基于卷积神经网络的环境声音识别方法及系统与流程
本发明涉及的是一种音频处理领域的技术,具体是一种基于卷积神经网络的环境声音识别方法及系统。
背景技术
在音频信息的研究中,环境声音识别是一个重要的研究领域,其在安全监控、医疗监护、智能家居和场景分析等领域有着很大的应用潜力。相比于语音识别,环境声音具有类噪、宽频谱等特性,使得环境声音的识别更具有挑战性。
现有的基于卷积神经网络和耳蜗谱图的声音事件识别方法、基于卷积神经网络和随机森林的声音场景识别方法以及基于时频域统计特征提取的环境声音识别方法均具有适用范围有限、特征提取不方便、对于噪声的鲁棒性较差等缺点。
技术实现要素:
本发明针对现有技术存在的上述不足,提出一种基于卷积神经网络的环境声音识别方法及系统,能够结合声音梅尔能量谱有效提取特征的同时,使用混合构建的方法进行模型训练,增强训练样本分布,提高模型鲁棒性。本发明在esc-10、esc-50和urbansound8k三个公开环境声音数据集上取得了目前最好或接近最好的识别准确度。
本发明是通过以下技术方案实现的:
本发明涉及一种基于卷积神经网络的环境声音识别方法,将从原始音频中提取得到的梅尔能量谱特征进行混合构建得到样本库,用于对卷积神经网络模型进行训练,最终以训练后的卷积神经网络进行环境声音的识别。
所述的提取,具体包括以下步骤:
①对原始音频进行分帧后对每一帧进行fft变换得到声音的幅度谱
②利用梅尔滤波器组将声音的能量谱转换到梅尔频率表示,具体为:
③对得到的梅尔能量谱进行非线性变换:
所述的混合构建是指:从梅尔能量谱特征中随机选出两个样本,将两个样本按比率混合构建虚拟训练样本,以两个样本的混合比率为训练目标,通过利用特征的线性插值和相关目标的线性插值扩展训练分布增加训练样本的多样性,对模型有正则化的作用,提高了模型的鲁棒性。
所述的混合具体为:
所述的卷积神经网络包括:八个卷积层和两个全连接层,其中:每两个卷积层后通过设置一最大池化层进行降维;该卷积神经网络采用混合构建得到的样本库训练。
本发明涉及一种实现上述方法的系统,包括:特征提取模块、混合构建模块以及网络训练模块,其中:特征提取模块从原始音频中提取得到m梅尔能量谱片段并输出至混合构建模块,混合构建模块对m梅尔能量谱片段及其one-hot标签混合生成训练样本并输出至网络训练模块,网络训练模块使用混合样本进行训练后再次接收待测音频并输出对应的类别预测概率分布。
技术效果
与vgg-10网络结构相比,本发明中提出的卷积神经网络结构在esc-10、esc-50和urbansound8k数据集中分别提升了1.2%,3.5%和1.5%;识别精度在esc-10、esc-50和urbansound8k数据集均取得了最好或接近最好的识别准确度,说明本发明适用于不同类型的环境声音分类,具有鲁棒性。
附图说明
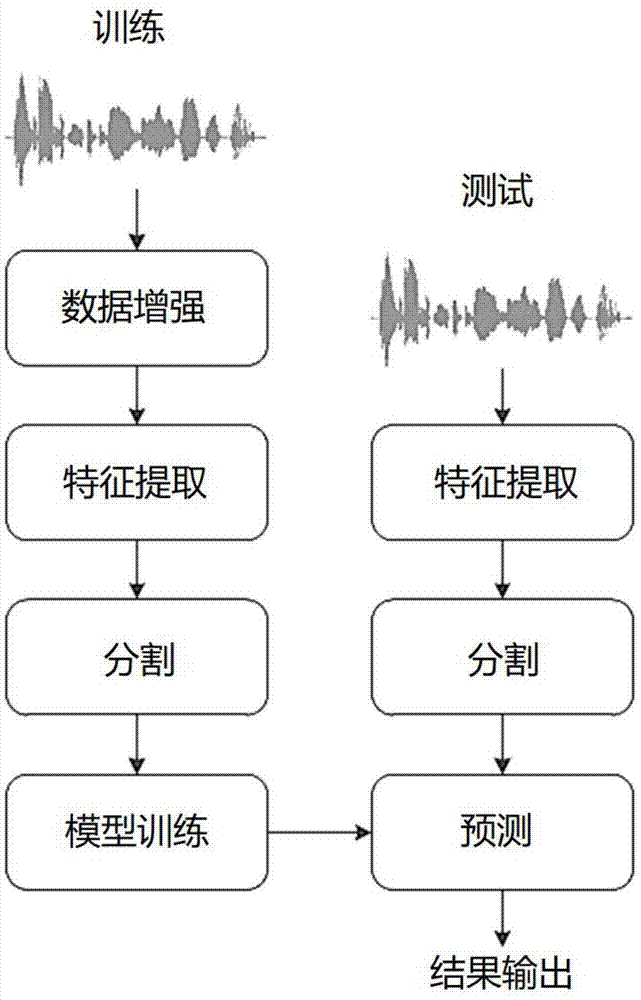
图1为本发明环境声音识别流程图;
图2为实施例mixup方法流程图。
具体实施方式
本实施例在三个公开数据集esc-10、esc-50和urbansound8k数据集上进行测试,如图1所示,具体包括:
步骤1)数据增强:三个公开数据集的声音样本数量较少,本实施例使用时间延伸处理和音调转换处理以扩充训练样本以增强模型的泛化性能。
所述的时间延伸处理是指:加快或放慢声音而不改变声音的音调并得到新的样本。
所述的音调转换处理是指:升高或降低音调而不改变声音的时长并得到新的样本。
步骤2)特征提取:利用fft变换得到声音的幅度谱,取平方得到声音的能量谱,然后利用梅尔滤波器组将声音的能量谱转换到梅尔频率表示,得到声音的梅尔能量谱。
优选地,本实施例使用基于能量的方法移除微弱音频,即通过预设阈值,移除连续三帧梅尔能量谱能量均值小于预设阈值的音频帧。
优选地,为了提升声音的低频表示,增强隐藏在低频部分的特征信息,本实施例对梅尔能量谱图取log非线性变换,得到最后的梅尔能量谱特征。
步骤3)音频分割:为了更有效的利用有限的数据,本实施例采用音频分割将步骤2得到的梅尔能量谱特征分割成固定长度的小尺寸的梅尔能量谱特征图,以此来获取更多的训练样本。
步骤4)模型训练:将音频分割后得到的小尺寸的梅尔能量谱特征作为模型训练样本,并将训练样本赋予相应的类别标签。
如图1所示,所述的混合构建是指:在梅尔能量谱特征中随机选取两个样本以一定的比例进行线性混合,构建虚拟训练样本,模型的训练目标更改为两个样本的混和比率,构建方式为:
本实施例将得到的虚拟训练样本和相应的训练标签输入卷积神经网络模型中进行监督训练。训练时,卷积核和权重采用随机参数初始化,偏置采用全0初始化。采用随机梯度下降(sgd)算法进行网络参数的更新,当网络迭代次数达到预设的迭代次数时,训练停止并保存训练好的卷积神经网络模型。
步骤5)测试阶段:通过对待测声音样本采用和训练阶段同样的特征提取和音频分割步骤,得到用于测试的小尺寸梅尔能量谱特征并赋予类别标签,将测试样本和相应的类别标签输入到训练好的所述的卷积神经网络模型中,将卷积神经网络的输出与测试集样本所对应的类别进行比对,计算出环境声音的识别率。
具体地,本实施例使用卷积神经网络和mixup方法对在esc-10、esc-50和urbansound8k数据集上进行性能测试。
所述的urbansound8k数据集包含8732个取自城区的声音片段,每段声音长度不大于4秒,采样率为44.1khz。该数据集包括:10类。esc-50数据集包含2000个自然环境声音片段,每段声音长度为5秒,采样率为44.1khz。该数据集包括:5个大类,分别为动物叫声、自然环境声、人类非语音声、室内声和城市室外声5大类,每个大类包含10类声音,每类声音有40个样本。esc-10数据集是esc-50数据集的子集,包括:10类声音,400个样本,所有样本均取自esc-50数据集。数据集详细信息见表1。
表1环境声音数据集
对上述训练数据集,使用“时间延伸”和“音调转换”方法生成新的样本,扩充数据集为原始训练数据集的5倍。
使用hamming窗对声音信号进行分帧,每帧选取1024个采样点,为了保持相邻帧之间的连续性,帧移选取为512个采样点;利用fft变换得到声音的幅度谱,对幅度谱做平方处理得到声音的能量谱,然后利用128阶梅尔滤波器组将声音的能量谱转换到梅尔频率表示,得到梅尔能量谱;使用一种基于能量的微弱音频移除算法。具体而言,本实施例预设了一个阈值,当连续三帧的能量均值小于预设的阈值,则移除这三帧;最后,为了提升声音的低频表示,增强隐藏在低频部分的特征信息,本实施例对梅尔能量谱取log非线性变换,得到最后的128×f维梅尔能量谱特征,其中f为时间帧的长度。
对得到的128×f维梅尔能量谱特征沿时间帧进行分割,得到m个128×128维的梅尔能量谱特征,并给每个样本赋予类别标签,作为卷积神经网络输入数据。
将训练样本输入到卷积神经网络,进行监督训练。训练过程中,卷积核和权重进行随机初始化,偏置项置为0。采用随机梯度下降(sgd)算法进行网络参数的更新,当网络迭代次数达到预设值时,训练停止并保存训练好的卷积神经网络模型。
所述的卷积神经网络包括:8卷积层、4个池化层和2全连接层,具体设置为:
第一卷积层conv1卷积核尺寸为3×7,步长为1×1,卷积核数量为32;
第二卷积层conv2卷积核尺寸为3×5,步长为1×1,卷积核数量为32;前两卷积层使用尺寸较大的卷积核,进行基本的特征提取;
第一最大池化层pool1卷积核尺寸为4×3,步长为4×3,用于降低特征维度;
第三卷积层conv3和第四卷积层conv4卷积核尺寸为3×1,步长为1×1,卷积核数量为64,用于提取高层频域特征;
第二最大池化层pool2卷积核尺寸为4×1,步长为4×1,降低频域维度;
第五卷积层conv5和第六卷积核conv6卷积核尺寸为1×3,步长为1×1,卷积核数量为128,用于提取高层时域特征;
第三最大池化层pool3卷积核尺寸为1×3,步长为1×3,降低时域维度;
第七卷积层conv7和第八个卷积层conv8卷积核尺寸为3×3,步长为1×1,卷积核数量为256,用于提取时频特征;
第四最大池化层pool4卷积核尺寸为2×2,步长为2×2;
第一全连接层fc1有512个节点,第二全连接层fc2,即输出层节点个数需根据类别数量而确定。
对于esc-10和urbansound8k数据集,fc2节点数为10;对于esc-50数据集,fc2节点数为50。卷积层和fc1使用relu激活函数,进行非线性转换,输出层激活函数使用softmax,用于输出不同类别的预测概率。
表2卷积神经网络参数设置
将测试样本输入到保存的卷积神经网络模型中,输出预测结果,并计算识别率(识别率=识别正确的样本数/识别的总样本总数)。如表3所示,本实施例中提出的卷积神经网络结构与同层数的vgg结构(vgg-10)进行对比,在三个公开数据集中识别精度均高于vgg-10。
表3提出的卷积神经网络与vgg-10的性能对比。
如表4所示,本方法在不同的公开数据集上都能取得很好的结果,在urbansound8k数据集上取得了目前最好的识别准确度,在esc-10和esc50数据集上取得了接近最好的结果。
表4不同环境声音识别方法的性能对比。
上述具体实施可由本领域技术人员在不背离本发明原理和宗旨的前提下以不同的方式对其进行局部调整,本发明的保护范围以权利要求书为准且不由上述具体实施所限,在其范围内的各个实现方案均受本发明之约束。
- 还没有人留言评论。精彩留言会获得点赞!