颤音建模方法、装置、计算机设备及存储介质与流程
本申请涉及人工智能技术领域,尤其涉及一种颤音建模方法、装置、计算机设备及存储介质。
背景技术:
近年来,基于隐马尔可夫模型进行参数合成的歌曲合成方法在业界非常受关注。使用隐马尔可夫模型合成歌曲的最大优点是,在不需要庞大的歌唱数据库的情况下,可以有效的模拟不同的声音特征,歌唱风格,甚至是情绪。而颤音,作为一种重要的歌唱技巧,对合成歌曲的自然度有很大的影响。颤音在声学特征上的具体体现为基频上的小幅震动,颤音的具体时间点和强度因歌手而异。然而普通的隐马尔可夫模型会在训练和合成时平滑基频上的小幅度的起伏,如此会平滑掉颤音,导致合成的歌唱中并没有颤音的效果。
技术实现要素:
本申请实施例提供一种颤音建模方法、装置、计算机设备及存储介质,可保留颤音特征,以提高合成歌曲的自然度。
第一方面,本申请实施例提供了一种颤音建模方法,该方法包括:
获取多首歌的歌曲数据,其中,每一首歌的歌曲数据包括一篇标有歌词的乐谱和一段与所述乐谱相符的清唱录音;提取所述乐谱的语言学特征和音乐特征;提取所述清唱录音的声学特征;根据所述声学特征提取所述清唱录音的颤音特征;基于隐马尔可夫模型,以所述乐谱的语言学特征和音乐特征为输入,以所述清唱录音的声学特征和颤音特征为输出,训练得到颤音模型。
第二方面,本发明实施例提供了一种颤音建模装置,该颤音建模装置包括用于执行上述第一方面所述的方法对应的单元。
第三方面,本发明实施例提供了一种计算机设备,所述计算机设备包括存储器,以及与所述存储器相连的处理器;
所述存储器用于存储计算机程序,所述处理器用于运行所述存储器中存储的计算机程序,以执行上述第一方面所述的方法。
第四方面,本发明实施例提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时,实现上述第一方面所述的方法。
本申请实施例通过提取清唱录音的颤音特征,基于隐马尔可夫模型,将歌曲的乐谱的语言学特征和音乐特征作为输入,将该歌曲的清唱录音的声学特征和颤音特征作为输出,如此,得到输入为所述乐谱的语言学特征和音乐特征,输出为所述清唱录音的声学特征和颤音特征的颤音模型。该颤音模型可有效的保留颤音特征,以提高合成歌曲的自然度。
附图说明
为了更清楚地说明本发明实施例技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本申请实施例提供的颤音建模方法的流程示意图;
图2是本申请实施例提供的一个音符所对应的标签对数据;
图3是本申请实施例提供的一段清唱录音所对应的基频的示意图;
图4是本申请实施例提供的颤音建模方法的子流程示意图;
图5是本申请另一实施例提供的颤音建模方法的子流程示意图;
图6是本申请另一实施例提供的颤音建模方法的流程示意图;
图7是本申请实施例提供的颤音建模装置的示意性框图;
图8是本申请实施例提供的颤音定位单元的示意性框图;
图9是本申请另一实施例提供的颤音定位单元的示意性框图;
图10是本申请另一实施例提供的颤音建模装置的示意性框图;
图11是本申请实施例提供的计算机设备的示意性框图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
图1是本申请实施例提供的颤音建模方法的流程示意图。如图1所示,该方法包括s101-s105。
s101,获取多首歌的歌曲数据,其中,每一首歌的歌曲数据包括一篇标有歌词的乐谱和一段与所述乐谱相符的清唱录音。
其中,每一首歌的清唱录音是与该乐谱对应的清唱录音,即乐谱和清唱录音是对应的。其中,乐谱是以文本文件的形式存在。通常情况下,用一些软件如musescore制作电子乐谱时,可以直接将乐谱文件保存为一些预设的格式文件如musicxml格式。这类的格式文件其本质是有特殊格式的文本文件。
s102,提取所述乐谱的语言学特征和音乐特征。
从整体来看,一个乐谱文件的结构如下:
·音调
·谱号
·拍号
·速度
·(一些显示信息)
·第一小节:
·音符
·音符
·音符
……
·第二小节:
·音符
……
……
一个乐谱文件中通常包括音调、谱号、拍号、速度、显示信息(显示信息与音符在乐谱编辑软件中的视觉显示有关,与模型的训练无关,可忽略)、多个小节等信息。其中,每个小节中包括多个音符。每个音符中包括音高、时长、声部、音符类型、歌词等信息。而音高包括音阶和八度等信息,歌词包括音节、文本等信息。
乐谱文件中以标签对的形式来标识乐谱文件的各种信息,如<></>即为一个标签对。图2是本申请实施例提供的一个音符所对应的标签对数据。需要注意的是,图2中的汉字所对应的是注解,以方便理解该音符所对应的标签对数据的含义。如图2所示,<note>和</note>这个标签之间包含了关于这个音符所有信息。而其中的<pitch>和</pitch>之间记录了该音符的音高信息,<duration>和</duration>之间记录了该音符的时长信息,<voice>和</voice>之间记录了该音符的声部信息,<type>和</type>之间记录了该音符的音符类型,<stem>和</stem>之间记录了该音符的显示信息(显示信息与音符在乐谱编辑软件中的视觉显示有关,与模型的训练无关,可忽略),<lyric>和</lyric>之间记录了该音符的歌词信息。其中,音高信息<pitch>和</pitch>中的<step>和</step>之间记录了音高信息中的音阶,<octave>和</octave>之间记录了音高信息中的八度;<lyric>和</lyric>中的<syllabic>和</syllabic>之间记录了歌词的音节,<text>和</text>之间记录了歌词文本。通过寻找标签对,可以读取到每个标签对中具体的关键字(如pitch、step、lyric等关键字)和关键字对应值的信息。
在一个乐谱文件中,“音调”、“谱号”、“拍号”、“速度”、每个音符的“音高”、“时长”、“声部”和“音符类型”都是音乐特征,“歌词”则是文本特征,对应语言学特征。具体地,步骤s102,即提取所述乐谱的语言学特征和音乐特征,包括:获取乐谱文件中的便签对;解析标签对,以提取标签对中所对应的音乐特征以及语言学特征的值。其中,语言学特征包括歌词的发音,以及上下前后文的关系等。如此通过获取并解析乐谱文件中的标签对,提取乐谱中的语言学特征和音乐特征,达到提取特征的目的。
s103,提取所述清唱录音的声学特征。
其中,声学特征包括基频和梅尔频谱系数等。每一帧对应一组特征。
基音的频率称为基频,而基音就是指发浊音时声带振动的周期性,基频是语音中频率最低的纯音,但振幅确是最大的,决定整个音的升高。基频作为语音的主要特征,广泛应用于语音编码、语音识别、语音合成等领域。
清唱录音的基频特征的提取方法有很多种,大致可以分为三类:一,时域分析算法,如自相关法(acf)、短时平均幅度差法(amdf)等;二,频域分析算法,如倒谱法(cep)等;三,时频结合的分析算法,如小波分析算法等。还可以使用其他的基频提取方法来提取清唱录音的基频。其中,提取出的清唱录音的基频为基频序列。
梅尔倒谱系数是在mel标度频率域提取出来的倒谱参数,mel标度描述了人耳频率的非线性特性。提取梅尔倒谱系数的方法主要包括:
对清唱录音的语音信号进行采样处理以得到清唱录音的数字语音信号;将清唱录音的数字语音信号进行预加重处理;将预加重处理后的数字语音信号进行分帧处理;将分帧处理后的数字语音信号进行加窗处理;将加窗处理后的数字语音信号进行快速傅里叶变换以得到频域的声音信号;通过三角形带通滤波器组对频域的声音信号进行滤波以使三角形带通滤波器中的每个滤波器分别输出滤波结果,其中,该三角形带通滤波器包括p个滤波器;将每个滤波器输出的滤波结果分别取对数以得到声音信号的p个对数能量;将所得的p个对数能量进行离散余弦变化得到梅尔频率倒谱系数的p阶分量。其中,p可以在22-26范围内取值,也可以在其他合适的范围内取值。
其中,预加载处理就是将清唱录音的数字语音信号通过一个高通滤波器,预加重的目的是提升高频部分,使得清唱录音的数字语音信号的频谱变得平坦,移除频谱倾斜,来补偿语音信号受到发音系统所抑制的高频部分;同时,也是为了消除发生过程中声带和嘴唇的效应。使用三角带通滤波器的目的是对频谱进行平滑化,并消除谐波的作用,此外还可以减少运算量。
s104,根据所述声学特征提取所述清唱录音的颤音特征。
在本实施例中,认为颤音是出现在基频序列上小幅的正弦的波动,颤音特征包括振幅和频率。根据所述声学特征提取所述清唱录音的颤音特征,包括:根据所述声学特征中的基频来提取所述清唱录音的颤音特征。
在一实施例中,步骤s104,包括:定位所述基频所对应的基频序列中的颤音片段;计算所述颤音片段的振幅和频率,将计算出的所述颤音片段的振幅和频率作为所述颤音片段中每一帧的颤音特征。
在一实施例中,还需将所述基频中的非颤音片段的振幅和频率设置为零,如此,以得到所述清唱录音的颤音特征。可以理解地,计算颤音片段的振幅和频率,将计算出的振幅和频率作为颤音特征;对于清唱录音中的非颤音片段,即没有颤音或者静音的片段,设置振幅和频率都为零。
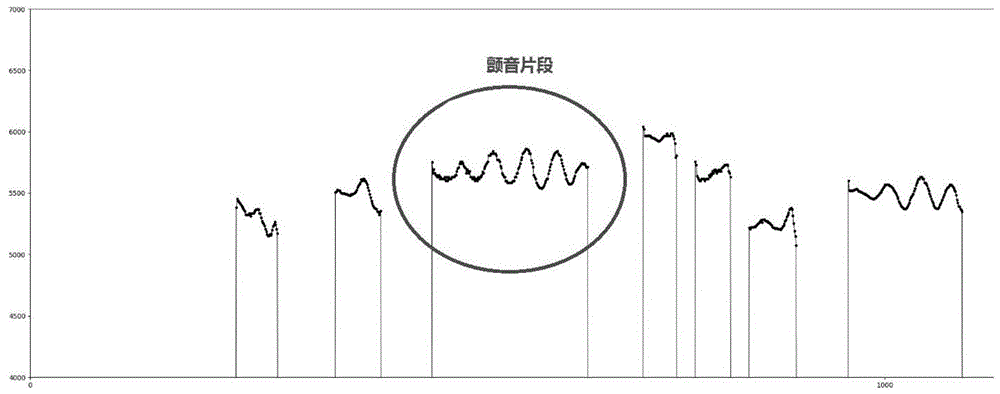
图3是本申请实施例提供的一段清唱录音所对应的基频的示意图。图3中横轴是时间,单位为0.5毫秒;纵轴为基频,单位为森特。椭圆圈的部分即为颤音片段,具体地定位基频所对应的基频序列中的颤音片段的方法下文将具体介绍。其中,可以看出颤音是出现在基频序列上小幅的正弦的波动。其他没有颤音或者静音的片段,设置振幅和频率都为零。
在一实施例中,如图4所示,定位所述基频所对应的基频序列中的颤音片段,包括s401-s405。
s401,检测所述基频序列中连续出现波谷或者波峰的次数是否达到预设次数。
其中,连续出现波谷或者波峰意味着该基频序列片段没有间断,即该基频序列片段是不间断的,在一些实施例中,也可以理解为,该基频序列片段中没有频率为0的频率。检测在一个不间断的基频序列片段中出现波谷或者波峰的次数是否达到预设次数。其中,连续出现波谷或者波峰的次数可以刚好是预设次数,也可以超过预设次数。刚好是预设次数,或者超过预设次数,都认为达到预设次数。其中,预设次数可以设置为5次,也可以设置为其他的次数。
若所述基频序列中连续出现波谷或者波峰的次数达到预设次数,执行步骤s402;否则,执行步骤s405。
s402,获取所对应的基频序列片段,并统计该基频序列片段中的平均频率。
基频序列片段中的平均频率通过获取该基频序列片段中每一帧的频率,将该基频序列片段中每一帧的频率之和,除以该基频序列片段中的总帧数,以得到该基频序列片段中的平均频率。
s403,检测预设次数中每次频率由波谷到波峰或者频率由波峰到波谷的过程中,波谷所对应的频率是否小于平均频率,且波峰所对应的频率是否大于平均频率。
若每次波谷所对应的频率小于平均频率,且波峰所对应的频率大于平均频率,执行步骤s404;否则,执行步骤s405。
s404,确定该基频序列片段为颤音片段。
s405,确定该基频序列片段为非颤音片段。
即基频序列中连续出现波谷或者波峰的次数未达到预设次数;或者达到预设次数,但是并非每次波谷所对应的频率小于平均频率、且波峰所对应的频率大于平均频率,那么确定该频率序列片段为非颤音片段。
该实施例中通过判断基频序列中的基频是否连续预设次数或者预设次数以上由高到低,或由低到高的穿过该基频序列片段的平均基频。若是,则认为是该基频序列片段为颤音片段,否则,认为该基频序列片段为非颤音片段。如图3所示,所确定颤音片段的频率是连续预设次数或者预设次数以上由高到低穿过该基频序列片段的平均基频。
在一实施例中,预设次数的判断可通过统计该基频序列中出现频率连续由波谷到波峰或者频率连续由波峰到波谷的次数,即判断基频序列中出现频率连续由波谷到波峰或者频率连续由波峰到波谷的次数是否达到预设次数。
其中,连续波谷到波峰理解为基频的频率从一个波谷到达波峰(再达到波谷),紧接着又从波谷到达一个波峰(再达到波谷),如此连续的从波谷到达波峰的次数是否达到预设次数。需要注意的是,在该过程中,基频的频率并未间断。其中,预设次数可以设置为5次。基频连续由高到低的理解也是一致,只是统计的是基频从波峰到达波谷的次数。
由于颤音的频率范围是在一个预设赫兹频域范围内,如预设赫兹频域范围是5到8赫兹,因此如果某一基频序列片段是颤音片段,那么该基频序列片段的基频以一个5到8赫兹之间的频率f在振动。在一实施例中,如图5所示,定位所述基频所对应的基频序列中的颤音片段,包括s501-s508。
s501,对所述基频序列中的基频序列片段做短时距傅里叶变换,得到基频序列片段的功率谱。
将基频的功率谱表示为x(f,t),其中,f为基频的震动频率,t为时间。则x(f,t)可以理解为是在时间点t时,频率为f的波形(如图3所示的基频曲线)的振幅。
s502,将所述功率谱进行正则化以得到正则化函数。
即对x(f,t)进行正则化以得到正则化函数
s503,计算正则化函数在预设赫兹频域范围上的积分,以得到所述基频序列片段的功率。
若预设赫兹频域范围为5到8赫兹,对
s504,计算正则化函数在所述基频序列片段中的斜率变化。
其中,斜率变化越大代表函数值的尖峰越明显。计算斜率变化的计算公式如下:
s505,根据计算出的所述基频序列片段的功率和斜率变化确定颤音概率。
其中,在时间t时,根据计算出的所述基频序列片段的功率和斜率变化确定颤音概率pv(t)的计算公式为:pv(t)=sv(t)ψv(t)。
pv(t)的值越大,说明该时间点t属于颤音片段的可能性越大。
s506,判断所述颤音概率是否超过预设数值。
若所述颤音概率超过预设数值,则认为该时间点属于颤音片段中的点。若连续多个点判断出来都是属于颤音片段,那么该基频序列片段则属于颤音片段。
若所述颤音概率超过预设数值,执行步骤s507;若所述颤音概率未超过预设数值,执行步骤s508。
s507,确定所述基频序列片段为颤音片段。
s508,确定所述基频序列片段为非颤音片段。
其中,需要注意的是,计算斜率变化和计算功率的步骤的先后顺序不做具体限定,也可以先计算功率再计算斜率变化。
该实施例中,可以理解为,若某一个基频序列片段中预设赫兹频域范围段(如5到8赫兹这个频率段)的功率高于其他频率段;频率为f的波形振幅要明显的大于5到8赫兹之间其他波形的振幅,那么认为该基频序列片段是颤音片段。
在一实施例中,也可以将以附图4和图5两个实施例中的判断方法结合起来以用来定位基频序列中的颤音片段,那么可以理解地,基连续预设次数以上由高到低,或由低到高的穿过该片段的平均基频,且计算出的颤音概率超过预设数值,那么确认该时间点所在的基频序列片段是颤音片段。
在一实施例中,也可以将以上两个实施例中的判断方法结合起来以用来定位基频序列中的颤音片段,那么可以理解地,基连续预设次数以上由高到低,或由低到高的穿过该片段的平均基频,且计算出的颤音概率超过预设数值,那么确认该时间点所在的基频序列片段是颤音片段。
s105,基于隐马尔可夫模型,以所述乐谱的语言学特征和音乐特征为输入,以所述清唱录音的声学特征和颤音特征为输出,训练得到颤音模型。
可以理解地,将所述乐谱的语言学特征和音乐特征作为输入,输入到隐马尔科夫模型中,训练该隐马尔科夫模型,以使得输出为所述清唱录音的声学特征和颤音特征。将训练得到的隐马尔科夫模型作为颤音模型。
以上方法实施例通过提取清唱录音的颤音特征,基于隐马尔可夫模型,将歌曲的乐谱的语言学特征和音乐特征作为输入,将该歌曲的清唱录音的声学特征和颤音特征作为输出,如此,得到输入为所述乐谱的语言学特征和音乐特征,输出为所述清唱录音的声学特征和颤音特征的颤音模型。以上方法实施例实现了颤音模型的训练。该颤音模型可有效的保留颤音特征,以在合成歌曲时提高合成歌曲的自然度。
图6是本申请另一实施例提供的颤音建模方法的示意流程图。如图6所示,该实施例包括步骤s601-s609。其中,该实施例与图1实施例的区别在于:增加了步骤s606-s609,其他步骤s601-s605与图1实施例的步骤s101-s105分别对应。下面将详细介绍该实施例与图1实施例的区别之处。
s606,提取待合成歌曲的乐谱的语言学特征和音乐特征。
其中,提取待合成歌曲的乐谱的语言学特征和音乐特征的方法请参看图1实施例中的提取乐谱的语言学特征和音乐特征的描述,在此不再赘述。
s607,将提取的语言学特征和音乐特征输入到训练好的颤音模型中,以得到与所述待合成歌曲的乐谱相符的清唱录音的声学特征和颤音特征。
s608,在所得到的声学特征中加入所得到的颤音特征。
首先判断待合成歌曲中的每一帧是否为静音;如果是静音,那么基频不变;如果不为静音,那么就在基频上加入所得到的颤音特征。如此,在基频上加入了颤音特征。具体地,在基频上加入所得到的颤音特征,包括:在基频上加入与所得到的颤音特征的振幅和频率对应的正弦波来模拟颤音。该处的对应理解为相同,即在基频上加入与所得到的颤音特征的振幅和频率相同的正弦波来模拟颤音。
s609,将加入了颤音特征的声学特征输入声码器,以合成歌曲。
输入到声码器中的声学特征包括:加入了颤音特征的基频和梅尔频谱系数。
声码器(vocoder),是语音信号某种模型的语音分析合成系统。在传输中只利用模型中的特征参数,在编译码时利用模型中的特征参数估计和语音合成的语音信号编译码器,一种对话音进行分析和合成的编、译码器。
该实施例进一步通过训练好的颤音模型来得到待合成歌曲的乐谱相符的清唱录音的声学特征和颤音特征,并将得到的颤音特征加入到声学特征中的基频中,如此,声学特征(包括基频和梅尔频谱系数)中可以表达颤音。在将加入了颤音特征的声学特征合成歌曲时,歌曲中可以很好的体现颤音,如此,使生成的歌曲的自然度显著提升。
图7是本申请实施例提供的颤音建模装置的示意性框图。如图7所示,该装置包括用于执行上述颤音建模方法所对应的单元。具体地,如图7所示,该装置70包括歌曲数据获取单元701、音乐特征提取单元702、声学特征提取单元703、颤音特征提取单元704以及模型建立单元705。
歌曲数据获取单元701,用于获取多首歌的歌曲数据,其中,每一首歌的歌曲数据包括一篇标有歌词的乐谱和一段与所述乐谱相符的清唱录音。
音乐特征提取单元702,用于提取所述乐谱的语言学特征和音乐特征。具体地,音乐特征提取单元702,包括标签对获取单元、解析单元。其中,标签对获取单元,用于获取所述乐谱所对应的乐谱文件中的标签对。解析单元,用于解析所述标签对,以提取所述标签对中所对应的音乐特征以及语言学特征的值。
声学特征提取单元703,用于提取所述清唱录音的声学特征。其中,所述声学特征包括基频和梅尔频谱倒数。
颤音特征提取单元704,用于根据所述声学特征提取所述清唱录音的颤音特征。具体地,根据所述声学特征中的基频提取所述清唱录音的颤音特征。颤音特征包括振幅和频率。
在一实施例中,颤音特征提取单元704,包括:颤音定位单元、颤音特征确定单元。其中,颤音定位单元,用于定位所述基频所对应的基频序列中的颤音片段。颤音特征确定单元,用于计算所述颤音片段的振幅和频率,将计算出的所述颤音片段的振幅和频率作为所述颤音片段中每一帧的颤音特征。
在一实施例中,颤音特征提取单元704还包括设置单元。所述设置单元,用于将所述基频中的非颤音片段的振幅和频率设置为零。如此,以得到所述清唱录音的颤音特征。
在一实施例中,如图8所示,颤音定位单元80包括次数检测单元801、统计单元802、频率检测单元803以及第一颤音确定单元804。其中,次数检测单元801,用于检测所述基频序列中连续出现波谷或者波峰的次数是否达到预设次数。统计单元802,用于若达到预设次数,获取所对应的基频序列片段,并统计该基频序列片段中的平均频率。频率检测单元803,用于检测预设次数中每次频率由波谷到波峰或者频率由波峰到波谷的过程中,波谷所对应的频率是否小于平均频率,且波峰所对应的频率是否大于平均频率。第一颤音确定单元804,用于若每次波谷所对应的频率小于平均频率,且波峰所对应的频率大于平均频率,确定该基频序列片段为颤音片段。第一颤音确定单元804,还用于若基频序列中连续出现波谷或者波峰的次数未达到预设次数;或者达到预设次数,但是并非每次波谷所对应的频率小于平均频率、且波峰所对应的频率大于平均频率,确定该基频序列片段为非颤音片段。
在一实施例中,如图9所示,颤音定位单元90包括变换单元901、正则化单元902、功率计算单元903、斜率变化计算单元904、概率计算单元905、概率判断单元906以及第二颤音确定单元907。其中,变换单元901,用于对所述基频序列中的基频序列片段做短时距傅里叶变换,得到基频序列片段的功率谱。正则化单元902,用于将所述功率谱进行正则化以得到正则化函数。功率计算单元903,用于计算正则化函数在预设赫兹频域范围上的积分,以得到所述基频序列片段的功率。斜率变化计算单元904,用于计算正则化函数在所述基频序列片段中的斜率变化。概率计算单元905,用于根据计算出的所述基频序列片段的功率和斜率变化确定颤音概率。概率判断单元906,用于判断所述颤音概率是否超过预设数值。第二颤音确定单元907,用于若所述颤音概率超过预设数值,确定所述基频序列片段为颤音片段;若所述颤音概率未超过预设数值,确定所述基频序列片段为非颤音片段。
模型建立单元705,用于基于隐马尔可夫模型,以所述乐谱的语言学特征和音乐特征为输入,以所述清唱录音的声学特征和颤音特征为输出,训练得到颤音模型。
图10本申请实施例提供的颤音建模装置的示意性框图。如图10所示,该装置包括用于执行上述颤音建模方法所对应的单元。具体地,如图10所示,该装置100包括歌曲数据获取单元101、音乐特征提取单元102、声学特征提取单元103、颤音特征提取单元104、模型建立单元105、模型使用单元106、颤音加入单元107以及合成单元108。其中,该实施例与图7所示的实施例的不同之处在于:增加了模型使用单元106、颤音加入单元107以及合成单元108。下面将描述该实施例与图7实施例的不同之处,其他的单元与图7实施例所示的单元分别对应,在此不再赘述。
音乐特征提取单元102,还用于提取待合成歌曲的乐谱的语言学特征和音乐特征。
模型使用单元106,用于将提取的语言学特征和音乐特征输入到训练好的颤音模型中,以得到与所述待合成歌曲的乐谱相符的清唱录音的声学特征和颤音特征。
颤音加入单元107,用于在所得到的声学特征中加入所得到的颤音特征。
合成单元108,用于将加入了颤音特征的声学特征输入声码器,以合成歌曲。
需要说明的是,所属领域的技术人员可以清楚地了解到,上述装置和各单元的具体实现过程,可以参考前述方法实施例中的相应描述,为了描述的方便和简洁,在此不再赘述。
上述装置可以实现为一种计算机程序的形式,计算机程序可以在如图11所示的计算机设备上运行。
图11为本申请实施例提供的一种计算机设备的示意性框图。该设备为终端等设备,如移动终端、pc终端、ipad等。该设备110包括通过系统总线111连接的处理器112、存储器和网络接口113,其中,存储器可以包括非易失性存储介质114和内存储器115。
该非易失性存储介质114可存储操作系统1141和计算机程序1142。该非易失性存储介质中所存储的计算机程序1142被处理器112执行时,可实现上述所述的颤音建模方法。该处理器112用于提供计算和控制能力,支撑整个设备的运行。该内存储器115为非易失性存储介质中的计算机程序的运行提供环境,该计算机程序被处理器112执行时,可使得处理器112执行上述所述的颤音建模方法。该网络接口113用于进行网络通信。本领域技术人员可以理解,图11中示出的结构,仅仅是与本申请方案相关的部分结构的框图,并不构成对本申请方案所应用于其上的设备的限定,具体的设备可以包括比图中所示更多或更少的部件,或者组合某些部件,或者具有不同的部件布置。
其中,所述处理器112用于运行存储在存储器中的计算机程序,以实现如下步骤:
获取多首歌的歌曲数据,其中,每一首歌的歌曲数据包括一篇标有歌词的乐谱和一段与所述乐谱相符的清唱录音;提取所述乐谱的语言学特征和音乐特征;提取所述清唱录音的声学特征;根据所述声学特征提取所述清唱录音的颤音特征;基于隐马尔可夫模型,以所述乐谱的语言学特征和音乐特征为输入,以所述清唱录音的声学特征和颤音特征为输出,训练得到颤音模型。
在一实施例中,所述处理器112还具体实现如下步骤:
提取待合成歌曲的乐谱的语言学特征和音乐特征;将提取的语言学特征和音乐特征输入到训练好的颤音模型中,以得到与所述待合成歌曲的乐谱相符的清唱录音的声学特征和颤音特征;在所得到的声学特征中加入所得到的颤音特征;将加入了颤音特征的声学特征输入声码器,以合成歌曲。
在一实施例中,所述声学特征包括基频,所述处理器112在执行所述根据所述声学特征提取所述清唱录音的颤音特征的步骤时,具体实现如下步骤:
定位所述基频所对应的基频序列中的颤音片段;计算所述颤音片段的振幅和频率,将计算出的所述颤音片段的振幅和频率作为所述颤音片段中每一帧的颤音特征。
在一实施例中,所述处理器112在执行所述定位所述基频所对应的基频序列中的颤音片段的步骤时,具体实现如下步骤:
检测所述基频序列中连续出现波谷或者波峰的次数是否达到预设次数;若达到预设次数,获取所对应的基频序列片段,并统计该基频序列片段中的平均频率;检测预设次数中每次频率由波谷到波峰或者频率由波峰到波谷的过程中,波谷所对应的频率是否小于平均频率,且波峰所对应的频率是否大于平均频率;若每次波谷所对应的频率小于平均频率,且波峰所对应的频率大于平均频率,确定该基频序列片段为颤音片段;否则,确定该基频序列片段为非颤音片段。
在一实施例中,所述处理器112在执行所述定位所述基频所对应的基频序列中的颤音片段的步骤时,具体实现如下步骤:
对所述基频序列中的基频序列片段做短时距傅里叶变换,得到基频序列片段的功率谱;将所述功率谱进行正则化以得到正则化函数;计算正则化函数在预设赫兹频域范围上的积分,以得到所述基频序列片段的功率;计算正则化函数在所述基频序列片段中的斜率变化;根据计算出的所述基频序列片段的功率和斜率变化确定颤音概率;判断所述颤音概率是否超过预设数值;若所述颤音概率超过预设数值,确定所述基频序列片段为颤音片段;否则,确定所述基频序列片段为非颤音片段。
在一实施例中,所述处理器112在执行所述提取所述乐谱的语言学特征和音乐特征的步骤时,具体实现如下步骤:
获取所述乐谱所对应的乐谱文件中的标签对;解析所述标签对,以提取所述标签对中所对应的音乐特征以及语言学特征的值。
在一实施例中,所述处理器112在执行所述在所得到的声学特征中加入所得到的颤音特征的步骤时,具体实现如下步骤:
在所得到的声学特征中加入与所述颤音特征的振幅和频率对应的正弦波。
应当理解,在本申请实施例中,所称处理器112可以是中央处理单元(centralprocessingunit,cpu),该处理器还可以是其他通用处理器、数字信号处理器(digitalsignalprocessor,dsp)、专用集成电路(应用程序licationspecificintegratedcircuit,asic)、现成可编程门阵列(field-programmablegatearray,fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。
本领域普通技术人员可以理解的是实现上述实施例的方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成。该计算机程序可存储于一存储介质中,该存储介质可以为计算机可读存储介质。该计算机程序被该计算机系统中的至少一个处理器执行,以实现上述方法的实施例的流程步骤。
因此,本申请还提供了一种存储介质。该存储介质可以为计算机可读存储介质。该存储介质存储有计算机程序,该计算机程序当被处理器执行时实现以下步骤:
获取多首歌的歌曲数据,其中,每一首歌的歌曲数据包括一篇标有歌词的乐谱和一段与所述乐谱相符的清唱录音;提取所述乐谱的语言学特征和音乐特征;提取所述清唱录音的声学特征;根据所述声学特征提取所述清唱录音的颤音特征;基于隐马尔可夫模型,以所述乐谱的语言学特征和音乐特征为输入,以所述清唱录音的声学特征和颤音特征为输出,训练得到颤音模型。
在一实施例中,所述处理器还具体实现如下步骤:
提取待合成歌曲的乐谱的语言学特征和音乐特征;将提取的语言学特征和音乐特征输入到训练好的颤音模型中,以得到与所述待合成歌曲的乐谱相符的清唱录音的声学特征和颤音特征;在所得到的声学特征中加入所得到的颤音特征;将加入了颤音特征的声学特征输入声码器,以合成歌曲。
在一实施例中,所述声学特征包括基频,所述处理器在执行所述根据所述声学特征提取所述清唱录音的颤音特征的步骤时,具体实现如下步骤:
定位所述基频所对应的基频序列中的颤音片段;计算所述颤音片段的振幅和频率,将计算出的所述颤音片段的振幅和频率作为所述颤音片段中每一帧的颤音特征。
在一实施例中,所述处理器在执行所述定位所述基频所对应的基频序列中的颤音片段的步骤时,具体实现如下步骤:
检测所述基频序列中连续出现波谷或者波峰的次数是否达到预设次数;若达到预设次数,获取所对应的基频序列片段,并统计该基频序列片段中的平均频率;检测预设次数中每次频率由波谷到波峰或者频率由波峰到波谷的过程中,波谷所对应的频率是否小于平均频率,且波峰所对应的频率是否大于平均频率;若每次波谷所对应的频率小于平均频率,且波峰所对应的频率大于平均频率,确定该基频序列片段为颤音片段;否则,确定该基频序列片段为非颤音片段。
在一实施例中,所述处理器在执行所述定位所述基频所对应的基频序列中的颤音片段的步骤时,具体实现如下步骤:
对所述基频序列中的基频序列片段做短时距傅里叶变换,得到基频序列片段的功率谱;将所述功率谱进行正则化以得到正则化函数;计算正则化函数在预设赫兹频域范围上的积分,以得到所述基频序列片段的功率;计算正则化函数在所述基频序列片段中的斜率变化;根据计算出的所述基频序列片段的功率和斜率变化确定颤音概率;判断所述颤音概率是否超过预设数值;若所述颤音概率超过预设数值,确定所述基频序列片段为颤音片段;否则,确定所述基频序列片段为非颤音片段。
在一实施例中,所述处理器在执行所述提取所述乐谱的语言学特征和音乐特征的步骤时,具体实现如下步骤:
获取所述乐谱所对应的乐谱文件中的标签对;解析所述标签对,以提取所述标签对中所对应的音乐特征以及语言学特征的值。
在一实施例中,所述处理器在执行所述在所得到的声学特征中加入所得到的颤音特征的步骤时,具体实现如下步骤:
在所得到的声学特征中加入与所述颤音特征的振幅和频率对应的正弦波。
所述存储介质可以是u盘、移动硬盘、只读存储器(read-onlymemory,rom)、磁碟或者光盘等各种可以存储程序代码的计算机可读存储介质。
在本申请所提供的几个实施例中,应该理解到,所揭露的装置、设备和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式。所属领域的技术人员可以清楚地了解到,为了描述的方便和简洁,上述描述的装置、设备和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。以上所述,仅为本申请的具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!