信息处理设备和信息处理方法与流程
本技术涉及信息处理设备和信息处理方法,并且特别地涉及使得能够更准确地估计用户的话语的意图的信息处理设备和信息处理方法。
背景技术:
近年来,已经开始在各个领域中使用作出与用户话语对应的响应的话语对话系统。话语对话系统不仅需要识别用户话语的语音,而且需要通过估计用户话语的意图来作出适当的响应。
例如,专利文献1公开了通过使用语言语法将输入的句子划分为元素并且对所划分的元素进行语义分析来增强长句的分析能力的技术。
引用列表
专利文献
专利文献1:jph6-295308a
技术实现要素:
技术问题
然而,在使用上述专利文献1中公开的语言语法来划分输入的句子中,存在用户的话语中包括的各种表达未能以用户的意图为单位被正确地划分的可能性。因此,当用户说出包括多个意图的长句、复杂句等时,有时无法准确地估计用户的话语的意图。
鉴于这种情况已经设计了本技术,并且本技术使得能够更准确地估计用户的话语的意图。
问题的解决方案
本技术的方面的信息处理设备是一种包括以下单元的信息处理设备:检测单元,其被配置成基于在用户的话语期间获得的识别的结果来检测用户的话语的断点;以及估计单元,其被配置成基于通过在话语的所检测到的断点处划分话语句子而获得的经划分话语句子的语义分析的结果来估计用户的话语的意图。
本技术的方面的信息处理方法是一种信息处理设备的信息处理方法,该信息处理方法包括:信息处理设备基于在用户的话语期间获得的识别的结果来检测用户的话语的断点;以及基于通过在话语的所检测到的断点处划分话语句子而获得的经划分话语句子的语义分析的结果来估计用户的话语的意图。
在本技术的方面的信息处理设备和信息处理方法中,基于在用户的话语期间获得的识别的结果来检测用户的话语的断点;以及基于通过在话语的所检测到的断点处划分话语句子而获得的经划分话语句子的语义分析的结果来估计用户的话语的意图。
根据本技术的方面的信息处理设备可以是独立设备,或者可以是构成一个设备的内部块。
发明的有益效果
根据本技术的方面,可以更准确地估计用户的话语的意图。
此外,此处提到的有益效果不一定是限制性的,并且可以获得本公开内容中描述的任何有益效果。
附图说明
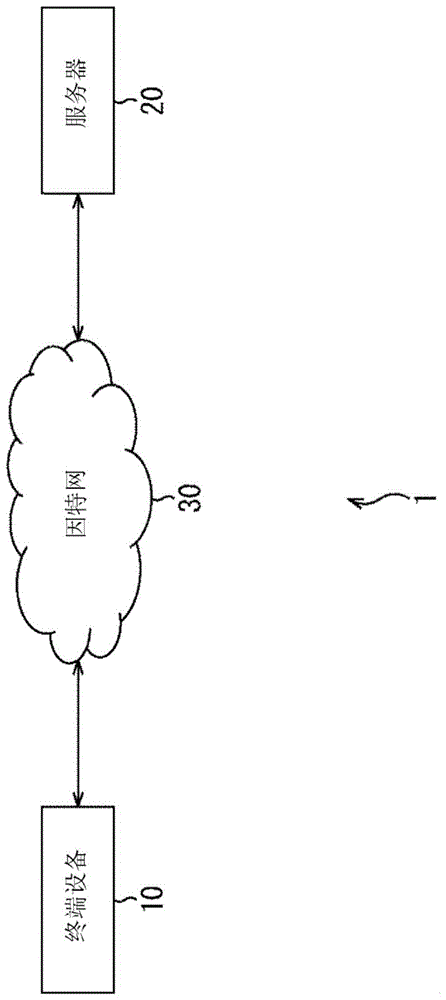
图1是示出应用了本技术的话语对话系统的配置的示例的框图。
图2是示出应用了本技术的话语对话系统的功能配置的示例的框图。
图3是描述话语对话处理的流程的流程图。
图4是示出在使用第一条件的情况下进行的用户话语的断点的检测的示例的图。
图5是示出在使用第一条件的情况下进行的用户话语的断点的检测的示例的图。
图6是示出在使用第二条件的情况下进行的用户话语的断点的检测的示例的图。
图7是示出用户的意图估计的第一示例的图。
图8是示出用户的意图估计的第二示例的图。
图9是示出用户的意图估计的第三示例的图。
图10是示出用户的意图估计的第四示例的图。
图11是描述整个话语的主体确定处理的流程的流程图。
图12是描述划分单元中的取消处理的流程的流程图。
图13是示出计算机的配置示例的图。
具体实施方式
在下文中,将参照附图描述本技术的实施方式。此外,将按以下顺序给出描述。
1.本技术的实施方式
2.修改示例
3.计算机的配置
<1.本技术的实施方式>
(话语对话系统的配置示例)
图1是示出应用了本技术的话语对话系统的配置的示例的框图。
话语对话系统1包括安装在诸如用户家的本地侧并且用作话语对话服务的用户接口的终端设备10,以及安装在诸如数据中心的云端侧并且执行用于实现话语对话功能的处理的服务器20。在话语对话系统1中,终端设备10和服务器20经由因特网30彼此连接。
例如,终端设备10是可以连接至诸如家庭局域网(lan)的网络的扬声器,并且还被称为智能扬声器、家庭代理等。除了音乐的重放以外,这种类型的扬声器例如具有与用户进行话语对话、诸如照明设备和空调的设备的语音操作等功能。
此外,终端设备10不限于扬声器,并且可以形成为例如游戏机、诸如智能电话和移动电话的移动设备、平板电脑等。
通过经由因特网30与服务器20协作,终端设备10可以向用户提供话语对话服务(的用户接口)。
例如,终端设备10收集用户发出的语音(用户话语),并且经由因特网30将语音数据发送至服务器20。另外,终端设备10经由因特网接收从服务器20发送的处理数据,并且输出诸如与处理数据对应的语音的信息。
服务器20是提供基于云的话语对话服务的服务器。
例如,服务器20基于经由因特网30从终端设备10发送的语音数据进行诸如话语识别处理和语义分析处理的处理,并且经由因特网30将与处理结果对应的处理数据发送至终端设备10。
(话语对话系统的功能配置示例)
图2是示出图1中所示的话语对话系统1的功能配置的示例的框图。
在图2中,话语对话系统1包括语音输入单元101、图像输入单元102、传感器单元103、话语识别单元104、图像识别单元105、传感器识别单元106、话语断点检测单元107、语义分析单元108、多个意图估计单元109、任务执行单元110、音效重放单元111、话语合成处理单元112、输出图像处理单元113、语音输出单元114、图像输出单元115和存储单元116。
例如,语音输入单元101包括诸如麦克风的语音输入器件。语音输入单元101将通过用户2发出的语音转换成电信号而获得的语音数据提供至话语识别单元104。
例如,图像输入单元102包括诸如包括图像传感器的摄像机的图像输入器件。图像输入单元102将通过捕获诸如用户2的对象的图像而获得的图像数据提供至图像识别单元105。
例如,传感器单元103包括诸如各种类型的传感器的传感器器件。传感器单元103执行对用户2、用户2周围事物等的感测,并且将与感测结果对应的传感器数据提供至传感器识别单元106。
此处,作为传感器单元103,例如可以包括检测诸如吸气、脉搏跳动、指纹和虹膜的生物信息的生物传感器,检测磁化场(磁场)的大小和方向的磁传感器,检测加速度的加速度传感器,检测角度(姿态)、角速度和角加速度的陀螺传感器,检测接近的物体的接近传感器等。
另外,传感器单元103可以是附接至用户2的头部并且通过测量电势等来检测脑波的脑波传感器。此外,传感器单元103可以包括用于测量周围环境的传感器,例如检测温度的温度传感器、检测湿度的湿度传感器和检测周围事物的亮度的环境光传感器,以及用于检测诸如全球定位系统(gps)信号的位置信息的传感器。
基于从语音输入单元101提供的语音数据,话语识别单元104执行话语识别处理,并且将话语识别的结果提供至话语断点检测单元107。
在话语识别处理中,例如,通过参考用于话语-文本转换的数据库等执行将来自语音输入单元101的语音数据转换成文本数据(话语句子)的处理。
另外,在话语识别处理中,例如,对语音数据执行用于提取在后续话语断点检测处理中使用的话语识别的结果的处理,诸如分析来自语音输入单元101的语音数据(的信号波形)的处理。
此外,在以下描述中,在由话语识别单元104执行的话语识别处理中,用于获得用户2的话语的文本数据(话语句子)的话语识别将被描述为“话语识别(asr:自动话语识别)”,并且将其与用于在后续话语断点检测处理中检测话语的断点的话语识别结果区分开。此外,作为由话语识别处理执行的话语识别(asr)的结果而获得的文本数据将被描述为“话语句子”。
基于从图像输入单元102提供的图像数据,图像识别单元105执行图像识别处理,并且将图像识别的结果提供至话语断点检测单元107。在图像识别处理中,对图像数据执行用于提取在后续话语断点检测处理中使用的图像识别的结果的处理。
基于从传感器单元103提供的传感器数据,传感器识别单元106执行传感器识别处理,并且将传感器识别的结果提供至话语断点检测单元107。在传感器识别处理中,对传感器数据执行用于提取在后续话语断点检测处理中使用的传感器识别的结果的处理。
将来自话语识别单元104的话语识别的结果、来自图像识别单元105的图像识别的结果和来自传感器识别单元106的传感器识别的结果与作为由话语识别单元104执行的话语识别(asr)的结果的话语句子一起提供至话语断点检测单元107。
基于话语识别的结果、图像识别的结果和传感器识别的结果,话语断点检测单元107对话语句子执行话语断点检测处理,并且将话语断点检测的结果提供至语义分析单元108。另外,话语断点检测单元107将话语断点检测的结果提供至音效重放单元111、话语合成处理单元112或输出图像处理单元113。
基于话语识别的结果、图像识别的结果或传感器识别的结果中的至少一个识别的结果,话语断点检测处理例如在话语暂停时间超过固定时间时、在检测到语调短语的边界时、在检测到支吾或补白时等检测话语的断点。
此外,在以下描述中,通过使用由话语断点检测处理检测到的话语断点位置作为边界对作为话语识别(asr)的结果获得的话语句子进行划分而获得的文本数据将被描述为“经划分话语句子”。另外,稍后将参照图4至图6等描述话语断点检测处理的细节。
基于从话语断点检测单元107提供的话语断点检测的结果(经划分话语句子),语义分析单元108执行语义分析处理,并且将语义分析的结果提供至多个意图估计单元109。
在语义分析处理中,例如,通过参考用于话语语言理解的数据库等执行将通过对作为话语识别(asr)的结果获得的以自然语言表示的话语句子进行划分而获得的经划分话语句子(文本数据)转换成对于机器(系统)可理解的表示的处理。
此处,作为语义分析的结果,话语的含义以用户期望执行的“意图(意向)”以及用作其参数的“实体信息(实体)”的形式表示。此外,在以下描述中,语义分析处理也将被描述为“语义分析(nlu:自然语言理解)”。另外,在以下描述中,通过将作为针对每个经划分话语句子执行的语义分析(nlu)的结果而获得的意图描述为“意图(意向)”或“意向”,意图将与用户2的话语意图区分开。
基于从语义分析单元108提供的语义分析(nlu)的结果,多个意图估计单元109执行意图估计处理,并且将意图估计的结果提供至任务执行单元110。
在意图估计处理中,基于针对每个经划分话语句子执行的语义分析(nlu)结果(意图、实体)来估计用户2的话语的一个或多个意图。此外,此处,在估计用户2的话语的意图时,例如可以使用其他类型的信息,诸如每个经划分话语句子的话语速率。另外,稍后将参照图7至图12等描述意图估计处理的细节。
此外,因为经划分话语句子通过话语断点检测单元107被顺序地输入至语义分析单元108,并且通过将语义分析(nlu)的结果(临时地)记录(积累)到存储单元116中来获得了针对经划分话语句子中的每一个的意图(意向)和实体信息(实体),因此多个意图估计单元109可以获取记录(积累)在存储单元116中的每个经划分话语句子的语义分析的结果(意图、实体)。
基于从多个意图估计单元109提供的意图估计的结果,任务执行单元110执行任务执行处理,并且将任务执行的结果提供至话语合成处理单元112和输出图像处理单元113。
基于从话语断点检测单元107提供的话语断点检测的结果,音效重放单元111执行音效重放处理,并且将音效重放的结果提供至语音输出单元114。
基于从话语断点检测单元107提供的话语断点检测的结果,话语合成处理单元112执行话语合成处理,并且将话语合成的结果提供至语音输出单元114。另外,基于从任务执行单元110提供的任务执行的结果,话语合成处理单元112执行话语合成处理,并且将话语合成的结果提供至语音输出单元114。
基于从话语断点检测单元107提供的话语断点检测的结果,输出图像处理单元113执行输出图像处理,并且将输出图像的结果提供至图像输出单元115。另外,基于从任务执行单元110提供的任务执行的结果,输出图像处理单元113执行输出图像处理,并且将输出图像的结果提供至图像输出单元115。
例如,语音输出单元114包括诸如扬声器和耳机的语音输出器件。基于从音效重放单元111提供的音效重放的结果,或者从话语合成处理单元112提供的话语合成的结果,语音输出单元114输出与这些语音数据对应的声音作为系统响应(响应)。
例如,图像输出单元115包括诸如液晶显示器或有机el显示器的图像输出器件。基于从输出图像处理单元113提供的输出图像的结果,图像输出单元115输出(显示)与图像数据对应的图像作为系统响应(响应)。
话语对话系统1具有上述配置。
此外,在图2中的话语对话系统1中,从语音输入单元101至存储单元116的结构元件可以任意地并入至终端设备10(图1)和服务器20(图1)中的任一设备中。例如,可以采用以下配置。
更具体地,在用作用户接口的语音输入单元101、图像输入单元102、传感器单元103、语音输出单元114和图像输出单元115可以并入至设置在本地侧的终端设备10中的同时,具有其他功能的话语识别单元104、图像识别单元105、传感器识别单元106、话语断点检测单元107、语义分析单元108、多个意图估计单元109、任务执行单元110、音效重放单元111、话语合成处理单元112、输出图像处理单元113和存储单元116可以并入至设置在云端侧的服务器20中。
此时,话语识别单元104、图像识别单元105、传感器识别单元106、话语断点检测单元107、语义分析单元108、多个意图估计单元109、任务执行单元110、音效重放单元111、话语合成处理单元112和输出图像处理单元113例如通过服务器20的执行程序的中央处理单元(cpu)来实现。另外,例如,存储单元116包括随机存取存储器(ram),随机存取存储器(ram)是一种易失性存储器。
另外,为了经由因特网30交换数据,终端设备10和服务器20各自包括包含通信接口电路等的通信i/f,其未在附图中示出。利用这种配置,在用户2的话语期间,终端设备10和服务器20可以经由因特网30执行通信,并且在服务器20侧,可以基于来自终端设备10的识别结果来执行诸如话语断点检测处理的处理。
此外,终端设备10可以具有以下配置。例如,提供包括按钮、键盘等的输入单元,使得可以获得与用户的操作对应的操作信号。可替选地,图像输出单元115形成为其中集成有触摸传感器和显示单元的触摸面板,使得可以获得与用户使用手指或触摸笔(触控笔)执行的操作对应的操作信号。
(话语对话处理的流程)
接下来,将参照图3中的流程图描述由话语对话系统1执行的话语对话处理的流程。
当存在于终端设备10附近的用户2开始话语时,执行话语对话处理。此外,此处,当用户2开始话语时,例如,可以通过使用特定关键词(所谓的激活词)的呼叫、通过拍手产生的爆破音等发出用于开始话语的明确指令。
在步骤s11中,语音输入单元101通过收集由用户2发出的语音来接收用户2的话语。
在步骤s12中,诸如话语识别单元104的识别单元基于来自诸如语音输入单元101的在前输入单元的数据在用户的话语期间执行识别处理。
此处,例如,话语识别处理由话语识别单元104基于来自语音输入单元101的语音数据执行,并且获得话语识别(asr)的结果。另外,在由话语识别单元104执行的话语识别处理、由图像识别单元105执行的图像识别处理和由传感器识别单元106执行的传感器识别处理中,执行至少一种类型的识别处理,并且获得在后续话语断点检测处理(s13)中使用的识别结果。
在步骤s13中,基于在步骤s12中的处理中获得的识别结果(每个输入单元的识别结果),话语断点检测单元107对作为话语识别(asr)的结果而获得的话语句子执行话语断点检测处理,并且检测用户2的话语的断点。
在步骤s14中,语义分析单元108执行在步骤s13中的处理中获得的话语的断点位置处划分的经划分话语句子的语义分析处理。
通过语义分析处理,执行将通过对作为话语识别(asr)的结果获得的以自然语言表示的话语句子进行划分而获得的经划分话语句子(文本数据)转换成对于机器(系统)可理解的表示的处理。由此获得经划分话语句子的语义分析(nlu)的(意向、实体)的结果。
在步骤s15中,话语合成处理单元112生成指示在步骤s13中的处理中获得的话语的断点位置处的话语意图的接收的反馈信息(例如,说“是”的语音),并且从语音输出单元114输出所生成的反馈信息。从而将反馈信息作为系统响应(响应)输出(呈现)至用户2。
此外,此处,除了输出由话语合成处理单元112合成的语音以外,作为反馈信息,例如,可以输出由音效重放单元111重放的音效或由输出图像处理单元113生成的输出图像。
在步骤s16中,基于由语音输入单元101收集的语音,确定用户2的话语是否已经完成。
在步骤s16中确定用户2的话语未完成的情况下,处理返回至步骤s11,并且重复上述步骤s11至步骤s15中的处理。
更具体地,通过重复步骤s11至步骤s15中的处理,针对用户2的话语的相应断点获得的经划分话语句子被顺序地输入(经历)至语义分析处理,并且针对经划分话语句子中的每一个,获得语义分析(nlu)的结果(意向、实体)。由此,关于用户2的话语,将每个经划分话语句子的意图(意向)和实体信息(实体)作为语义分析(nlu)结果记录(积累)至存储单元116中。
接着,在步骤s16中确定用户2的话语已经完成的情况下,处理前进至步骤s17。
在步骤s17中,基于通过重复步骤s11至步骤s16中的处理而顺序记录的语义分析(nlu)的结果(意向、实体),多个意图估计单元109执行意图估计处理,并且估计用户2的话语的意图。
在步骤s18中,基于在步骤s17中的处理中获得的意图估计的结果,任务执行单元110执行任务执行处理,并且执行系统中的与用户2的话语的意图对应的任务。此处,基于用户2的话语的意图估计结果,执行一个或多个任务。
在步骤s19中,话语合成处理单元112生成指示在步骤s18中的处理中执行的系统的任务执行的结果的任务执行信息(例如,说任务已经正常完成的语音),并且从语音输出单元114输出所生成的任务执行信息。从而将任务执行信息作为系统响应(响应)输出(呈现)至用户2。
此外,此处,除了输出由话语合成处理单元112合成的语音以外,作为任务执行信息,例如,可以呈现由输出图像处理单元113生成的输出图像(例如,指示任务已经正常完成的图像)等。
在上文中,已经描述了话语对话处理的流程。
在由话语对话系统1执行的话语对话处理(图3)中,通过诸如麦克风的语音输入单元101对用户2的话语进行话语识别处理,并且将话语的内容转换成文本并且发送至话语断点检测处理。在用户2的话语期间不断地执行话语识别处理,并且将在话语期间可以识别的文本数据(经划分话语句子)顺序地发送至话语断点检测处理。
另外,话语识别处理不仅可以将用户2的话语内容转换成文本,而且可以执行输入语音的节奏的检测,诸如话语的音调提取,并且将检测到的节奏顺序地发送至话语断点检测处理。
此外,除了用户2的话语的语音以外,可以通过诸如摄像机的图像输入单元102对用户2的捕获的图像进行图像识别处理,并且可以识别诸如用户2的嘴或颈部的运动等的姿势。可替选地,可以通过传感器单元103对用户2的生物信息等进行传感器识别处理,并且可以识别用户2的呼吸状况等。
在用户2的话语期间不断地执行这些类型的识别处理,并且将识别的结果顺序地发送至话语断点检测处理。
接着,在由话语对话系统1执行的话语对话处理(图3)中,基于在话语期间用户2的状态、姿势等的识别结果来检测话语的断点,对在断点位置经划分话语句子顺序地执行语义分析(nlu),基于作为语义分析的结果而获得的多个意图(意向)和多条实体信息(实体)来估计用户的一个或多个意图,并且执行与估计结果对应的任务(动作)。
此处,例如,作为在话语期间用户2的状态或姿势,存在话语的小的暂停、嘴或颈部的运动、生物信息、支吾或补白、语调等。因此,在话语对话系统1中,通过检测用户的话语特性,并且以期望理解用户2的意图为单位划分话语句子来更准确地估计用户2的话语的意图。
(话语断点检测处理)
接下来,将参照图4至图6等描述由话语断点检测单元107执行的话语断点检测处理的详细内容。
通过在用户2的话语期间基于从话语识别单元104、图像识别单元105和传感器识别单元106顺序发送的识别结果来执行话语断点检测处理,话语断点检测单元107检测用户2的话语的断点位置。
在话语断点检测处理中,例如,基于下面列出的条件(a)至条件(g)中的一个条件或多个条件的组合,检测用户2的话语的断点的时刻。
(a)当话语暂停的时间超过固定时间时
(b)当检测到语调短语的边界时
(c)当检测到支吾或补白时
(d)当检测到呼吸的吸入时
(e)当检测到嘴不动的时间超过固定时间时
(f)当检测到视线的大运动时
(g)当检测到身体(的一部分)的大运动时
此外,上述条件(a)至条件(g)是用于检测话语断点的所列出的示例性条件,并且可以使用另外的条件,只要可以检测用户2的话语断点的时刻即可。
(a)第一条件
此处,在使用上面作为(a)列出的第一条件的情况下,“当话语暂停的时间超过固定时间时”,检测话语的断点。图4示出了这种情况的具体示例。
在图4中,在用户2顺序说出“好的,”和“从十点,”的情况下,当从说出“好的,”的话语结束至说出“从十点,”的话语开始的时间超过非常短的时间(例如,大约几百毫秒)时,话语对话系统1检测用户2的话语的断点,并且做出说“是”的响应。
更具体地,在话语对话系统1中,在用户2的话语期间顺序输出话语识别(asr)的结果(话语的文本数据),并且在作为话语识别(asr)的结果而被顺序输出的文本数据(经划分话语句子)的中间结果在超过阈值(例如300ms)的时间内没有被更新的情况下,检测话语的断点。然后,在检测到话语的断点的情况下,话语对话系统1可以通过将从前一时间的断点位置至此时的断点位置的文本数据(经划分话语句子)的中间结果输入至语义分析处理来获得意图(意向)和实体信息(实体)作为语义分析(nlu)的结果。
在图4中,在时间t11至时间t12中,使用说“好的,”的话语执行话语识别处理,并且更新话语识别(asr)的结果的输出,但是在时间t12之后停止话语识别(asr)的结果的输出的更新,并且即使时间超过阈值(阈值时间)也不执行话语识别(asr)的结果的输出的更新。因此,在时间t13处,检测到用户2的话语的断点,将说“好的,”的经划分话语句子输入至语义分析处理作为文本数据的中间结果,以及获得语义分析(nlu)的结果。然后,在时间t14处,作出了说“是”的响应。
之后,在时间t15至时间t16中,使用说“从十点,”的话语执行话语识别处理,并且更新话语识别(asr)的结果的输出。
另外,例如,在图5中,在用户2执行说“好的,让我们从十点开始,在通常位置…,”的话语的情况下,话语对话系统1检测由作为话语识别(asr)的结果而获得的“好的,”与“让我们从十点开始,”之间的微小的暂停指示的话语的断点。然后,在话语对话系统1中,将说“好的,”的经划分话语句子输入至语义分析处理,并且获得语义分析(nlu)的结果。
另外,话语对话系统1检测由作为话语识别(asr)的结果而获得的“让我们从十点开始,”与“在通常位置…,”之间的微小的暂停指示的话语的断点。然后,在话语对话系统1中,将说“让我们从十点开始,”的经划分话语句子输入至语义分析处理,并且获得语义分析(nlu)的结果。
此外,以类似的方式,在那之后,当检测到说“在通常位置…,”的话语的断点时,在话语对话系统1中,将说“在通常位置…,”的经划分话语句子输入至语义分析处理,其未在附图中示出。
以这种方式,在使用上述第一条件(a)的情况下,例如,当在用户2的话语期间诸如微小的暂停的话语暂停时间超过固定时间时,话语断点检测单元107基于由话语识别单元104执行的话语识别的结果来检测用户2的话语的断点。
(b)第二条件
在使用上述第二条件(b)的情况下,“当检测到语调短语的边界时”,检测话语的断点。图6示出了这种情况的具体示例。
在图6中,在用户2执行说“好的,让我们从十点开始。我将在通常位置等待。以这种方式回复。”的话语的情况下,话语对话系统1基于作为话语识别(asr)的结果而获得的“好的,”与“让我们从十点开始。”之间的话语语音的音调的自然下降来检测语调短语的边界(呼吸的吸入)。
此处,如图6中的“音调”的波形所指示的,如果注意说“好的,”的话语,则由于用户2的话语的音调的包络波形(例如,与调值和基本频率f0对应)在话语开始时的音调上升,且在重音内核之后自然下降,因此通过检测音调的自然下降,可以检测语调短语的边界(呼吸的吸入)。
此外,作为与音调对应的物理量的基本频率f0沿时间轴趋于逐渐下降,并且该趋势被称为自然下降(下降)。
然后,在话语对话系统1中,基于说“好的,”的话语的语调短语的边界来检测话语的断点,将说“好的,”的经划分话语句子输入至语义分析处理,并且获得语义分析(nlu)的结果。
另外,以类似的方式,如果注意说“让我们从十点开始”和“我将在通常位置等待。以这种方式回复。”的话语,则在话语对话系统1中,检测这些话语中的每一个的音调的自然下降,并且基于语调短语的边界来检测话语的断点。然后,在话语对话系统1中,将说“让我们从十点开始”的经划分话语句子和说“我将在通常位置等待。以这种方式回复。”的经划分话语句子顺序地输入至语义分析处理,并且为这些经划分话语句子中的每一个获得语义分析(nlu)的结果。
此外,同样在图6中,当检测到用户2的话语的断点时,由话语对话系统1作出说“是”的响应。
以这种方式,在使用上述第二条件(b)的情况下,例如,当在用户2的话语期间基于由话语识别单元104执行的话语识别的结果检测到语调短语的边界(呼吸的吸入)时,话语断点检测单元107检测用户2的话语的断点。
(c)第三条件
在使用上述第三条件(c)的情况下,例如,当在用户2的话语期间基于由话语识别单元104执行的话语识别的结果检测到支吾或补白(例如“呃”、“嗯”等)时,话语断点检测单元107检测用户2的话语的断点。
此外,在使用英语作为日语以外的语言的情况下,例如,当检测到使用诸如“如”、“你知道”和“我的意思”的特定措辞的补白时,检测用户2的话语的断点。
(d)第四条件
在使用上述第四条件(d)的情况下,例如,当在用户2的话语期间基于由传感器识别单元106执行的传感器识别的结果检测到呼吸着的用户2的吸气(呼吸的吸入)时,话语断点检测单元107检测用户2的话语的断点。作为此处使用的传感器识别的结果,例如,可以使用从形成为生物传感器的传感器单元103获得的传感器数据的识别结果。
(e)第五条件
在使用上述第五条件(e)的情况下,例如,当在用户2的话语期间从关于图像的信息获得的用户2的嘴不动的时间超过固定值(阈值)时,话语断点检测单元107基于由图像识别单元105执行的图像识别的结果来检测用户2的话语的断点。
(f)第六条件
在使用上述第六条件(f)的情况下,例如,当在用户2的话语期间根据关于图像的信息检测到用户2的视线的大运动(例如,目光接触等)时,基于由图像识别单元105执行的图像识别的结果,话语断点检测单元107检测用户2的话语的断点。
(g)第七条件
在使用上述第七条件(g)的情况下,例如,当在用户2的话语期间基于由传感器识别单元106执行的传感器识别的结果检测到用户2的身体的一部分(例如,颈部等)的大运动时,话语断点检测单元107检测用户2的话语的断点。作为此处使用的识别的结果,例如,可以使用从形成为附接至用户2的身体诸如头部的加速度传感器的传感器单元103获得的传感器数据的识别结果。
(话语断点检测的另外的示例)
此外,作为除了上述条件(a)至条件(g)以外的另外的条件,例如,当获得以下识别的结果时,话语对话系统1可以基于识别的结果来检测用户2的话语的断点。
作为第一另外的示例,当用户2不看显示在终端设备10(的图像输出单元115)上的显示信息时,或者当用户2看着这些进行确认时,可以检测用户2的话语的断点。例如,此处,显示信息包括诸如图标(例如麦克风图标)和用户的话语识别结果(例如话语识别(asr)或语义分析(nlu)的结果)的信息。
作为第二另外的示例,当用户2的话语的音量、调值或速率的变化量大时,可以检测用户2的话语的断点。此处,例如,语音音量等与音量对应。另外,例如,速率的变化量包括语音快速变为大声或静音、音调变化或说话速率(话语速度)变化。
作为第三另外的示例,当在用户2的话语中包括延长单词结尾的表达时,可以检测用户2的话语的断点。此处,延长单词结尾的表达包括例如元音的持续时间长的表达,诸如“是…啊”或“然后…啊”(“啊”指示延长的声音)。
作为第四另外的示例,例如,由于基于语调模式的话语的断点有时取决于语言或地区而变化,因此可以根据关于用户的信息(例如,服务的登录信息等)获取区域的属性,并且取决于区域,可以在改变要采用的模式的同时检测用户2的话语的断点。
另外,通过用户单独地对系统设置基于另外的因素使话语分离的语调模式,当系统将在下一次或后续的时间使用时,可以使用个性化的模式检测话语的断点。
此外,当在用户2的话语期间根据视线或话语内容检测到与除了终端设备10以外的另外的目标(例如,诸如家人或朋友的另外的用户)说话时,话语对话系统1可以基于识别的结果停止话语断点的检测和积累,并且可以停止向用户2返回响应。
(语言语法的使用)
在话语对话处理中,当基于正在说话的用户2的状态、姿势等的识别结果检测到话语的断点时,在由于仅使用用户2的状态或姿势分离的长的经划分话语句子使作为语义分析(nlu)的结果未能获得意图(意向)的情况下,可以组合使用使用语言语法的话语句子的划分。
例如,在将基于用户2的状态、姿势等的识别结果分离的经划分话语句子输入至语义分析处理,并且作为语义分析(nlu)的结果而获得的意图(意向)的可靠性分数等于或小于固定值的情况下,通过向语义分析处理输入通过使用其中修改距离远的经划分话语句子中的一部分作为边界进一步执行划分而获得的经划分话语句子,可以获得具有更高的可靠性分数的意图(意向)。
例如,在用户2执行说“调高音量并返回至音乐的开始”的话语的情况下,当使用上述条件未能检测到话语的断点时(当话语的断点的检测准确性差时),因为说“返回”的话语的修改远离说“调高音量”的话语,因此使用语言语法可以在说“调高音量”的话语之后检测话语的断点。
例如,以上述方式,在话语对话系统1中,当用户2开始话语时,由话语断点检测单元107使用上述条件诸如第一条件至第七条件中的一个条件或者多个条件的组合来执行话语断点检测处理。另外,在话语对话系统1中,当由话语断点检测处理检测到话语的断点时,将从前一时间的断点位置至此时的断点位置的文本数据(经划分话语句子)的中间结果输入至由语义分析单元108执行的语义分析处理。
然后,在话语对话系统1中,直到用户2完成话语,每次检测到话语的断点时顺序地执行经划分话语句子的语义分析处理,并且记录(积累)相应获得的经划分话语句子中的每一个的语义分析(nlu)的结果(意图、实体)。
以这种方式,通过在用户2的话语期间顺序地执行语义分析处理,并且记录(积累)相应获得的语义分析(nlu)的结果(意图、实体),与在用户2话语完成之后对所有话语句子执行语义分析处理的情况相比,获得了加速话语对话系统1的响应的效果。
(话语断点处的反馈信息输出处理)
接下来,将描述在话语断点处的由音效重放单元111、话语合成处理单元112或输出图像处理单元113执行的反馈信息输出处理的详细内容。
同时,通过无意识地执行在断点处作出暂停的以使话语意图对于其他人可理解的姿势,人提示指示接收到此人的意图的响应动作(例如衬托型反馈行为(backchanneling)等)。
另外,在人可以理解由其他人正在说的内容或其意图的时刻,人执行指示接收到意图的响应动作(例如衬托型反馈行为等)。通过话语对话系统1执行(模拟)与人的响应动作(理解动作)对应的操作,用户可以在话语期间接收指示系统理解话语的反馈。
此处,在话语对话系统1中,当识别出用户的用于检测话语的断点的状态或姿势时,通过向用户2输出语音或图像执行反馈。因此,用户2更容易向话语对话系统1说出后续的话语内容。
例如,在上述的图4和图6中,已经例示了话语合成处理单元112在检测到用户2的话语的断点的时刻输出说“是”的衬托型反馈行为作为系统话语的情况。在输出这样的衬托型反馈行为作为响应(系统话语)的情况下,当作为与话语的断点对应的每个经划分话语句子的语义分析(nlu)的结果获得意图(意向)时,可以输出指示接收的“是”,当未获得意图(意向)时,可以输出指示不能理解话语的“什么?”作为响应(系统话语)。
利用该配置,在用户2对话语对话系统1执行话语的情况下,当从话语对话系统1执行接收的衬托型反馈行为时,用户2可以容易地执行后续的话语。另一方面,当从话语对话系统1执行指示不能理解话语的衬托型反馈行为时,用户2可以使用不同的措辞对话语进行改述。
此外,例如,上述的“作为每个经划分话语句子的语义分析(nlu)的结果未获得意图(意向)的时间”与意图不是遵循对话的语境的意图(意向)的情况、意图(意向)的可靠性分数低于固定值(阈值)的情况等对应。
另外,在上述示例中已经描述了输出诸如“是”的衬托型反馈行为作为响应(系统话语)的情况,但是可以通过例如音效重放单元111输出诸如“哗哗声”的音效来向用户2通知反馈信息。
此时,在音效重放单元111中,音效的类型可以在作为每个经划分话语句子的语义分析(nlu)的结果获得意图(意向)的时间与作为每个经划分话语句子的语义分析(nlu)的结果未获得意图(意向)且未能理解话语的时间之间变化。
此外,可以通过例如输出图像处理单元113生成诸如化身的图像来向用户2通知反馈信息。此处,通知不限于图像的显示,并且可以使用另外的方法,例如只要该方法可以在视觉上向用户2通知反馈信息,诸如发光二极管(led)的发光图案或基于颜色的视觉信息。
此时,在输出图像处理单元113中,显示的图像的类型可以在作为每个经划分话语句子的语义分析(nlu)的结果获得意图(意向)的时间与作为每个经划分话语句子的语义分析(nlu)的结果未获得意图(意向)且未能理解话语的时间之间变化。
通常,基于在大约一秒或更长时间内未执行用户2的话语的事实在话语对话系统1侧确定用户2的话语的完成。通过检测用户2的话语的断点,假设用户2保持等待很长时间,并且当没有从话语对话系统1发出反馈信息的通知时,在话语的完成等待期间,用户2可能不能看到其本身的话语是否已经被接收,变得焦虑且执行不必要的改述等。
为了解决该问题,通过音效重放单元111、话语合成处理单元112或输出图像处理单元113在话语断点处执行反馈信息输出处理,以及在用户2的话语断点处提早输出反馈信息,用户2可以识别出已经接收到其本身的话语。因此,用户2可以避免执行不必要的改述。
(反馈信息输出的另外的示例)
此外,上述反馈信息输出是示例,并且在话语对话系统1中可以使用各种类型的反馈,只要根据用户2的话语执行反馈即可。
例如,可以通过用户2佩戴的设备(例如智能电话、可佩戴设备等)振动来通过触觉通知反馈信息。此时,可以根据反馈的内容变化振动的类型。而且,另外,可以通过将精细电流流至用户2的身体来施加刺激。
另外,例如,在从先前断点位置开始的特定时间段内未检测到话语的断点并且识别出话语时间长的情况下,可以呈现用于提示用户2作出话语断点的反馈信息。利用这种配置,可以提早呈现反馈信息,并且可以使经划分话语句子的划分单元变小。因此,可以提高由语义分析单元108执行的后续的语义分析处理的分析准确性。
此处,作为用于提早呈现反馈信息的方法,例如,当用户2的话语时间长时,通过在图像输出单元115上显示的拟人代理点头,可以提示用户2作出话语的断点。此外,拟人代理是拟人话语对话代理,其使用例如计算机图形(cg)角色、视频化身等的运动图像与用户进行话语对话。
(意图估计处理和任务执行处理)
接下来,将参照图7至图10描述由多个意图估计单元109执行的意图估计处理和由任务执行单元110执行的任务执行处理的详细内容。
多个意图估计单元109通过基于语义分析(nlu)的记录(积累)结果(意向、实体)执行意图估计处理来估计用户2的意图。另外,任务执行单元110通过基于用户2的意图估计的结果执行任务执行处理来执行系统的任务。
(用户意图估计的第一示例)
图7示出了用户2的意图估计的第一示例。
在图7中,用户2正在执行说“好的,让我们从十点开始。我将在通常位置等待。以这种方式回复。”的话语。在传统的话语对话系统中,因为语义分析处理是对整个话语句子执行的,所以在话语句子中包括多个不同的意图,并且语义分析(nlu)的结果变为域外(ood)。此处,ood意味着作为语义分析处理的结果而获得的可靠性分数低且没有获得正确的结果。
另一方面,在话语对话系统1中,在说“好的”的话语之后检测到话语的断点,并且将说“好的”的第一经划分话语句子(文本数据)输入至语义分析处理。然后,通过语义分析处理,作为第一经划分话语句子的语义分析(nlu)的结果,获得意向=“是”。
此时,在话语对话系统1中,因为检测到说“好的”的话语的断点,所以对用户2作出说“是”的响应(衬托型反馈行为)。
接着,在话语对话系统1中,在说出“好的”的话语后的说“让我们从十点开始”的话语之后,检测到话语的断点,并且将说“让我们从十点开始”的第二经划分话语句子(文本数据)输入至语义分析处理。通过语义分析处理,作为第二经划分话语句子的语义分析(nlu)的结果,获得意向=“闹钟-设置”和实体=“十”。
此时,在话语对话系统1中,因为检测到说“让我们从十点开始”的话语的断点,所以对用户2作出说“是”的响应(衬托型反馈行为)。
接下来,在话语对话系统1中,在说出“让我们从十点开始”的话语后的说“我将在通常位置等待。以这种方式回复。”的话语之后,检测到话语的断点,并且将说“我将在通常位置等待。以这种方式回复。”的第三经划分话语句子(文本数据)输入至语义分析处理。通过语义分析处理,作为第三经划分话语句子的语义分析(nlu)的结果,获得意向=“回复”和实体=“我将在通常位置等待”。
然后,在话语对话系统1中,因为第三经划分话语句子的语义分析(nlu)的结果示出了意向=“回复”和实体=“我将在通常位置等待”,所以可以通过多个意图估计单元109估计在前的第一经划分话语句子和第二经划分话语句子也具有与第三经划分话语句子相似的回复(“回复”)内容。更具体地,例如,在日语的情况下,因为谓语结束了话语,所以此处将作为第三经划分话语句子的意图(意向)的回复(“回复”)估计为整个话语的意图。
利用这种配置,多个意图估计单元109可以获得意向=“回复”和实体=“好的”+“让我们从十点开始”+“我将在通常位置等待”,作为用户2的整个话语的意图估计的结果。考虑到说“好的,让我们在通常位置从十点开始。“我将在通常位置等待。以这种方式回复。”的话语的内容,作为遵循用户2的意图的结果,可以说整个话语的意图估计的结果是合适的。
之后,基于由多个意图估计单元109执行的意图估计的结果,任务执行单元110控制终端设备10或服务器20的每个单元(例如,消息生成单元、通信i/f等),并且执行返回说“好的,让我们在通常位置从十点开始。“我将在通常位置等待”的消息的处理。以这种方式,在话语对话系统1(的任务执行单元110)中,根据用户2的话语执行作为“消息的回复”的任务。
此外,在图7的示例中,已经描述了作为“消息的回复”的任务,但是任务不限于此,并且例如,在话语对话系统1中,上述配置也可以类似地应用于执行诸如“消息的创建”的另外的任务的情况。
(用户意图估计的第二示例)
图8示出了用户2的意图估计的第二示例。
在图8中,用户2正在执行说“为了记住,为孩子买礼物,并且早点回家,将这些添加至今天的日程表”的话语。
话语对话系统1在说出“为了记住”的话语之后检测到话语的断点,并且将说“为了记住”的第一经划分话语句子输入至语义分析处理。通过语义分析处理,作为第一经划分话语句子的语义分析(nlu)的结果,获得意向=ood。
另外,此时,话语对话系统1分析说出“为了记住”的话语的语音数据,并且确定话语的速率(话语速度)为“慢”。将这些分析结果(意向、话语速度)记录至存储单元116中。
接下来,话语对话系统1在说出“为了记住”的话语后的说“为孩子买礼物”的话语之后,检测到话语的断点,并且将说“为孩子买礼物”的第二经划分话语句子输入至语义分析处理。通过语义分析处理,作为第二经划分话语句子的语义分析(nlu)的结果,获得意向=“买-物品”和实体=“给孩子的礼物”。
此处,将“给孩子的礼物”视为主体类型的实体。此外,主体表示话语的内容,并且主体类型的实体包括自由话语。
另外,此时,话语对话系统1分析说出“为孩子买礼物”的话语的语音数据,并且确定话语的速率(话语速度)为“快”。将这些分析结果(意向、实体、话语速度)记录至存储单元116中。
接下来,话语对话系统1在说出“为孩子买礼物”的话语后的说“并且早点回家,将这些添加至今天的日程表”的话语之后,检测到话语的断点,并且将说“并且早点回家,将这些添加至今天的日程表”的第三经划分话语句子输入至语义分析处理。通过语义分析处理,作为第三经划分话语句子的语义分析(nlu)的结果,获得意向=“日程表-添加”、实体=“早点回家”和实体=“今天”。然而,在这些实体中,“早点回家”被视为主体类型的实体,并且“今天”被视为日期类型的实体。
另外,此时,话语对话系统1分析说出“并且早点回家,将这些添加至今天的日程表”的话语的语音数据,并且确定话语的速率(话语速度)为“快”。将这些分析结果(意向、实体、话语速度)记录至存储单元116中。
此外,与上述示例类似,话语对话系统1在检测到用户2的话语的断点时对用户2作出说“是”的响应(衬托型反馈行为)。
然后,在话语对话系统1中,多个意图估计单元109基于记录在存储单元116中的通过将用户2的话语划分为三句而获得的每个经划分话语句子的语义分析(nlu)的结果(意向、实体)和每个经划分话语句子的话语的速率(话语速度)来估计用户2的话语的意图。
在意图估计处理中,因为针对作为最后经划分话语句子的第三经划分话语句子的意图(意向)的主体类型的实体是“早点回家”,第三经划分话语句子具有包括主体类型的实体的意图(意向),并且在其前一个提供的作为第二经划分话语句子的“为孩子买礼物”的话语速度被确定为“快”,因此以以下方式处理第二经划分话语句子的语义分析(nlu)的结果。
更具体地,在意图估计处理中,拒绝了第二经划分话语句子的意图(意向),并且将话语内容添加至作为第三经划分话语句子的意图(意向)的意向=“日程表-添加”的主体类型的实体中。
另外,在意图估计处理中,因为在其进一步的前面的作为第一经划分话语句子(开头的经划分话语句子)的“为了记住”的话语速度被确定为“慢”,所以防止了将第一经划分话语句子的意图(意向)添加至第三经划分话语句子的主体类型的实体中。
利用这种配置,多个意图估计单元109可以获得意向=“日程表-添加”、主体类型的实体=“为孩子买礼物”+“早点回家”以及日期类型的实体=“今天”,作为用户2的整个话语的意图估计的结果。考虑到说“为了记住,为孩子买礼物,并且早点回家,将这些添加至今天的日程表”的话语的内容,作为遵循用户2的意图的结果,可以说整个话语的意图估计是适合的。
之后,基于由多个意图估计单元109执行的意图估计的结果,任务执行单元110控制终端设备10或服务器20的每个单元(例如,日程表管理单元等),并且执行将“为孩子买礼物,并且早点回家”的日程表项目登记到日程表中作为“今天”的日程表项目的处理。以这种方式,在话语对话系统1(的任务执行单元110)中,根据用户2的话语执行作为“日程表的登记”的任务。
此外,在第二示例中,在意图估计处理中,当根据多个语义分析(nlu)的结果确定主体的部分时使用话语的速率(话语速度),并且将该部分添加至日程表的内容中,但是可以使用另外类型的信息,只要可以基于该信息确定是否作为主体的部分添加。
(用户意图估计的第三示例)
图9示出了用户2的意图估计的第三示例。
在图9中,用户2正在执行说“啊,明天下雨。我将在通常位置等待。以这种方式回复。”的话语。
话语对话系统1在说出“啊”的话语之后检测到话语的断点,并且将说“啊”的第一经划分话语句子输入至语义分析处理。通过语义分析处理,作为第一经划分话语句子的语义分析(nlu)的结果,获得意向=ood。
另外,此时,话语对话系统1分析在说“啊”的话语期间获得的图像数据,并且确定用户2在话语期间“不看”终端设备10。将这些分析结果(意向、视线)记录至存储单元116中。
接下来,话语对话系统1在说出“啊”的话语后的说“明天下雨”的话语之后,检测到话语的断点,并且将说“明天下雨”的第二经划分话语句子输入至语义分析处理。通过语义分析处理,作为第二经划分话语句子的语义分析(nlu)的结果,获得意向=ood。
另外,此时,话语对话系统1分析在说“明天下雨”的话语期间获得的图像数据,并且确定用户2在话语期间“不看”终端设备10。将这些分析结果(意向、视线)记录至存储单元116中。
接下来,话语对话系统1在说出“明天下雨”的话语后的说“我将在通常位置等待。以这种方式回复。”的话语之后,检测到话语的断点,并且将说“我将在通常位置等待。以这种方式回复。”的第三经划分话语句子输入至语义分析处理。通过语义分析处理,作为第三经划分话语句子的语义分析(nlu)的结果,获得意图=“回复”和实体=“我将在通常位置等待”。
另外,此时,话语对话系统1分析在说“我将在通常位置等待。以这种方式回复”的话语期间获得的图像数据,并且确定用户2在话语期间“看”终端设备10。将这些分析结果(意向、实体、视线)记录至存储单元116中。
然后,在话语对话系统1中,由多个意图估计单元109获得的第三经划分话语句子的语义分析(nlu)的结果示出了意向=“回复”、实体=“我将在通常位置等待”,但是因为确定用户在其前一个提供的作为第二经划分话语句子的“明天下雨”的话语期间“不看”,所以防止了将第二经划分话语句子的意图(意向)添加至第三经划分话语句子的主体类型的实体中。
以类似的方式,另外,因为确定用户在其进一步的前面的作为第一经划分话语句子(开头的经划分话语句子)的“啊”的话语期间“不看”,所以防止了将第一经划分话语句子的意图(意向)添加至第三经划分话语句子的主体类型的实体中。
利用这种配置,多个意图估计单元109可以获得意向=“回复”和主体类型的实体=“我将在通常位置等待”,作为用户2的整个话语的意图估计的结果。考虑到说“啊,明天下雨。我将在通常位置等待。以这种方式回复。”的话语的内容,作为遵循用户2的意图的结果,可以说整个话语的意图估计是适合的,原因是“啊,明天下雨”是用户2的独白。
之后,基于由多个意图估计单元109执行的意图估计的结果,任务执行单元110控制终端设备10或服务器20的每个单元(例如,消息生成单元、通信i/f等),并且执行返回说“我将在通常位置等待”的消息的处理。以这种方式,在话语对话系统1(的任务执行单元110)中,根据用户2的话语执行作为“消息的回复”的任务。
此外,在第三示例中,在意图估计处理中,当根据多个语义分析(nlu)的结果确定主体的部分时使用视线,并且将该部分添加至日程表的内容中,但是可以使用另外类型的信息,只要可以基于该信息确定是否作为主体的部分添加。
(用户意图估计的第四示例)
图10示出了用户2的意图估计的第四示例。
在图10中,用户2正在执行说“调高音量并返回至音乐的开始”的话语。在传统的话语对话系统中,语义分析处理是对整个话语句子执行的,但是因为在话语句子中包括多个不同的意图,因此作为语义分析(nlu)的结果,获得意向=ood。
另一方面,话语对话系统1在说出“调高音量”的话语之后检测到话语的断点,并且将说“调高音量”的第一经划分话语句子输入至语义分析处理。然后,通过语义分析处理,作为第一经划分话语句子的语义分析(nlu)的结果,获得意向=“音量_增大”。
此时,在话语对话系统1中,因为检测到说“调高音量”的话语的断点,所以对用户2作出说“是”的响应(衬托型反馈行为)。
另外,话语对话系统1在说出“调高音量”的话语后的说“并返回至音乐的开始”的话语之后,检测到话语的断点,并且将说“并返回至音乐的开始”的第二经划分话语句子输入至语义分析处理。然后,通过语义分析处理,作为第二经划分话语句子的语义分析(nlu)的结果,获得意向=“音乐_重放”。
此时,在话语对话系统1中,因为检测到说“并返回至音乐的开始”的话语的断点,所以对用户2作出说“是”的响应(衬托型反馈行为)。
然后,在话语对话系统1中,因为由多个意图估计单元109获得的第一经划分话语句子的语义分析(nlu)的结果示出了意向=“音量_增大”,以及由多个意图估计单元109获得的第二经划分话语句子的语义分析(nlu)的结果示出了意向=“音乐_重放”,所以可以估计出在用户2的话语中包括两个意图(意向)。
利用这种配置,多个意图估计单元109可以获得包括意向=“音量_增大”和“音乐_重放”的两个意图(意向),作为用户2的整个话语的意图估计的结果。考虑到说“调高音量并返回至音乐的开始”的话语的内容,作为遵循用户2的意图的结果,可以说整个话语的意图估计的结果是适合的。
基于由多个意图估计单元109执行的意图估计的结果,任务执行单元110通过控制终端设备10的语音输出单元114等执行调高音量并在将音乐返回至开始之后重放音乐的处理。以这种方式,在话语对话系统1(的任务执行单元110)中,根据用户2的意图,可以共同地执行对应于意图(意向)为“音量_增大”的“调高音量”的第一任务和对应于意图(意向)为“音乐_重放”的“在将音乐返回至开始之后重放音乐”的第二任务。
此外,在图10的示例中,已经描述了针对音乐重放操作的请求,但是意图不限于此,并且例如在用户2的话语包括对话语对话系统1中的系统的多个请求意图的情况下,能够应用该方法。
(意图估计处理和任务执行处理的其他示例)
如上述图7中的用户意图估计的第一示例,已经描述了执行消息的回复和创建的任务的示例,并且消息的回复和创建的任务可以应用于其他功能,诸如代理的消息功能。
例如,在用户2对话语对话系统1执行说“传达‘在冰箱里有用于下午茶的一块蛋糕’”的话语(消息)的情况下,可以通过将话语中的与话语的断点对应的“在冰箱里有用于下午茶的一块蛋糕”的部分的话语语音记录为消息正文来仅将消息正文的语音重放给其他用户(例如,家人)。
另外,用户2可能在话语期间作出话语错误。因此,可以在话语的划分单元中执行对话语期间作出的话语错误的取消、撤销和撤回。
此处,将描述话语的划分单元中的取消功能的两个特定示例,并且在对话中,将用户2的话语描述为“u(用户)”以及将由话语对话系统1作出的响应(任务的执行)描述为“s(系统)”。另外,“/”表示话语中的通过话语断点检测处理已经检测到的断点位置。
(第一示例)
u:“为明天设置闹钟/到七点/不,这是错误的/到六点”
s:(执行“设置闹钟”到“明天早上六点”的任务)
在第一示例的情况下,话语对话系统1取消与话语中的紧接在说“不,这是错误的”的经划分话语句子之前提供的断点对应的说“到七点”的经划分话语句子,并且使用与话语中的紧接在说“不,这是错误的”的经划分话语句子之后提供的断点对应的说“到六点”的经划分话语句子来设置到明天早上六点的闹钟。
换而言之,此处,在针对相应的经划分话语句子获得的语义分析(nlu)的结果中,将用作实体信息(实体)的“七”校正为“六”,其中意图(意向)是闹钟设置(“闹钟-设置”)保持不变。
(第二示例)
u:“添加至购物清单/鸡蛋/胡萝卜/不,取消这个/小萝卜”
s:(执行“将‘鸡蛋’和‘小萝卜’添加至购物清单”的任务)
在第二示例的情况下,话语对话系统1取消与话语中的紧接在说“不,取消这个”的经划分话语句子之前提供的断点对应的说“胡萝卜”的经划分话语句子,并且使用与话语中的紧接在说“不,取消这个”的经划分话语句子之后提供的断点对应的说“小萝卜”的经划分话语句子将鸡蛋和小萝卜添加至购物清单。
换而言之,此处,在针对相应的经划分话语句子获得的语义分析(nlu)的结果中,将用作实体信息(实体)的“胡萝卜”校正为“小萝卜”,其中意图(意向)是购物日程表(“日程表-添加”)保持不变。
(统计分析)
例如,在话语对话系统1中,因为针对每个经划分话语句子获得语义分析(nlu)的结果(意向、实体),所以可以统计地分析多个意图(意向)的相对共现频率,并且分析结果可用于意图估计处理。
例如,当用户2执行说“调高音量并重放音乐××”的话语时,基于说“调高音量”的第一经划分话语句子和说“并重放音乐××”的第二经划分话语句子的各自的语义分析(nlu)结果,可以统计地学习意向=音量_增大+播放_音乐的相对共现频率。
另外,在话语对话系统1中,通过将数据诸如记录至存储单元116中的每个经划分话语句子的语义分析(nlu)的结果(意向、实体)作为收集的数据记录,例如可以通过统计地分析收集的数据学习到具有意图(意向)是播放_音乐的话语很可能在具有意图(意向)是音量_增大的话语之后执行。
然后,例如,当用户2执行说“调高音量并重放××”的话语时,假设获得意向=音量_增大+ood作为说“调高音量”的第一经划分话语句子和说“并重放××”的第二经划分话语句子的各自的语义分析(nlu)结果。此处,因为意向=播放_音乐的可靠性分数低,所以第二经划分话语句子的意图(意向)为ood。
此时,在话语对话系统1(的多个意图估计单元109)中,通过将与共现频率对应的值添加至被确定为ood的播放_音乐的可靠性分数、使用预先执行的学习结果以及校正可靠性分数(由于音量_增大之后的播放_音乐的共现频率高,可靠性分数增加)获得其中意图被确定为不是ood而是播放_音乐的意图的意图估计结果。利用这种配置,在话语对话系统1(的任务执行单元110)中,音乐的重放也与调高音量一起执行。
此外,在服务器20中设置有存储单元116的情况下,因为可以将不仅与某个特定用户的话语对应而且与使用话语对话服务的许多用户的话语对应的语义分析(nlu)的结果(意向、实体)作为收集的数据积累,所以可以使用更多的收集的数据执行更准确的机器学习。
更具体地,可以针对所有用户收集并应用上述统计的共现频率,可以针对每个用户属性(例如,区域、年龄组、性别等)收集并应用上述统计的共现频率,或者可以针对某个特定用户收集并应用上述统计的共现频率。
另外,例如,在上述示例中已经描述了n-gram统计中n=2的情况,但是可以通过增加诸如n=3、n=4的共现关系的数目等统计地分析频率。
例如,通过执行这样的统计分析,收集的数据量随着系统的使用小时数而增加,并且也从由用户说出的长句、复句等获得每个经划分话语句子的语义分析(nlu)的结果。由此,用户可以实现意图估计处理中的意图估计的准确性增加,并且随着更多地使用系统,系统变得更加睿智。
(整个话语的主体确定处理的流程)
接下来,将参照图11中的流程图描述由话语对话系统1执行的整个话语的主体确定处理的流程。
此外,整个话语的主体确定处理包括在步骤s17中的处理中,步骤s17中的处理将在重复地执行图3中的话语对话处理中的步骤s11至步骤s16中的处理之后执行,并且获得相应的经划分话语句子的语义分析(nlu)的结果。
在步骤s31中,多个意图估计单元109获取记录在存储单元116中的通过将用户2的话语划分为n句而获得的经划分话语句子的语义分析(nlu)的结果和每个经划分话语句子的话语的速率(话语速度)。此处,n表示1或更大的整数。
在步骤s32中,多个意图估计单元109将n=n设置为经划分句子的索引n。此处,通过设置n=n,将处理目标设置为最后经划分话语句子。
在步骤s33中,多个意图估计单元109确定第n个经划分话语句子的意图(意向)是否包括主体类型的实体信息(实体)。
在步骤s33中确定第n个经划分话语句子的意图(意向)不包括主体类型的实体信息(实体)的情况下,处理前进至步骤s35。
在步骤s35中,因为用户2的话语中不存在主体类型的实体信息(实体),所以多个意图估计单元109估计与n个经划分话语句子的相应的意图(意向)对应的意图。利用这种配置,基于来自多个意图估计单元109的意图估计的结果,任务执行单元110执行与n个经划分话语句子的相应的意图(意向)对应的任务。
例如,执行步骤s35中的处理的情况与图10中示出的用户意图估计的第四示例对应。在图10中,作为用户2的整个话语的意图估计的结果,估计包括意向=“音量_增大”和“音乐_重放”的两个意图(意向)。
当步骤s35中的处理结束时,整个话语的主体确定处理结束。
另一方面,在步骤s33中确定第n个经划分话语句子的意图(意向)包括主体类型的实体信息(实体)的情况下,处理前进至步骤s34。
在步骤s34中,多个意图估计单元109确定第n个经划分话语句子是否位于用户2的话语的开头。此处,确定处理目标是否是n=1,也就是说,第一个(开头)经划分话语句子。
在步骤s34中确定第n个经划分话语句子位于用户2的话语的开头的情况下,因为第n个经划分话语句子包括主体类型的实体信息(实体),但是是开头的经划分话语句子,所以整个话语的主体确定处理结束。
另外,在步骤s34中确定第n个经划分话语句子不位于用户2的话语的开头的情况下,处理前进至步骤s36。在步骤s36中,多个意图估计单元109将n=n-1设置为经划分句子索引n。此处,例如,在n旁边,设置与前一个提供的经划分话语句子对应的索引,诸如n-1。
在步骤s37中,多个意图估计单元109确定第n个经划分话语句子的用户2的话语的速率是否超过阈值(话语的速率是否快于阈值指示的速率)。
在步骤s37中确定用户2的话语的速率超过阈值的情况下,处理前进至步骤s38。
在步骤s38中,多个意图估计单元109使得不执行第n个经划分话语句子的意图(意向),并且估计将其内容添加至最后经划分话语句子的意图(意向)的主体类型的实体信息(实体)的意图。由此,任务执行单元110执行与意图估计的结果对应的任务,其中第n个经划分话语句子的意图(意向)被添加至最后经划分话语句子的意图(意向)的主体类型的实体信息(实体)。
例如,执行步骤s38中的处理的情况与图7中示出的用户意图估计的第一示例对应。在图7中,作为用户2的整个话语的意图估计的结果,添加说“好的”和“让我们从十点开始”的经划分话语句子的内容作为最后经划分话语句子的主体类型的实体信息(实体),并且获得意向=“回复”以及实体=“好的”+“让我们从十点开始”+“我将在通常位置等待”。
当步骤s38中的处理结束时,处理返回至步骤s34,并且重复上述处理。
另一方面,在步骤s37中确定用户的话语的速率小于阈值的情况下,处理前进至步骤s39。
在步骤s39中,多个意图估计单元109确定在第n个经划分话语句子之前提供的经划分话语句子不是对系统的请求的话语,并且估计不执行在第n个经划分话语句子之前提供的经划分话语句子的意图(意向)的意图。由此,任务执行单元110执行与意图估计的结果对应的任务,其中不执行在第n个经划分话语句子之前提供的经划分话语句子的意图(意向)。
例如,执行步骤s39中的处理的情况与图8中示出的用户意图估计的第二示例对应。在图8中,不执行说“为了记住”的经划分话语句子(的意图(意向)),并且作为整个话语的意图估计的结果,获得意向=“日程表-添加”、主体类型的实体=“为孩子买礼物”+“早点回家”以及日期类型的实体=“今天”。
当步骤s39中的处理结束时,整个话语的主体确定处理结束。
在上文中,已经描述了整个话语的主体确定处理的流程。
(划分单元中的取消处理的流程)
接下来,将参照图12中的流程图描述由话语对话系统1执行的划分单元中的取消处理的流程。
此外,划分单元中的取消处理包括在步骤s17中的处理中,步骤s17中的处理将在重复地执行图3中的话语对话处理中的步骤s11至步骤s16中的处理之后执行,并且获得每个经划分话语句子的语义分析(nlu)的结果。
在步骤s51中,多个意图估计单元109获取记录在存储单元116中的通过将用户的话语划分为n句而获得的经划分话语句子的语义分析(nlu)的结果。此处,n为1或更大的整数。
在步骤s52中,多个意图估计单元109将n=n设置为经划分句子索引n。通过设置n=n,将处理目标设置为最后经划分话语句子。
在步骤s53中,多个意图估计单元109确定第n个经划分话语句子是否位于用户2的话语的开头。此处,确定处理目标是否是n=1,也就是说,第一个(开头)经划分话语句子。
在步骤s53中确定第n个经划分话语句子位于用户2的话语的开头的情况下,因为不需要在话语的划分单元中执行取消,所以划分单元中的取消处理结束。
另一方面,在步骤s53中确定第n个经划分话语句子不位于用户2的话语的开头的情况下,处理前进至步骤s54。
在步骤s54中,多个意图估计单元109确定第n个经划分话语句子的意图(意向)是否包括取消或撤回的意图。此处,取消或撤回的意图的示例包括与上述经划分话语句子对应的意图(意向),诸如“不,这是错误的”或“不,取消这个”。
在步骤s54中确定第n个经划分话语句子的意图(意向)包括取消等的意图的情况下,处理前进至步骤s55。在步骤s55中,多个意图估计单元109从用户2的意图估计的目标中删除第(n-1)个经划分话语句子。
例如,在上述第一示例中,在检测到话语中的说“…/设置到七点/不,这是错误的/…”的断点的情况下,当确定说“不,这是错误的”的第n个经划分话语句子包括取消等的意图时,从意图估计的目标中删除说“设置到七点”的第(n-1)个经划分话语句子。
另外,例如,在上述第二示例中,在检测到话语中的说“…/胡萝卜/不,取消这个/…”的断点的情况下,当确定说“不,取消这个”的第n个经划分话语句子包括取消等的意图时,从意图估计的目标中删除说“胡萝卜”的第(n-1)个经划分话语句子。
另一方面,在步骤s54中确定第n个经划分话语句子的意图(意向)不包括取消等的意图时,处理前进至步骤s56。在步骤s56中,多个意图估计单元109将n=n-1设置为经划分句子索引n。此处,例如,在n旁边,设置与前一个提供的经划分话语句子对应的索引,诸如n-1。
当步骤s56中的处理结束时,处理返回至步骤s53,并且重复后续的处理。
另外,当步骤s55中的处理结束时,处理前进至步骤s57。在步骤s57中,多个意图估计单元109确定第(n-1)个经划分话语句子是否位于用户2的话语的开头。此处,确定处理目标是否是n=2,也就是说,第二个经划分话语句子。
在步骤s57中确定第(n-1)个经划分话语句子位于用户2的话语的开头的情况下,因为不再需要在话语的划分单元中执行取消,所以划分单元中的取消处理结束。
另一方面,在步骤s57中确定第(n-1)个经划分话语句子不位于用户2的话语的开头的情况下,处理前进至步骤s58。在步骤s58中,多个意图估计单元109将n=n-2设置为经划分句子索引n。此处,例如,在n旁边,设置与前两个提供的经划分话语句子对应的索引,诸如n-2。
当步骤s58中的处理结束时,处理返回至步骤s53,并且重复后续的处理。
在上文中,已经描述了划分单元中的取消处理的流程。
以这种方式,在话语对话系统1中,通过检测用户2的话语特性,以及针对通过以期望理解用户2的意图为单位划分话语句子而获得的每个经划分话语句子获得语义分析(nlu)的结果,可以更准确地估计用户2的话语的意图。
同时,在传统的语义分析引擎(nlu引擎)中,当从用户的话语句子中提取意图(意向)和实体信息(实体)时,难以从包括多个意图的长句或复句中正确地提取意图(意向)和实体信息(实体)。换而言之,随着用户说出的句子变得更长,包括多个意图(意向)和多条实体信息(实体)的可能性变得更高,而这妨碍了传统的语义分析引擎估计唯一的意图(意向)。
另外,在传统的话语对话系统中,在用户执行长话语的情况下,当不能正确地估计其意图(意向)时,引起用户不期望的系统行为。因此,用户仅对话语对话系统执行基于短句或命令的话语,并且不能离开使用语音命令的输入用户接口(ui:用户接口)。
此处,上述语音命令意味着用户使用语音发出特定命令,并且意味着该命令不是用户执行的自然话语。
与之相比,在话语对话系统1中,因为检测到人的话语特性并且针对通过以期望理解用户2的意图为单位划分话语句子而获得的每个经划分话语句子获得语义分析(nlu)的结果,所以可以获得遵循用户2的话语的意图(意向)和实体信息(实体)。因此,在话语对话系统1中,即使在用户2说出包括多个意图的长句或复句的情况下(在用户2的话语包括对系统的多个请求意图的情况下),可以正确地估计请求意图中的每一个并且共同执行与相应的请求任务对应的任务。
因此,针对每个请求任务,期望用户2停止使用诸如语音命令的短句话语来执行对话话轮。另外,即使当用户2说长句或复句时,用户2也获得系统正确地理解意图并进行操作的这样的体验,并且通过该体验,用户2感觉可以对系统执行使用长句或复句的话语。
此外,在话语对话系统1中,因为获得用户2的复杂话语的意图不需要使用诸如语音命令的短句话语的多个对话话轮,所以可以在不引起对话话轮的意识的情况下对用户2执行自然对话。
另外,在话语对话系统1中,例如,因为可以在电子邮件、社交网络服务(sns)等的消息的创建请求的话语时从话语句子正确地提取消息的内容(主体),所以例如可以在一个对话话轮中共同处理消息的创建请求和消息内容(主体)的输入,而非在不同的对话话轮中处理消息的创建请求和消息内容(主体)的输入。
<2.修改的示例>
作为示例,已经给出了话语对话系统1的配置的以上描述,其中,从语音输入单元101至传感器单元103、语音输出单元114和图像输出单元115的结构元件被并入至本地侧的终端设备10中,并且从话语识别单元104至输出图像处理单元113的结构元件被并入至云端侧的服务器20中,但是从语音输入单元101至图像输出单元115的结构元件中的每一个可以并入至终端设备10和服务器20中的任何一个设备中。
例如,可以将从语音输入单元101至图像输出单元115的所有结构元件并入至终端设备10侧,并且可以在本地侧完成处理。然而,即使在采用这样的配置的情况下,也可以由因特网30上的服务器20管理各种类型的数据库。
另外,在由话语识别单元104执行的话语识别处理和在由语义分析单元108执行的语义分析处理中,可以使用在另外的服务中提供的话语识别服务和语义分析服务。在这种情况下,例如,在服务器20中,通过将语音数据发送至因特网30上提供的话语识别服务,可以获得话语识别的结果。另外,例如,在服务器20中,通过将经划分话语句子的数据发送至因特网30上提供的语义分析服务,可以获得每个经划分话语句子的语义分析结果(意向、实体)。
<3.计算机的配置>
上述一系列处理(例如,图3中示出的话语对话处理等)可以通过硬件或软件执行。在通过软件执行一系列处理的情况下,在每台计算机上安装包括该软件的程序。图13是示出通过程序执行上述一系列处理的计算机的硬件配置的示例的框图。
在计算机1000中,中央处理单元(cpu)1001、只读存储器(rom)1002和随机存取存储器(ram)1003通过总线1004彼此连接。输入和输出接口1005进一步连接至总线1004。输入单元1006、输出单元1007、记录单元1008、通信单元1009和驱动器1010连接至输入和输出接口1005。
麦克风、键盘、鼠标等用作输入单元1006。扬声器、显示器等用作输出单元1007。硬盘、非易失性存储器等用作记录单元1008。网络接口等用作通信单元1009。驱动器1010驱动可移除记录介质1011,诸如磁盘、光盘、磁光盘或半导体存储器。
在具有上述配置的计算机1000中,cpu1001通过经由输入和输出接口1005和总线1004将记录在rom1002或记录单元1008上的程序加载至ram1003并且执行该程序来执行上述一系列处理。
由计算机1000(cpu1001)执行的程序例如可以记录在诸如封装介质的可移除记录介质1011上进行供应。另外,可以经由有线或无线传输介质诸如局域网、因特网或数字广播来提供程序。
在计算机1000中,可以通过将可移除记录介质1011安装在驱动器1010上经由输入和输出接口1005将程序安装在记录单元1008上。另外,程序可以由通信单元1009经由有线或无线传输介质接收,并且可以安装在记录单元1008上。另外,程序可以预先安装在rom1002或记录单元1008上。
此处,在本说明书中,由计算机根据程序执行的处理可以不必按照流程图描述的顺序按时间顺序执行。也就是说,由计算机根据程序执行的处理还包括并行或单独执行的处理(例如,并行处理或由对象进行的处理)。另外,程序可以由一个计算机(处理器)处理或者可以由多个计算机分配和处理。
此外,本技术的实施方式不限于上述实施方式,而是在不脱离本技术的主旨的情况下,可以在本技术的范围内作出各种改变。
另外,除了由一个设备执行以外,图3中示出的话语对话处理的每个步骤还可以由多个设备以共享的方式执行。此外,在一个步骤包括多个处理的情况下,除了由一个设备执行以外,一个步骤中包括的多个处理还可以由多个设备以共享的方式执行。
另外,本技术还可以被如下配置。
(1)一种信息处理设备,包括:
检测单元,其被配置成基于在用户的话语期间获得的识别结果来检测所述用户的所述话语的断点;以及
估计单元,其被配置成基于通过在所述话语的所检测到的断点处划分话语句子而获得的经划分话语句子的语义分析的结果来估计所述用户的所述话语的意图。
(2)根据(1)所述的信息处理设备,其中,所述识别结果包括下述中的至少一个识别结果:所述用户的所述话语的语音数据的识别结果、通过捕获所述用户的图像而获得的图像数据的识别结果、或者通过感测所述用户或所述用户的周围事物而获得的传感器数据的识别结果。
(3)根据(2)所述的信息处理设备,其中,所述检测单元基于根据所述识别结果而获得的所述用户的状态或姿势来检测所述话语的所述断点。
(4)根据(1)至(3)中任一项所述的信息处理设备,其中,所述估计单元基于针对所述经划分话语句子中的每一个来顺序地获得的意图(意向)和实体信息(实体)来估计所述用户的所述话语的意图。
(5)根据(4)所述的信息处理设备,其中,所述估计单元从相应的经划分话语句子的多个意图(意向)中提取遵循所述话语句子的意图(意向)。
(6)根据(4)或(5)所述的信息处理设备,其中,所述估计单元从相应的经划分话语句子的多条实体信息(实体)中提取遵循所述话语句子的实体信息(实体)。
(7)根据(4)所述的信息处理设备,其中,所述实体信息(实体)包括主体类型作为所述实体信息的类型,所述主体类型表示包括自由话语,以及
在最后的经划分话语句子的意图(意向)包括主体类型的实体信息(实体)的情况下,在作为所述最后的经划分话语句子之前提供的经划分话语句子且作为目标的目标经划分话语句子满足特定条件的情况下,所述估计单元使得不执行所述目标经划分话语句子的意图(意向),并且将所述目标经划分话语句子的内容添加至所述最后的经划分话语句子的所述意图(意向)中包括的主体类型的实体信息(实体)。
(8)根据(7)所述的信息处理设备,其中,在所述目标经划分话语句子不满足所述特定条件的情况下,所述估计单元丢弃所述目标经划分话语句子的所述意图(意向)。
(9)根据(8)所述的信息处理设备,其中,所述特定条件包括:用于确定所述用户的所述话语的速率是否超过预定阈值的条件;或者用于确定所述用户是否看预定目标的条件。
(10)根据(4)所述的信息处理设备,其中,所述实体信息(实体)包括主体类型作为所述实体信息的类型,所述主体类型表示包括自由话语,并且
当包括主体类型的实体信息(实体)的所述经划分话语句子不存在时,所述估计单元根据相应的经划分话语句子的意图(意向)来估计所述用户的所述话语的意图。
(11)根据(4)至(10)中任一项所述的信息处理设备,其中,当所述用户的所述话语包括撤回的意图(意向)时,所述估计单元从所述用户的所述话语的意图估计的目标中删除要撤回的经划分话语句子。
(12)根据(11)所述的信息处理设备,其中,其中,当第n个经划分话语句子包括撤回的意图(意向)时,所述估计单元从所述用户的所述话语的意图估计的目标中删除第n-1个经划分话语句子。
(13)根据(1)或(12)中任一项所述的信息处理设备,还包括生成单元,所述生成单元被配置成生成要在所述话语的所检测到的断点处输出的反馈信息。
(14)根据(13)所述的信息处理设备,其中,所述反馈信息包括语音、音效或图像。
(15)根据(2)或(3)所述的信息处理设备,其中,当所述用户的所述话语的暂停时间超过固定时间时,当检测到所述用户的所述话语中包括的语调短语的边界时,或者当检测到所述用户的所述话语中包括的支吾或补白时,所述检测单元基于所述语音数据的所述识别结果来检测所述话语的所述断点。
(16)根据(2)或(3)所述的信息处理设备,其中,当所述用户的嘴不动的时间超过固定时间时,或者当检测到所述用户的视线的大运动时,所述检测单元基于所述图像数据的所述识别结果来检测所述话语的所述断点。
(17)根据(2)或(3)所述的信息处理设备,其中,当检测到所述用户的呼吸的吸入时,或者检测到所述用户的整个身体或身体的部分的运动时,所述检测单元基于所述传感器数据的所述识别结果来检测所述话语的所述断点。
(18)根据(1)至(17)中的任一项所述的信息处理设备,还包括任务执行单元,所述任务执行单元被配置成基于所述用户的所述话语的意图估计的结果来执行任务。
(19)根据(1)至(18)中任一项所述的信息处理设备,还包括:
话语识别单元,其被配置成执行话语识别(asr),以从所述用户的所述话语中获得所述话语句子;以及
语义分析单元,其被配置成执行在所述话语的所述断点处顺序地获得的所述经划分话语句子的语义分析(nlu)。
(20)一种信息处理设备的信息处理方法,所述信息处理方法包括:
由所述信息处理设备进行以下操作
基于在用户的话语期间获得的识别结果来检测所述用户的所述话语的断点;以及
基于通过在所述话语的所检测到的断点处划分话语句子而获得的经划分话语句子的语义分析的结果来估计所述用户的所述话语的意图。
附图标记列表
1话语对话系统
10终端设备
20服务器
30因特网
101语音输入单元
102图像输入单元
103传感器单元
104话语识别单元
105图像识别单元
106传感器识别单元
107话语断点检测单元
108语义分析单元
109多个意图估计单元
110任务执行单元
111音效重放单元
112话语合成处理单元
113输出图像处理单元
114语音输出单元
115图像输出单元
116存储单元
1000计算机
1001cpu
- 还没有人留言评论。精彩留言会获得点赞!