用于使虚拟3D音频适应现实房间的设备和方法与流程
本发明涉及双耳音频渲染技术领域,具体地,涉及如混响时间和混合时间等房间的声学参数的估计。具体地,本发明提供了一种用于估计此类房间声学参数的设备和方法。因此,所述设备和方法用于使虚拟3d音频适应现实房间。本发明针对的产品是带有耳机的增强现实(augmented-reality,ar)应用、移动设备(智能手机或平板电脑)上的耳机环绕声、使用智能手机或与单个/多个远程用户的电话会议等。
背景技术:
双耳房间脉冲响应(binauralroomimpulseresponse,brir)是通过耳机创建沉浸式3d音频信号所必需的。brir不仅与人有关,还与房间有关。如图23所示,brir(在时间轴上)由直接声音部分、早期反射声和晚期混响组成。直接声音部分对声源定位很重要。早期反射声提供空间信息,对距离感知和声源的外部化至关重要。晚期混响为听者提供房间信息,它由高密度的反射声组成,不再依赖于声源的位置。
由于实际障碍和复杂度,在常见消费者场景中测量每个用户的brir较为困难,且不切实际。因此,通常使用一组合成brir(例如,基于通用头相关传输函数(head-relatedtransferfunction,hrtf)和人工混响、物理房间声学建模等)或一组参考brir来代替测量的brir进行双耳渲染。
然而,在不了解实际房间声学的情况下使用合成brir进行双耳渲染时,感知的外部化和似真性可能会降低。这是因为感知的听觉印象依赖于外部的声音刺激,但也取决于由于不同的房间声学对实际房间内听觉事件产生预期。因此,尽可能精确地估计实际现实房间中的声学参数很重要。一个重要的声学参数是混响时间(也称为rt60)。
已知许多关于虚拟3d音频的通用房间适应,具体关于混响时间估计的传统方案。
wo2017185663a1中使用智能设备(例如,虚拟现实(virtualreality,vr)耳机、智能手机等)的麦克风和扬声器来测量实际房间中的房间脉冲响应(roomimpulseresponse,rir),然后将房间脉冲响应与预先选择的hrtf组合,以渲染3d音频。因此,虚拟声学可以适应实际现实房间的声学。然而,测量难以在常见消费者场景中进行,因为设备中的麦克风和扬声器以及收听环境的要求较高(底噪、频率响应、环境的背景噪音、录制的信号的信噪比(signal-to-noiseratio,snr)等)。因此,这种方法的缺点是:
·直接测量rir需要安静的环境和相对良好的设备(非常高的snr)。
·在合成部分中,rir响应根据预先选择的hrtf的长度进行截断,混合时间固定且与房间无关。
与上述方法直接使用测量的rir不同,wo2017136573a1中提出一种使用静态房间参数来扩展3d音频渲染算法以匹配本地环境声学的方法。为此,测量实际房间的混响指纹(体积和频率相关混响时间),并将其与参考房间的混响指纹(已预先测量)进行比较。然后,可以根据参考brir以及实际房间和参考房间的混响指纹,对实际房间的brir进行重整形。这个理念旨在使虚拟3d音频适应现实的声学环境。然而,这种方法的缺点是:
·由于大多数消费者可能没有测量混响时间的硬件或技术知识,因此难以在常见消费者场景中测量房间体积和频率相关混响时间。因此,需要额外的设备或软件来测量房间体积。此外,还需要安静的环境和相对良好的设备来测量混响时间。
估计混响时间的传统方法通常基于测量的rir(schroeder方法)或录制的白噪声(interrupted方法)。然而,由于对播放、录音设备和收听环境的要求相对较高,并且测量过程对于某些消费者而言可能比较困难,因此这些测量难以在常见消费者场景中进行。为了解决这些问题,提出了一些基于语音或音乐信号的rt60盲估计方法。混响可以使用语音信号根据最大似然法/信号衰减率分布等来估计。特别地,这些传统方法的缺点是:
·由于语音信号的频率范围,这些方法与频率无关,或者频率限制在8khz以内。另外,在环境噪声影响下,在中频到高频(2-8khz)内,所应用的算法不准确/鲁棒性较低。
技术实现要素:
鉴于上述缺点,本发明旨在改进虚拟3d音频的通用房间适应的传统方法,具体旨在改进估计混响时间的传统方法。本发明的目的是提供一种用于更加快速、高效地估计房间声学参数的设备和方法。特别地,所述设备和方法应该能够精确估计全频带(即,频率不受限制)混响时间和可选的混合时间。
本发明的目的通过所附独立权利要求中提供的方案来实现。本发明的有利实现方式在从属权利要求中进一步定义。
特别地,本发明实施例通过测量实际房间中的语音信号来获得房间声学参数。然后,可以根据估计的声学参数合成brir。合成brir可以进一步用于双耳渲染,例如用于ar应用或移动设备上的耳机环绕。本发明实施例特别基于一种用于将频率相关混响时间的盲估计从较低频率扩展到较高频率的方案。
本发明的第一方面提供一种用于估计声学参数的设备,所述设备用于录制声学信号,特别是语音信号;根据所述录制的声学信号估计较低频率范围内的频率相关混响时间;并根据预定模型将所述频率相关混响时间扩展到较高频率范围,以获得扩展的频率相关混响时间。
所述第一方面的设备不测量(房间)声学参数(即,特别是混响时间),而是根据语音录制进行估计。因此,不需要极度安静的环境和良好的设备(非常高的snr)。因此,该设备在噪声环境中也能很好地工作。此外,也不需要事先了解房间几何构造和混响时间。因此,不需要额外的设备或软件来测量房间体积。所述第一方面的设备不同于估计混响时间的传统方法,因为扩展的频率相关混响时间覆盖整个频率范围,而传统方法频率受到限制。
在所述第一方面的一种实现方式中,所述较低频率范围包括8khz以下,特别是在1.4khz与8khz之间的频率;所述较高频率范围包括8khz以上,特别是在8khz与18khz之间的频率。
也就是说,与用于估计混响时间的传统方法不同,该设备甚至能够获得8khz以上的混响时间。
在所述第一方面的另一种实现方式中,所述设备用于通过执行盲估计来估计所述较低频率范围内的所述频率相关混响时间。
由于基于语音信号或音乐信号等进行盲估计,因此不需要测量rir(schroeder方法)或录制的白噪声(interrupted方法)。混响时间可以替代地使用声学信号,根据最大似然法/信号衰减率分布等进行估计。主要应用有去混响、提高语音可懂度等。
在所述第一方面的另一种实现方式中,所述预定模型描述从所述较低频率范围中包括的较低频率到所述较高频率范围中包括的较高频率的混响时间变化。
该模型可以进行预先定义,使得设备能够快速精确地估计扩展的混响时间。
在所述第一方面的另一种实现方式中,所述设备用于通过分析多个不同房间类型的rir来构建所述预定模型。
因此,该模型包括多个不同房间类型和几何构造的精确指纹,并且所述设备可以精确地估计任何房间内的混响时间。
在所述第一方面的另一种实现方式中,所述设备用于在将所述较低频率范围内的所述频率相关混响时间扩展到所述较高频率范围之前,平滑所述频率相关混响时间。
这有助于减少由环境噪声造成的盲估计不准确。
在所述第一方面的另一种实现方式中,所述设备用于根据所述较低频率范围内的确定频率下所述平滑的频率相关混响时间的单个混响时间,计算所述预定模型的系数,以便根据所述预定模型将所述平滑的频率相关混响时间扩展到所述较高频率范围。
根据这些参数,可以精确估计扩展的混响时间。
在所述第一方面的另一种实现方式中,所述设备用于通过以下方式估计所述较低频率范围内的所述频率相关混响时间:使用滤波器组对所述录制的声学信号进行滤波;根据盲估计方法,估计所述滤波后的声学信号的多个频率信道中每个频率信道的混响时间。
例如,盲估计方法可以采用最大似然法或功率频谱密度估计。
在所述第一方面的另一种实现方式中,所述设备用于根据所述扩展的频率相关混响时间估计混合时间。
因此,所述第一方面的设备还获得混合时间作为估计的房间声学参数的一部分。也就是说,混合时间不是固定的,与房间有关,因此在合成brir时,可以得到更好的结果。
在所述第一方面的另一种实现方式中,所述设备用于通过以下方法估计所述混合时间:将所述较低频率范围内的确定频率下所述扩展的频率相关混响时间的单个混响时间乘以预定因子,或根据所述扩展的频率相关混响时间计算房间体积,并根据所述房间体积计算所述混合时间。
也就是说,提供了两种获取混合时间的方法,前者关注速度,后者关注精确度。
在所述第一方面的另一种实现方式中,所述设备用于根据所述扩展的频率相关混响时间合成brir。
因此,合成brir利用实际房间声学的知识来获得,并获得改进的双耳渲染。
在所述第一方面的另一种实现方式中,所述设备用于进一步根据所述混合时间合成所述brir。
从与实际房间的对应性角度来看,这进一步改进了brir。
在所述第一方面的另一种实现方式中,所述设备用于通过以下方式合成所述brir:使用所述扩展的频率相关混响时间合成所述brir的晚期混响部分;使用所述混合时间调整所述合成brir中的所述晚期混响部分的起始时间。
混合时间由早期反射声到晚期混响的过渡点(以时间计算)来定义。因此,获得适合实际房间的非常精确的brir。
在所述第一方面的另一种实现方式中,所述设备用于通过以下方式合成所述brir:根据所述扩展的频率相关混响时间,对白噪声或高斯白噪声进行重整形,以合成所述晚期混响部分;根据所述混合时间和窗函数截断所述晚期混响部分;将直接部分和/或早期反射声的hrtf与所述截断的晚期混响部分组合以获得整个brir。
本发明的第二方面提供一种用于估计声学参数的方法,所述方法包括:录制声学信号,特别是语音信号;根据所述录制的声学信号估计较低频率范围内的频率相关混响时间;并根据预定模型将所述频率相关混响时间扩展到较高频率范围,以获得扩展的频率相关混响时间。
在所述第二方面的一种实现方式中,所述较低频率范围包括8khz以下,特别是在1.4khz与8khz之间的频率;所述较高频率范围包括8khz以上,特别是在8khz与18khz之间的频率。
在所述第二方面的另一种实现方式中,所述方法包括:通过执行盲估计来估计所述较低频率范围内的所述频率相关混响时间。
在所述第二方面的另一种实现方式中,所述预定模型描述从所述较低频率范围中包括的较低频率到所述较高频率范围中包括的较高频率的混响时间变化。
在所述第二方面的另一种实现方式中,所述方法包括:通过分析多个不同房间类型的rir来构建所述预定模型。
在所述第二方面的另一种实现方式中,所述方法包括:在将所述较低频率范围内的所述频率相关混响时间扩展到所述较高频率范围之前,平滑所述频率相关混响时间。
在所述第二方面的另一种实现方式中,所述方法包括:根据所述较低频率范围内的确定频率下所述平滑的频率相关混响时间的单个混响时间,计算所述预定模型的系数,以便根据所述预定模型将所述平滑的频率相关混响时间扩展到所述较高频率范围。
在所述第二方面的另一种实现方式中,所述方法包括通过以下方式估计所述较低频率范围内的所述频率相关混响时间:使用滤波器组对所述录制的声学信号进行滤波;根据盲估计方法,估计所述滤波后的声学信号的多个频率信道中每个频率信道的混响时间。
在所述第二方面的另一种实现方式中,所述方法包括根据所述扩展的频率相关混响时间估计混合时间。
在所述第二方面的另一种实现方式中,所述方法包括通过以下方法估计所述混合时间:将所述较低频率范围内的确定频率下所述扩展的频率相关混响时间的单个混响时间乘以预定因子,或根据所述扩展的频率相关混响时间计算房间体积,并根据所述房间体积计算所述混合时间。
在所述第二方面的另一种实现方式中,所述方法包括根据所述扩展的频率相关混响时间合成brir。
在所述第二方面的另一种实现方式中,所述方法包括进一步根据所述混合时间合成所述brir。
在所述第二方面的另一种实现方式中,所述方法包括通过以下方式合成所述brir:使用所述扩展的频率相关混响时间合成所述brir的晚期混响部分;使用所述混合时间调整所述合成brir中的所述晚期混响部分的起始时间。
在所述第二方面的另一种实现方式中,所述方法包括通过以下方式合成所述brir:根据所述扩展的频率相关混响时间,对白噪声或高斯白噪声进行重整形,以合成所述晚期混响部分;根据所述混合时间和窗函数截断所述晚期混响部分;将直接部分和/或早期反射声的hrtf与所述截断的晚期混响部分组合以获得整个brir。
通过所述第二方面及其实现方式的方法,实现了所述第一方面及其相应实现方式的设备的上述优点和效果。
本发明的第三方面提供一种计算机程序产品,包括程序代码,其中,当所述程序代码由设备的一个或多个处理器执行时,用于控制所述设备执行所述第二方面提供的方法。
需要说明的是,本申请中描述的所有设备、元件、单元和模块可以在软件或硬件元件或其任何类型的组合中实现。本申请中描述的各种实体执行的所有步骤和所描述的将由各种实体执行的功能旨在表明各个实体适于或用于执行各自的步骤和功能。虽然在以下具体实施例的描述中,由外部实体执行的特定功能或步骤没有在执行该特定步骤或功能的该实体的具体详述元件的描述中反映,但是技术人员应该清楚,这些方法和功能可以在相应的硬件或软件元件或其任意组合中实现。
附图说明
结合所附附图,下面具体实施例的描述阐述本发明的各方面及其实现方式,其中:
图1示出了本发明实施例提供的设备;
图2示出了本发明实施例提供的方法;
图3分别示出了在本发明实施例提供的设备中的分析部分和合成部分的概述;
图4示出了在本发明实施例提供的设备中的分析部分;
图5示出了在本发明实施例提供的设备中估计频率相关混响时间的详细示例;
图6示出了在本发明实施例提供的设备中将混响时间扩展到较高频率范围的详细示例;
图7示出了示例性brir;
图8示出了在本发明实施例提供的设备中估计混合时间的详细示例;
图9示出了在本发明实施例提供的设备中的详细合成部分;
图10示出了使用传统方法估计混响时间的模拟结果;
图11示出了在本发明实施例提供的设备中估计混响时间的模拟结果;
图12示出了在本发明实施例提供的设备中合成brir的模拟结果;
图13示出了使用本发明的第一具体实施例提供的设备的场景;
图14示出了本发明的第一具体实施例提供的设备的框图;
图15示出了使用本发明的第二具体实施例提供的设备的场景;
图16示出了本发明的第二具体实施例提供的设备的框图;
图17示出了在本发明的第三具体实施例提供的设备中使用非个人化hrtf和晚期混响合成brir;
图18示出了在第三具体实施例中的合成brir的示例;
图19示出了在本发明的第四具体实施例提供的设备中使用参考brir和合成的晚期混响合成brir;
图20示出了在本发明的第四具体实施例中的合成brir的示例;
图21示出了在本发明的第五具体实施例提供的设备中使用非个人化hrtf、早期反射声和晚期混响合成brir;
图22示出了在本发明的第五具体实施例中的合成brir的示例;
图23示出了示例性brir。
具体实施方式
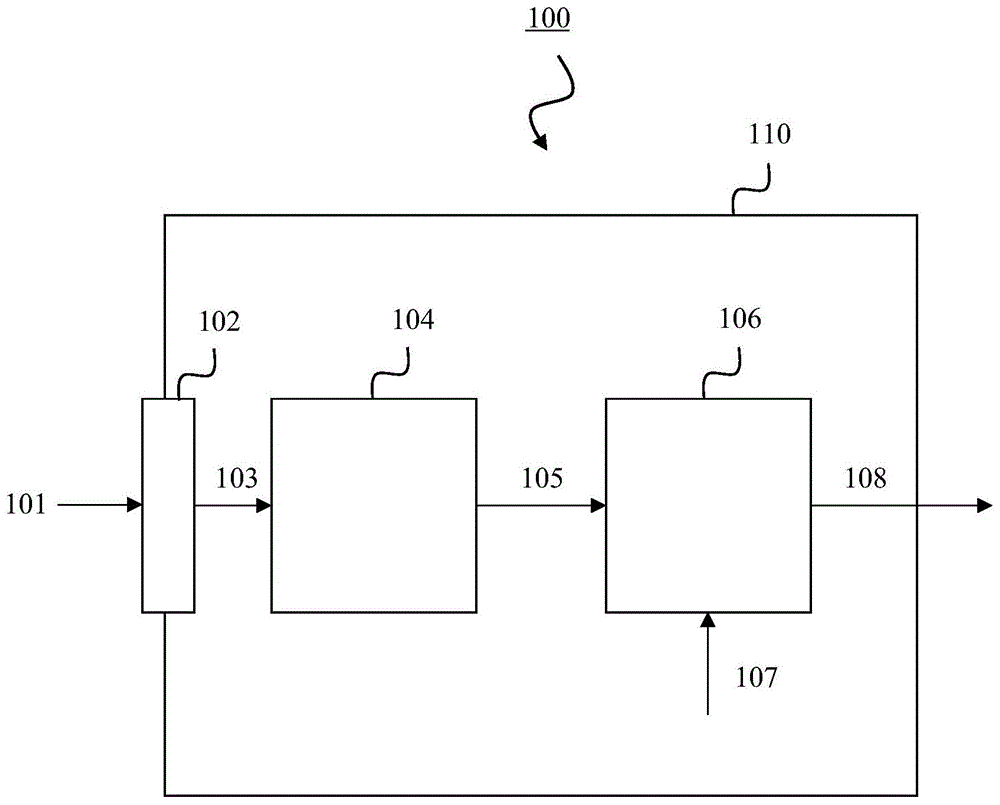
图1示出了本发明实施例提供的设备100。设备100用于估计房间声学参数,特别是实际房间的混响时间。
设备100可以包括处理电路110,用于执行下文描述的各种操作和方法。处理电路110可以包括硬件和软件。在一个实施例中,处理电路110包括一个或多个处理器(未示出)和与所述一个或多个处理器连接的非易失性存储器(未示出)。所述非易失性存储器可携带可执行的程序代码,当所述可执行的程序代码由一个或多个处理器执行时,使设备100执行所述操作或方法。
设备100用于录制(102)声学信号101,特别是语音信号。录制(102)可以通过单声道麦克风、双声道麦克风等进行。声学信号101通过录制成为录制的声学信号103。
设备100还用于根据录制的声学信号103,估计(104)较低频率范围内的频率相关混响时间105。估计(104)可以由处理电路110执行,处理电路110可以包括滤波器组(未示出)。较低频率范围可以包括8khz以下的频率,例如在1.4khz与8khz之间的频率。估计(104)可以通过盲估计来进行。
设备100还用于将较低频率范围的估计的频率相关混响时间105扩展(106)到较高频率范围,其中,扩展(106)基于预定模型107。由此获得扩展的频率相关混响时间108。扩展(106)可以由处理电路110执行,处理电路110可以包括一个或多个平滑滤波器(未示出)。较高频率范围可以包括8khz以上的频率,例如在8khz与18khz之间的频率。预定模型107可以描述从较低频率范围中包括的较低频率到较高频率范围中包括的较高频率的混响时间变化。模型107可以由设备100或预先由其它设备通过分析多个不同房间(类型、几何构造、大小)的rir来构建。
图2示出了本发明实施例提供的用于估计房间的声学参数,特别是混响时间的通用方法200。方法200可以由图1的设备100执行。方法200包括第一步骤:录制(102)声学信号101,特别是语音信号。此外,方法200包括第二步骤:根据录制的声学信号103,估计(104)较低频率范围内的频率相关混响时间105。此外,方法200包括第三步骤:根据预定模型107将频率相关混响时间105扩展(106)到较高频率范围,以便获得扩展的频率相关混响时间108。
下文根据本发明的其它实施例描述设备100(以及相应的方法200)的更多细节,其中,所有实施例均基于图1所示的设备100的通用实施例构建。因此,各个实施例中的相同元件和功能共用相同的附图标记。
图3分别示出了在本发明实施例提供的设备100中的分析部分和合成部分的概述。分析部分包括信号播放300(例如干语音信号的信号播放300)、信号的录制102,以及房间声学参数的估计301。估计301包括图1所示的混响时间的估计104和扩展106,即,获取扩展的混响时间108。合成部分包括根据估计的房间声学参数,特别是根据扩展的混响时间108和可选的混合时间402合成(303)brir(结合图4详细描述)。分析部分可以简单地由用户使用耳机或智能设备上的一个或多个麦克风完成,合成部分可以在智能设备上执行。下文分别描述分析部分和合成部分的细节。
图4示出了本发明实施例提供的设备100的分析部分结构的示例性概述。例如,使用单声道麦克风或一对双声道麦克风录制(102)一段语音信号101。然后,可以根据一个或多个录制的信号103盲估计(104)频率相关混响时间105。之后,可以平滑(400)估计的混响时间105(在图4中示例性地为1.4khz到8khz),然后例如从8khz扩展(106)到18khz,以便获得扩展的频率相关混响时间108。此外,可以根据获得的扩展混响时间108估计(401)混合时间402。
图5进一步示出了图4所示的盲估计104的示例。例如,使用单声道或一对双声道麦克风再次录制(102)一段语音信号101,以盲估计(104)频率相关混响时间105。然后,通过滤波器组500对录制的信号103进行滤波。例如,可以使用gammatone滤波器组或1/3倍频程滤波器组。然后,例如使用每个频率信道中信号的最大似然法估计频率相关混响时间105。这可以具体如‘
然而,由于语音信号101的频率范围,估计的混响时间105的频率仍然限制在8khz以内。此外,在噪声环境的情况下,获得的混响时间的准确度在低频到中频(例如,1.4khz到8khz)内鲁棒性可能不会很高。由于在中频到高频内没有盲估计的混响时间,因此难以根据混响时间105精确合成brir中的晚期混响部分。因此,设备100还用于获得全频率范围(例如,1.4-18khz)内的混响时间108。为此,设备100用于扩展(106)(在此为平滑并扩展400)混响时间105,以获得扩展的频率相关混响时间108。
图6示出了在本发明实施例提供的设备100中扩展(106)中频到高频的混响时间105的示例。通过分析rir603的大型数据库,例如airrir数据集,可以发现从中频到高频混响时间平滑变化。然而,在噪声环境的情况下,盲估计(104)混响时间105(例如1.4khz到8khz)的准确度可能会有所降低。因此,可以将平滑滤波器600应用于估计的混响时间105(例如1.4khz到8khz),以减少由环境噪声造成的测量不准确。例如,可以使用中值滤波器来平滑(600)混响时间105,但是也可以使用其它平滑方法或滤波器。此外,通过分析rir603的大型数据库,还发现从中频到高频,混响时间单调下降。因此,可以根据在不同房间中获得的频率相关混响时间构建(602)中频到高频的混响时间的模型107(其中,混响时间可以使用schroeder方法针对rir数据集中不同房间内的rir603进行计算)。模型107可以特别表示为:
t60,midtohigh为中频到高频内的混响时间;t60,4khz为4khz下的混响时间;fmidtohig表示滤波器组500的中频到高频中心频率。参数a通常大于0,而b通常小于0。这些参数可以使用以下等式获得:
用于计算参数a和b的这些等式(等式2和等式3)可以通过分析rir603的大型数据库来确定。例如,参数c1、c2、d1、d2、e1、e2、g1和g2为:0.003227、–0.03699、–0.006、0.0581、0.005581、–0.1155、–0.0005413、0.008851,这些值可以根据airrir数据库确定。对于实际的现实房间,应首先估计4khz下的混响时间(t60,4khz),然后可以根据模型107(等式1)计算中频到高频下的混响时间。也可以使用其它模型107(例如拟合函数)计算中频到高频内扩展的混响时间108,例如指数函数、高阶多项式函数等。
总之,可以在使用最大似然法等盲估计(104)混响时间105之后平滑例如1.4khz到8khz的混响时间105。然后,可以使用4khz下的混响时间来计算系数a和b。之后,可以根据所提出的模型107(等式1)获得例如从8khz到18khz的扩展的混响时间108。
混合时间402描述rir/brir(参见图7的示例性brir)中从早期反射声到晚期混响的过渡时间。本发明实施例提供的设备100还可以用于估计(401)混合时间402,以便调整使用盲估计的混响时间108获得的合成brir中的晚期混响部分。
图8示出了根据估计的扩展混响时间108计算混合时间402的两种示例性方式。在一种方式中,根据在500hz下测量的混响时间108直接预测(800)混合时间(其可以近似为0.08×混响时间)。这可以如‘hidaka,yamada和nakagawa,“房间脉冲响应中早期反射声与晚期混响之间的边界点的新定义(anewdefinitionofboundarypointbetweenearlyreflectionsandlatereverberationinroomimpulseresponses)”j.acoust.soc.am.,第122卷,第1期,第326-332页,2007’中所述进行。另一种方式为首先根据估计的扩展混响时间108预测(801)房间体积802(这可以如‘kuster,“根据单房间脉冲响应估计房间体积的可靠性(reliabilityofestimatingtheroomvolumefromasingleroomimpulseresponse)”j.acoust.soc.am.,第124卷,第2期,2008’中所述进行),然后根据预测的房间体积802计算(803)混合时间402(这可以如lindau等人“双耳房间脉冲响应中混合时间的基于模型和信号的预测因子的感知评价(perceptualevaluationofmodel-andsignal-basedpredictorsofthemixingtimeinbinauralroomimpulseresponses)”,j.audioengineeringsociety,第60卷,2012’中所述进行)。
根据实际房间的估计的房间声学参数(例如,频率相关的扩展混响时间108和可选的混合时间402),可以合成非常适于实际房间的brir。
图9示出了在本发明实施例提供的设备100中如何合成brir的示例。频率相关的扩展混响时间108用于合成brir中的晚期混响部分907,混合时间402可以用于使晚期混响适应brir。
特别地,如图9所示,可以首先通过滤波器组902对一对双声道高斯白噪声901(针对左耳和右耳)进行滤波。可以有利地使用与应用于分析部分(即混响时间估计)的滤波器组500相似或相同的滤波器组902。然后,可以根据每个频率信道中的频率相关混响时间108对滤波后的高斯白噪声903进行重整形(904)。例如,滤波后的高斯白噪声901可以通过使用指数函数h(f)相乘进行重整形(904),该指数函数的衰减率ρ(f)取决于混响时间:
a为晚期混响的缩放因子,取决于源听者的距离,通常限制在0与1之间。此外,n为采样点数量,fs为采样频率。例如,a、n和fs可以分别设置为1、8196个采样点和48khz。然后,可以将各频率信道中的重整形高斯白噪声905求和(906),以得到左耳和右耳的合成混响907。
之后,获得的混响907可以进一步通过基于估计的混合时间402的窗口截断(908)以适应合成brir。为了确保早期反射声与晚期混响之间的平滑过渡而没有可感知的伪影,可以使用例如具有10ms长上升时间的窗口,以截断(908)合成的晚期混响。由此获得加窗后的合成的晚期混响909,在此基础上可以合成(910)brir。
图10和图11的模拟结果说明了设备100(以及相应的方法200)获得全频带混响时间108的性能。对于这些模拟,将一段语音信号(采样频率为16khz)与从airrir数据集获得的演讲室rir进行卷积,如‘jeub等人“用于评价混响算法的双耳房间脉冲去混响数据库(abinauralroomimpulseresponsedatabasefortheevaluationofdereverberationalgorithms)”,internationalconferenceondigitalsignalprocessing(dsp),2009’中所述(下采样到16khz)。为了模拟环境噪声,在混响语音信号中加入不同snr(15db、20db、30db、40db、60db)的高斯白噪声。15db的snr表示十分嘈杂的环境,60db的snr表示相对安静的环境。以通过schroeder方法计算的混响时间作为基线(参考)。该schroeder方法是基于已知rir603的分析,并且通常用于计算混响时间。相比之下,本发明实施例提供的设备100和方法200是基于一段录制的语音信号102,而无需测量实际房间中的rir。
图10特别示出了使用传统方法的盲估计混响时间的结果。可以看出,由于语音信号的频率范围,混响时间限制在8khz以内,并且低频到中频(即,例如1.4khz到8khz)内估计的混响时间在噪声环境(低snr)中不稳定。
图11示出了使用本发明实施例提供的设备100(或相应的方法200)获得的估计的混响时间的结果。容易看出,通过平滑混响时间(这里为1.4khz到8khz)提高了低snr下估计的混响时间的准确度。此外,扩展了混响时间(这里为8khz到18khz),并且扩展的混响时间与基线匹配良好(schroeder方法)。
brir可以看作是直接声音、早期反射声和晚期混响的总和。图12示出了左耳的合成brir的示例,其中,使用通过本发明实施例提供的设备100(或相应的方法200)获得的直接声音的通用/非个人化hrtf、模拟的早期反射声和合成的晚期混响。下文进行详细描述。
下文描述了本发明的具体实施例提供的设备100。实施例分为两部分:首先为混响时间的分析(具体实施例1和2),其次为brir的合成(具体实施例3、4和5)。
实施例1分别如图13和图14所示,并基于使用单声道麦克风的混响时间的分析。如图13所示,在实际房间中,用户例如说一些短句(10-20s),并同时使用设备100(例如,具有麦克风的智能设备(例如,智能手机或平板电脑))录制声音。由于设备100在十分嘈杂的环境(例如,录制的信号的snr为15db)中也能良好工作,因此声源不必非常靠近麦克风,并且环境也不必非常安静。设备100根据录制的声音估计房间声学参数(混响时间108、混合时间402等)。然后,设备100根据估计的房间声学参数(例如,左耳和右耳的混响时间108)合成左耳和右耳的晚期混响907。图14示出了本实施例的设备100的框图。框的细节如上文结合图5、图6和图8所述。
实施例2分别如图15和图16所示,并基于使用一对双声道麦克风的混响时间的分析。如图15所示,用户可以在实际房间内在设备100(例如智能设备(例如,智能手机或平板电脑))上播放干语音文件,也可以说一些短句(10-20s),并同时使用一对双声道麦克风(例如主动噪声控制(activenoisecontrol,anc)耳机上的麦克风)录制声音。设备100使用录制的双耳信号来分别估计左耳和右耳的房间声学参数(例如,混响时间108、混合时间402等)。左耳和右耳的计算的房间声学参数还分别用于合成左耳和右耳的混响907。图16示出了本实施例的设备100的框图。框的细节如上文结合图5、图6和图8所述。
实施例3分别如图17和图18所示,并基于使用非个人化hrtf和晚期混响的brir的合成。brir可以看作是直接声音、早期反射声和晚期混响的总和。如图17所示,合成一对brir的最简单的方法是使用并组合(910)直接声音的通用/非个人化hrtf1700和合成的晚期混响907。以这种方式,不需要早期反射声,并且不需要知道确切的混合时间402。虽然缺乏早期反射声可能会导致感知的外部化和似真性降低,但仍然可以感知房间的性质(房间的大小、房间的混响等)。图18示出了由直接声音和晚期混响组成的合成brir。
实施例4分别如图19和图20所示,并基于使用参考brir和合成的晚期混响合成brir。晚期混响提供房间信息,有助于听者感知声环境。早期反射声提供空间信息,对虚拟声源的外部化很重要。在该实施例中,如图19所示,一组参考brir1800用于合成(910)实际房间中的brir。以这种方式,直接声音和早期反射声1801直接从参考brir1800获得,并且去除(1802)参考brir中的晚期混响部分,并根据从估计的房间声学参数(频率相关混响时间108和混合时间402)推导的晚期混响907,用加窗(截断910)后的合成的晚期混响909替换所述晚期混响部分。图20示出了基于参考brir1800和合成的晚期混响909的合成brir的示例。
实施例5分别如图21和图22所示,并基于使用非个人化hrtf、早期反射声和晚期混响的brir的合成。在该实施例中,brir看作是直接声音、早期反射声和晚期混响的总和。如图21所示,通用/非个人化hrtf1700用于产生直接声音部分。给定房间几何构造、一个或多个声源和听者的位置的额外信息2100,通用/非个人化hrtf1700也用于模拟(2102)早期反射声2103。具有实际房间声学的合成的晚期混响909适应brir。
模拟(2102)早期反射声2103有许多方法,如图像源方法、射线追踪法等。为了模拟(2102)早期反射声2013,应首先由用户确定房间内声源和听者的位置。此外,房间的几何构造(长、宽和高)应使用外部传感器(如ar耳机)估计,或由用户提供。根据房间的几何构造、听者和虚拟声源的位置,可以使用图像源方法等模拟早期反射声。图像源的数量取决于智能设备的性能。然后,根据混合时间402,将根据混响时间108计算的晚期混响909添加到合成brir中。图22示出了使用该方法合成的左耳brir的示例。
已经结合作为实例的不同实施例以及实现方式描述了本发明。然而,根据对附图、本发明和所附权利要求书的研究,本领域技术人员在实践所要求保护的发明时,能够理解和实现其它变化。在权利要求以及说明书中,词语“包括”不排除其它元件或步骤,且“一个”不排除多个。单个元件或其它单元可满足权利要求书中所叙述的若干实体或项目的功能。在互不相同的从属权利要求中列举某些措施并不表示这些措施的组合不能用于有益的实现方式。
- 还没有人留言评论。精彩留言会获得点赞!