一种基于声音特征识别的婴儿哭声翻译方法与流程
本发明涉及声音识别技术领域,特别是一种基于声音特征识别的婴儿哭声翻译方法。
背景技术
传统婴幼儿陪护过程中,由于婴儿尚未具备语言能力,其生理需求和情感表达主要依靠陪护人的观察婴儿的表情、表观现象及体感特征等经验判断。这种方法在一定程度上依赖于看护人的经验丰富程度,但年轻父母或其他看护人很少接受专业培训,而造成经验不足或不尽相同、且没有相对统一的参考标准。这种传统的经验式判断存在以下弊端:1.由于看护人未及时掌握婴儿生理或心理需求,使得看护质量下降,效率不高;2.由于看护人误判、延判,造成婴儿的医疗、救治不及时。
技术实现要素:
本发明的目的是要解决现有技术中存在的不足,提供一种基于声音特征识别的婴儿哭声翻译方法,通过对婴儿哭声的特征提取与分析和神经网络训练,可以识别婴儿在不同生理状态下的声音反应,并反馈为饥饿、瞌睡、疼痛、无聊、恐惧、不适六种状态,可以协助人们对婴儿的反应做出判断,提高婴儿护理的科学性和可靠性。
为达到上述目的,本发明是按照以下技术方案实施的:
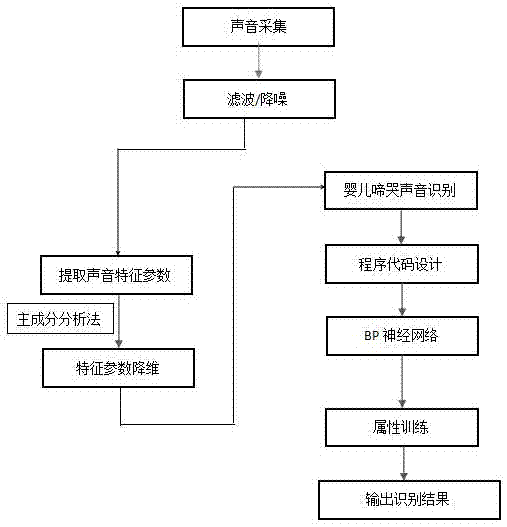
一种基于声音特征识别的婴儿哭声翻译方法,包括以下步骤:
步骤一、采用一个精密声级拾音器采集婴儿哭声的声音片段,并对采集的所有婴儿哭声的声音片段进行前处理,所述前处理包括对所有婴儿哭声的声音片段的语音降噪、滤波消噪;
步骤二、将经前处理的婴儿哭声的声音片段经a/d采样后存储于计算机,通过计算机对经前处理的婴儿哭声的声音片段再次进行滤波和降噪处理;
步骤三、对步骤二处理过的婴儿哭声的声音片段提取音色、音调、响度、能量、频率共5个特征参数特征参数和频率共生矩阵,共生矩阵的特征参数包括对比度、相关、逆差距、能量、中值、协方差、反差、差异性、二阶矩、熵、自相关共11个特征参数;
步骤四、通过主成分分析法对提取的音色、音调、响度、能量、频率的特征参数和频率共生矩阵的特征参数进行降维处理;
步骤五、选取降维处理后的婴儿哭声的声音片段的音色、音调、响度、能量、频率的特征参数用于输入bp神经网络的输入层,输出层神经元的个数为6,设定隐含层神经元的个数为4;设定bp神经网络最大训练次数为60000次,使最小均方差为0.0001;设定输入层的转换函数为tansig、输出层的转换函数为purelin、bp神经网络的训练函数为traingdm,权值和阈值的学习函数为learngdm;在输出层中分别表示如下:饥饿[100000]、瞌睡[010000]、疼痛[001000]、无聊[000100]、恐惧[000010]、不适[000001],然后开始对bp神经网络进行训练;
步骤六、bp神经网络训练完成后,将待识别的婴儿哭声的声音片段的降维处理后的声音片段的音色、音调、响度、能量、频率的特征参数输入到训练好的bp神经网络中,输出层得到婴儿哭声的声音识别。
进一步的技术方案为,所述步骤一中,所述精密声级拾音器放置于婴儿嘴部上方10cm处,采集1s时长的婴儿哭声的声音片段。
进一步的技术方案为,所述步骤四中降维处理具体为:采用db5小波对声音片段进行4层分解,得到16个等分的频率段,然后求出每个频率段的能量,然后将各段声音信号能量归一化后构成特征向量,该特征向量可表示为:
式中,e1,e2,……,e13,e14为每个频率段能量,e为信号总能量。
进一步的技术方案为,所述步骤五中,分别用[10000]、[01000]、[00100]、[00010]和[00001]来表示降维后的每段婴儿哭声的的声音片段的音色、音调、响度、能量、频率的特征参数。
与现有技术相比,本发明依据婴儿在不同生理状态下啼哭的声音特征差异,利用计算机声音处理技术,分别提取婴儿在不同生理状态下啼哭声音特征参数:音色、音调、响度、能量、频率和频率共生矩阵的11个特征参数,总共的16个特征参数。通过bp神经网络算法,对婴儿在不同生理状态下啼哭声音片段进行采集,对声音片段降噪和滤波后再建立婴儿啼哭声音特征差异与饥饿、瞌睡、疼痛、无聊、恐惧、不适六种生理状态之间的对应关系,并给出识别结果为:饥饿、瞌睡、疼痛、无聊、恐惧、不适。在训练bp神经网络中,输入任何一段婴儿哭声声音片段中提取的特征参数,即可从输出层得到识别的结果,提高婴儿护理的质量与效率,减少婴儿护理中的误判和延判。
附图说明
图1为本发明的流程图。
图2为bp神经网络结构图。
图3为多元神经单层神经网络示意图。
具体实施方式
下面结合具体实施例对本发明作进一步描述,在此发明的示意性实施例以及说明用来解释本发明,但并不作为对本发明的限定。
如图1所示,本实施例的一种基于声音特征识别的婴儿哭声翻译方法,具体步骤如下所示:
可以采用一个手持式的精密声级拾音器放置于婴儿嘴部上方10cm处,采集1s时长的婴儿哭声的声音片段,并对采集的所有婴儿哭声的声音片段进行前处理,所述前处理包括采用minidsp音频处理器,dsp语音降噪算法,ld-2l滤波消噪电流声抗干扰器对所有婴儿哭声的声音片段的语音降噪、滤波消噪。
这些声音信号在输入bp神经网络前需经分析处理,以获取利于识别的有效特征,这是决定bp网络输入层节点数和网络识别精度的关键。前面采集并存储于计算机的声音是离散的时域信号,可对婴儿啼哭产生的声音的进行频谱等特征分析,以提取相关的特征参数,从而建立婴儿啼哭声音特征差异与饥饿、瞌睡、疼痛、无聊、恐惧、不适六种生理状态之间的对应关系。
进一步,将经前处理的婴儿哭声的声音片段经a/d采样后存储于计算机,通过计算机对经前处理的婴儿哭声的声音片段再次进行滤波和降噪处理。
进一步,对处理过的婴儿哭声的声音片段提取音色、音调、响度、能量、频率共5个特征参数特征参数和频率共生矩阵,共生矩阵的特征参数包括对比度、相关、逆差距、能量、中值、协方差、反差、差异性、二阶矩、熵、自相关共11个特征参数。
进一步,由于不同婴儿啼哭的声音信号的功率谱不同,通过主成分分析法对提取的音色、音调、响度、能量、频率的特征参数和频率共生矩阵的特征参数进行降维处理,具体方法为:采用db5小波对婴儿哭声的声音片段进行4层分解,得到16个等分的频率段,然后求出每个频率段的能量,然后将各段声音信号能量归一化后构成特征向量,该特征向量可表示为:
式中,e1,e2,……,e13,e14为每个频率段能量,e为信号总能量。
bp神经网络是采用误差反向传播算法的多层前馈神经网络,它包含输入层、输出层和一个或多个隐层,如图3所示。各层神经元仅与相邻层神经元之间相互全连接,同层神经元之间无连接。输入信号从输入层节点(神经元)依次传过各隐层节点,再传到输出节点,每一层节点的输出只影响下一层节点的输出,然后按照误差减少的原则,从输出层经隐层向输入层逐层修正权值,这种逆向误差传播修正不断进行,直到达到所要求的学习目标。
进一步,构建bp神经网络,包含输入层节点数、输出层节点数和网络层数的确定。其中输入层节点数和输出层节点数是由实际问题本身决定的。如图2所示,选取降维处理后的声音片段的5个主成分特征参数:音色、音调、响度、能量、频率的特征参数用于输入bp神经网络的输入层,分别用[10000]、[01000]、[00100]、[00010]和[00001]来表示降维后的每段声音的音色、音调、响度、能量、频率的特征信号,输出层神经元的个数为6,设定隐含层神经元的个数为4;设定bp神经网络最大训练次数为60000次,使最小均方差为0.0001;设定输入层的转换函数为tansig、输出层的转换函数为purelin、bp神经网络的训练函数为traingdm,权值和阈值的学习函数为learngdm;在输出层中分别表示如下:饥饿[100000]、瞌睡[010000]、疼痛[001000]、无聊[000100]、恐惧[000010]、不适[000001],然后开始对bp神经网络进行训练。
进一步,bp神经网络训练完成后,将待识别的婴儿哭声的声音片段的降维处理后的声音片段的音色、音调、响度、能量、频率的特征参数输入到训练好的bp神经网络中,输出层得到婴儿哭声的声音识别,从而就判断出婴儿所表达的是饥饿、瞌睡、疼痛、无聊、恐惧、不适中具体的一种状态。
为了进一步验证本实施例的可行性,bp神经网络训练完成后,选取另外的待识别的待识别的20个婴儿哭声的声音片段,将每个试样的5个主成分特征参数输入到训练好的bp神经网络中,即得到如表1的输出结果。
表1bp神经网络测试结果
从表1中可以看出,将待识别的降维处理后的婴儿哭声的声音片段的音色、音调、响度、能量、频率的特征参数输入到训练好的bp神经网络中,可以快速识别出婴儿所表达的具体是饥饿、瞌睡、疼痛、无聊、恐惧、不适中具体的一种状态。
本发明的技术方案不限于上述具体实施例的限制,凡是根据本发明的技术方案做出的技术变形,均落入本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!