一种赣方言语音和方言点识别方法与流程
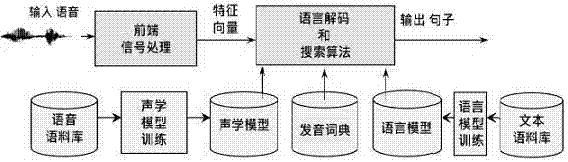
本发明涉及一种语音识别方法及转换系统,特别涉及一种赣方言语音和方言点识别方法。
背景技术:
:语音是人类最自然的特征之一,也是最直接的交互手段。语音识别是一门交叉学科,语音识别正逐步成为信息技术中人机接口的关键技术,语音识别技术与语音合成技术结合使人们能够甩掉键盘,通过语音命令进行操作。目前很多语音识别的声学建模通常是指从语音波形中计算得出的特征向量序列建立统计陈述的过程。目前语音识别多为普通话,而方言作为一个地方特色语言,有一大批人还在使用,特别是一些年龄比较大的人不会说普通话只会说方言,因此无法使用语言识别。且随着社会发展,越来越多软件:如输入法、导航软件都要使用到语言识别,方言的识别需求已经越来越强烈需求量也越来越大。赣方言作为江西方言,历史悠久,是唐宋以前中原移民的中原话和赣地先民语言相互融合的产物,形成于汉朝,定型于唐宋。主要包括赣语、客家语、江淮官话,方言间混淆度很大,这无疑给赣语方言种类识别带来了较大的挑战。技术实现要素:为解决上述问题,本发明的目的在于提供一种赣方言语音和方言点识别方法,采用dnn(deepneuralnetwork)替换传统的gmm(gaussianmixturemode)对hmm(hiddenmarkovmodel)状态的发射概率进行建模,基于kaldi1实现了赣方言的hmm-dnn(hiddenmarkovmodel-deepneuralnetwork)模型,结合我们标注的赣方言语音和文字语料库,采用5倍交叉验证进行赣方言语音和方言点识别任务,用最新深度学习卷积神经网络框架对输入的赣方言语音进行识别,可以识别出其对应的方言汉字文本和其归属的片区,同时还可以识别出其所在的方言点。为实现上述目的,本发明通过以下技术方案来实现:一种赣方言语音和方言点识别方法,其特征在于,包括预先构建赣方言语音识别模型,所述赣方言语音识别模型由前端信号处理模块、语言解码和搜索算法模块、声学模型、发音词典、语言模型构成,所述语言解码和搜索算法模块主要将声学信号解码成理想情况下接近源词序列的词序列,通过使用声学模型和语言模型生成具有最大后验概率输入特征向量的词序列,所述声学模型构建方式为通过建立赣方言语音语料库后通过声学模型训练而成,所述语言模型构建方式为通过建立赣方言文本语料库后通过语言模型训练而成,所述发音字典模块为赣方言发音词典,主要包含赣方言句子以及它对应的声母、韵母和声调信息;赣方言语音识别模型接收待识别的赣方言语音;对接收到的赣方言语音通过赣方言语音识别模型中的前端信号处理模块进行预处理并提取出mfcc(melfrequencycepstralcoefficients)特征向量;通过语言解码和探索算法模块将声学模块与语言模型结合起来,选出概率最大的句子作为语音识别句子输出;构建赣方言点识别模型,采用cnn网络结构(convolutionneuralnetwork)混合建模,首先以赣方言语音识别模型识别出来的赣方言汉字为基础,利用word2vec工具将其转换成汉字向量;其次利用赣方言语音中抽取出mfcc特征,对识别出的赣方言文本和语音两种类型的向量进行拼接,将此向量作为cnn的输入,并将卷积层的过滤大小分别设置为3、4和5;然后将卷积层后的向量利用最大池化策略降维;最后采用dropout防止模型过拟合,并利用softmax对赣方言点进行识别;通过赣方言点识别模型识别赣方言点。进一步地,所述的前端信号处理模块的预处理过程具体为:输入是赣方言声音信号,经过数模转换后,再去除直流信号,然后对信号进行分帧处理,接着对信号进行放大(扩大频率),对其分窗,然后经过付立叶变换,截取mel频率范围信号,经过对数运算,提取出mfcc特征,再结合每帧的能量信号,得到差分信息,最后提取出语音信号的声学特征,用于后续的模型训练。进一步地,所述信号进行分帧处理以25毫秒为一帧,每两个帧之间的叠加长度为10毫秒。进一步地,所述声学模型采用基于hmm-dnn的声学建模,赣方言语音的mfcc特征向量作为dnn输入,输出各种精度的音素,声学模型采用公式(1)所示的交叉熵作为目标函数,同时采用随机梯度下降法对其进行优化;h0=-yclog[p(yc=1)]-(1-yc)log[1-p(yc=1)](2)公式(1)中的θ是参数集,m代表训练实例的个数。进一步地,所述赣方言点识别模型采用公式(1)所示的交叉熵作为目标函数,同时采用adam算法对其进行优化。本发明采用hmm-dnn模型有两大优点:一是不需要对语音数据分布进行假设,不需要切分成语流来分段拟合;二是dnn的输入可以将相邻语音帧拼接成包含时序结构信息的矢量,在帧层次利用更多的上下文信息。说明书附图图1为本发明一种赣方言语音和方言点识别方法的赣方言语音识别模型;图2为mfcc声学特征提取流程;图3为hmm-dnn模型;图4为本发明一种赣方言语音和方言点识别方法的赣方言点识别模型。具体实施方式下面结合附图对本发明作进一步说明:一种赣方言语音和方言点识别方法,包括预先构建赣方言语音识别模型,通过赣方言语音识别模型接收待识别的赣方言语音;对接收到的赣方言语音通过赣方言语音识别模型中的前端信号处理模块进行预处理并提取出mfcc(melfrequencycepstralcoefficients)特征向量;通过语言解码和探索算法模块将声学模块与语言模型结合起来,选出概率最大的句子作为语音识别句子输出;构建赣方言点识别模型通过赣方言点识别模型对赣方言点进行识别。附图1显示了一个完整的建赣方言语音识别模型。语音识别的任务就是通过计算机程序将语音信号转换为相应的单词序列的一个过程。如图1所示,在信号处理模块中处理语音信号,提取解码器的显著特征向量。解码器(decoder)使用声学和语言模型生成具有最大后验概率的输入特征向量的词序列。各部件的组成分别如下:(1)前端信号处理模块在开始语音识别之前,首先要对语音信号进行预处理。预处理由三个阶段来完成,分别是模拟信号数字化、端点检测和分帧。在语音信号分帧以后,我们才可以对它进行详细分析。分帧是指将一段完整的语音信号切开成很多长度相等的小段。切开的每一段语音称为一帧。分帧操作一般采用移动窗函数来实现。第一帧和第二帧只有一个叠加部分。一般一帧长度为25毫秒,每两个帧之间的叠加长度为10毫秒即可。语音信号分帧完了以后,提取语音信号的特征参数。常用的特征有lpc(linearpredictivecoding)、lpcc(licensedprofessionalclinicalcounselor)和mfcc(melfrequencycepstralcoefficients)。本文我们选用mfcc作为特征参数。mfcc声学特征提取过程如附图2所示,其输入的是赣方言声音信号,经过数模转换后,再去除直流信号,然后对信号进行分帧处理(25毫秒为一帧,每两个帧之间的叠加长度为10毫秒),接着对信号进行放大(扩大频率),对其分窗,然后经过付立叶变换,截取mel频率范围信号,经过对数运算,提取出mfcc特征,再结合每帧的能量信号,得到差分信息,最后提取出语音信号的声学特征,用于后续的模型训练。输入的语音以wave(waveaudiofileformat)格式保存在计算机上,这种格式是直接保存对声音波形的采样数据,数据没有经过压缩,最大程度的保存了原语音特征的数据。本赣方言识别平台使用单声道的语音音频,其采样频率为16000hz,采样位数为16bit。最后每一帧的mfcc特征实际上是13维的向量,再通过一阶差分和二阶差分的计算,得到了长度为39维的声学特征。(2)声学模型模块声学模型主要负责完成语音到音节概率的计算。语音识别的声学建模通常是指从语音波形中计算得出的特征向量序列建立统计陈述的过程。本装置采用dnn(deepneuralnetwork)替换传统的gmm(gaussianmixturemode)对hmm(hiddenmarkovmodel)状态的发射概率进行建模有两大优点:一是不需要对语音数据分布进行假设,不需要切分成语流来分段拟合;dnn的输入可以将相邻语音帧拼接成包含时序结构信息的矢量,在帧层次利用更多的上下文信息。附图3显示了hmm-dnn模型,图3中模块7主要负责从语音信号中提取mfcc特征,模块8是dnn(deepneuralnetwork)深度神经网络模块,利用dnn可替换描述特征发射概率模型的gmm(gaussianmixturemodel),模块9是隐马尔可夫过程(hiddenmarkovmodel,简称hmm),其中在每个状态表示成i,ii,iii......n,状态之间可以进行转换,转换概率分别用aij进行表示,1<=i<=n;1<=j<=n。转移概率是每个状态转移到自身或转移到下个状态的概率。在实际中,每个音素用一个包含6个状态的hmm建模,每个状态用高斯混合模型gmm拟合对应的观测帧,观测帧按时序组合成观测序列。每个模型可以生成长短不一的观测序列,即一对多映射。训练过程即将样本按音素划分到具体的模型,再学习每个模型中hmm的转移矩阵和gmm的权重以及均值方差等参数。dnn比gmm提供更好的观察概率,dnn的每一帧的特征向量的长度为40维,考虑了相邻发音之间的关系,采用了相邻的11帧总共440维的数据作为dnn的输入,输出是各种精度的音素:单音子音素和三音子音素。模型采用公式(1)所示的交叉熵作为目标函数,同时采用随机梯度下降法对其进行优化:h0=-yclog[p(yc=1)]-(1-yc)log[1-p(yc=1)](2)公式(1)中的θ是参数集,m代表训练实例的个数。基于dnn-hmm的声学建模时,一般mlp对音素分类建模,计算音素分类的后验概率,并于hmm一起组成混合模型结构。深度神经网络的输入是语音的特征向量,这些特征向量通过线性辨别式分析(lineardiscriminantanalysis,lda)映射位200维向量,然后经过倒谱归一化去除信道噪声后作为dnn的输入。它的输出是各种精度的音素,常见的有单音子音素(monophone)和它的状态,三音子音素(triphone)和状态绑定等。hmm-dnn是一个完整的声学模型。利用dnn的时候hmm的作用就是对输出进行强对齐。因为,训练dnn的时候,需要知道每一帧对应的是什么音素。而一般语音数据的标注,只有音素串,并不知道每个音素hmm状态的起止时间。“强制对齐”就是利用hmm模型,求出每个音素或hmm状态的起止时间。(3)语言模型训练模块语言模型主要负责音节到字概率的计算,用以约束单词搜索,并计算句子出现的概率。统计语言模型是一个词序列上的概率分布。在语音识别中,计算机尝试将声音与字序列进行匹配。语言模型提供上下文单词和短语相似的相似度。数据稀疏是构建语言模型的主要问题。在训练中将不会观察到最可能的字序列。一个解决方案是假设一个单词的概率只取决于前面的n个单词。这一般称为n-gram模型。在n-gram语言模型中,观察句子w1,w2,…wn的概率p(w1,w2,wm)近似为条件概率可以从n-gram模型频率计算得出:bigram和trigram语言模型分别表示n=2和n=3的n-gram语言模型。然而,通常n-gram模型概率不直接来自于频率计数,因为以这种方式推出的模型在遇到以前没有明确出现的任何n-gram时,都会遇到严重问题。相反,某种形式的平滑是必要的,将一些总概率质量分配给不出现的单词或n-gram模型,其核心思想是对根据极大似然估计原则得到的概率分布进一步调整,确保统计语言模型中的每个概率参数均不为零,同时使概率分布更加趋向合理、均匀。常用的数据平滑技术有:加法平滑,good-turing估计,回退(backing-offsmoothing)平滑,线性插值(linearinterpolation)等。(4)发音词典模块本装置的赣方言发音词典主要包含赣方言句子以及它对应的声母、韵母和声调信息。赣方言发音词典实例如表1所示表1赣方言训练实例(5)语言解码和搜索模块解码器旨在将声学信号x解码成理想情况下接近源词序列的词序列,通过使用声学模型和语言模型生成具有最大后验概率的输入特征向量的词序列。解码器能够将声学模型与语言模型结合起来考虑,选出概率最大的句子作为语音识别的句子。而语音识别过程就是在状态网络中搜索一条最佳路径,语音对应这条路径的概率最大,这个过程称为“解码”,而基于动态规划剪纸的viterbi算法是一种常用的路径搜索算法,它可以寻找全局最优路径。hmm中的观察概率是指每帧和每个状态对应的概率;转移概率是每个状态转移到自身或转移到下个状态的概率。在实际中,每个音素用一个包含6个状态的hmm建模,每个状态用高斯混合模型gmm拟合对应的观测帧,观测帧按时序组合成观测序列。每个模型可以生成长短不一的观测序列,即一对多映射。训练过程即将样本按音素划分到具体的模型,再学习每个模型中hmm的转移矩阵和gmm的权重以及均值方差等参数。(6)赣方言点识别模块方言点的分类粗粒度的是精确到六大片区,细粒度的是精确到19个县市的方言点如表2所示:表2赣方言的层次区域结构赣方言点识别模型如图4所示,本装置所使用的cnn网络结构包括了输入层(inputlayer)1、卷积层(convlayer)2、最大池化层(maxpool)3、全连接层(fullyconnected)4、dropout层5和输出层(output)6。从模型结构图可以看出,输入层1输入的是语料库中的原始语句,该语句是由词向量拼接而成的句子向量。卷积层2对输入数据应用3种范围的过滤器,每种范围的过滤器个数是128个。在该模型中,过滤器的长度大小与词向量的长度大小是相同的,这一点不同于对图像做卷积时的过滤器。图4中卷积层2过滤器的宽度从左到右分别为3、4、5,表示同时对连续的3个词、4个词和5个词做特征提取。从直觉上讲,如果将一个权重分布到整个图像上,那么这个特征就和位置无关了,同时多个过滤器可以分别探测出不同的特征。最大池化层3能够缩减输入数据的规模,对每一个过滤器提取出来的特征只取一个最大的特征。在最大池化层3后面通常连接着一个或多个连接层,该模型在最大池化层3后面接了一个全连接层4,全连接层4将不同过滤器提取的特征拼接起来。dropout层5随机删除网络中的一些隐藏神经元,可以有效地减轻过拟合的发生,一定程度上达到了正则化的效果,本文中将该值设置为一般的0.5。输出层6最后输出每一个对应分类的概率值。实施例1:我们将音频采样率设置为16000hz,单声道,采样精度为16位;采用pydub工具按句子切分音频。对于hmm-dnn模型,我们采用sigmoid作为激活函数,softmax作为最后的输出层,学习率(learningrate)设置为0.008,mini-batch大小设置为256。评测指标:在语音识别中,常用的评估标准为词错误率wer(worderrorrate),其计算方式如公式(3)所示。为了使识别出来的词序列和标准的词序列之间保持一致,需要进行替换、删除、或者插入某些词,这些插入(insertions)、替换(substitutions)、删除(deletions)的词的总个数除以标准的词序列中词的个数的百分比便得到wer。错误!未找到引用源。(3)赣方言语音识别结果:表3显示了hmm-dnn赣方言语音识别性能,体现了深度学习的复杂学习能力。但是相比与普通话语音识别而言,赣方言的语音识别性能还有很大的提升空间。表3赣方言语音识别性能模型wer(%)hmm-dnn模型24.76在赣方言点识别模型中,我们设置5帧mfcc为一组,从而得到65维度的语音特征向量。为了与语音向量维度一致,我们设置赣方言语音识别后的汉字向量的维度也为65。cnn卷积层的过滤大小分别为3、4和5,过滤节点个数为128,采用relu作为激活函数,设置mini-batch大小为64,dropout比例为0.5,最大学习率为0.005,最小学习率为0.0001。与赣方言语音识别不同,我们没有对mfcc进行一阶和二阶差分,而是直接利用原始的13维度的mfcc作为特征。模型采用公式(1)所示的交叉熵作为目标函数,并利用adam算法优化该目标函数。评测指标我们采用正确度公式(4)度量系统性能。其中,truepositive代表本来是正样例,同时分类成正样例的个数;truenegative代表本来是负样例,同时分类成负样例的个数;all代表样例总个数。结果分析:表4显示了赣方言点识别模型的实验结果,从表中数据得知我们的系统取得了很好的识别性能,这充分说明了语音特征和文本特征的互补性。因为赣方言中各片区人群的发音特点在语音层面上有很大的差别,相比而言,各片区的词语方面的差别性要相对较小些。表4赣方言点识别实验结果正确率6路分类(第一层次)95.6419路分类(第二层次)94.90表5显示了我们提出的模型下第一层次的赣方言点识别实验混淆矩阵结果,我们可以看出绝大多数实例都可以被正确地识别出来,只有极少数实例被识别错误。其中,l1代表‘昌靖片’,l2代表‘抚广片’,l3代表‘客家话’,l4代表‘吉莲片’,l5代表‘宜萍片’,l6代表‘鹰弋片’。表5第一层次赣方言点识别混淆矩阵当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1