一种语音识别控制系统及其识别控制方法与流程
本发明属于嵌入式的语音识别控制技术领域,具体是涉及一种语音识别控制系统及其识别控制方法。
背景技术:
语音识别控制技术应用广泛,尤其是在机器人控制领域,目前的语音识别控制的方法一般是首先录音过程采用windows自带的api函数,通过录音程序获取需要识别的音频文件;然后将音频文件输入到讯飞语音识别函数接口中进行处理,输出与音频相对应的文本;再用zigbee根据识别文本中的关键词来控制。该技术存在以下问题:1、该技术是基于windows操作系统上的,windows操作系统对硬件要求很大,不作为嵌入式系统,无法嵌入到小型机器比如路由器等,因此适应性差,不能广泛使用;2、该项技术对识别文本关键词存在缺陷,误识别的概率比较大。
技术实现要素:
本发明针对现有技术的不足,提供一种语音识别控制系统及其识别控制方法;该系统和方法不但大大的减少了误识别的概率,而且适应性强,可以广泛嵌入生活中的小型机器里面。
为了达到上述目的,本发明一种语音识别控制系统,主要包括用于拾取外来声音并将该声音的模拟信号合成处理成数字信号的拾音器,作为主机处理来自拾音器声音数字信号的exynos4412开发板,用于将声音数字信号进行分析匹配并把结果转化为json文本格式的讯飞语音云端,以及作为控制处理器处理来自exynos4412开发板的信息并执行处理该信息后相应任务的stm32单片机;所述拾音器、exynos4412开发板以及stm32单片机依次通信连接,而讯飞语音云端则基于exynos4412开发板作为主机平台分别与拾音器、stm32单片机通信连接;所述操作系统为linuxqt操作系统,exynos4412开发板则作为该操作系统的平台。
优选地,所述拾音器将声音的模拟信号传递到麦克风阵列模块xfm10412的dsp中合成处理成数字信号。
优选地,所述拾音器为由四个线性麦克风,底板滤波电路、接口电路,以及麦克风阵列模块组成。该麦克风阵列模块为科大讯飞的麦克风阵列模块xfm10412。
优选地,所述exynos4412开发板将来自讯飞语音云端的json文本格式的匹配结果进行分析并提取转化成关键字,然后以gb2312码的格式将信息用串口通信方式传入到stm32单片机,之后stm32单片机将以gb2312码的格式进行任务匹配并执行匹配后的相应任务,从而完成语音识别控制的功能。
一种语音识别控制系统的识别控制方法,主要包括以下步骤:
首先,拾音器拾取外来声音并将该声音的模拟信号合成处理成数字信号后通过串口通信传入到exynos4412开发板;此时的拾音器作为从机,exynos4412开发板则作为主机;
其次,exynos4412开发板基于讯飞开发的语音识别应用程序在linuxqt操作系统上执行,从拾音器传来的信息发送到讯飞语音云端上经过处理后的结果以json文本格式返回到操作系统上;
第三,exynos4412开发板将来自讯飞语音云端的json文本格式的匹配结果进行分析并提取转化成关键字,然后以gb2312码的格式将信息用串口通信方式传入到stm32单片机;此时的stm32单片机作为从机,exynos4412开发板则作为主机;
最后,stm32单片机将以gb2312码的格式进行任务匹配,之后再执行匹配后的相应任务,从而完成语音识别控制的功能。
优选地,所述拾音器为由四个线性麦克风,底板滤波电路、接口电路,以及麦克风阵列模块组成。该麦克风阵列模块为科大讯飞的麦克风阵列模块xfm10412。
与现有技术相比,本发明主要有以下优点:1、以linuxqt作为操作系统平台,linuxqt操作系统对硬件要求低,所以适应性好,应用范围广;2、结合讯飞语音成熟的技术在系统本身多次过滤信息可以大大降低误识别率;3、以json文本关键字转化成gb2312码,并在stm32单片机以gb2312码匹配相应任务来完成控制,用此方法可以更精确的执行任务。
附图说明
图1为本发明语音识别控制系统的组成框图;
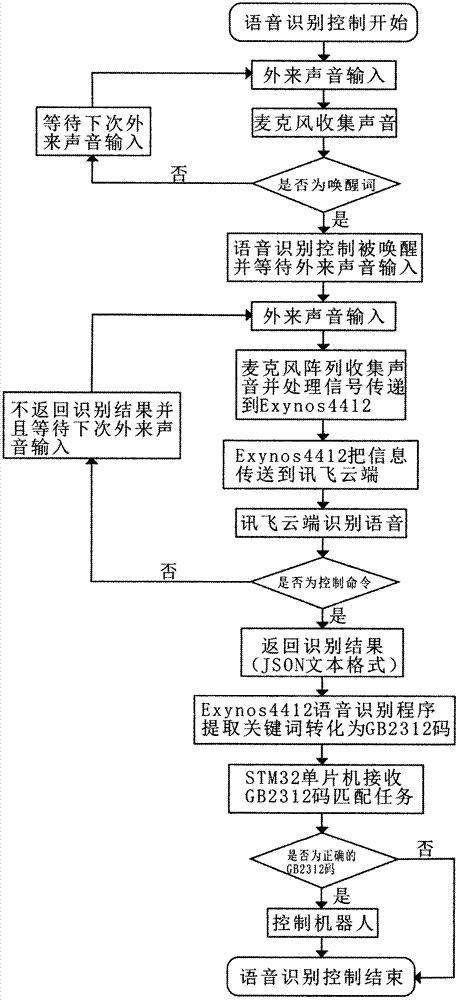
图2为本发明语音识别控制系统的算法流程图。
其中,1为拾音器,2为exynos4412开发板,3为讯飞语音云端,4为stm32单片机。
具体实施方式
以下结合附图和具体实施例对本发明进行详细描述,但不作为对本发明的限定。
参照图1和图2,本发明实施例一种语音识别控制系统,主要包括用于拾取外来声音并将该声音的模拟信号合成处理成数字信号的拾音器1,作为主机处理来自拾音器1声音数字信号的exynos4412开发板2,用于将声音数字信号进行分析匹配并把结果转化为json文本格式以返回到操作系统上的讯飞语音云端3,以及作为控制处理器处理来自exynos4412开发板2的信息并执行处理该信息后相应任务的stm32单片机4;所述拾音器1、exynos4412开发板2以及stm32单片机4依次通信连接,而讯飞语音云端3则基于exynos4412开发板2作为主机平台分别与拾音器1、stm32单片机3通信连接;所述操作系统为linuxqt操作系统,exynos4412开发板2则作为该操作系统的平台。
所述拾音器1将声音的模拟信号传递到模块的dsp中合成处理成数字信号,所述拾音器1为由四个线性麦克风,底板滤波电路、接口电路,以及科大讯飞的麦克风阵列模块xfm10412组成。所述exynos4412开发板2将来自讯飞语音云端3的json文本格式的匹配结果进行分析并提取转化成关键字,然后以gb2312码的格式将信息用串口通信方式传入到stm32单片机4,之后stm32单片机4将以gb2312码的格式进行任务匹配并执行匹配后的相应任务,从而完成语音识别控制的功能。
参照图1和图2,一种语音识别控制系统的识别控制方法,主要包括以下步骤:
首先,拾音器1拾取外来声音并将该声音的模拟信号合成处理成数字信号后通过串口通信传入到exynos4412开发板2;此时的拾音器1作为从机,exynos4412开发板2则作为主机;
所述拾音器1为由四个线性麦克风,底板滤波电路、接口电路,以及科大讯飞的麦克风阵列模块xfm10412组成。该拾音器1将声音的模拟信号传递到模块的dsp中合成处理成数字信号。
其次,exynos4412开发板2基于讯飞开发的语音识别应用程序在linuxqt操作系统上执行,从拾音器1传来的信息发送到讯飞语音云端3上经过处理后的结果以json文本格式返回到操作系统上;
第三,exynos4412开发板2将来自讯飞语音云端3的json文本格式的匹配结果进行分析并提取转化成关键字,然后以gb2312码的格式将信息用串口通信方式传入到stm32单片机4;此时的stm32单片机4作为从机,exynos4412开发板2则作为主机;
最后,stm32单片机4将以gb2312码的格式进行任务匹配,之后再执行匹配后的相应任务,从而完成语音识别控制的功能。
本发明中的软件设计分为讯飞语音识别应用程序的设计、stm32单片机的控制程序设计、linuxqt操作系统移植和驱动移植开发设计。其中讯飞语音识别应用程序设计是利用讯飞本身的接口函数进行开发,修改添加代码适合自己的要求,本项设计是把最原始语音识别全部文本结果以json格式提取出关键字,将原始语音识别可能带来的误识别结果进行多次过滤,大大降低误识别的机率,再加上讯飞云端计算的高正确率识别,总体语音识别的正确率可以做到99%。stm32单片机控制程序设计是编写串口通信功能代码和控制电机的代码。其中,这是通过gb2312码进行任务匹配后再控制相应电机做出相应动作;linuxqt操作系统移植和驱动移植开发设计是在exynos4412开发板移植linuxqt操作系统,由于移植完的系统缺乏wifi驱动和声卡驱动,需要根据wifi芯片进行驱动开发,声卡驱动进行库移植等。
与现有技术相比,本发明主要有以下优点:1、以linuxqt作为操作系统平台,linuxqt操作系统对硬件要求低,所以适应性好,应用范围广;2、结合讯飞语音成熟的技术再系统本身多次过滤信息可以大大降低误识别率;3、以json文本关键字转化成gb2312码,并在stm32单片机以gb2312码匹配相应任务来完成控制,用此方法可以更精确的执行任务。
以上已将本发明做一详细说明,但显而易见,本领域的技术人员可以进行各种改变和改进,而不背离所附权利要求书所限定的本发明的范围。
- 还没有人留言评论。精彩留言会获得点赞!