一种基于多尺度深度卷积循环神经网络的语音情感识别方法与流程
本发明涉及语音信号处理、模式识别领域,特别是涉及一种基于多尺度深度卷积循环神经网络的语音情感识别方法。
背景技术:
人类的语言不仅包含了丰富的文本信息,同时也携带着包含人们情绪表达的音频信息,如语音的高低、强弱、抑扬顿挫等变化。如何让计算机从语音信号中自动识别出说话人的情感状态,即所谓的“语音情感识别”方面的研究,已成为人工智能、模式识别、情感计算等领域中的一个热点研究课题。该研究旨在让计算机通过分析说话人的语音信号对用户的情感信息进行获取、识别和响应,从而实现用户与计算机之间的交互更加和谐与自然。该研究在智能人机交互、电话客服中心、机器人技术等方面具有重要的应用价值。
目前,在语音情感识别领域,大量的前期工作主要是针对模拟情感而进行的,因为这种模拟情感数据库的建立相对自然情感而言,要容易得多。近年来,针对实际环境下的自然语音情感识别方面的研究备受研究者的关注,因为它更接近实际,而且比模拟情感的识别要困难得多。
语音情感特征提取,是语音情感识别中的一个关键步骤,其目的是从情感语音信号中提取能够反映说话人情感表达信息的特征参数。目前,大量语音情感识别文献采用了手工设计的特征用于情感识别,如韵律特征(基频、振幅、发音持续时间)、音质特征(共振峰、频谱能量分布、谐波噪声比),谱特征(梅尔频率倒谱系数(mfcc))等(见文献:anagnostopouloscn,etal.featuresandclassifiersforemotionrecognitionfromspeech:asurveyfrom2000to2011.artificialintelligencereview,2015,43(2):155-177.)。然而,这些手工设计的语音情感特征参数属于低层次的特征,与人类理解的情感标签还存在“语义鸿沟”问题,因此有必要发展高层次的语音情感特征提取方法。
为了解决这个问题,近年来新出现的深度学习技术可能提供了线索。一些代表性的深度学习方法主要包括:深度信念网络(dbn)、深度卷积神经网络(cnn)与长短时记忆网络(lstm)。其中,lstm是一种改进的循环神经网络(rnn),用于解决传统rnn存在的梯度消失问题。但是,现有基于深度学习技术的语音情感识别方法,都忽略了不同长度的语音频谱片段信息对不同情感类型识别的判别力不同的特性(见文献:maoq,etal.learningsalientfeaturesforspeechemotionrecognitionusingconvolutionalneuralnetworks.ieeetransactionsonmultimedia,2014,16(8):2203-2213.)。针对此问题,本发明将深度卷积神经网络(cnn)与长短时记忆网络(lstm)相结合,并同时考虑不同长度的语音频谱片段信息对不同情感类型识别的判别力不同的特性,从而提出一种多尺度cnn+lstm的混合深度学习模型,并应用于实际环境下的自然语音情感识别。
技术实现要素:
本发明的目的就是为了克服上述现有语音情感识别技术的不足,提供一种基于多尺度深度卷积循环神经网络的语音情感识别方法,用于实现实际环境下的自然语音情感识别任务。
本发明所采用的技术方案是:
一种基于多尺度深度卷积循环神经网络的语音情感识别方法,其主要技术步骤为:
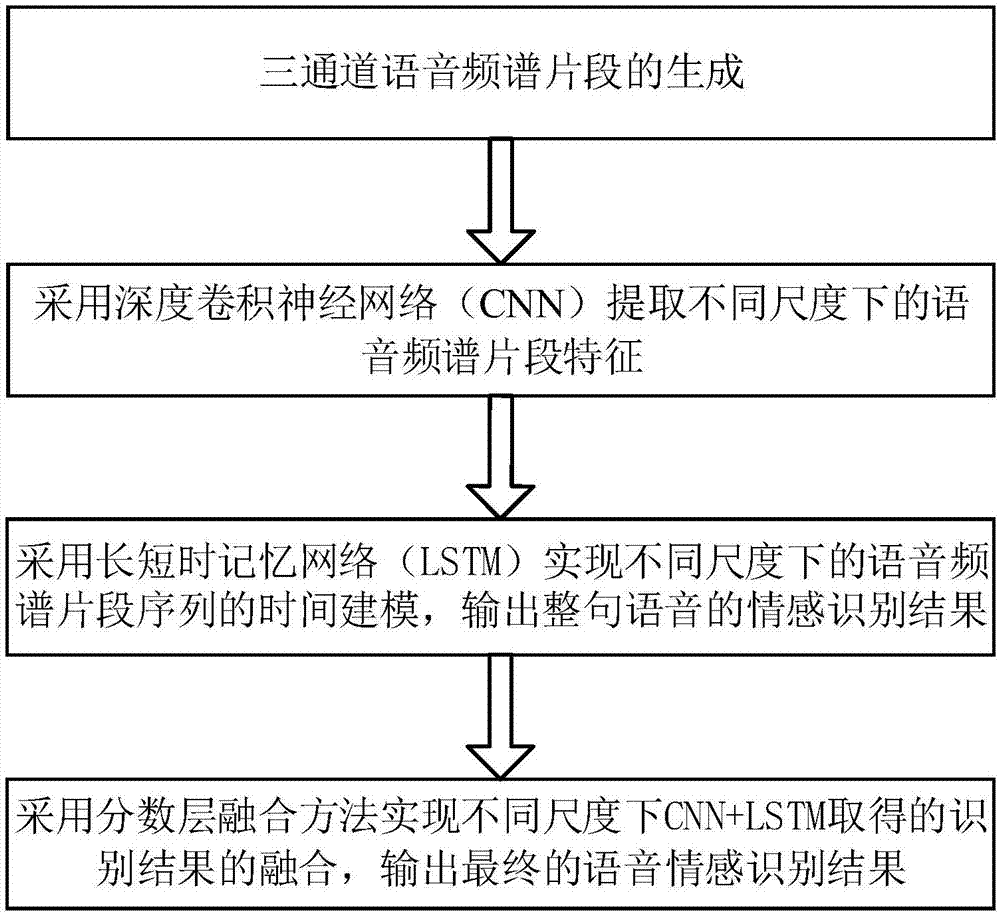
步骤1:三通道语音频谱片段的生成;
步骤2:采用深度卷积神经网络(cnn)提取不同尺度下的语音频谱片段特征;
步骤3:采用长短时记忆网络(lstm)实现不同尺度下的语音频谱片段序列的时间建模,输出整句语音的情感识别结果;
步骤4:采用分数层融合方法实现不同尺度下cnn+lstm取得的识别结果的融合,输出最终的语音情感识别结果。
其中,
(1)三通道语音频谱片段的生成,包括:
从原始的一维情感语音信号,拟提取的三通道mel语音频谱片段特征,可形式化表述为:
mel_ss=f×t×c(式1)
式中,f表示mel滤波器个数,t表示频谱片段长度,等于加窗处理所采用的文本窗(contextwindow)大小(即语音帧数),c表示频谱的通道数(c=1,2,3)。考虑到计算机视觉领域中的图像的高宽比关系,拟采用mel_ss=64×64×3(f=64,t=64,c=3)作为举例说明,如何实现这种三通道mel频谱片段特征的提取。
为此,我们先采用64个mel滤波器和64帧的文本窗大小,计算出二维的静态(static)频谱片段64×64(相当于一个通道c=1),然后采用公式(2)对其在时间轴上进行第一次求导,以便抓住该静态频谱片段的时间动态特性。这样的求导操作完全类似于常用的语音特征mfcc的一阶和二阶求导,其目的是用来提取特征的时间动态特性信息。
式中,dt表示为采用静态频谱片段系数ct-n至ct+n对其第t帧进行求导之后的系数,n为回归窗(regressionwindow)的大小,一般取值在[2,9]。
同样,利用上述公式对第一次求导之后的系数dt再进行第二次求导,就可以得到反映dt的时间动态特性方面的系数。最后,将语音信号的静态的频谱片段特征、以及它的第一次求导系数和第二次求导系数作为rgb图像的三个通道,然后将它们组合就得到了类似于rgb图像的三通道mel频谱片段特征mel_ss=64×64×3。对于不同尺度的语音频谱片段的获取,只需改变t值就可以得到,即mel_ss=64×t×3。
(2)采用深度卷积神经网络(cnn)提取不同尺度下的语音频谱片段特征,包括:
考虑到情感语音数据库的样本一般都比较有限,拟采用预训练好的深度学习模型,如alexnet模型(见文献:krizhevskya,etal.imagenetclassificationwithdeepconvolutionalneuralnetworks.nips25,2012,1106-1114.)在目标情感语音数据集上进行微调(fine-tuning)。
当微调alexnet时,需要复制alexnet的网络参数进行初始化,然后将其最后一个全连接层(fc8)的神经元数量修改为目标情感语音数据集的情感类别数目,再次训练一次。由于alexnet模型的固定输入大小为227×227×3,因此需要对产生的三通道mel频谱片段mel_ss进行采样处理。对于不同尺度的语音频谱片段mel_ss=64×t×3,都采用双线性内插(bilinearinterpolation)方法将mel_ss采样到227×227×3。
(3)采用长短时记忆网络(lstm)实现不同尺度下的语音频谱片段序列的时间建模,输出整句语音的情感识别结果,包括:
给定一个时间长度为t的输入序列(x1,x2,…xt),lstm旨在通过计算网络节点激活函数的输出,将输入序列(x1,x2,…xt)映射到一个输出序列(y1,y2,…yt),如下所示:
it=σ(wxixt+whiht-1+wcict-1+bi)(式3)
ft=σ(wxfxt+whfht-1+wcfct-1+bf)(式4)
ct=ftct-1+ittanh(wxcxt+whcht-1+bc)(式5)
σt=σ(wxoxt+whoht-1+wcoct-1+bo)(式6)
ht=σttanh(ct)(式7)
式中,it、ft、ct、σt分别是lstm模型中的输入门、忘记门、细胞存储单元和输出门的激活输出向量。xt和ht分别表示第t个时间步长的输入向量和隐层向量。wαβ表示α和β之间的权重矩阵。例如,wxi是从输入xt到输入门it的权重矩阵。bα是α的偏置值,σ表示sigmoid激活函数σ(x)=1/(1+e-x)。当获得lstm的输出序列(y1,y2,…yt),就可以采用softmax分类器来预测整句语音的情感类别。
(4)采用分数层融合方法实现不同尺度下cnn+lstm取得的识别结果的融合,输出最终的语音情感识别结果,包括:
为了融合不同尺度下cnn+lstm取得的识别结果,采用分数层融合方法(score-levelfusion)进行融合,计算公式如下所示:
scorefusion=r1score1+r2score2+…+rmscorem(式8)
式中,rj和scorej分别表示第j个(j=1,2,…,m)权重值,以及cnn+lstm在第j个尺度下所获得的相应的情感分类的得分值(scorevalue)。
与现有技术相比,本发明的优点和效果在于:
1.为了充分利用不同长度的语音频谱片段信息对不同情感类型识别的判别力不同的特性,提出一种基于多尺度cnn+lstm的混合深度学习模型,并成功应用于自然语音情感识别。
2.考虑到情感语音数据库的样本一般都比较有限的特点,采用已创建的类似于rgb图像的三通道mel频谱片段作为cnn的输入,从而可以采用预训练好的深度学习图像模型在目标情感语音数据集上进行微调。这种从图像到语音的跨媒体迁移学习策略在一定程度上缓解了语音情感数据集样本不足的问题。
本发明的其他优点将在下面继续描述。
附图说明
图1——本发明流程图
图2——不同的单一长度的语音频谱片段作为cnn+lstm输入的性能比较
图3——融合5种不同尺度cnn+lstm取得的识别结果的性能以及相应的最优的融合权重值参数
图4——本发明方法取得40.73%的识别性能时的各种情感类型的正确识别率(%)
具体实施方式
下面结合附图和实施例,对本发明所述的技术方案进一步说明。
图1为本发明流程图,主要包括:
步骤1:三通道语音频谱片段的生成;
步骤2:采用深度卷积神经网络(cnn)提取不同尺度下的语音频谱片段特征;
步骤3:采用长短时记忆网络(lstm)实现不同尺度下的语音频谱片段序列的时间建模,输出整句语音的情感识别结果;
步骤4:采用分数层融合方法实现不同尺度下cnn+lstm取得的识别结果的融合,输出最终的语音情感识别结果。
一、本发明流程图每一个步骤的实现,结合实施例具体表述如下:
(1)三通道语音频谱片段的生成,包括:
从自然情感语音数据集afew5.0(见文献:dhalla,etal.videoandimagebasedemotionrecognitionchallengesinthewild:emotiw2015.acmoninternationalconferenceonmultimodalinteraction,seattle,2015,423-426.)提取生气(anger)、厌恶(disgust)、恐惧(fear)、高兴(joy)、悲伤(sad)、惊奇(surprise)和中性(neutral)共7种情感类别的样本。其中,训练集含有723个样本,验证集含有383个样本。
针对拟从原始的一维情感语音信号,采用帧移为10ms,时长为25ms的汉明窗提取出整句语音信号的一维对数mel频谱,然后将其分段,并转换成类似于rgb彩色图像的三通道(red,green,black)mel频谱片段,作为后续的深度卷积神经网络(cnn)的输入。
从原始的一维情感语音信号,拟提取的三通道mel语音频谱片段特征,可形式化表述为:
mel_ss=f×t×c(式1)
式中,f表示mel滤波器个数,t表示频谱片段长度,等于加窗处理所采用的文本窗(contextwindow)大小(即语音帧数),c表示频谱的通道数(c=1,2,3)。考虑到计算机视觉领域中的图像的高宽比关系,拟采用mel_ss=64×64×3(f=64,t=64,c=3)作为举例说明,如何实现这种三通道mel频谱片段特征的提取。
为此,我们先采用64个mel滤波器和64帧的文本窗大小,计算出二维的静态(static)频谱片段64×64(相当于一个通道c=1),然后采用公式(2)对其在时间轴上进行第一次求导,以便抓住该静态频谱片段的时间动态特性。这样的求导操作完全类似于常用的语音特征mfcc的一阶和二阶求导,其目的是用来提取特征的时间动态特性信息。
式中,dt表示为采用静态频谱片段系数ct-n至ct+n对其第t帧进行求导之后的系数,n为回归窗(regressionwindow)的大小,一般取值在[2,9]。
同样,利用上述公式对第一次求导之后的系数dt再进行第二次求导,就可以得到反映dt的时间动态特性方面的系数。最后,将语音信号的静态的频谱片段特征、以及它的第一次求导系数和第二次求导系数作为rgb图像的三个通道,然后将它们组合就得到了类似于rgb图像的三通道mel频谱片段特征mel_ss=64×64×3。对于不同尺度的语音频谱片段的获取,只需改变t值就可以得到,即mel_ss=64×t×3。
(2)采用深度卷积神经网络(cnn)提取不同尺度下的语音频谱片段特征,包括:
考虑到情感语音数据库的样本一般都比较有限,拟采用预训练好的深度学习模型,如alexnet模型(见文献:krizhevskya,etal.imagenetclassificationwithdeepconvolutionalneuralnetworks.nips25,2012,1106-1114.)在目标情感语音数据集上进行微调(fine-tuning)。alexnet模型包含5个卷积层(conv1-conv2-conv3-conv4-conv5)、3个池化层(pool1-pool2-pool5)和3个全连接层(fc)层组成。前两个全连接层(fc6,fc7)包含4096个神经元,最后一个全连接层(fc8)包含1000个神经元,用于实现imagenet数据集中的1000种图像的分类。其中,fc7所输出的4096-d特征表示alexnet模型所学习到的高层次的属性特征,用于后续的情感识别。
当微调alexnet时,需要复制alexnet的网络参数进行初始化,然后将其最后一个全连接层(fc8)的神经元数量修改为目标情感语音数据集的情感类别数目,再次训练一次。由于alexnet模型的固定输入大小为227×227×3,因此需要对产生的三通道mel频谱片段mel_ss进行采样处理。对于不同尺度的语音频谱片段mel_ss=64×t×3,都采用双线性内插(bilinearinterpolation)方法将mel_ss采样到227×227×3。
(3)采用长短时记忆网络(lstm)实现不同尺度下的语音频谱片段序列的时间建模,输出整句语音的情感识别结果,包括:
给定一个时间长度为t的输入序列(x1,x2,…xt),lstm旨在通过计算网络节点激活函数的输出,将输入序列(x1,x2,…xt)映射到一个输出序列(y1,y2,…yt),如下所示:
it=σ(wxixt+whiht-1+wcict-1+bi)(式3)
ft=σ(wxfxt+whfht-1+wcfct-1+bf)(式4)
ct=ftct-1+ittanh(wxcxt+whcht-1+bc)(式5)
σt=σ(wxoxt+whoht-1+wcoct-1+bo)(式6)
ht=σttanh(ct)(式7)
式中,it、ft、ct、σt分别是lstm模型中的输入门、忘记门、细胞存储单元和输出门的激活输出向量。xt和ht分别表示第t个时间步长的输入向量和隐层向量。wαβ表示α和β之间的权重矩阵。例如,wxi是从输入xt到输入门it的权重矩阵。bα是α的偏置值,σ表示sigmoid激活函数σ(x)=1/(1+e-x)。当获得lstm的输出序列(y1,y2,…yt),就可以采用softmax分类器来预测整句语音的情感类别。本发明采用2层的结构lstm(4096-256-256-7)表现最好。
(4)采用分数层融合方法实现不同尺度下cnn+lstm取得的识别结果的融合,输出最终的语音情感识别结果,包括:
为了融合不同尺度下cnn+lstm取得的识别结果,采用分数层融合方法(score-levelfusion)进行融合,计算公式如下所示:
scorefusion=r1score1+r2score2+…+rmscorem(式8)
式中,rj和scorej分别表示第j个(j=1,2,…,m)权重值,以及cnn+lstm在第j个尺度下所获得的相应的情感分类的得分值(scorevalue)。权重值r的确定,采用在[0,1]范围内以步长为0.1进行搜索而找到的最优值。
二、识别系统的评价
为了验证不同长度的语音频谱片段作为cnn+lstm输入的影响,测试了五种不同长度的语音频谱片段64×t×3(t=20,40,64,80,100)的性能。这些频谱片段的间隔约为20帧,其时间长度为215ms。这个时间长度达到了所要求的能够表达足够情感信息的最短语音长度,从而保证分段得到的语音频谱片段具有区分情感的差异性。对于不同长度的语音频谱片段,都采用双线性内插方法采样到cnn的固定输入大小227×227×3。图2列出了不同的单一长度的语音频谱片段作为cnn+lstm输入的性能比较。从图2可以看出,cnn+lstm的性能随着语音频谱片段长度t的增大而提高,在t=80时表现最好,其取得的正确识别率达到了35.51%。尽管如此,但cnn+lstm的性能在t=100时下降。这表明增大t值,并不能持续提升cnn+lstm的性能。
图3给出了融合5种不同尺度cnn+lstm取得的识别结果的性能以及相应的最优的融合权重值参数。从图2和图3来看,与单一尺度(t=80)cnn+lstm获得的最好性能(35.51%)相比,融合多尺度cnn+lstm的结果导致语音情感识别性能提升了5.22%(从35.51%至40.73%)。这表明融合多尺度cnn+lstm的有效性。主要原因是,不同长度的语音频谱片段作为cnn+lstm输入,在识别不同情感类型时会产生不同的作用。图4给出了本发明方法取得40.73%的识别性能时的各种情感类型的正确识别率。其中,图4中对角线粗体数据表示每一种具体的情感类型所获得的正确识别率。
- 还没有人留言评论。精彩留言会获得点赞!