用于隐私保护型语音交互的设备和方法与流程
本公开涉及语音交互领域,并且更具体地涉及在多用户家庭辅助环境中保护用户的隐私。
背景技术:
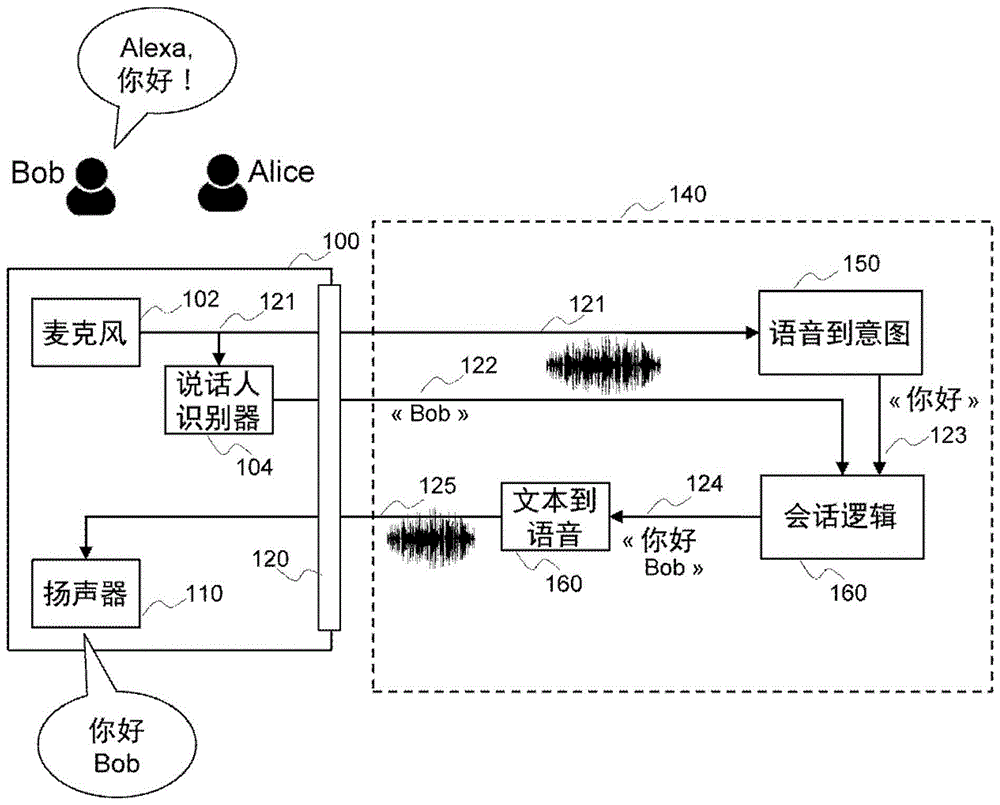
:本部分旨在向读者介绍本领域的各个方面,其可与下文描述和/或要求保护的本公开的各个方面相关。相信该讨论有助于向读者提供背景信息,以更好地理解本公开的各个方面。因此,应该理解的是,这些陈述应该从这个角度来进行理解,而不应被理解为承认是现有技术。通过家庭辅助设备(比如,amazonecho或googlehome)以及家庭辅助服务(比如,microsoftcortana或applesiri)在住宅环境内使用语音控制功能已经形成了很大的市场;数以百万计的家庭都使用此类设备或服务。家庭辅助设备通过麦克风从家庭用户捕获自然语音,对用户查询加以分析,并提供适当的回应或服务。待执行的查询可以是使用家庭设备(例如:关闭电视的声音,关闭百叶窗等),也可以使用非家庭服务(例如:检索天气预报或股价,获取帮助以解决设备故障等)。此外,最新一代的家庭辅助设备还执行对说话人的识别。这种识别允许实现多种功能,比如,访问控制(例如:孩子不能配置家庭网络,不能访问成人电影等)、交互个性化(例如:交互的词汇可以适合于说话人类型,该说话人类型是从年幼的孩子、青少年、成年人或老年人中选出的)。但是,这样做的代价是用户的隐私受保护程度降低。实际上,在这些语音交互生态系统中使用的语音分析和会话逻辑按惯例是在家庭环境之外操作的,通常是在云端操作的。因此,可以认识到的是,需要一种能解决现有技术的至少一些问题的针对住户说话人的识别的解决方案。本公开提供了这样的解决方案。技术实现要素:本公开描述了一种用于隐私保护型语音交互的家庭辅助设备和方法。麦克风捕获对应于语音用户查询的音频信号。确定说话人的身份,并且对应于所识别出的说话人,生成模糊姓名。分析音频信号以确定用户的意图,并结合模糊姓名生成个性化回答。之后,通过重新加入说话人姓名来对此回答进行去模糊处理。然后将去模糊回答呈现给说话人。在第一方面,本公开涉及一种用于执行隐私保护型语音交互的设备,包括:麦克风,其配置为捕获音频信号,该音频信号表示与来自说话人的查询有关的语音发声;说话人识别器,其配置为根据捕获的音频信号确定说话人的身份;隐私执行器,其配置为生成与所识别的说话人相对应的模糊说话人姓名,并存储说话人姓名与模糊说话人姓名之间的对应关系的列表;通信接口,其配置为向外部设备提供捕获的音频信号和模糊说话人姓名,从外部设备接收针对说话人查询的回答;其中隐私执行器还配置为确定所接收的回答是否包含列表中的模糊说话人姓名,并且在这种情况下,在所接收的回答中用对应的姓名替换模糊说话人姓名,从而生成去模糊回答。在第一方面的第一变型中,所接收的回答是文本形式,并且设备还包括配置为将去模糊回答从文本形式转换为音频信号的文本到语音转换器。在第一方面的第二变型中,所接收的回答是音频格式,并且隐私执行器还配置为通过检测列表中的说话人姓名并用代表对应的模糊说话人姓名的音频信号对其进行替换来对捕获的音频信号进行模糊处理。在第一方面的第三变型中,隐私执行器还包括用于打开或关闭隐匿模式的设置,其中在第一种情况下,隐私执行器在提供说话人姓名之前对其进行模糊处理,并且在所接收的回答包含模糊说话人姓名时,对其进行去模糊处理,而在第二种情况下,隐私执行器不再对说话人姓名进行模糊处理,并且不再判断所接收的回答是否包含模糊说话人姓名。在第二方面,本公开涉及一种用于执行隐私保护型语音交互的方法,包括:捕获音频信号,该音频信号表示与来自说话人的查询有关的语音发声;根据捕获的音频信号识别说话人;生成与所识别的说话人相对应的模糊说话人姓名,并存储说话人姓名与模糊说话人姓名之间的对应关系的列表;向外部设备提供捕获的音频信号和模糊说话人姓名;从外部设备获取针对查询的回答;确定所接收的回答是否包含列表中的模糊说话人姓名,并且在这种情况下,在所接收的回答中用对应的姓名替换模糊说话人姓名,从而生成去模糊回答;并且为说话人提供回答。在第二方面的第一变型中,所接收的回答是文本形式,并且方法还包括检测列表中的说话人姓名并用表示对应的模糊说话人姓名的音频信号对其进行替换。第二方面的第二变型还包括打开或关闭隐匿模式的设置,其中在第一种情况下,在提供说话人姓名之前对其进行模糊处理,并且在所接收的回答包含模糊说话人姓名时,对其进行去模糊处理,而在第二种情况下,不再对说话人姓名进行模糊处理,并且不再判断所接收的回答是否包含模糊说话人姓名。第二方面的第三变型包括更新模糊说话人姓名。在第三方面,本公开涉及一种计算机程序,该计算机程序包括可由处理器执行来实现第二方面的方法的任何实施例的程序代码指令。在第四方面,本公开涉及一种计算机程序产品,该计算机程序产品存储在非暂时性计算机可读介质上并且包括可由处理器执行来实现第二方面的方法的任何实施例的程序代码指令。附图说明现在将参考附图通过非限制性示例来描述本公开的优选特征,其中:图1a示出了根据现有技术的示例性家庭辅助生态系统,图1b示出了在其中可以实现本公开的至少一部分的示例性家庭辅助生态系统,图2示出了根据本公开的实施例的隐私保护型语音交互方法的示例性流程图。具体实施方式图1a示出了根据现有技术的示例性家庭辅助生态系统。本领域技术人员应该认识到,为了清楚起见,简化了所示出的设备。家庭辅助生态系统至少包括通过通信接口120与服务提供者进行交互的家庭辅助设备100。服务提供者向用户提供多种服务,其特征在于:这些服务是建立在语音交互的基础上,并且针对各个用户进行了个性化。所述服务由专门的软件应用提供,这些应用相互协作来回应说话人的请求。这些软件应用按惯例是在非家庭设备上(通常是在云端)执行的,并且可以由单个服务运营商140操作(如图1a所示),或者可以分到多个协作的服务提供者。家庭辅助设备包括:麦克风102,用于捕获由用户进行语音查询而生成的语音发声,并生成对应的音频信号121。说话人识别器模块104分析音频信号121,以从家庭用户组中识别出说话人,并向服务提供者140提供说话人身份122。语音到意图150接收音频信号121,对其加以分析,将其转换为文本并生成意图。“语音到意图”功能不同于“语音到文本”功能。实际上,意图对应于概念,并且含义更广,不仅是识别出的词。例如,当说话人说“gutentag”、“bonjour”、“hi”等时,意图可以是“打招呼”。会话逻辑160接收意图123和说话人身份122。在知晓之前与说话人的交互的情况下,会话逻辑160响应于最新意图来生成适当的回答124。由于会话逻辑知道说话人身份,会话逻辑例如通过在响应中插入说话人的姓名来对回答进行个性化处理。回答124是文本串并被提供给文本到语音逻辑160,文本到语音逻辑160将其转换为音频信号125,音频信号125被传送给家庭辅助设备并在扬声器110上呈现。例如,如图1a所示,当用户bob想要与生态系统进行交互时,在amazon生态系统的情况下他通过简单的查询“alexa,bonjour!”来开始。生态系统将会通过说出“bonjourbob”来作出回复,如此便通过插入所识别的说话人的姓名来使响应变得个性化。借助于这种设置,家庭辅助设备100向服务提供者提供说话人的身份。然而,用户并不总是希望他们的身份被公开,并且期望他们的隐私保护得到改善。图1b示出了在其中可以实现本公开的至少一部分的示例性家庭辅助生态系统。该家庭辅助生态系统包括隐私友好型家庭辅助设备100′,并且在改善对说话人的隐私保护的同时能够在与图1a中描述的现有技术系统完全相同的服务运营商环境140下操作。家庭辅助设备100′包括:麦克风102,其配置为捕获来自用户的音频;说话人识别器104,其配置为在家庭用户中检测说话人的身份;隐私执行器106,其配置为通过用临时姓名替换说话人姓名并将其插回到输入数据中以在输出数据中模糊说话人的身份;可选的文本到语音转换器108,其配置为将文本回答转换成语音信号;扬声器110,其配置为输出音频信号;以及通信接口120。家庭辅助设备100′还包括其他组件,这些组件由于与本发明无关而未进行示出(比如,用于配置系统的按钮、用于操作电子部件的电源、用于驱动扬声器的音频放大器等),但是对于设备的操作而言是必不可少的。家庭辅助设备100′可以实现为独立设备,或者可以集成在诸如机顶盒、网关、电视机、计算机、智能电话、平板电脑等传统消费者设备中。通信接口120配置为与至少执行语音到意图和会话逻辑功能的非家庭设备进行交互,比如,云端中的数据服务器和处理器。adsl、线缆调制解调器、3g或4g是可以用于实现此目的的通信接口的示例。可以采用其他通信接口。根据由会话逻辑提供给家庭辅助设备100′的回答类型,家庭辅助设备100′按照两种模式中的一种操作。当会话逻辑160传送文本格式的回答时,使用第一模式。在这种情况下,不使用服务提供者140的文本到语音转换器170,而是在家庭辅助设备100′内通过文本到语音转换器108完成到音频的转换。第二模式是与传统服务提供者一起使用,其中回答作为音频信号进行传送,因此使用了服务提供者140的文本到语音转换器170。根据优选实施例,家庭辅助生态系统按照第一模式操作。说话人产生语音发声,以做出语音查询,比如,“alexa,今天天气如何?”。麦克风102捕获此语音发声并生成对应的音频信号121。说话人识别器模块104分析音频信号121并将说话人识别为识别符为xyz-002且姓名为bob的说话人。例如,这种识别使用传统的说话人识别技术来完成,比如,使用gmm-ubm模型(高斯混合模型-通用背景模型)的分类来完成。一旦识别出了说话人,则向隐私执行器106提供说话人姓名122,隐私执行器106生成临时姓名126(在图1b的示例中:“tak”)并将其提供给服务提供者140,从而模糊说话人的真实姓名和身份。隐私执行器106存储说话人识别符与模糊姓名126之间的关系。这是例如通过在映射表中存储所识别的说话人的姓名(或其本地识别符/简档)与模糊姓名之间的关联性来完成的。表1示出了这种映射表的示例。#姓名模糊姓名xyz-001aliceokulxyz-002bobtakxyz-003charliewakboxyz-004eleonoredragopasa表1:映射表多种技术可被用来生成模糊姓名,比如,生成随机文本串,或者在与家庭成员姓名不同的随机文本列表中随机地选择一个元素。模糊姓名优选地不对应于常见姓名或常用单词。为了确保这一点,所生成的随机文本只有在它不是人名词典和传统词典的一部分时才能被使用。如果情况不是如此,则必须生成新的随机文本。然后,隐私执行器106将音频信号121′和模糊姓名126提供给服务运营商140。语音到意图150分析所接收的音频信号121′并生成对应的意图123。会话逻辑160然后分析意图123并生成例如包括模糊姓名的个性化回答124。之后,将该回答以文本形式直接发送回家庭辅助设备100′。隐私执行器106分析所接收的回答124并检查它是否包含映射表的模糊姓名列表中的模糊姓名。当情况是如此时,所检测到的模糊姓名被对应的说话人姓名替换,从而生成去模糊回答124′,这种去模糊回答124′由文本到语音转换器108转换为由扬声器110呈现的音频信号127。在图1b所示的示例中,bob说了“alexa,今天天气如何?”说话人被识别为“bob”,因此,对应的模糊姓名是“tak”。音频分析表明,意图是“今天天气”。于是,获取今天的天气报告,并通过添加说话人的姓名来使回答变得个性化:“你好tak。今天天气是......”,该回答中仍然包含的是模糊说话人姓名。当对该回答进行分析时,检测到列表中的模糊说话人姓名中的一个(“tak”)。该模糊说话人姓名被对应的真实说话人姓名“bob”替换,由此生成了最终的响应“你好bob。今天天气是......”。所以,没有在家庭辅助设备100′之外公开说话人姓名,从而保护了家庭辅助设备的多个用户的隐私。根据替代实施例,家庭辅助生态系统按照第二模式操作。与第一模式的不同之处在于:当会话逻辑生成回答124时,由于音频信号125是由服务提供者140的文本-语音转换器170生成的,因而此回答不是以文本形式而是以音频形式直接提供给家庭辅助设备100′。因此,当家庭辅助设备100′接收到回答125时,隐私执行器106分析音频信号125,以检测出模糊姓名。为此目的,隐私执行器获得模糊姓名的音频表示,并在音频域中的音频信号125内搜索这些表示,例如使用两个音频信号的互相关性来搜索。当找到模糊姓名时,它被对应的说话人姓名替换,从而生成去模糊回答127,该去模糊回答127由扬声器110呈现。在这种第二模式中,所选择的模糊姓名可以如表1中所示具有与说话人姓名相似的长度。替代地,它也可以具有固定长度,避免提供可以用于确定家庭人数的信息。用于生成这种模糊姓名的技术的一个示例是在固定数量的字母上使随机辅音和随机元音交替出现。在这种情况下,表1的模糊姓名的示例可以是“kadopabo”、“jilybelo”、“gatekomu”和“dagopasa”。在替代实施例中,为了提高隐私性,所记录的音频信号121被隐私执行器修改成另一个音频信号121′,这样使得无法识别出所记录的语音的语音特征。此项工作可以采用任何语音转换算法(语音变形、韵律调整,或者甚至是先应用语音到文本然后再应用文本到语音,等等)来完成,从而在不改变所说出的文本的情况下转换特性。这种转换的结果将是离开家庭网络的所有语音都是相同的,因此变得无法区分。这种附加安全措施适用于这两种模式。在替代实施例中,隐私执行器还对来自所记录的音频信号121的输出音频信号121′的文本进行模糊处理。这是通过在音频信号内检测家庭说话人的其中一个姓名(例如,如在表1的映射表中所列出的姓名)来完成的。当找到说话人姓名时,它将被对应的模糊姓名替换。本实施例是可选的,因为它在某些情况下可能导致查询不成功。例如,如果激活了此功能,在上面的表1的情况下,将可能无法观看电影“爱丽丝梦游仙境(aliceinwonderland)”,这是因为查询将被转换为“奥库尔梦游仙境(okulinwonderland)”。在替代实施例中,在默认设置、用户选择或者用户偏好设置的控制下周期性地更新模糊处理,所述周期性例如是在设备的每次启动时,每天,每15分钟,针对每个查询等。针对每个查询对模糊处理进行更新的情况改善了两个连续的请求之间的不可关联性(unlinkablity)。然而,它的缺点在于弱化了查询的上下文,这是因为会话逻辑将总是在每次更新(因为它是由假定的新说话人执行的)之后从空的上下文开始。根据实施例,可以例如在用户选择或用户偏好设置的控制下打开或关闭隐私执行器106。此举实现了对隐私执行器所提供的隐私级别的控制,因此被命名为隐私级别设置。当隐私级别设置是“no_privacy(无隐私保护)”时,隐私执行器106是完全透明的:它不影响家庭辅助设备100′的输出查询,也不修改进入的结果。当隐私级别设置是“incognito(隐匿)”时,隐私执行器106完全发挥作用:它对输出查询进行分析以模糊查询中的说话人姓名,从音频中移除任何说话人姓名,转换输出语音查询,并且在进入的结果中恢复说话人姓名。其他中间隐私级别设置也是可能的,例如不执行语音转换。根据实施例,可以使用音频查询本身来调整隐私级别设置,比如,使用“启动私人模式”、“启动隐匿模式”、“隐藏我的身份”等来启用隐私执行器,以及,使用“停止隐私保护模式”、“停止隐匿模式”等来绕过隐私执行器。隐私执行器检测到此查询,相应地调整其行为。图2示出了根据本公开的实施例的隐私保护型语音交互方法的示例性流程图。在步骤200中,麦克风捕获由用户执行的形成语音查询的语音发声,并生成对应的音频信号。在步骤202中,说话人识别器识别所捕获的音频信号的说话人的身份,并且在步骤204中,隐私执行器生成模糊说话人姓名。可选地,在并行的步骤206中,隐私执行器对音频信号进行模糊处理。在步骤208中,获得并分析音频信号,并且生成对应的意图。在步骤210中,在获得模糊说话人姓名之后生成个性化响应。在步骤212中,由隐私执行器对响应加以分析,该隐私执行器用对应的说话人姓名替换响应中的模糊姓名。在步骤214中,扬声器呈现去模糊响应。模糊步骤204和206以及去模糊步骤212处于隐私级别设置的控制下,并且当隐私级别设置是“no_privacy”时,绕过这些步骤。如本领域技术人员将认识到的,以上所述的本发明原理和特征的各方面可以采用完全硬件实施例的形式、完全软件实施例(包括固件、常驻软件、微代码等)的形式或者将硬件和软件方面加以组合的实施例的形式。例如,尽管使用了针对说话人识别器104、隐私执行器106和文本到语音转换器108的硬件组件来完成描述,但是,这些元件可以使用如下内容被实现为软件组件:配置为执行本公开的至少一个实施例的方法的至少一个硬件处理器、配置为存储执行本公开的至少一个实施例的方法所需的数据的存储器以及可由处理器执行来实现本公开的至少一个实施例的计算机可读程序代码。因此,在这样的实现方式中,硬件处理器配置为至少实现说话人识别器104、隐私执行器106和文本到语音转换器108的功能,并且配置为通过通信接口120与服务提供者相接。为此目的,硬件处理器配置为至少实现图2的步骤,包括识别用户步骤202、模糊姓名步骤204、模糊音频查询步骤206、去模糊步骤212和呈现回答步骤214。此外,尽管已经分别描述了不同的替代实施例,但是它们可以以任何形式组合在一起。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1