励函数),输出层使用linear激励函数(线性激励函数),首先随机化网络参数作为初始参数,然后基于下面的MMSE(Minimum Mean Square Error,最小均方差)准则进行模型训练:
L(y,z)=||y-z||2
其中y是自然的目标参数,z是DNN模型预测的参数,训练的目标是更新DNN网络、使得L(y,z)最小。
这里对上面提到的两类声学特征分别进行建模:
1)频谱、能量和基频,共133维,网络结构为:1116-1024-1024-133,得到的中立语音合成模型记为MANS;
2)时长,共1维,这里网络输入不考虑帧在当前音素中相对位置信息,网络结构为:1114-1024-1024-1,得到的中立语音合成模型记为MAND;
(三)利用高兴语音数据进行DNN模型训练得到发音人A的高兴语音合成模型;该高兴语音数据包括高兴语音的特征序列和对应的文本数据信息,其中的高兴语音的特征序列包括频谱、能量、基频和时长,具体建模方式与发音人A的中立语音合成模型类似,得到的发音人A的情感语音合成模型的DNN模型,记为MAES和MAED。
(四)提供任意一批一定数量的语句文本(比如5000句),将该语句文本分别输入到发音人A的中立语音合成模型和发音人A的高兴语音合成模型,以对应的获得A的中立合成声学特征数据和A的高兴合成声学特征数据,然后构建A的中立合成声学特征和A的高兴合成声学特征的声学转换关系,该中立和高兴的语音转换关系利用DNN得到情感转换模型,如图6所示,图6为本发明的基于深度神经网络模型的情感合成方法的情感转换模型的结构示意图,具体内容如下:
步一:获取输入数据:
根据输入的文本,使用发音人A的中立语音合成模型,得到对应的中立声学特征数据,具体的,使用发音人A的中立语音合成模型MANS得到频谱、能量和基频特征,使用发音人A的中立语音合成模型MAND得到音素时长特征;
步二:获取输出数据:
根据输入的文本,使用发音人A的情感语音合成模型、得到对应的声学特征,具体的,使用发音人A的情感语音合成模型MAES得到频谱、能量和基频特征,使用发音人A的情感语音合成模型MAED得到音素时长特征;该两对特征作为目标情感声学特征参数。
步三:训练DNN模型:
这里使用BP(Back Propagation)神经网络构建回归模型(DNN模型的一种),隐层使用sigmoid激励函数,输出层使用linear激励函数,首先随机化网络参数作为初始参数,然后基于下面的MMSE准则进行模型训练:
L(y,z)=||y-z||2
其中y是目标情感声学特征参数,z是DNN模型预测的情感声学特征参数,训练的目标是更新DNN网络、使得L(y,z)最小。
这里对上面提到的两类声学特征分别进行建模:
1)频谱、能量和基频,共133维,网络结构为:133-1024-1024-133,得到的模型记为MCS;
2)时长,共1维,网络结构为:1-1024-1024-1,得到的模型记为MCD;
该模型MCS和模型MCD即为发音人A的中立声学特征数据与情感声学特征数据的情感转换模型。
而后,获取发音人B的中立语音数据。
再利用发音人B的中立语音数据,对发音人A的中立语音合成模型进行重训练(retrain),得到发音人B的中立语音合成模型;或者,也可以利用获取的发音人B的中立语音数据直接进行深度神经网络模型(DNN)模型训练,同样可以得到发音人B的中立语音合成模型,本实施例中采用了前一种方案。其中的中立语音数据包括中立语音的特征序列和对应的文本数据信息,其中的中立语音的特征序列包括频谱、能量、基频和时长,具体建模方式与发音人A的中立语音合成模型类似,只是这里不是随机化网络参数,而是使用发音人A的中立语音合成模型作为初始参数,得到的发音人B的中立语音合成模型的DNN模型,记为MBNS和MBND。
将发音人B的中立语音合成模型MBNS和MBND,分别与情感转换模型MCS和MCD进行串联,得到发音人B的情感语音合成模型MBNS-MCS和MBND-MCD,结构如图7所示,图7为发音人B的情感语音合成模型的结构示意图。
在合成阶段,对于待合成的文本,使用合成前端对文本分析,获取对应的文本特征,具体地,获取文本对应的传统音素和韵律等信息,并进行0\1编码,共得到1114维二值数字;同时,加入当前帧在当前音素中相对位置信息(规整到0和1之间),包括前向位置和后向位置,共2维;音素\韵律等信息0\1编码和位置信息共1116维,作为DNN网络输入;
预测步骤如下:
1、预测音素时长信息,这里网络输入不考虑帧在当前音素中相对位置信息,将1114维音素\韵律等信息的0\1编码信息作为输入,预测出音素时长;
2、预测频谱、能量、基频信息,将上面前端分析得到的1116维信息作为输入,预测出频谱、能量、基频信息,共133维;
3、对预测出的声学参数,通过下面的公式进行参数生成,以得到平滑的声学参数:
其中,W是计算一阶差分和二阶差分的窗函数矩阵,C为待生成的声学特征,M为DNN网络预测出的声学特征,U为从训练音库中统计得到的全局方差。
4、使用声学特征C,通过声码器合成出语音,得到发音人B的情感语音合成模型。
以上所述仅是本发明的较佳实施例而已,并非对本发明做任何形式上的限制,虽然本发明已以较佳实施例揭露如上,然而并非用以限定本发明,任何熟悉本专业的技术人员,在不脱离本发明技术方案的范围内,当可利用上述揭示的技术内容作出些许更动或修饰为等同变化的等效实施例,但凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与修饰,均仍属于本发明技术方案的范围内。
- 还没有人留言评论。精彩留言会获得点赞!