一种针对汉语普通话的早期AD言语辅助筛查系统的制作方法
本发明涉及一种针对汉语普通话的早期ad言语辅助筛查系统。
背景技术:
近十年来,研究新型的、无创的、经济的、适合于早期ad筛查的辅助诊断标志物,已成为ad早期诊断研究的热点问题。研究人员从认知损伤、生化诊断、神经电生理等不同角度提出一系列有可能成为ad早期筛查工具的辅助诊断方法,如言语测试、嗅觉测试、步态检测、视网膜成像检测、aβ外周血液筛查、尿液ad7c-ntp蛋白检测、脑电分析(eeg)等。
现有的早期ad筛查方案主要存在以下问题,阻碍了相关诊断方法在ad早期筛查检测及ad疾病进程评估中的进一步临床应用。
(1)成本较高,对环境设置及执行人员有专业性要求,难以大范围推广
目前,临床上对ad的检测方法有脑脊液(csf)分析、神经影像学、神经心理量表测试三类方法。然而,由于成本高昂、侵入性检查的普及率低及高门槛准入等局限性,上述检测方法很难作为大范围早期ad筛查的诊断工具。
(2)缺乏对不同言语任务和所提取的言语特征的合理利用与系统考察
当前相关技术在手段或方案上仍存在一些不足,例如样本量较少、特征提取方案和特征选择方法较为单一等。所采用的检测任务、辅助材料以及基于任务所提取的数据特征也不尽相同,具有较大的差异性。由于早期ad语言障碍体现在语音、语义提取等多个方面,单一言语任务不能全面了解早期ad患者的言语特异性。
技术实现要素:
为解决上述背景技术中存在的问题,本发明提出一种针对汉语普通话的早期ad言语辅助筛查系统,该系统从早期ad语言功能受损角度出发,针对汉语普通话的ad早期筛查这一研究目标,提供关于早期ad言语特异性特征的提取方案及配套装置,具有低成本、可实时获取丰富数据、易实现大样本采集(可用于大数据分析)、可以实现远程采集分析等优势,在大范围ad早期筛查和长时间病程管理方面都有着重大应用潜力。
本发明解决上述问题的技术方案是:一种针对汉语普通话的早期ad言语辅助筛查系统,其特殊之处在于:
包括主体测试单元、言语特征提取单元和识别单元;
所述主体测试单元用于对被测对象进行测试;所述言语特征提取单元用于提取被测对象的言语特征,并对该言语特征进行存储;所述识别单元用于对言语特征进行言语特征进行识别;
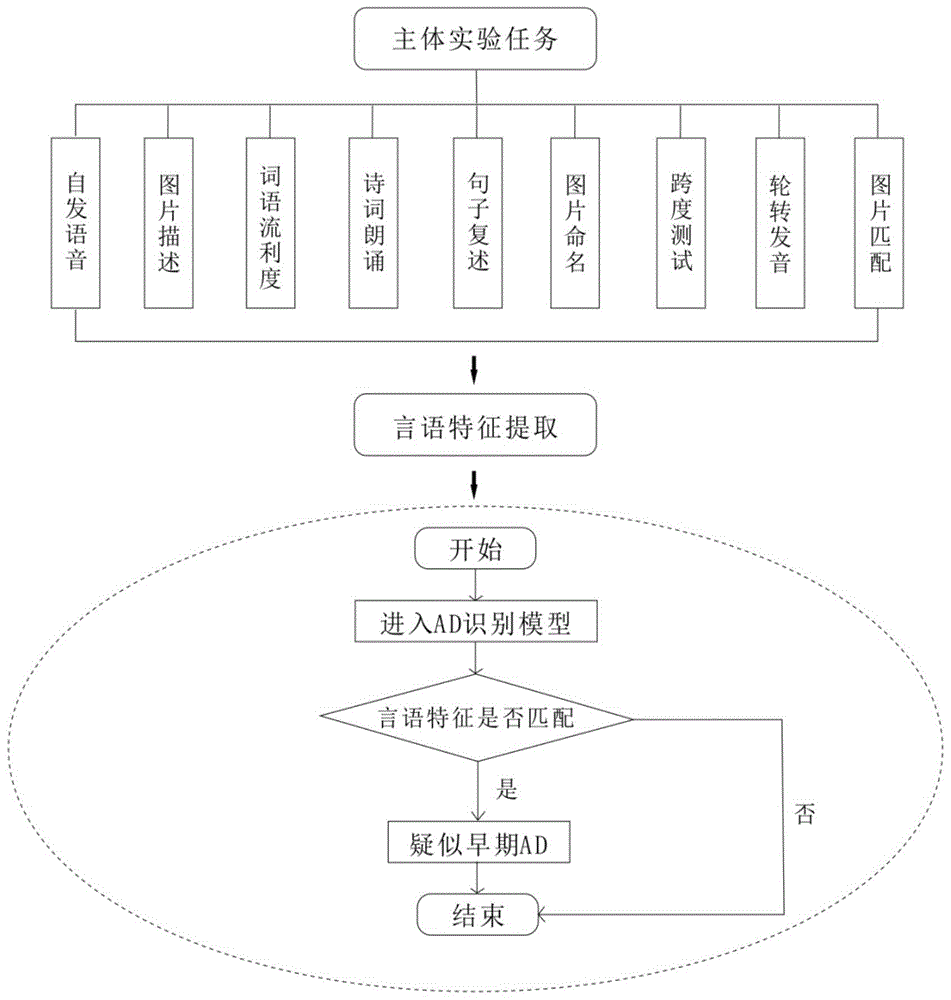
所述主体测试单元包括自发语音模块、图片描述模块、词语流利度模块、诗词朗诵模块、句子复述模块、图片命名模块、跨度测试模块、轮转发音模块和图片匹配模块;
所述言语特征提取单元包括语音信号的自动切分模块、信号预处理模块、自动语音识别模块、文本分析模块、语音分析模块;主体测试单元中各个模块中记录得到的语音数据首先经过自动切分模块得到分段的语音,经过信号的预处理和自动语音识别模块识别为文本,文本分析模块和语音分析模块根据语音识别的结果计算和估计其对应的语音特征、词汇特征、语法特征、语用特征;
所述识别单元包括特征选择模块和分类模块;特征选择模块对多维特征进行选择和优化,得到对诊断敏感的特征集;分类模块使用优化的特征集,并运用多任务深度置信网络算法(multi-taskdbn),利用任务相关性联合提高对分类任务的预测;该网络以分类任务为主任务,而mmse和moca评分将作为相关任务进行训练,以帮助提高分类任务的预测性能;根据预测结果最终完成对早期ad患者的诊断和筛查。
进一步地,上述自发语音模块主要测试被测对象的语言词汇产出与语句连贯性特征。
进一步地,上述图片描述模块提供至少一张记事图片,被测对象在给定时间内通过自己的语言来叙述图片中故事的情节。主要测试被测对象的语言产出情况(包括语言流畅与词汇量)。
进一步地,上述词语流利度模块提供至少一个主题,被测对象在1分钟内讲出尽可能多的相关词语。
进一步地,上述诗词朗诵模块提供至少一首古诗词,用于检测被测对象言语的韵律特征。
进一步地,上述句子复述模块提供多个语句,被测对象对看到的句子进行重复,本模块可以检测被测对象的言语产出情况。
进一步地,上述图片命名模块提供按照随机顺序出现的多张图片,被测对象说出图片中的事物,本模块可以评估被测对象是否具有词汇语义层面的缺陷,同时还可以评估被测对象在词汇选择方面是否存在困难。
进一步地,上述跨度测试模块提供依次出现读音相近的2至5个汉字,要求被测对象复述自己看到的内容;根据模块数据判断复述的正确性,并分析音节跨度为2-5时的正确率。对于短期记忆而言,相似性小的语音比相似性大的语音更容易记忆,本模块可据此检测被测对象的言语感知情况。本模块涉及的所有字形在测试时依次以双音节、三音节、四音节、五音节为一组,按照阴平、阳平、上声、去声、阴平、阳平、上声、去声的顺序播放。
进一步地,上述轮转发音模块提供至少一组三音节音串,要求被测对象重复三遍。用于检测被测对象对音节串联内部的协调运动是否过慢、构音功能是否异常。
进一步地,上述图片匹配模块提供多个页面;每个页面包括至少三幅图,其中有两幅图具有相关性。要求被测对象将具有相关性两幅图选出。
本发明的优点:
(1)从早期ad语言功能受损角度出发,针对汉语普通话的ad早期筛查这一研究目标,提供关于早期ad言语特异性特征的提取方案、识别方法及配套装置,具有低成本、可实时获取丰富数据、易实现大样本采集(可用于大数据分析)、可以实现远程采集分析等优势,在大范围ad早期筛查和长时间病程管理方面都有着重大应用潜力;
(2)面向患者的环节以多种言语认知任务为主,采用自动言语分析技术提取ad早期言语特征集,具有操作便捷、无侵入等特点,可在患者舒适环境下采集,在用户体验方面有着独特优势;
(3)提出一种言语特异性声学特征选择与降维的同步优化方案,该方案引入多任务学习思想,结合稳定特征选择和深度学习来实现对特征选择与分类特征子空间的同步优化;
(4)易与其他方法相结合,组成多模态辅助诊断标记物,进而作为高敏感性的ad早期筛查综合指标,提示ad高风险,提高早期ad患者的发现率,有助于实现对患者的尽早干预,为相关治疗争取更多有效时间。
附图说明
图1是本发明针对汉语普通话的早期ad言语辅助筛查系统实施例的流程图;
图2是本发明针对汉语普通话的早期ad言语辅助筛查系统的结构示意图;
图3是图片描述模块中的记事图片;
图4是图片命名模块中的图片;
图5是图片匹配模块中的页面示意图。
具体实施方式
为使本发明实施方式的目的、技术方案和优点更加清楚,下面将结合本发明实施方式中的附图,对本发明实施方式中的技术方案进行清楚、完整地描述,显然,所描述的实施方式是本发明一部分实施方式,而不是全部的实施方式。基于本发明中的实施方式,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施方式,都属于本发明保护的范围。因此,以下对在附图中提供的本发明的实施方式的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施方式。基于本发明中的实施方式,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施方式,都属于本发明保护的范围。
语言障碍是ad早期的重要特征之一,会导致患者自发语音的韵律、发音周期、发音质量以及言语处理速率等特征发生改变,其临床表现为相对非流利的自发性言语、找词困难、语速减慢、长时间的停顿及音位错误等。本发明采用客观分析手段对早期ad语言障碍在言语信息中的特异性表现进行量化,通过自动言语分析(automaticspeechanalyses,asa)和自动语音识别等技术有效检测相关言语特征,以期实现针对汉语普通话使用者的ad早期自动筛查。
参见图1-图2,一种针对汉语普通话的早期ad言语辅助筛查系统,包括主体测试单元、言语特征提取单元和识别单元。
所述主体测试单元用于对被测对象进行测试;所述言语特征提取单元用于提取被测对象的言语特征,并对该言语特征进行存储;所述识别单元用于对言语特征进行言语特征进行识别。
所述主体测试单元包括自发语音模块、图片描述模块、词语流利度模块、诗词朗诵模块、句子复述模块、图片命名模块、跨度测试模块、轮转发音模块和图片匹配模块。
进一步地,上述自发语音模块主要测试被测对象的语言词汇产出与语句连贯性特征。
具体地,本模块要求患者围绕“自我介绍”这一主题完成2分钟左右的情感自发语音,例如介绍姓名、年龄、家庭、工作、兴趣爱好。模块数据可提取语言词汇产出与语句连贯性特征。
进一步地,上述图片描述模块提供至少一张记事图片,被测对象在给定时间内通过自己的语言来叙述图片中故事的情节。主要测试被测对象的语言产出情况(包括语言流畅与词汇量)。
具体地,本模块要求患者观察一张没有文字的记事图片,并在给定时间(1-2分钟)内通过自己的语言来叙述图片中故事的情节。在本模块中,患者需要对图片故事中的人物和事件加以理解,在产出中呈现出一个有条理的框架。因此,模块可以测试患者的语言产出情况(包括语言流畅与词汇量)。本模块共包括3张图片(例如图3);其中,第一张图片的规定描述时长为2分钟左右,后两张图片的规定描述时长为1分钟左右。根据患者的实际表现,具体时长可酌情出入。
进一步地,上述词语流利度模块提供至少一个主题,被测对象在1分钟内讲出尽可能多的相关词语。
具体地,所述主题可以是水果,患者说出每类词的间隔时间,可以分析患者的长时记忆功能。
进一步地,上述诗词朗诵模块提供至少一首古诗词,用于检测被测对象言语的韵律特征。
古诗词具有良好的汉语韵律结构,可以作为检测汉语使用者发音韵律缺陷的实验材料。具体地,本模块共包含6首简单的诗词供患者阅读,例如:白日依山尽,黄河入海流。欲穷千里目,更上一层楼。
进一步地,上述句子复述模块提供多个语句,被测对象对看到的句子进行重复,本模块可以检测患者的言语产出情况。
具体地,本模块要求患者对看到的句子进行重复,模块数据用于计算患者在复述句子过程中字词之间的间隔时间。一般来说,人们对短词的记忆优于长词,长词需要更长的演练时间(rehearsaltimes)。因此,本模块可以检测患者的言语产出情况。本模块共包含14个句子,句子难度逐渐增加,例如:明天星期天。
进一步地,上述图片命名模块提供按照随机顺序出现的多张图片,被测对象说出图片中的事物,本模块可以评估患者是否具有词汇语义层面的缺陷,同时还可以评估患者在词汇选择方面是否存在困难。
具体地,本模块中将按照随机顺序出现36张图片(例如图4),要求患者说出图片中的事物,实验时间无限制,患者可自行控制切换图片。本模块可以评估患者是否具有词汇语义层面的缺陷,同时还可以评估患者在词汇选择方面是否存在困难。命名示例:长颈鹿。
进一步地,上述跨度测试模块提供依次出现读音相近的2至5个汉字(例如当跨度为2时,出现“安”“班”),要求被测对象复述自己看到的内容;根据模块数据判断复述的正确性,并分析音节跨度为2-5时的正确率。对于短期记忆而言,相似性小的语音比相似性大的语音更容易记忆,本模块可据此检测患者的言语感知情况。本模块涉及的所有字形在测试时依次以双音节、三音节、四音节、五音节为一组,按照阴平、阳平、上声、去声、阴平、阳平、上声、去声的顺序播放。
进一步地,上述轮转发音模块提供至少一组三音节音串,,例如依次发一组pa-ta-ka三音节音串,要求被测对象重复三遍。用于检测被测对象对音节串联内部的协调运动是否过慢、构音功能是否异常。
进一步地,上述图片匹配模块提供多个页面;每个页面包括至少三幅图,其中有两幅图具有相关性。要求被测对象将具有相关性两幅图选出。
具体地,本模块的每个页面会给出三幅图(例如图5),其中,上排的图与下排中的一幅图具有明显的相关性,要求患者通过键盘上的左右键来选择下排中相关性最高的图片。每一次实验完成后,都会在文件夹中生成一个表格;表格记录了患者的图片选择情况,实验完成后可以对这些记录进行分析反应时与正确率。ad患者对事物的反应时间明显大于正常人,对事物的认知能力也不如正常人,因此本模块数据可通过分析图片选择正确率与反应时间来快速直观地区分患者与正常人。
多任务有机结合能够从多个侧面反映ad引发的语言障碍,因此,本发明建立了一种多任务、多维言语特征的自动言语异常特征提取框架,以期基于ad患者与正常人的言语特征差异完成ad早期筛查。上述主体测试单元的认知发音任务结束后,对各模块生成的录音等文件信息进行分析,分别针对不同模块的言语产出提取任务相关的多维言语特征,从而获得可用于筛查ad早期症状的敏感特征集。
所述言语特征提取单元包括语音信号的自动切分模块、信号预处理模块、自动语音识别模块、文本分析模块、语音分析模块。主体测试单元中各个模块中记录得到的语音数据首先经过自动切分模块得到分段的语音,经过信号的预处理和自动语音识别模块识别为文本,文本分析和语音分析模块根据语音识别的结果计算和估计其对应的语音特征、词汇特征、语法特征、语用特征
根据语言学的范畴划分,本发明所采用的言语特征可以大致分为四类:语音特征、词汇特征、语法特征和语用特征。其中,某些由多个认知功能损害所造成言语缺陷特征,有可能同时属于以上多个层面。
语音特征描述了语言产出在声音层面的缺陷,主要包括三个方面。首先是产出词语、音素、音节的时间,语流中停顿的次数,语流中言语产出和停顿的时间,重复等,这些特征均可以衡量语流的流畅程度,其中重复还可以根据其在语流中的位置来判定其产生的原因。如果重复出现在句子的开头或结尾,可以认为患者存在理解上的问题;如果重复出现在句中,则可以认为患者想重述之前的内容。语音特征还包括梅尔频率倒谱系数、基频、音长等,其中梅尔频率倒谱系数描写了声能与频率之间的对数关系,更符合人耳对声音的感知,其高低反映了声音在声道中的回响程度。这些特征可以用来描写语音中的韵律信息,如音调轮廓、重音等。除此之外,语音错误,即发出不符合语言发音规则的语音,和没有发全音的单词也属于语音特征。
词汇特征主要表现了语言产出在词汇内容层面的特征。词汇可以通过词性来进行分类,然后依据各词类出现的频率来分析词汇的分布,同时也可以通过该频率来分析患者倾向/不倾向使用哪类词汇。例如,产出的语言中含有大量指示代词,这意味着该产出可能语义模糊。另一类词汇语义特征用来衡量词汇的丰富度和信息密度,这类特征的测量以类符形符比为主。类符指一段言语对应的文本中所使用的不同词语,而形符即所有的词形。在言语产出长度相等的前提下,类符形符比值在一定程度上体现语料库词汇的丰富程度。类符形符比值越大,说明使用的词汇变化大,词汇重复率低。
语法特征表现了语言产出在语法层面的特征,通过衡量词法及句法的复杂程度来实现。这类特征主要包括各语法成分的出现频率、相对比例和平均长度,从句的数量及长度,句法树的高度以及句子深度;也包括对句法错误的考察,例如句法结构的错误和不完整的句子。
语用特征体现了语言产出的衔接性与连贯性,属于语篇层面的变量。衔接性所关注的是句与句之间的关系,连贯性则可以分为局部连贯和整体连贯。局部连贯是指一句话与下一句话之间是否连贯,整体连贯则是指一句话的内容是否与整个语篇的主题紧密相关。此外,语用特征还包括语言产出的信息完整性。可以事先确定产出中应出现的信息,然后统计患者产出中所覆盖到的信息数量,例如统计语言产出中关键词的出现数量。对信息的定位则需借助语法分析。
所述识别单元包括特征选择模块和分类模块;特征选择模块对多维特征进行选择和优化,得到对诊断敏感的特征集;分类模块使用优化的特征集,并运用多任务深度置信网络算法(multi-taskdbn),利用任务相关性联合提高对分类任务的预测;该网络以分类任务为主任务,而mmse和moca评分将作为相关任务进行训练,以帮助提高分类任务的预测性能。根据预测结果最终完成对早期ad患者的诊断和筛查。
本发明采用一种基于多任务深度学习(multi-taskdeeplearning,mdtl)的框架实现ad患者的自动分类。该结构包括两级模块,上级模块为基于稳定选择的多任务深度学习的特征选择,下级模块为elm或svm分类器进行分类。首先,我们将对上述与ad语言脑功能网络相关高维声学特征进行归一化处理,应用lasso估计和稳定特征选择(stabilityselection)技术进一步优化,实现对诊断敏感的特征集。其次,本发明引入稳定特征选择技术,将重复50次不同参数λ参数取值的lasso估计,特征向量集中的每个参数的可能性表述为在这50次lasso估计中出现的频率之和,选择使得稳态特征集参数变化很小的阈值t确定特征集。最后,本发明利用多任务学习(multi-tasklearning)原理,构建一种多任务深度置信网络(multi-taskdbn),利用任务相关性联合提高对分类任务的预测。该网络以分类任务为主任务,而mmse和moca评分将作为相关任务进行训练,以帮助提高分类任务的预测性能。
因此,基于言语特征集的具体匹配结果,可以实现对患者语言产出情况的识别。如果经实验任务采集到的患者言语特征集与ad识别模型中置入的标准特征集匹配度较高,则可以认为该患者疑似早期ad。
以上所述仅为本发明的实施例,并非以此限制本发明的保护范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的系统领域,均同理包括在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!