操作语音识别功能的电子设备和方法与流程
本公开总体上涉及语音识别的电子设备和方法,且更具体地,涉及改进的语音识别方法和利用该方法的电子设备。
背景技术:
由于硬件和通信技术的发展,电子设备用于广泛的领域,并提供用户需要的各种功能。通常,在包括语音输入设备(例如,麦克风)在内的各种电子设备中实现语音识别技术。利用语音识别技术的输入正在逐渐取代物理输入,并被推广为提供对电子设备的语音控制。
技术实现要素:
[技术问题]
在语音识别技术中,已经提出了一种方案,即无缝语音识别方案,以基于用户语音输入来激活电子设备并执行无缝语音命令。由于电子设备必须始终准备好记录用户的语音以用于语音识别,所以无缝语音识别方案在处于待机状态时必须持续地维持语音识别系统。需要将系统持续地维持在待机状态以执行无缝语音识别导致了以下问题。如果使用低功率芯片来实现语音识别系统以减少电流消耗,则由于有限的存储器和系统组件之间的性能差异,语音识别错误率增加。如果使用高性能芯片来改善语音识别错误率,则高性能芯片必须始终保持在活动状态,从而增加电流消耗损失。
[问题的解决方案]
根据本公开的一个方面,提供了一种电子设备,该电子设备包括:第一处理器,被配置为接收音频信号,对所述音频信号执行第一语音识别,以及基于所述第一语音识别的结果向第二处理器传输驱动信号;以及所述第二处理器,被配置为响应于所述驱动信号,基于所述第一语音识别的语音信号和所述音频信号中的至少一项来执行第二语音识别。
根据本公开的另一方面,提供了一种由电子设备执行语音识别的方法,所述方法包括:接收音频信号;由第一处理器对所述音频信号执行第一语音识别;由所述第一处理器基于所述第一语音识别的结果向第二处理器传输驱动信号;以及由所述第二处理器响应于所述驱动信号,基于所述第一语音识别的语音信号和所述音频信号中的至少一项来执行第二语音识别。
[发明的有益效果]
做出本公开以处理上述问题和缺点,并至少提供下述优点。因此,本公开的一个方面提供操作语音识别功能的电子设备和方法,其使电子设备中的语音识别功能的错误最小化,增加识别率,并且降低电流消耗,同时提高语音识别性能的效率。
附图说明
根据结合附图给出的以下详细描述,将更清楚本公开的上述和其他方面、特征和优点,在附图中:
图1是根据本公开实施例的电子设备的框图;
图2是根据本公开实施例的电子设备的框图;
图3是根据本公开实施例的电子设备的框图;
图4是示出了根据本公开实施例的用于电子设备中的音频输入模块的语音识别的方法的流程图;
图5是示出了根据本公开实施例的用于电子设备中的音频处理模块的语音识别的方法的流程图;
图6是示出了根据本公开实施例的用于电子设备中的语音识别模块的语音识别的方法的流程图;
图7是示出了根据本公开实施例的用于电子设备中的主处理器的语音识别的方法的流程图;
图8是示出了根据本公开实施例的用于电子设备中的主处理器的语音识别的方法的流程图;
图9是示出了根据本公开实施例的电子设备的组件之间的语音识别的流程图;
图10是示出了根据本公开实施例的电子设备的组件之间的语音识别的流程图;
图11是示出了根据本公开实施例的电子设备的组件之间的语音识别的流程图;
图12a提供了根据本公开实施例的电子设备的语音识别操作屏幕的示例;
图12b提供了根据本公开实施例的电子设备的语音识别操作屏幕的示例;
图13a提供了根据本公开实施例的电子设备的语音识别操作屏幕的示例;以及
图13b提供了根据本公开实施例的电子设备的语音识别操作屏幕的示例。
具体实施方式
下文中,参考附图详细地描述了本公开的实施例。
在各种实施例中,“音频信号”包括通过声音信息从音频输入模块输入的信号,并且“语音信号”包括基于语音识别从音频信号中提取的语音信号。
在各种实施例中,语音识别包括提取并仅识别要识别的字的关键字识别、识别说话人的语音作为执行命令的命令识别、以及识别注册特定说话人的语音的说话人识别中的至少一项。语音识别可以分开识别用于触发语音功能的语音触发(即触发语音)和输入的用于在识别出语音触发之后基于语音来执行功能的语音命令(即命令语音)。
例如,关键字识别和命令识别可以是识别许多未指定语音的说话人无关识别方案,并且说话人识别可以是识别特定说话人语音的说话人相关识别方案。关键字识别可以通过分析语音序列以识别连续声音的模式来工作,并且确定在语音模式的连续声音中说出了与关键字相对应的字。如果存在先前存储的关键字,则针对关键字的识别可能会是成功的,而如果没有关键字,则识别可能会失败。说话人识别可以是确定关于注册说话人的语音信息和语音信号之间的相似度的说话人验证功能。当语音输入对应于注册说话人的语音输入时,说话人识别成功,而当语音输入不是注册说话人的语音信号时,说话人识别失败。对于说话人识别,电子设备可以接收注册说话人的语音,提取说话人的语音的特征,对特征进行建模,并存储特征以供以后比较。
图1是根据本公开实施例的电子设备的框图。
参考图1,根据各种实施例的电子设备101包括音频输入模块110、音频处理模块130、存储模块140、显示模块150和主处理器170。
音频输入模块110接收声音信息作为音频信号。例如,音频输入模块110可以是麦克风(mic)。
音频输入模块110保持在开启状态,而不管主处理器170的睡眠模式或操作模式。音频输入模块110以每个预定时间间隔将音频信号存储在音频输入模块110的缓冲器111中。音频输入模块110所接收的声音信息可以包括噪声(例如,来自电子设备周围环境的声音)以及待输入的语音和特定声音。
音频输入模块110可以实现为专用集成电路(asic)的形式以支持声音识别功能。例如,音频输入模块110可以确定由输入声音生成的音频信号是否是要求驱动语音识别系统的声音,并且当音频信号是要求驱动语音识别系统的声音时,唤醒音频处理模块130。例如,当音频信号的大小(例如,db水平等)大于或等于预设阈值时,音频输入模块110将音频信号识别为要求驱动语音识别系统的声音。关于对声音是否要求驱动语音识别系统的确定的参考可以是音频信号的大小、频带等,并且可以根据设计者的意图来设置。音频输入模块110可以向音频处理模块130(或语音识别模块)传输驱动信号,例如唤醒信号、识别请求信号、中断信号等,并且向音频处理模块130的缓冲器131传输存储在缓冲器111中的音频信号。
音频处理模块130可以连接到音频输入模块110以处理向/从音频输入模块110和主处理器170发送/接收的音频信号,并执行处理音频信号的功能。例如,音频处理模块130可以执行将模拟信号转换为数字信号或将数字信号转换为模拟信号的功能、音频输入/输出预处理/后处理功能、和语音识别功能。
音频处理模块130可以包括数字信号处理器(dsp)。音频处理模块130可以独立于主处理器操作或依赖于主处理器操作,并且在睡眠模式或操作模式下操作。音频处理模块130可以根据处理音频信号(例如,再现声音、转换信号等)的功能来控制音频处理模块130的操作时钟。音频处理模块130处理音频信号并以预定时间间隔将音频信号存储在缓冲器131中。
当在睡眠模式下从音频输入模块110传输驱动信号时,音频处理模块130可以将睡眠模式切换到操作模式。音频处理模块130可以响应于驱动信号而被激活以分析从音频输入模块110传输的音频信号并对音频信号执行语音识别。音频处理模块130可以通过执行关键字识别和说话人识别中的至少一项来识别由说话人(或注册说话人)输入的语音触发。当语音识别成功时,音频处理模块130在缓冲器131中连续地缓冲从音频输入模块110输入的音频信号一段时间(在该段时间期间主处理器170被激活),并且在主处理器170被激活的时间点传输所缓冲的音频信号和/或语音信号。相对地,音频处理模块130可以在语音识别失败时将操作模式切换到睡眠模式。
例如,音频处理模块130可以并行或顺序地执行关键字识别和说话人识别。当关键字识别和说话人识别都成功时,音频处理模块130向主处理器170传输驱动信号。当关键字识别和说话人识别之一失败时,音频处理模块130切换到睡眠模式。
在另一示例中,音频处理模块130执行关键字识别和说话人识别之一,并且当识别成功时激活主处理器170或者当在识别失败时切换到睡眠模式。
当语音识别(例如,关键字识别和说话人识别中的至少一项)成功时,音频处理模块130连续地向主处理器传输从音频输入模块输入的音频信号,并且当从主处理器170接收到识别失败结果时,将操作模式切换到睡眠模式。存储模块140存储从主处理器或其它元件(例如,音频处理模块等)接收的或由其它元件生成的命令或数据。例如,存储模块140存储用于引导电子设备101并操作前述元件的操作系统(os)、至少一个应用程序、根据功能执行的数据等。
存储模块140可以包括编程模块,例如内核、中间件、应用编程接口(api)、应用等。上述编程模块的每一个可以具有软件、固件、硬件或者其中至少两个的组合的形式。存储模块140可以存储用于语音识别功能的至少一个语音识别算法和关于注册说话人的建模信息。
显示模块150执行向用户显示图像或数据的功能。显示模块150可以包括显示面板。显示面板可以采用例如液晶显示器(lcd)或有源矩阵有机发光二极管(am-oled)。显示模块150还可以包括控制显示面板的控制器。显示面板可以实现为例如柔性的、透明的和/或可穿戴的。同时,显示模块150可以被配置为与触摸面板耦接的模块(例如,触摸屏类型)。显示模块150可以根据电子设备101的应用/功能执行而显示各种屏幕,例如呼叫应用/功能执行屏幕、相机执行应用屏幕、语音识别功能执行屏幕等。
主处理器170从电子设备101的元件(例如,音频处理模块130等)接收命令,分析接收到的命令,并根据所分析的命令执行计算和数据处理。例如,当供电时,主处理器170控制电子设备101的引导过程,并执行存储在程序区域中的各种应用程序以根据用户的设置执行功能。主处理器可以包括一个或多个应用处理器(ap)、或一个或多个通信处理器(cp)。
主处理器170可以在睡眠模式下或操作模式下操作。当从音频处理模块130传输了用于语音识别的驱动信号时,主处理器170将睡眠模式切换到操作模式,并执行语音识别,例如关键字识别、命令识别和说话人识别中的至少一项。当主处理器170包括多个计算设备时,主处理器170可以激活用于语音识别功能的一个计算设备,以响应于音频处理模块130的驱动信号而执行语音识别。
主处理器170分析音频信号和/或语音信号,并且并行地或顺序地执行关键字识别、说话人识别、和命令识别。
当音频处理模块130执行关键字识别和说话人识别之一时,主处理器170执行另一个语音识别,即,未由音频处理模块130执行的语音识别。此外,处理器170可以执行命令识别。
当关键字识别和说话人识别中的至少一项失败时,主处理器170向音频处理模块130传输识别失败结果,并将操作模式切换到睡眠模式。
主处理器170可区分地识别语音触发和语音命令,并且当语音识别成功时,根据所识别的语音命令执行电子设备的功能。例如,当注册在电子设备中的用户在睡眠模式下输入语音“higalaxy,相机执行”时,电子设备通过音频输入模块110、音频处理模块130和主处理器170顺序地处理语音输入,并且主处理器170识别用于电子设备操作的语音输入“higalaxy,相机执行”,以例如关闭屏幕并执行相机功能。这里,“higalaxy”对应于用于激活基于语音的功能的语音触发,而“相机执行”对应于用于响应于语音输入而执行相应功能的语音命令。更具体地,语音识别可被划分为用于自动执行语音识别应用的语音触发和在识别语音触发之后输入的语音命令。例如,当对来自音频信号的对应于语音触发的“higalaxy”的识别成功时,音频处理模块130向主处理器传输驱动信号。当对应于语音触发的“higalaxy”的识别成功时,并且如果对应于语音命令的“相机执行”的识别成功,则主处理器操作电子设备并执行相机功能。
主处理器170的语音识别可以由语音识别系统实现,该语音识别系统比在音频处理模块130中实现的简单语音识别系统复杂。该复杂的语音识别系统可以使用相对更多的资源(例如内存、计算量和相似度测量)来确定语音识别,并且与简单语音识别系统相比具有更高的识别率。
例如,由主处理器170执行的关键字识别可以由基于维特比(viterbi)解码仅提取要识别的单个字的识别算法来实现,并且与音频处理模块130相比,主处理器170可以具有关键字识别的相对较小的误识别率。主处理器170的说话人识别可以由以下一项或多项的组合来实现:基于深度神经网络的识别算法、基于多神经网络的识别算法、以及基于通用背景模型-高斯混合模型(ubm-gmm)的识别算法。基于多神经网络的识别算法可以通过存在隐藏层的神经网络在考虑诸如关键字识别结果、信噪比(snr)和背景噪声去除等多个因素的情况下确定认证成功/失败。ubm-gmm算法可以通过比较基于gmm的背景模型得分和说话人模型得分的二进制确定方法,以帧为单位比较ubm值和说话人模型值来确定认证成功/失败。
主处理器170可以在执行语音识别的同时控制显示模块150。
例如,主处理器170在操作模式下执行语音识别的同时维持显示模块150的关闭状态。然后,如果主处理器的语音识别成功,则主处理器170打开显示模块以显示与语音命令相对应的电子设备的功能执行屏幕,或者如果语音识别失败,则维持显示模块的关闭状态。
在另一示例中,主处理器170在操作模式下执行语音识别的同时控制对通知语音识别状态的屏幕的输出。主处理器170响应于语音识别成功而显示电子设备的功能执行屏幕,或者当语音识别失败时关闭显示模块。
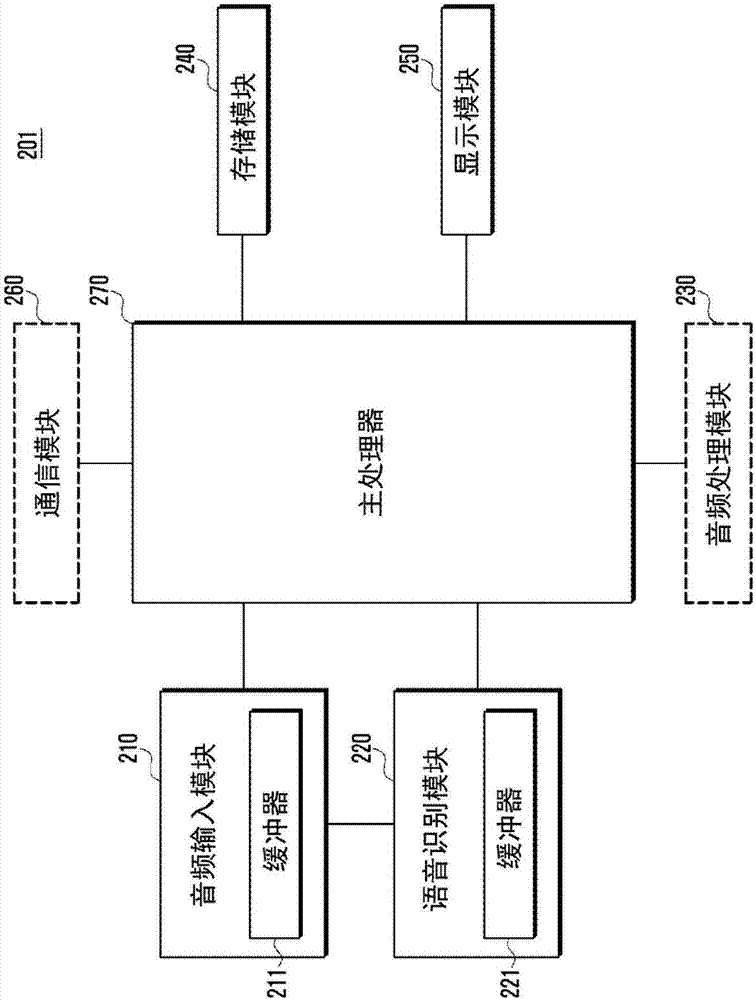
图2是根据本公开实施例的电子设备的框图。
参考图2,根据各种实施例的电子设备201包括音频输入模块210、语音识别模块220、音频处理模块230、存储模块240、通信模块260、显示模块250、和主处理器270。
音频输入模块210连续操作,即不改变操作状态,而不管主处理器270的睡眠模式或操作模式。音频输入模块210可以像图1所述的音频输入模块110一样实现为asic类型以支持声音识别功能。
在图2的实施例中,音频输入模块210确定存储在缓冲器211中的音频信号是否是要求驱动语音识别系统的声音,并且当音频信号是要求驱动语音识别系统的声音时,唤醒语音识别模块220。当输入音频信号被确定为要求驱动语音识别系统的声音时,音频输入模块210向语音识别模块220传输驱动信号(例如,唤醒信号、语音识别请求信号、中断信号等),并向语音识别模块220的缓冲器221传输存储在缓冲器211中的音频信号。语音识别模块220连接到音频输入模块210和主处理器270,并支持语音识别(例如,关键字识别和说话人识别中的至少一项)功能。语音识别模块220可以包括仅操作用于语音识别功能的低功率处理器。语音识别模块220可以独立于主处理器270操作或依赖于主处理器270操作,并且可以在睡眠模式或操作模式下独立地操作。例如,语音识别模块220可以维持睡眠模式,而不管主处理器270的操作状态。当从音频输入模块210接收到驱动信号时,语音识别模块220变换到操作模式以基于从音频输入模块210传输的音频信号来执行语音识别。当语音识别成功时,语音识别模块220驱动主处理器270并向主处理器270传输存储在缓冲器221中的音频信号。语音识别模块220在语音触发识别成功时驱动主处理器。
语音识别模块220可以在语音识别(例如,关键字识别和说话人识别中的至少一项)失败时切换到睡眠模式,或者可以在从主处理器270接收到语音识别失败信息时将操作模式切换到睡眠模式。
语音识别模块220可被包括在图1的音频处理模块130中。
同时,在图2的实施例中,与图1的实施例不同的是,电子设备201还包括音频处理模块230,其处理音频数据,诸如音频信号预处理/后处理、信号转换功能、噪声去除功能等,而不涉及语音识别功能。
存储模块240和显示模块250与图1所述的存储模块140和显示模块150相似,且省略其详细描述以避免冗余。
根据图2的实施例的主处理器270执行与图1中所述的主处理器170的基本操作相似的操作,并省略其重复描述。
与图1的实施例不同的是,图2的主处理器270从语音识别模块220接收驱动信号,以响应于来自语音识别模块220的驱动信号而将睡眠模式切换到操作模式,并执行语音识别。主处理器270可以由与在图1的主处理器中实现的语音识别相同的语音识别系统实现。当语音识别成功时,主处理器270根据与语音输入相对应的命令执行电子设备的功能。当语音识别失败时,主处理器270向语音识别模块220传输识别失败结果,并将操作模式切换到睡眠模式。
图2的实施例中的电子设备201还包括通信模块260。
通信模块260的示例包括收发器,以通过有线/无线通信与网络进行通信,以与外部设备(例如,服务器)进行语音、视频或数据通信,且通信模块260由主处理器270控制。无线通信可以包括例如wi-fi、蓝牙(bt)、近场通信(nfc)、全球定位系统(gps)和蜂窝通信(例如,长期演进(lte)、高级长期演进(lte-a)、码分多址(cdma)、宽带cdma(wcdma)、通用移动电信系统(umts)、无线宽带(wibro)或全球移动通信系统(gsm))中的至少一种。有线通信可以包括例如通用串行总线(usb)、高清多媒体接口(hdmi)、推荐标准232(rs-232)和普通老式电话服务(pots)中的至少一种。
通信模块260与服务器通信以附加地支持语音识别功能。例如,当语音识别模块220第一次成功地进行语音识别并且主处理器270第二次成功地进行语音识别时,可以通过通信模块260向语音识别服务器发送音频信号和/或语音信号,该语音识别服务器与电子设备相比使用附加的资源。
根据另一实施例,主处理器区分语音触发和在识别语音触发之后输入的语音命令,并向服务器传输经区分的语音。主处理器传输与在识别语音触发之后输入的语音命令相对应的语音信号,或者传输标识语音触发和语音命令分离的时间点的信息。然后,当从主处理器270传输了未被区分的音频信号或语音信号时,服务器可以区分语音触发和语音命令,并执行语音识别。
服务器可以对从电子设备201传输的音频信号(或/和语音信号)执行语音识别,以识别语音命令并向电子设备提供语音命令的识别结果。当语音识别成功时,服务器可以将语音命令转换为文本,并向电子设备201传输关于所转换文本的信息。当语音识别失败时,服务器可以向电子设备201提供失败信息。
电子设备201的主处理器270可以识别有限的语音命令,而与主处理器270相比,服务器可以识别附加语音命令。例如,主处理器270可以识别简单的或预配置在电子设备中的语音命令,例如“相机执行”或“电话呼叫执行”,并且基于所识别的语音命令来执行电子设备201的功能。相对地,电子设备201可以请求服务器识别复杂的或各种语音命令,从服务器接收语音识别结果,并执行与语音识别相对应的功能。
通信模块260可以从服务器接收关于服务器所执行的语音识别的结果的信息。当语音识别成功并且从服务器接收到文本信息时,主处理器270执行与接收到的文本信息相对应的功能。当从服务器接收到语音识别失败信息时,主处理器270将操作模式切换到睡眠模式。
图3是根据本公开实施例的电子设备的框图。
参考图3,电子设备301包括音频输入模块310、语音识别模块320、音频处理模块330、存储模块340、显示模块350、通信模块360和主处理器370。
由于音频输入模块310、存储模块340、显示模块350和通信模块360与上述图2的音频输入模块210、存储模块240、显示模块250和通信模块260相同,省略对其的详细描述以避免冗余。
根据图3的实施例的语音识别模块320接收音频输入模块310的缓冲器311中存储的音频信号,并基于音频信号第一次执行语音识别。当语音识别成功时,语音识别模块320唤醒音频处理模块330并向音频处理模块330传输语音识别模块320的缓冲器321中存储的音频信号。
音频处理模块330基于语音识别模块320的激活信号将睡眠模式切换到操作模式,接收语音识别模块320的缓冲器321中存储的音频信号,并基于音频信号第二次执行语音识别。当语音识别成功时,音频处理模块330通过向主处理器370传输驱动信号并传输缓冲器331中存储的音频信号来激活主处理器370。
由于根据图3的实施例的主处理器370执行与图2中所述的主处理器270的语音识别操作相同的操作,因此省略对其的重复描述以避免冗余。
主处理器370从音频处理模块330接收驱动信号,基于驱动信号将睡眠模式切换到操作模式,并对从音频处理模块330传输的音频信号第三次执行语音识别。
语音识别模块320和音频处理模块330执行关键字识别和说话人识别中的至少一项,且主处理器370执行关键字识别、说话人识别和命令识别中的至少一项。当语音识别成功时,主处理器370根据与语音输入相对应的命令来执行电子设备的功能。如果语音识别失败,则主处理器370向语音识别模块320和音频处理模块330传输识别失败结果,并将操作模式切换到睡眠模式。
如果语音识别成功,则主处理器370通过通信模块360向支持语音识别的服务器发送音频信号和/或语音信号,并从服务器接收关于语音识别的识别结果信息。由于服务器的操作与图2中所述的服务器的操作相同,因此省略对其的详细描述以避免冗余。
如果语音识别成功并且从服务器接收到文本信息,则主处理器370执行与接收到的文本信息相对应的功能。如果接收到语音识别失败信息,则主处理器370将操作模式切换到睡眠模式。
下文中,描述操作用于电子设备的各种组件的语音识别功能的方法。
图4是示出了根据本公开实施例的用于电子设备中的音频输入模块的语音识别的方法的流程图。
参考图4,在步骤410中,电子设备的音频输入模块在操作模式下操作。例如,音频输入模块继续操作而不管电子设备的操作状态或睡眠(或待机)状态,例如,主处理器在睡眠模式下操作,显示模块处于关闭状态,并获取由声音生成的音频信号。
在步骤420中,音频输入模块获取由声音生成的音频信号,并在步骤430中将音频信号存储在缓冲器中。音频输入模块内所包括的缓冲器可以实现为循环缓冲器,并且可以按照音频信号存储在循环缓冲器中的顺序向音频处理模块(或音频识别模块)传输音频信号。
在步骤440中,音频输入模块确定音频信号是否是要求驱动语音识别系统的声音。例如,当缓冲器中的由声音生成的音频信号的大小是大于或等于预设阈值的音频信号或特定频带内的音频信号时,音频输入模块将音频信号识别为要求驱动语音识别系统的声音。
如果音频信号被识别为要求驱动语音识别系统的声音,则在步骤450中,音频输入模块向音频处理模块或语音识别模块传输用于激活请求的驱动信号。在步骤460中,音频输入模块向所激活的音频处理模块(或语音识别模块)传输缓冲器中存储的音频信号。
例如,音频输入模块首先在音频处理模块或语音识别模块被激活的时间内向音频处理模块或语音识别模块内的缓冲器传输音频信号,然后向音频处理模块或语音识别模块顺序传输实时获取的音频信号。
同时,如果在步骤440中音频信号未被识别为要求驱动语音识别系统的声音,则音频输入模块返回到步骤420并重复获取音频信号的操作。如上所述,音频输入模块可以保持操作状态,以不断地识别声音,并且如果声音被识别,则激活音频处理模块或语音识别模块以处理音频信号并发送音频信号。
图5是示出了根据本公开实施例的用于电子设备中的音频处理模块的语音识别的方法的流程图。
参考图5,在步骤510中,电子设备的音频处理模块初始在睡眠模式下操作。例如,当电子设备处于睡眠(或待机)状态时(例如,主处理器在睡眠模式下操作且显示模块处于关闭状态),音频处理模块在睡眠模式下操作。
在步骤520中,音频处理模块从音频输入模块接收驱动信号。当接收到驱动信号时,在步骤530中,音频处理模块将睡眠模式切换到操作模式。在步骤540中,音频处理模块对从音频输入模块输入的音频信号执行语音识别。语音识别可以包括关键字识别和说话人识别。音频处理模块在音频信号中识别与语音触发相对应的关键字。
音频处理模块的关键字识别可以使用基于维特比解码仅提取要识别的字的识别算法来执行,而说话人识别可以使用简单的基于神经网络的识别算法来执行。
在步骤550中,音频处理模块确定语音识别是否成功,并在步骤560中传输驱动信号以请求激活主处理器。
音频处理模块基于从音频输入模块传输的音频信号并行地或顺序地执行关键字识别和说话人识别,或者执行关键字识别和说话人识别之一。例如,音频处理模块识别用于自动驱动语音识别系统或应用的语音触发。
在步骤570中,音频处理模块向主处理器传输音频信号(例如,语音信号)。音频处理模块对从音频输入模块传输的音频信号实时执行语音识别,并且当语音识别成功时,在主处理器被激活的时间期间缓冲音频信号。当主处理器被激活时,音频处理模块向主处理器实时传输音频信号。
同时,如果在步骤550中确定语音识别失败,则音频处理模块在步骤590中将操作模式切换到睡眠模式。
在操作模式下,在步骤580中,音频处理模块从主处理器接收根据主处理器的语音识别失败的失败信息。当从主处理器接收到语音识别失败信息时,在步骤590中,音频处理模块将操作模式切换到睡眠模式。
图6是示出了根据本公开实施例的用于电子设备中的语音识别模块的语音识别的方法的流程图。
参考图6,电子设备包括语音识别模块,且在步骤610中,语音识别模块初始在睡眠模式下操作。语音识别模块实现低功率芯片以减少电流消耗并且可以限制性地操作,即仅对语音识别功能进行操作。语音识别模块可被包括在音频处理模块中或者作为与音频处理模块分离的元件实现在电子设备中。
在步骤620中,音频识别模块从音频输入模块接收驱动信号。当接收到驱动信号时,在步骤630中,语音识别模块将睡眠模式切换到操作模式。在步骤640中,语音识别模块对从音频输入模块传输的音频信号执行语音识别。
语音识别可以包括关键字识别和说话人识别中的至少一项。此外,语音识别模块可以识别用于自动驱动语音识别应用的语音触发。在步骤650中,语音识别模块确定语音识别是否成功,并且如果语音识别成功,则在步骤660中向主处理器或音频处理模块传输驱动信号以请求激活。
例如,当在语音识别功能中未涉及电子设备的音频处理模块时,在语音识别成功的情况下,语音识别模块激活主处理器。当语音识别模块和音频处理模块在电子设备中分开实现并且在语音识别功能中未涉及音频处理模块时,语音识别模块激活音频处理模块。
在步骤670中,语音识别模块向主处理器或音频处理模块传输音频信号(例如,语音信号)。同时,如果在步骤650中确定语音识别失败,则在步骤690中,语音识别模块将操作模式切换到睡眠模式。
当在操作模式下在步骤680中语音识别模块从主处理器或音频处理模块接收到根据语音识别失败的失败信息时,在步骤690中,语音识别模块将操作模式切换到睡眠模式。
图7是示出了根据本公开实施例的用于电子设备中的主处理器的语音识别的方法的流程图。
参考图7,在步骤710中,电子设备的主处理器在睡眠模式下操作。主处理器的睡眠模式是指未使用电子设备的状态,即,应用处理器的非活动状态。睡眠模式的主处理器阻止对与主处理器相连的某些功能块的供电。
如果主处理器在睡眠模式下操作,则音频输入模块保持在活动状态,且即使便携式终端未被使用,也检测声音信息,获取音频信号,并将音频信号存储在缓冲器中。
在步骤720中,主处理器接收请求激活的驱动信号。例如,主处理器在睡眠模式下从音频处理模块或语音识别模块接收驱动信号。
在步骤730中,主处理器响应于驱动信号而将睡眠模式切换到操作模式。在步骤740中,主处理器从音频处理模块或语音识别模块接收音频信号(或/和语音信号),并在步骤750中对音频信号(或/和语音信号)执行语音识别。例如,主处理器基于从音频处理模块输入的音频信号或由音频处理模块或语音识别模块第一次识别的语音信号来执行语音识别。
主处理器由复杂的语音识别系统实现,该复杂的语音识别系统与在音频处理模块或语音识别模块中实现的简单语音识别系统相比使用相对更多的资源。例如,主处理器的关键字识别由基于维特比解码仅提取要识别的字的识别算法来实现。主处理器的说话人识别可以由以下一项或多项的组合来实现:基于深度神经网络的识别算法、基于多神经网络的识别算法、以及基于ubm-gmm的识别算法。
主处理器通过区分用于自动执行语音识别应用的语音触发和在识别语音触发之后输入的语音命令来执行语音识别。备选地,主处理器在活动状态下对从音频处理模块或语音识别模块传输的音频信号执行语音识别。
在步骤760中,主处理器确定语音识别是否成功。如果语音识别成功,则在步骤770中,主处理器识别与语音识别相对应的命令,并基于语音命令执行电子设备的功能。
如果在步骤760中语音识别失败,则在步骤780中,主处理器传输向音频处理模块或语音识别模块通知语音识别失败的失败信息,并在步骤790中将操作模式切换到睡眠模式。
主处理器在执行语音识别的同时控制显示模块的开启/关闭操作。在图12a、图12b、图13a和图13b中描述与主处理器的语音识别有关的显示模块的开启/关闭操作的示例。
图8是示出了根据本公开实施例的用于电子设备中的主处理器的语音识别的方法的流程图。
参考图8,在步骤810中,电子设备的主处理器在睡眠模式下操作。在步骤820中,主处理器接收请求激活的驱动信号。例如,在睡眠模式下,主处理器从音频处理模块或语音识别模块接收驱动信号。
在步骤825中,主处理器响应于驱动信号而将睡眠模式切换到操作模式。在步骤830中,主处理器从音频处理模块或语音识别模块获取音频信号(或/和语音信号),并在步骤840中对音频信号执行语音识别。
在步骤845中,主处理器确定语音识别是否成功,并且当语音识别成功时,在步骤850中通过通信模块向支持语音识别的服务器发送语音识别请求和音频信号(和/或语音信号)。主处理器向服务器传输以下至少一项:从音频输入模块输入的基于外部声音的音频信号和基于语音识别来提取的语音信号。主处理器由复杂的语音识别系统实现,该复杂的语音识别系统与在音频处理模块或语音识别模块中实现的简单语音识别系统相比使用更多的资源。主处理器通过区分用于自动执行语音识别应用的语音触发和在识别语音触发之后输入的语音命令来执行语音识别。主处理器传输与在识别语音触发之后输入的语音命令相对应的语音信号,或者传输标识语音触发和语音命令分离的时间点的信息。然后,服务器基于从电子设备传输的音频信号(或/和语音信号)执行语音识别。由服务器执行的语音识别可以是关键字识别、说话人识别、和命令识别中的至少一项。如上所述,与主处理器相比,服务器可以识别更多语音命令。服务器可以通过基于深度神经网络(dnn)的ubm-gmm算法来执行语音识别,并向电子设备发送关于语音识别的结果信息。例如,当语音识别成功时,服务器可以将所识别的语音命令转换为文本信息,并向电子设备发送该文本信息。当语音识别失败时,服务器可以向电子设备发送向电子设备通知语音识别失败的失败信息。
在步骤855中,主处理器从服务器接收语音识别结果。当在步骤860中主处理器基于语音识别的结果接收到关于语音识别的成功信息时,在步骤865中,主处理器识别与语音识别相对应的命令,并基于语音命令执行电子设备的功能。
当语音识别失败时,在步骤870中,主处理器传输向音频处理模块或语音识别模块通知语音识别失败的失败信息,并在步骤880中将操作模式切换到睡眠模式。
图9是示出了根据本公开实施例的用于电子设备的组件之间的语音识别的方法的流程图。
参考图9,在步骤910中,电子设备通过音频输入模块识别声音。当音频输入模块识别出声音时,在步骤920中,电子设备向音频处理模块传输驱动信号以请求激活。在步骤911中,音频处理模块在睡眠模式下操作,并且当从音频输入模块接收到驱动信号时,在步骤930中,音频处理模块被唤醒并切换到操作模式。在步骤935中,电子设备可以通过音频处理模块基于从音频输入模块获取的音频信号(例如,语音信号)执行语音识别。当音频处理模块成功进行了语音识别时,在步骤940中,音频处理模块向主处理器传输驱动信号以请求激活。同时,当基于语音识别的结果,音频处理模块进行语音识别失败时,电子设备将音频处理模块切换到睡眠模式并使主处理器保持在睡眠模式下。
在步骤912中,主处理器在睡眠模式下操作,并且当从音频处理模块接收到驱动信号时,在步骤950中,主处理器被唤醒并切换到操作模式。在步骤955中,主处理器对基于由音频处理模块第一次执行的语音识别所提取的语音信号和从音频输入模块输入的音频信号第二次执行语音识别。
当基于语音识别的结果,主处理器成功进行了语音识别时,在步骤960中,电子设备基于所识别的语音命令执行其功能。同时,当基于语音识别的结果,主处理器进行语音识别失败时,在步骤975中,电子设备向音频处理模块传输语音识别失败信息,并将音频处理模块和主处理器切换到睡眠模式。
图10是示出了根据本公开实施例的电子设备的组件之间的语音识别的流程图。
参考图10,在步骤1010中,电子设备通过音频输入模块识别声音。当音频输入模块识别出声音时,在步骤1020中,电子设备的音频输入模块向音频处理模块(或语音识别模块)传输驱动信号以请求激活。在步骤1011中,音频处理模块(或语音识别模块)在睡眠模式下操作,并且当从音频输入模块接收到驱动信号时,在步骤1030中,音频处理模块(或语音识别模块)被唤醒并切换到操作模式。然后,在步骤1035中,电子设备通过音频处理模块(或语音识别模块)对从音频输入模块获取的音频信号执行语音识别。当音频处理模块(或语音识别模块)成功进行了语音识别时,在步骤1040中,电子设备向主处理器传输驱动信号以请求激活。音频处理模块(或语音识别模块)可以通过关键字识别和说话人识别来识别语音触发。
当电子设备的主处理器在睡眠模式下从音频处理模块接收到驱动信号时,在步骤1050中,主处理器被唤醒并切换到操作模式。当在步骤1055中电子设备的主处理器成功进行了语音识别时,在步骤1060中,主处理器向服务器发送音频信号和/或语音信号。
主处理器通过关键字识别和说话人识别来识别语音触发,并且区分语音触发和在语音触发之后输入的语音命令。主处理器可以传输与在识别语音触发之后输入的语音命令相对应的语音信号,或者传输与语音触发和语音命令分离的时间点有关的信息。主处理器可以向服务器传输以下至少一项:从音频输入模块输入的基于外部声音的音频信号和基于语音识别提取的语音信号。然后,在步骤1065中,服务器基于从电子设备传输的音频信号和/或语音信号执行语音识别,并在步骤1070中传输关于语音识别的结果信息。
当基于来自服务器的关于语音识别的结果信息,语音识别成功,并且接收到语音命令信息时,在步骤1080中,电子设备基于语音命令执行电子设备的功能。
同时,当基于语音识别的结果,音频处理模块(或语音识别模块)进行语音识别失败时,在步骤1090中,电子设备将音频处理模块(或语音识别模块)切换到睡眠模式,并使主处理器保持在睡眠模式下。同时,当基于来自服务器的语音识别结果,电子设备接收到通知语音识别失败的失败信息时,在步骤1090中,电子设备向音频处理模块(或语音识别模块)传输语音识别失败信息,并将音频处理模块(或语音识别模块)和主处理器切换到睡眠模式。
图11是示出了根据本公开实施例的电子设备的组件之间的语音识别的流程图。
参考图11,在步骤1110中,电子设备通过音频输入模块识别声音。当电子设备的音频输入模块识别出声音时,在步骤1120中,音频输入模块向语音识别模块传输驱动信号以请求激活。在步骤1111中,语音识别模块在睡眠模式下操作,并且当从音频输入模块接收到驱动信号时,在步骤1125中,语音识别模块被唤醒并切换到操作模式。然后,在步骤1130中,电子设备的语音识别模块对从音频输入模块获取的音频信号执行语音识别。当语音识别模块成功进行了语音识别时,在步骤1135中,语音识别模块向音频处理模块传输驱动信号以请求激活。在步骤1112中,音频处理模块在睡眠模式下操作,并且当从语音识别模块接收到驱动信号时,在步骤1140中,音频处理模块被唤醒并切换到操作模式。然后,在步骤1145中,电子设备的音频处理模块执行语音识别。当音频处理模块成功进行了语音识别时,在步骤1150中,音频处理模块向主处理器传输驱动信号以请求激活。音频处理模块(或语音识别模块)通过关键字识别和说话人识别来识别由注册说话人输入的语音触发。
在步骤1113中,电子设备的主处理器在睡眠模式下操作,并且当从音频处理模块接收到驱动信号时,在步骤1155中,主处理器被唤醒并切换到操作模式。当在步骤1160中电子设备的主处理器执行语音识别并且语音识别成功时,在步骤1165中,主处理器向服务器传输音频信号和/或语音信号。主处理器通过关键字识别和说话人识别来识别由注册说话人输入的语音触发,并且区分语音触发和在语音触发之后输入的语音命令。主处理器传输与在识别语音触发之后输入的语音命令相对应的语音信号,或者传输与语音触发和语音命令分离的时间点有关的信息以及连续语音信号。此外,主处理器向服务器传输以下至少一项:从音频输入模块输入的基于外部声音的音频信号和基于语音识别提取的语音信号。
然后,在步骤1175中,服务器基于从电子设备传输的音频信号和/或语音信号执行语音识别,并在步骤1180中传输关于语音识别的结果信息。在步骤1085中,电子设备基于从服务器接收的语音命令执行功能。当从主处理器传输了连续音频信号或语音信号时,服务器区分语音触发和语音命令,并执行语音识别。当从主处理器传输了语音命令的信号时,服务器执行语音命令识别。
由服务器执行的语音命令识别可以是关键字识别、说话人识别、和命令识别中的至少一项。如上所述,电子设备可以识别有限的语音命令,而与主处理器相比,服务器可以识别更多语音命令。
同时,当基于来自服务器的语音识别结果,电子设备接收到通知语音识别失败的失败信息时,在步骤1190中,电子设备向音频处理模块或语音识别模块传输语音识别失败信息,并在图9的步骤975、图10的步骤1095以及图11的步骤1192和1191中将音频处理模块或语音识别模块和主处理器切换到睡眠模式。
电子设备的语音识别模块第一次执行语音识别。当语音识别模块的语音识别成功时,音频处理模块第二次执行语音识别。当音频处理模块的语音识别成功时,主处理器第三次执行语音识别。此外,当电子设备的主处理器成功进行语音识别时,主处理器请求服务器第四次执行语音识别。
下文中,将描述电子设备的语音识别操作中的用户界面(ui)屏幕的实施例。
图12a提供了根据本公开实施例的电子设备的语音识别操作屏幕的示例。图12b提供了根据本公开实施例的电子设备的语音识别操作屏幕的示例。
参考图12a和图12b,当主处理器从睡眠模式切换到操作模式并执行语音识别时,电子设备控制显示模块的开启/关闭操作。
如附图标记1201(图12a)所示,在音频输入模块获取音频信号并且音频处理模块(或语音识别模块)执行语音识别时,电子设备的主处理器在睡眠模式下操作并且显示模块处于关闭状态。在主处理器由来自音频处理模块(或语音识别模块)的驱动信号激活并执行语音识别时,主处理器控制显示模块保持关闭状态。
当电子设备的主处理器成功进行了语音识别时,主处理器打开显示模块并显示语音识别操作屏幕,例如由附图标记1203(图12a)所示的语音识别应用屏幕,然后,顺序执行与语音命令相对应的功能,并控制如附图标记1204(图12a)所示的功能执行屏幕的输出。
例如,当基于语音识别的结果,电子设备的主处理器成功识别了注册说话人的语音触发(例如,“higalaxy”)并且成功识别了在语音触发之后输入的语音命令(例如,“打开相机”)时,主处理器控制显示模块输出语音识别应用屏幕1203以及随后输出功能执行屏幕1204(图12a)。
备选地,当基于语音识别的结果,电子设备的主处理器成功进行了语音识别时,主处理器打开显示模块,以执行与语音命令相对应的功能,并且直接显示功能执行屏幕。
在执行语音识别时,电子设备的主处理器控制显示模块保持关闭状态,如附图标记1205(图12b)所示。当基于语音识别的结果,语音识别失败时,主处理器可以从操作模式切换到睡眠模式并保持关闭状态,如附图标记1206(图12b)所示。
图13a提供了根据本公开实施例的电子设备的语音识别操作屏幕的示例。图13b提供了根据本公开实施例的电子设备的语音识别操作屏幕的示例。
参考图13a和图13b,电子设备从音频输入模块获取音频信号。在音频处理模块(或语音识别模块)执行语音识别时,主处理器在睡眠模式下操作,使得显示模块可以处于关闭状态,如附图标记1301(图13a)所示。当主处理器由来自音频处理模块(或语音识别模块)的驱动信号激活时,主处理器打开显示模块并显示指示正在执行语音识别的语音识别操作屏幕,如附图标记1302(图13a)所示。
当语音识别成功时,主处理器执行与语音命令相对应的功能,将语音识别操作屏幕切换到功能执行屏幕,并显示所切换的功能执行屏幕,如附图标记1303(图13a)所示。
如图13b所示,在电子设备的音频处理模块(或语音识别模块)执行语音识别时,显示模块保持在关闭状态,如附图标记1304所示。
当电子设备的主处理器因语音识别功能而被激活时,主处理器可以打开显示模块,并且在执行语音识别时,显示指示正在执行语音识别的语音识别操作屏幕,如附图标记1305所示。当在语音识别期间显示语音识别操作屏幕时基于语音识别的结果,语音识别失败时,主处理器关闭显示模块,并从操作模式切换到睡眠模式,如附图标记1306所示。
还可以提供其中存储有命令的存储介质。所述命令被配置为当由一个或多个处理器执行时允许所述一个或多个处理器执行一个或多个操作。所述一个或多个操作包括:由音频输入模块识别声音并请求激活语音识别模块;当语音识别模块响应于来自音频输入模块的激活请求而被激活时,对从音频输入模块传输的音频信号执行第一语音识别;当由语音识别模块执行的第一语音识别成功时,向处理器请求语音识别;以及由处理器对从语音识别模块传输的音频信号执行第二语音识别。
根据本公开,当语音识别第一次通过具有小电流消耗的低性能模块执行并且第一次语音识别成功时,通过具有相对较高识别率的高性能模块第二次执行语音识别,使得通过电子设备的组件的分阶段激活可以提高语音识别的识别率并且还可以改善电流消耗。
尽管已经参考本公开的特定实施例示出并描述了本公开,但是本领域技术人员将理解,在不脱离由所附权利要求及其等同物限定的本发明的精神和范围的前提下,可以在其中进行形式和细节上的各种改变。
- 还没有人留言评论。精彩留言会获得点赞!