一种用于VR展示教学的语音识别控制设备及控制方法与流程
本发明涉及vr教学设备领域,具体涉及一种用于vr展示教学的语音识别控制设备及控制方法。
背景技术
vr教学可以应用在虚拟仿真校园、虚拟教学科研、虚拟实验等方面。vr教学是可实现集教学、体验、实践于一体的立体化教学,改革传统教学模式,创新教学方法,达到培养创新型、实用型人才的目的。vr教学随着3d虚拟现实技术、三维建模、数据库技术等技术手段的不断成熟而成熟,vr教学在教育上应用日益广泛,但是传统的vr设备只能使用手柄以及内部的姿态加速度传感器进行控制,操作不便。
在专利号为cn107341981a的专利中公开了一种基于vr技术的学生教学互动平台控制方法,其包括如下步骤:s1、在服务器中建立学生以及教师形体三维模型;采集学生、教师的声音素材,根据学生、教师的声音素材建立学生、教师的语音数据库,语音数据中存储学生、教师的声音特征数据;s2、根据教学内容在服务器中建立不同的教学场景模型;所述教学场景模型包括环境模型、道具模型;53、服务器接收第一终端的教学请求,第一终端为教师侧的终端;服务器根据第一终端的教学请求选择需要连接的第二终端,第二终端为学生侧的终端;服务器在选择后建立与第二终端的连接;s4、服务器根据第一终端以及选择的第二终端从服务器中匹配相对应的学生以及教师形体三维模型以及教师、学生的声音特征数据;s5、第一终端向服务器发送教学信息;服务器根据教学信息判断需要的教学场景模型,并从服务器中匹配、选择相对应的教学场景模型;根据选择的教学场景模型、学生以及教师形体三维模型以及教师、学生的声音特征数据建立临时教学综合场景;s6、服务器接收教师、学生的语音信息、肢体动作信息;将教师的语音信息按照服务器中的教师的声音特征数据进行优化;将教师、学生的肢体动作信息、学生的语音信息、经过优化的教师的语音信息投射到临时教学综合场景中。但是上述方案使用vr机体的自带控制器进行控制,控制使用不便。
在专利号为cn107300970a的专利中公开了一种虚拟现实交互方法,其特征在于,包括以下步骤:获取vr资源;所述vr资源包括多个vr场景和多个交互环节;在对所述vr资源的vr场景进行展示的过程中,采集用户的控制语音;根据采集到的控制语音,对所述vr场景的展示过程进行控制;当展示到交互环节时,根据所述交互环节中采集到的用户的交互语音,确定所需展示的下一个vr场景,在当前所展示的vr场景中展示所述交互语音的反馈信息。但是上述方式无法对背景噪音以及vr设备本身声音进行过滤,容易导致误操作。
技术实现要素:
本发明的目的在于克服现有技术中存在的上述问题,提供一种用于vr展示教学的语音识别控制设备及控制方法,能够解析用户的语音指令用于控制vr设备,方便在教学过程中能够使用。
为实现上述技术目的,达到上述技术效果,本发明是通过以下技术方案实现:
一种用于vr展示教学的语音识别控制设备,包括机体,其特征在于:机体两侧固定有悬臂,悬臂外侧设置有降噪采集麦,悬臂内测设置有耳机,悬臂的末端通过弹性带连接,弹性带中部设置有连接扣,悬臂设置有转轴,转轴通过摆杆连接麦克风,用户将设备戴在头上,扣上连接扣,旋转摆杆,调整麦克风至合适的位置,调整过程中,转轴内的转盘在转动槽内转动,盲孔与转动槽内壁的弹性片卡接,起到相对固定的作用,在转盘转动过程,既是调整麦克风的位置;
所述转轴包括在悬臂侧壁转动槽内安置的转盘,转盘顶部和底部设置有与转动槽滑动摩擦的弧形块,转盘左右两侧设置有系列盲孔,盲孔与转动槽内壁左右固定的弹性片卡接,转盘固定有摆杆。
进一步地,所述摆杆包括套筒以及与套筒末端活动插接的伸缩杆,伸缩杆顶部的插接端固定有阻尼器,阻尼器侧壁开设的盲槽内设置有活动的橡胶块,盲槽内的弹性件压迫橡胶块与套筒内壁产生摩擦,套筒底部开口端内壁固定有限位块。
进一步地,所述盲孔纵向剖面为半球形,所述弹性片纵向剖面为半橄榄形。
一种用于vr展示教学的语音识别控制方法,其特征在于:包括以下步骤,
-步骤s1:通过降噪采集麦和麦克风分别采集降噪麦采集h(x)和麦克风采集g(x);
-步骤s2:结合预设静音室对比数据得出人声o(x);
-步骤s3:通过人声o(x)中的语音信息组合出语音指令;
-步骤s4:语音指令控制机体。
进一步地,一种用于vr展示教学的语音识别控制方法,其特征在于:所述步骤s2中,分为以下步骤,
-步骤s2.1:
设耳机输出声波为f(x),背景噪声为w(x),则
h(x)=w(x)+m1o(x)+k1f(x)公式1,
g(x)=w(x)+m2o(x)+k2f(x)公式2,
其中,m1为人声至降噪麦的传导系数,m1为人声至麦克风的传导系数,k1为耳机至降噪麦的传导系数,k2为耳机麦克风的传导系数;
-步骤s2.2:
在出厂静音室测试阶段,播放耳机,排除背景噪音w(x)以及人声o(x)的干扰,上述公式1和公式2变形为:
h(x)=k1f(x)公式3,
g(x)=k2f(x)公式4,
由于转轴多级可调整,针对每个转轴旋转状态,测试每个状态的k1、k2数值,
-步骤s2.3:
在出厂静音室测试阶段,测试人员戴上设备说话,关闭耳机,排除背景噪音w(x)以及耳机声音f(x)的干扰,上述公式1和公式2变形为:
h(x)=m1o(x)公式5,
g(x)=m2o(x)公式6,
由于转轴多级可调整,针对每个转轴旋转状态,测试每个状态的m1、m2数值,
-步骤s2.4:
代入公式1与公式2,之后公式2减去公式1,得到:
g(x)-h(x)=(m2-m1)o(x)+(k2-k1)f(x)公式7,
求解得出人声
将预设的m1、m2、k1、k2按预设顺序依此代入进行求解。
进一步地,所述步骤s3中,包括以下步骤,
-步骤s3.1:
在联网状态下,机体将人声语音o(x)实时上传至云识别平台进行语音指令识别,再将之后的语音指令下载,
-步骤s3.2:
当无法联网或者网络延迟过高,则将人声o(x)在本地处理。
进一步地,所述步骤s3.2包括以下步骤,
-步骤s3.2.1:
将人声o(x)建立响度db-时间t模型,
-步骤s3.2.2:
将响度db-时间t模型中响度db中人声o(x)求导得出d(x),
-步骤s3.2.3:
其中单个字的发声区间导数连贯,而单字之间则不连贯,由此将人声o(x)分切为单字发声,
-步骤s3.2.4:
将分切后的单字发声与语音数据库进行比对,转化为单个汉字,若转化失败,则跳转步骤s2.4重新求解,再合成为语音指令。
本发明的收益效果是:
1、方便调整麦克风位置,用户将设备戴在头上,扣上连接扣,旋转摆杆,调整麦克风至合适的位置,调整过程中,转轴内的转盘在转动槽内转动,盲孔与转动槽内壁的弹性片卡接,起到相对固定的作用,在转盘转动过程,既是调整麦克风的位置。
2、能够解析用户的语音指令用于控制vr设备,方便在教学过程中能够使用,包括以下步骤,通过降噪采集麦和麦克风分别采集降噪麦采集h(x)和麦克风采集g(x);结合预设静音室对比数据得出人声o(x);通过人声o(x)中的语音信息组合出语音指令;语音指令控制机体;本发明实施中,能够解析用户的语音指令用于控制vr设备,方便在教学过程中能够使用。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明所述用于vr展示教学的语音识别控制设备的结构立体示图;
图2为本发明所述用于vr展示教学的语音识别控制设备的右视图;
图3为本发明所述转轴的结构示意图;
图4为本发明所述摆杆的结构示意图;
图5为本发明所述摆杆的a处放大结构示意图;
图6为本发明所述语音识别控制设备各处音源的示意图;
图7为本发明所述用于vr展示教学的语音识别控制方法的步骤示意图;
图8为本发明所述步骤s3.2中切分单字语音的波形示意图;
图9为本发明所述步骤s3.2中切割单字之后的语音波形示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
如图1-9所示,本发明为为:
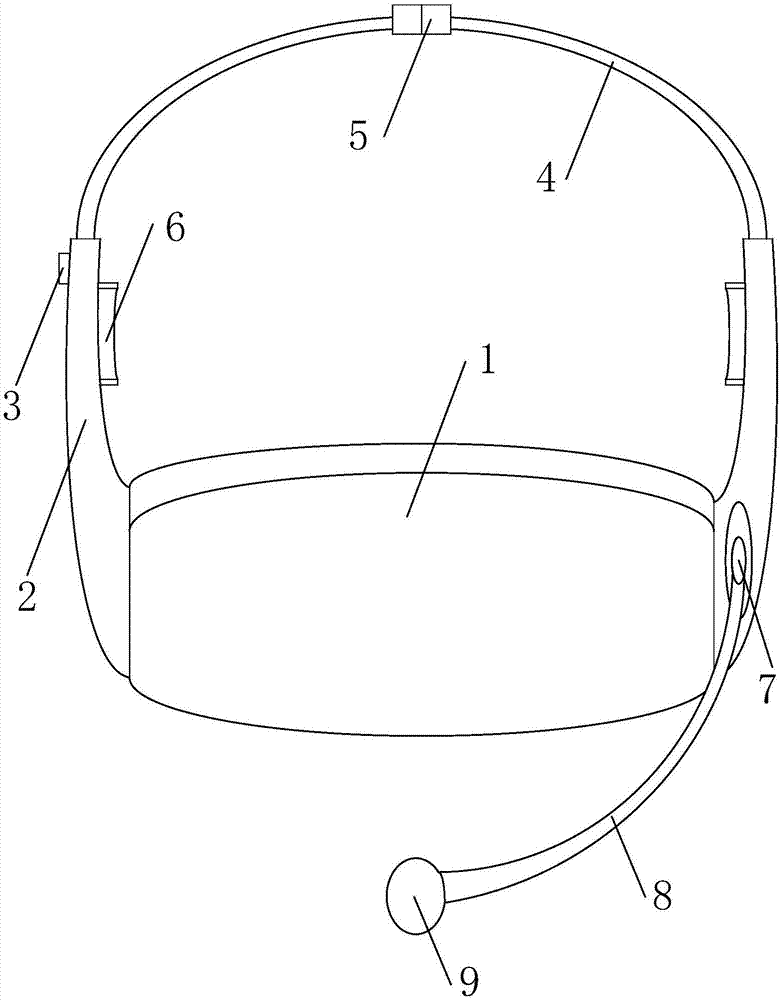
一种用于vr展示教学的语音识别控制设备,包括机体1,机体1两侧固定有悬臂2,悬臂2外侧设置有降噪采集麦3,悬臂2内测设置有耳机6,悬臂2的末端通过弹性带4连接,弹性带4中部设置有连接扣5,悬臂2设置有转轴7,转轴7通过摆杆8连接麦克风9风;
所述转轴包括在悬臂侧壁转动槽内安置的转盘,转盘顶部和底部设置有与转动槽滑动摩擦的弧形块,转盘左右两侧设置有系列盲孔,盲孔与转动槽内壁左右固定的弹性片卡接,转盘固定有摆杆,用户将设备戴在头上,扣上连接扣5,旋转摆杆8,调整麦克风9至合适的位置,调整过程中,转轴7内的转盘71在转动槽21内转动,盲孔712与转动槽21内壁的弹性片22卡接,起到相对固定的作用,在转盘71转动过程,既是调整麦克风9的位置。
进一步地,摆杆8包括套筒81以及与套筒81末端活动插接的伸缩杆82,伸缩杆82顶部的插接端固定有阻尼器821,阻尼器821侧壁开设的盲槽内设置有活动的橡胶块822,盲槽内的弹性件823压迫橡胶块822与套筒81内壁产生摩擦,套筒81底部开口端内壁固定有限位块811,当手动调整伸缩杆82插入深度的时候,盲槽内的弹性件823压迫橡胶块822与套筒81内壁产生摩擦,产生阻尼作用,保持摆杆8停留在调整之后的长度。
进一步地,所述盲孔712纵向剖面为半球形,所述弹性片22纵向剖面为半橄榄形。
一种用于vr展示教学的语音识别控制方法,其特征在于:包括以下步骤,
-步骤s1:通过降噪采集麦和麦克风分别采集降噪麦采集h(x)和麦克风采集g(x);
-步骤s2:结合预设静音室对比数据得出人声o(x);
-步骤s3:通过人声o(x)中的语音信息组合出语音指令;
-步骤s4:语音指令控制机体。
进一步地,一种用于vr展示教学的语音识别控制方法,其特征在于:所述步骤s2中,分为以下步骤,
-步骤s2.1:
设耳机输出声波为f(x),背景噪声为w(x),则
h(x)=w(x)+m1o(x)+k1f(x)公式1,
g(x)=w(x)+m2o(x)+k2f(x)公式2,
其中,m1为人声至降噪麦的传导系数,m1为人声至麦克风的传导系数,k1为耳机至降噪麦的传导系数,k2为耳机麦克风的传导系数;
-步骤s2.2:
在出厂静音室测试阶段,播放耳机,排除背景噪音w(x)以及人声o(x)的干扰,上述公式1和公式2变形为:
h(x)=k1f(x)公式3,
g(x)=k2f(x)公式4,
由于转轴多级可调整,针对每个转轴旋转状态,测试每个状态的k1、k2数值,
-步骤s2.3:
在出厂静音室测试阶段,测试人员戴上设备说话,关闭耳机,排除背景噪音w(x)以及耳机声音f(x)的干扰,上述公式1和公式2变形为:
h(x)=m1o(x)公式5,
g(x)=m2o(x)公式6,
由于转轴多级可调整,针对每个转轴旋转状态,测试每个状态的m1、m2数值,
-步骤s2.4:
代入公式1与公式2,之后公式2减去公式1,得到:
g(x)-h(x)=(m2-m1)o(x)+(k2-k1)f(x)公式7,
求解得出人声
将预设的m1、m2、k1、k2按预设顺序依此代入进行求解。
进一步地,所述步骤s3中,包括以下步骤,
-步骤s3.1:
在联网状态下,机体将人声语音o(x)实时上传至云识别平台进行语音指令识别,再将之后的语音指令下载,
-步骤s3.2:
当无法联网或者网络延迟过高,则将人声o(x)在本地处理。
进一步地,所述步骤s3.2包括以下步骤,
-步骤s3.2.1:
将人声o(x)建立响度db-时间t模型,
-步骤s3.2.2:
将响度db-时间t模型中响度db中人声o(x)求导得出d(x),
-步骤s3.2.3:
其中单个字的发声区间导数连贯,而单字之间则不连贯,由此将人声o(x)分切为单字发声,
-步骤s3.2.4:
将分切后的单字发声与语音数据库进行比对,转化为单个汉字,若转化失败,则跳转步骤s2.4重新求解,再合成为语音指令。
本实施例的一个具体应用为:
如图1-5所示,用户将设备戴在头上,扣上连接扣5,旋转摆杆8,调整麦克风9至合适的位置,调整过程中,转轴7内的转盘71在转动槽21内转动,盲孔712与转动槽21内壁的弹性片22卡接,起到相对固定的作用,在转盘71转动过程,既是调整麦克风9的位置,当手动调整伸缩杆82插入深度的时候,盲槽内的弹性件823压迫橡胶块822与套筒81内壁产生摩擦,产生阻尼作用,保持摆杆8停留在调整之后的长度。
如图6所示,用户对麦克风9说出语音指令,通过降噪采集麦3和麦克风9分别采集降噪麦采集h(x)和麦克风采集g(x),
如图7所示,降噪采集麦3接收到的声音h(x)包括背景噪声为w(x)、衰减之后的人声m1o(x)以及衰减之后的耳机声音k1f(x),麦克风9采集到的声音麦克风采集g(x)包括背景噪声为w(x)、衰减周的人声m2o(x)以及衰减之后的耳机声音k2f(x),即如下:
h(x)=w(x)+m1o(x)+k1f(x)公式1,
g(x)=w(x)+m2o(x)+k2f(x)公式2,
其中,m1为人声至降噪麦3的传导系数,m1为人声至麦克风9的传导系数,k1为耳机6至降噪麦3的传导系数,k2为耳机6麦克风9的传导系数,在出厂静音室测试阶段,播放耳机6,排除背景噪音w(x)以及人声o(x)的干扰,上述公式1和公式2变形为:
h(x)=k1f(x)公式3,
g(x)=k2f(x)公式4,
由于转轴7多级可调整,针对每个转轴7旋转状态,测试每个状态的k1、k2数值,
在出厂静音室测试阶段,测试人员戴上设备说话,关闭耳机6,排除背景噪音w(x)以及耳机声音f(x)的干扰,上述公式1和公式2变形为:
h(x)=m1o(x)公式5,
g(x)=m2o(x)公式6,
由于转轴7多级可调整,针对每个转轴7旋转状态,测试每个状态的m1、m2数值,
代入公式1与公式2,之后公式2减去公式1,得到:
g(x)-h(x)=(m2-m1)o(x)+(k2-k1)f(x)公式7,
求解得出人声
在解析o(x)过程中,将预设的m1、m2、k1、k2按预设顺序依此代入进行求解;
将人声o(x)建立响度db-时间t模型,
将响度db-时间t模型中响度db中人声o(x)求导得出d(x)
其中单个字的发声区间导数连贯,而单字之间则不连贯,由此将人声o(x)分切为单字发声,若无法解析出有意义单字发声,则转入将下一预设的m1、m2、k1、k2按预设顺序依此代入进行求解,
求解成功之后,将分切后的单字发声与语音数据库进行比对,转化为单个汉字,再合成为语音指令,
入图8所示,为语音“左转三十五度”六个汉字的语音波形图,分切之后入图9所示,
语音指令控制机体1。
上述操作中,相比较传统方式,能够解析用户的语音指令用于控制vr设备,方便在教学过程中能够使用。
在本说明书的描述中,参考术语“一个实施例”、“示例”、“具体示例”等描述意指结合该实施例或示例描述的具体特征、结构、材料过着特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
以上公开的本发明优选实施例只是用于帮助阐述本发明。优选实施例并没有详尽叙述所有的细节,也不限制该发明仅为所述的具体实施方式。显然,根据本说明书的内容,可作很多的修改和变化。本说明书选取并具体描述这些实施例,是为了更好地解释本发明的原理和实际应用,从而使所属技术领域技术人员能很好地理解和利用本发明。本发明仅受权利要求书及其全部范围和等效物的限制。
- 还没有人留言评论。精彩留言会获得点赞!