语音翻译装置、语音翻译方法及记录介质与流程
本发明涉及语音翻译装置、语音翻译方法及记录介质。
背景技术:
作为说出不同语言的说话者用来实现意思的沟通的工具,有相互进行将一方的说话者的语音翻译为另一方的说话者的语言的处理的语音翻译装置。但是,在这样的语音翻译装置中,有时因噪音等的影响而不能正确地识别说话者的语音,不能正确地翻译。
例如在专利文献1中提出了能够将语音识别处理中误识别的内容通过简单的讲话来进行订正的技术。由此,不用将最初讲的内容全部重新讲就能够容易地订正误识别的内容。
专利文献1:日本特开2005-283797号公报
技术实现要素:
但是,在专利文献1所公开的技术中,在噪音环境没有变化的情况下,有再次进行的讲话也在语音识别处理中被误识别的情况。并且,在这样的情况下,用户不知道怎样做语音翻译装置才正确地进行语音识别。
本发明是鉴于上述的情况而做出的,目的是提供一种能够判定因噪音等而语音识别困难,并向用户通知用于消除该困难的行动的语音翻译装置、语音翻译方法及记录介质。
有关本发明的一技术方案的语音翻译装置具备:第1波束成形部,通过对由麦克风阵列部取得的语音信号进行信号处理,计算第1波束成形输出,该第1波束成形输出是将集音的指向性控制为第1方向后的语音信号;第2波束成形部,通过对由上述麦克风阵列部取得的语音信号进行信号处理,计算第2波束成形输出,该第2波束成形输出是将集音的指向性控制为与上述第1方向不同的第2方向后的语音信号;方向指定部,通过用户的操作,指定第1波束成形部的输出及第2波束成形部的输出中的一方的输出;第1识别部,在由上述方向指定部指定的上述一方的输出是由上述第1波束成形部形成的第1波束的情况下,通过对上述第1波束成形输出以第1语言进行识别处理,将上述第1波束成形输出的内容识别为第1语言的第1内容;第1翻译部,将上述第1识别部识别出的上述第1内容翻译为第2语言;第2识别部,在由上述方向指定部指定的上述一方的输出是由上述第2波束成形部形成的第2波束的情况下,通过对上述第2波束成形输出以第2语言进行识别处理,将上述第2波束成形输出的内容识别为上述第2语言的第2内容;第2翻译部,将上述第2识别部识别出的上述第2内容翻译为上述第1语言;sn比计算部,将由上述方向指定部指定的上述一方的输出作为sn比(signaltonoiseratio:信噪比)中的信号成分,将没有被上述方向指定部指定的另一方的输出作为噪声成分,计算sn比;显示决定部,使用由上述sn比计算部计算出的上述sn比,判定由上述方向指定部指定的上述一方的输出的识别是否困难,在判定为困难的情况下,决定用于向上述用户通知且消除上述困难的讲话方法;以及显示部,将上述第1翻译部的输出或上述第2翻译部的输出、或者由上述显示决定部决定的上述讲话方法显示在显示器上。
另外,它们中的一部分的具体的形态也可以由系统、方法、集成电路、计算机程序或计算机可读取的cd-rom等的记录介质实现,也可以由系统、方法、集成电路、计算机程序及记录介质的任意的组合来实现。
发明效果
根据本发明,能够实现判定因噪音等而语音识别困难,并向用户通知用于消除该困难的行动的语音翻译装置等。
附图说明
图1是表示实施方式1的语音翻译装置的外观的一例的图。
图2是表示实施方式1的语音翻译装置的使用场景的一例的图。
图3是表示实施方式1的语音翻译装置的集音方向的图。
图4a是表示使用实施方式1的语音翻译装置的用户的位置关系的图。
图4b是表示使用实施方式1的语音翻译装置的用户的位置关系的图。
图5是表示实施方式1的语音翻译装置的结构的一例的图。
图6a是表示实施方式1的由显示部显示的消除用户的误操作的讲话方法的一例的图。
图6b是表示实施方式1的由显示部显示的消除用户的误操作的讲话方法的一例的图。
图7是表示实施方式2的语音翻译装置的结构的一例的图。
图8a是表示实施方式2的由显示部显示的讲话方法的一例的图。
图8b是表示实施方式2的由显示部显示的讲话方法的一例的图。
图8c是表示实施方式2的由显示部显示的讲话方法的一例的图。
图8d是表示实施方式2的由显示部显示的讲话方法的一例的图。
图9a是表示实施方式2的由显示部显示的讲话方法的一另例的图。
图9b是表示实施方式2的由显示部显示的讲话方法的一另例的图。
图9c是表示实施方式2的由显示部显示的讲话方法的一另例的图。
图9d是表示实施方式2的由显示部显示的讲话方法的一另例的图。
图10是表示实施方式2的语音翻译装置进行的动作处理的流程图。
图11是表示实施方式2的变形例1的语音翻译装置的结构的一例的图。
图12a是表示实施方式2的变形例2的由显示部显示的电平表的一例的图。
图12b是表示实施方式2的变形例2的由显示部显示的电平表的一例的图。
图13a是表示实施方式2的变形例2的由显示部显示的电平表的另一例的图。
图13b是表示实施方式2的变形例2的由显示部显示的电平表的另一例的图。
图14a是表示实施方式2的变形例2的由显示部显示的电平表的再另一例的图。
图14b是表示实施方式2的变形例2的由显示部显示的电平表的再另一例的图。
图15a是表示实施方式2的变形例2的由显示部显示的设定了上下限范围的电平表的一例的图。
图15b是表示实施方式2的变形例2的由显示部显示的设定了上下限范围的电平表的一例的图。
图15c是表示实施方式2的变形例2的由显示部显示的设定了上下限范围的电平表的一例的图。
图16a是表示实施方式2的变形例2的由显示部显示的音量等的电平的颜色变化的、设定了上下限范围的电平表的一例的图。
图16b是表示实施方式2的变形例2的由显示部显示的音量等的电平的颜色变化的、设定了上下限范围的电平表的一例的图。
图16c是表示实施方式2的变形例2的由显示部显示的音量等的电平的颜色变化的、设定了上下限的范围的电平表的一例的图。
图17a是表示实施方式2的变形例2的由显示部显示的电平表和消息的一例的图。
图17b是表示实施方式2的变形例2的由显示部显示的电平表和消息的一例的图。
图17c是表示实施方式2的变形例2的由显示部显示的电平表和消息的一例的图。
图18是表示实施方式2的变形例3的语音翻译装置的结构的一例的图。
图19是表示实施方式2的变形例4的语音翻译装置的结构的一例的图。
具体实施方式
有关本发明的一技术方案的语音翻译装置具备:第1波束成形部,通过对由麦克风阵列部取得的语音信号进行信号处理,计算第1波束成形输出,该第1波束成形输出是将集音的指向性控制为第1方向后的语音信号;第2波束成形部,通过对由上述麦克风阵列部取得的语音信号进行信号处理,计算第2波束成形输出,该第2波束成形输出是将集音的指向性控制为与上述第1方向不同的第2方向后的语音信号;方向指定部,通过用户的操作,指定第1波束成形部的输出及第2波束成形部的输出中的一方的输出;第1识别部,在由上述方向指定部指定的上述一方的输出是由上述第1波束成形部形成的第1波束的情况下,通过对上述第1波束成形输出以第1语言进行识别处理,将上述第1波束成形输出的内容识别为第1语言的第1内容;第1翻译部,将上述第1识别部识别出的上述第1内容翻译为第2语言;第2识别部,在由上述方向指定部指定的上述一方的输出是由上述第2波束成形部形成的第2波束的情况下,通过对上述第2波束成形输出以第2语言进行识别处理,将上述第2波束成形输出的内容识别为上述第2语言的第2内容;第2翻译部,将上述第2识别部识别出的上述第2内容翻译为上述第1语言;sn比计算部,将由上述方向指定部指定的上述一方的输出作为sn比(signaltonoiseratio:信噪比)中的信号成分,将没有被上述方向指定部指定的另一方的输出作为噪声成分,计算sn比;显示决定部,使用由上述sn比计算部计算出的上述sn比,判定由上述方向指定部指定的上述一方的输出的识别是否困难,在判定为困难的情况下,决定用于向上述用户通知且消除上述困难的讲话方法;以及显示部,将上述第1翻译部的输出或上述第2翻译部的输出、或者由上述显示决定部决定的上述讲话方法显示在显示器上。
通过该结构,能够使用sn比判定语音识别困难,在判定为困难的情况下,能够向用户通知适当的讲话方法。即,能够判定因噪音等而语音识别困难,并向用户通知用于消除该困难的行动。由此,使得能够正确地进行语音识别,能够正确地翻译。
这里,例如也可以是,上述显示决定部在上述sn比小于阈值的情况下判定为上述识别困难,并且作为上述讲话方法而决定使上述sn比成为上述阈值以上的行动内容。
由此,能够向用户通知改善sn比的讲话方法。即,能够判定因噪音等而语音识别困难,并向用户通知改善sn比的行动作为消除该困难的行动。
此外,例如也可以是,上述显示决定部在上述sn比小于阈值的情况下,判定为上述识别困难,作为上述讲话方法而决定使上述sn比成为上述阈值以上的行动内容。
由此,向用户通知靠近麦克风阵列部来讲话作为消除该困难的行动,并且通过原样使用由麦克风阵列部取得的语音信号而进行识别处理及翻译处理,能够改善语音的识别性能。这里,这是因为,在以靠近麦克风阵列部的状态讲话的情况下,即使形成波束,也有语音的识别性能下降的时候。
此外,例如也可以是,上述显示决定部还计算由上述方向指定部指定的上述一方的输出的音量,并决定将计算出的上述音量显示在上述显示器上;上述显示部还将表示上述音量的电平的电平表显示在上述显示器上。
由此,用户能够一边确认是否以适当的音量的电平进行了讲话一边进行讲话。因此,能够促使用户进行适合于语音识别处理的语音的电平下的讲话,所以能够进一步改善语音的识别性能。
此外,例如也可以是,上述显示决定部还决定将由上述sn比计算部计算出的上述sn比显示在上述显示器上;上述显示部还将表示上述sn比的电平的电平表显示在上述显示器上。
由此,用户能够一边确认是否以适当的sn比的电平进行了讲话一边进行讲话。因此,能够促使用户进行适合于语音识别处理的sn比的电平下的讲话,所以能够进一步改善语音的识别性能。
此外,例如也可以是,上述显示决定部还计算上述第1波束成形部的输出及上述第2波束成形部的输出中的由上述方向指定部指定的上述一方的输出的音量作为信号音量,计算由上述麦克风阵列部取得的语音信号的音量作为噪语音量,决定将计算出的上述信号音量及上述噪语音量显示在上述显示器上;上述显示部还将表示上述信号音量及上述噪语音量的电平的电平表显示在上述显示器上。
由此,用户能够一边确认是否以适当的信号音量及噪语音量的电平进行了讲话一边进行讲话。因此,能够促使用户进行适合于语音识别处理的信号音量及噪语音量的电平下的讲话,所以能够进一步改善语音的识别性能。
此外,例如也可以是,上述显示部使上述电平表的电平在从下限阈值到上限阈值的范围中变化并显示在上述显示器上。
由此,能够促使用户进行适合于语音识别处理的电平表的电平下的讲话,所以能够进一步改善语音的识别性能。
此外,例如也可以是,上述显示部使上述电平表的颜色对应于上述电平的大小不同而显示。
由此,能够促使用户进行适合于语音识别处理的电平表的电平下的讲话,所以能够进一步改善语音的识别性能。
此外,例如也可以是,上述显示部还将与上述电平的大小相应的通知显示在上述显示器上。
由此,能够促使用户进行适合于语音识别处理的电平表的电平下的讲话,所以能够进一步改善语音的识别性能。
此外,例如也可以是,具备噪音特性计算部,该噪音特性计算部使用由上述麦克风阵列部取得的语音信号或由上述方向指定部指定的上述一方的输出,计算噪音特性;上述显示决定部还使用由上述噪音特性计算部计算出的上述噪音特性,判定上述一方的输出是否识别困难。
由此,能够促使用户进行适合于语音识别处理的电平表的电平下的讲话,所以能够进一步改善语音的识别性能。
此外,例如也可以是,还具备判定由上述方向指定部指定的上述一方的输出的语音区间的语音判定部;上述显示决定部还使用由上述语音判定部判定出的上述语音区间,判定上述一方的输出是否识别困难。
由此,能够提高语音的识别是否困难的判定精度。
此外,例如也可以是,上述显示决定部还使用由上述语音判定部判定的上述语音区间,判定上述用户的操作是否错误。
由此,能够提高语音的识别是否困难的判定精度。
此外,有关本发明的一技术方案的语音翻译装置具备:第1波束成形部,通过对由麦克风阵列部取得的语音信号进行信号处理,计算第1波束成形输出,该第1波束成形输出是将集音的指向性控制为第1方向后的语音信号;第2波束成形部,通过对由上述麦克风阵列部取得的语音信号进行信号处理,计算第2波束成形输出,该第2波束成形输出是将集音的指向性控制为与上述第1方向不同的第2方向后的语音信号;方向指定部,通过用户的操作,指定第1波束成形部的输出及第2波束成形部的输出中的一方的输出;第1识别部,在由上述方向指定部指定的上述一方的输出是由上述第1波束成形部形成的第1波束的情况下,通过对上述第1波束成形输出以第1语言进行识别处理,将上述第1波束成形输出的内容识别为第1语言的第1内容;第1翻译部,将上述第1识别部识别出的上述第1内容翻译为第2语言;第2识别部,在由上述方向指定部指定的上述一方的输出是由上述第2波束成形部形成的第2波束的情况下,通过对上述第2波束成形输出以第2语言进行识别处理,将上述第2波束成形输出的内容识别为上述第2语言的第2内容;第2翻译部,将上述第2识别部识别出的上述第2内容翻译为上述第1语言;显示决定部,根据向上述方向指定部的指定内容、第1波束成形部的输出的大小和第2波束成形部的输出的大小,判定是否有上述用户的误操作,在判定为有上述用户的误操作的情况下,决定用于向上述用户通知且消除上述误操作的讲话方法;以及显示部,根据上述显示决定部的判定结果,将上述第1翻译部的输出或上述第2翻译部的输出、或者由上述显示决定部决定的内容显示在显示器上。
通过该结构,能够判定用户是否进行了误操作,向用户通知适当的讲话方法。即,在判定为用户进行了误操作的情况下,能够向用户通知用于消除该误操作的行动。在用户进行了误操作的情况下,由于用户的误操作而正确的语音识别等变得困难的可能性高,所以通过消除误操作,使得能够正确地进行语音识别,能够正确地翻译。
此外,有关本发明的一技术方案的语音翻译方法包括:第1波束成形步骤,通过对由麦克风阵列部取得的语音信号进行信号处理,计算第1波束成形输出,该第1波束成形输出是将集音的指向性控制为第1方向后的语音信号;第2波束成形步骤,通过对由上述麦克风阵列部取得的语音信号进行信号处理,计算第2波束成形输出,该第2波束成形输出是将集音的指向性控制为与上述第1方向不同的第2方向后的语音信号;方向指定步骤,通过用户的操作,指定上述第1波束成形步骤中的输出及上述第2波束成形步骤中的输出的一方的输出;第1识别步骤,在上述方向指定步骤中被指定的上述一方的输出是在上述第1波束成形步骤中形成的第1波束的情况下,通过对上述第1波束成形输出以第1语言进行识别处理,将上述第1波束成形输出的内容识别为第1语言的第1内容;第1翻译步骤,将在上述第1识别步骤中识别出的上述第1内容翻译为第2语言;第2识别步骤,在上述方向指定步骤中被指定的上述一方的输出是在上述第2波束成形步骤中形成的第2波束的情况下,通过对上述第2波束成形输出以第2语言进行识别处理,将上述第2波束成形输出的内容识别为上述第2语言的第2内容;第2翻译步骤,将在上述第2识别步骤中识别出的上述第2内容翻译为上述第1语言;sn比计算步骤,将在上述方向指定步骤中被指定的上述一方的输出作为sn比(signaltonoiseratio:信噪比)中的信号成分,将在上述方向指定步骤中未被指定的另一方的输出作为噪声成分,计算sn比;显示决定步骤,使用在上述sn比计算步骤中计算出的上述sn比,判定在上述方向指定步骤中被指定的上述一方的输出的识别是否困难,在判定为困难的情况下,决定用于向上述用户通知且消除上述困难的讲话方法;以及显示步骤,将上述第1翻译步骤中的输出或上述第2翻译步骤中的输出、或者在上述显示决定步骤中决定的上述内容显示在显示器上。
由此,能够使用sn比判定是否有望能够正确地进行语音识别,在正确的语音识别等困难的情况下向用户通知适当的讲话方法。即,能够判定因噪音等而语音识别困难,并向用户通知用于消除该困难的行动。结果,使得能够正确地进行语音识别,能够正确地翻译。
此外,有关本发明的一技术方案的记录介质,是记录有程序的非暂时性的计算机可读取的记录介质,所述程序使计算机执行:第1波束成形步骤,通过对由麦克风阵列部取得的语音信号进行信号处理,计算第1波束成形输出,该第1波束成形输出是将集音的指向性控制为第1方向后的语音信号;第2波束成形步骤,通过对由上述麦克风阵列部取得的语音信号进行信号处理,计算第2波束成形输出,该第2波束成形输出是将集音的指向性控制为与上述第1方向不同的第2方向后的语音信号;方向指定步骤,通过用户的操作,指定上述第1波束成形步骤中的输出及上述第2波束成形步骤中的输出的一方的输出;第1识别步骤,在上述方向指定步骤中被指定的上述一方的输出是在上述第1波束成形步骤中形成的第1波束的情况下,通过对上述第1波束成形输出以第1语言进行识别处理,将上述第1波束成形输出的内容识别为第1语言的第1内容;第1翻译步骤,将在上述第1识别步骤中识别出的上述第1内容翻译为第2语言;第2识别步骤,在上述方向指定步骤中被指定的上述一方的输出是在上述第2波束成形步骤中形成的第2波束的情况下,通过对上述第2波束成形输出以第2语言进行识别处理,将上述第2波束成形输出的内容识别为上述第2语言的第2内容;第2翻译步骤,将在上述第2识别步骤中识别出的上述第2内容翻译为上述第1语言;sn比计算步骤,将在上述方向指定步骤中被指定的上述一方的输出作为sn比(signaltonoiseratio:信噪比)中的信号成分,将在上述方向指定步骤中未被指定的另一方的输出作为噪声成分,计算sn比;显示决定步骤,使用在上述sn比计算步骤中计算出的上述sn比,判定在上述方向指定步骤中被指定的上述一方的输出的识别是否困难,在判定为困难的情况下,决定用于向上述用户通知且消除上述困难的讲话方法;以及显示步骤,将上述第1翻译步骤中的输出或上述第2翻译步骤中的输出、或者在上述显示决定步骤中决定的上述讲话方法显示在显示器上。
由此,能够使用sn比判定是否有望能够正确地进行语音识别,在正确的语音识别等困难的情况下向用户通知适当的讲话方法。即,能够判定因噪音等而语音识别困难,并向用户通知用于消除该困难的行动。结果,使得能够正确地进行语音识别,能够正确地翻译。
另外,这些中的一部分的具体的技术方案也可以由系统、方法、集成电路、计算机程序或计算机可读取的cd-rom等的记录介质实现,也可以由系统、方法、集成电路、计算机程序及记录介质的任意的组合来实现。
以下,参照附图对有关本发明的一技术方案的语音翻译装置具体地进行说明。另外,以下说明的实施方式都表示本发明的一具体例。在以下的实施方式中表示的数值、形状、材料、构成要素、构成要素的配置位置等是一例,不是限定本发明的意思。此外,关于以下的实施方式的构成要素中的、在表示最上位概念的独立权利要求中没有记载的构成要素设为任意的构成要素进行说明。此外,也可以在全部的实施方式中将各自的内容组合。
(实施方式1)
<<概要>>
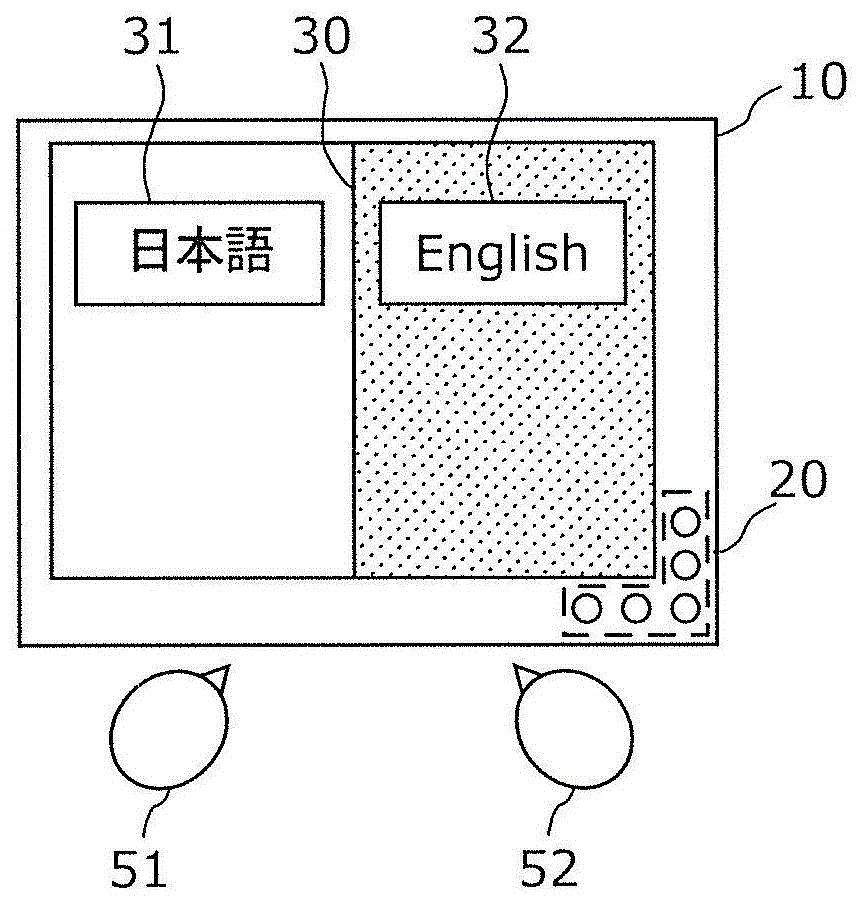
图1是表示实施方式1的语音翻译装置10的外观的一例的图。图2是表示实施方式1的语音翻译装置10的使用场景的一例的图。
语音翻译装置10是对以第1语言讲话的第1说话者51与以第2语言讲话的第2说话者52之间的会话进行翻译的装置。即,语音翻译装置10由不同语言的2个说话者使用,是双向进行翻译的装置。这样的语音翻译装置10例如以如卡那样的长条状的形状构成,通过平板等1个便携终端实现。语音翻译装置10如图1所示,具备由取得讲话的多个麦克风构成的麦克风阵列部20和将翻译结果显示为文本的显示器30。
在图1中,表示了作为第1语言而讲日语的第1说话者51位于左侧、作为第2语言而讲英语的第2说话者52位于右侧,横向并排来使用语音翻译装置10的同时进行会话的例子。
在讲日语的第1说话者51讲话的情况下,第1说话者51按下显示有“日本語(日语)”的按钮31并讲话。这里,例如假设第1说话者51在按下显示有“日本語”的按钮31后,例如讲了“東京駅は何処ですか?(东京站是哪里?)”。在此情况下,如图2所示,在显示器30的左侧区域中显示日语的识别结果“東京駅は何処ですか?(东京站是哪里?)”,在显示器30的右侧区域中显示由语音翻译装置10得到的英语的翻译结果“whereistokyostation?”。
同样,在讲英语的第2说话者52讲话的情况下,第2说话者52按下显示有“english(英语)”的按钮32并讲话。这里,例如假设第2说话者52在按下显示有“english”的按钮32后,例如讲了“whereistokyostation?(东京站是哪里?)”。在此情况下,与上述同样,在显示器30的右侧区域显示英语的识别结果“whereistokyostation?”,在显示器30的左侧区域显示由语音翻译装置10得到的日语的翻译结果“東京駅は何処ですか?”。
这样,语音翻译装置10通过用户的按钮操作等切换在第1语言和第2语言中从哪个语言翻译为哪个语言。
图3是表示实施方式1的语音翻译装置10的集音方向的图。对与图1及图2同样的要素赋予相同的标号。
在第1说话者51按下显示有“日本語”的按钮31并讲话的情况下,集音的指向性被控制为作为从语音翻译装置10看时第1说话者51所处的方向的集音方向61。另一方面,在第2说话者52按下显示有“english”的按钮32并讲话的情况下,集音的指向性被控制为作为从语音翻译装置10看时第2说话者52所处的方向的集音方向62。
这样,语音翻译装置10接受用户的按钮操作等而切换作为不同方向的集音方向61及集音方向62。这里,集音方向61及集音方向62是预先决定的方向,通过控制麦克风阵列部20的指向性来实现。
如以上这样,实施方式1的语音翻译装置10接受用户的按钮操作等而切换集音方向和语言。
另外,实施方式1的语音翻译装置10具有的显示器30是长条状的形状。该显示器30在设为纵向或横向的状态下被使用。
图4a及图4b是表示使用实施方式1的语音翻译装置10的用户的位置关系的图。对与图1~图3同样的要素赋予相同的标号,省略详细的说明。
如图4a所示,在用户即第1说话者51及第2说话者52以横向并排的状态使用语音翻译装置10的情况下,将显示器30设为横向的状态下使用。另一方面,如图4b所示,在用户即第1说话者51及第2说话者52以面对的状态使用语音翻译装置10的情况下,将显示器30设为纵向的状态下使用。在此情况下,显示有“日本語”的按钮31a被朝向第1说话者51显示,显示有“english”的按钮32a被朝向第2说话者52显示。此外,语音翻译装置10通过控制麦克风阵列部20的指向性,使集音方向61a朝向第1说话者51,使集音方向62a朝向第2说话者52。
<<装置结构>>
图5是表示实施方式1的语音翻译装置10的结构的一例的图。
语音翻译装置10如图5所示,具备波束成形部11、方向指定部12、显示决定部13、识别部14、翻译部15和显示部16。语音翻译装置10也可以还具备麦克风阵列部20。即,语音翻译装置10具备麦克风阵列部20不是必须的。
[麦克风阵列部20]
麦克风阵列部20取得语音信号。更具体地讲,麦克风阵列部20由相互分离而配置的2个以上的麦克风单元构成,将语音进行集音,取得从集音的语音变换为电信号的语音信号。麦克风阵列部20将所取得的语音信号向波束成形部11输出。另外,麦克风阵列部20也可以构成为适配器。在此情况下,麦克风阵列部20通过安装到语音翻译装置10上而发挥功能。
[波束成形部11]
波束成形部11通过对由麦克风阵列部20取得的语音信号进行信号处理,将集音的指向性控制为预先决定的方向,即在预先决定的方向上形成波束。这里,例如如图3所示,波束成形部11通过对由麦克风阵列部20取得的语音信号进行信号处理,使集音方向61朝向第1说话者51,或使集音方向62朝向第2说话者52。集音方向61及集音方向62是所形成的波束的方向,是相互不同的方向。
在本实施方式中,波束成形部11如图5所示,具备第1波束成形部111和第2波束成形部112。
第1波束成形部111通过对由麦克风阵列部20取得的语音信号进行信号处理,计算将集音的指向性控制为第1方向后的语音信号即第1波束成形输出,形成第1波束。这里,第1方向是从语音翻译装置10看的预定的第1说话者51的位置的方向。例如,在图4a所示的例子中,即在第1说话者51及第2说话者52以横向并排的状态使用语音翻译装置10的情况下,第1方向是集音方向61。在图4b所示的例子中,即在第1说话者51及第2说话者52以面对的状态使用语音翻译装置10的情况下,第1方向是集音方向61a。
第2波束成形部112通过对由麦克风阵列部20取得的语音信号进行信号处理,计算将集音的指向性控制为与第1方向不同的第2方向后的语音信号即第2波束成形输出,形成第2波束。这里,第2方向是从语音翻译装置10看的预定的第2说话者52的位置的方向。例如,在图4a所示的例子中,即,在第1说话者51及第2说话者52以横向并排的状态使用语音翻译装置10的情况下,第2方向是集音方向62。在图4b所示的例子中,即在第1说话者51及第2说话者52以面对的状态使用语音翻译装置10的情况下,第2方向是集音方向62a。
[方向指定部12]
方向指定部12通过被用户操作,指定波束成形部11的集音的指向性的控制方法和被识别部14识别的语言。方向指定部12将所指定的控制方法即指定内容向显示决定部13通知。
例如,在图3所示的例子中,如果用户即第1说话者51按下显示有“日本語”的按钮31,则波束成形部11的集音的指向性被指定为集音方向61。与此同时,向显示决定部13通知使识别部14识别的语言被指定为日语、被指定为集音方向61。另一方面,如果用户即第2说话者52按下显示有“english”的按钮32,则波束成形部11的集音的指向性被指定为集音方向62。与此同时,向显示决定部13通知使识别部14识别的语言被指定为英语、被指定为集音方向62。
在本实施方式中,方向指定部12通过用户的操作指定第1波束成形部111的输出及第2波束成形部112的输出中的一方的输出。更具体地讲,方向指定部12通过用户的操作,切换第1波束成形部111的输出及第2波束成形部112的输出。这是因为,第1波束成形部111及第2波束成形部112通过分别对由麦克风阵列部20取得的语音信号进行信号处理,总是形成第1波束及第2波束。
这样,方向指定部12能够使第1波束成形部111形成的第1波束及第2波束成形部112形成的第2波束中的某一个向显示决定部13及识别部14输出。
[显示决定部13]
显示决定部13基于通过用户的操作进行的向方向指定部12的指定、和通过由波束成形部11形成的波束而集音到的语音信号(表示讲话的语音信号)的大小,判定用户的误操作的有无。显示决定部13在判定为有用户的误操作的情况下,决定正确的操作方法等消除误操作的讲话方法,向显示部16输出。
在本实施方式中,显示决定部13根据向方向指定部12的指定内容、第1波束成形部111的输出的大小和第2波束成形部112的输出的大小,判定用户的误操作的有无。
例如,假设在方向指定部12中被指定了第2波束成形部112的输出,如果是(第1波束成形部111的输出>第2波束成形部112的输出),则显示决定部13判定为有用户的误操作。此外,假设在方向指定部12中被指定了第1波束成形部111的输出,如果是(第1波束成形部111的输出<第2波束成形部112的输出),则显示决定部13判定为有用户的误操作。
这里,使用图3对能够判定为是用户的误操作的理由进行说明。通过用户的操作指定第2波束成形部112的输出,意味着该用户是位于集音方向62的第2说话者52,预计讲第2语言。但是,在第1波束成形部111的输出>第2波束成形部112的输出的情况下,意味着该用户实际上位于与预计的集音方向62不同的集音方向61。由此,可知发生了以下这样的误操作。即,用户虽然是想要将日语翻译为英语的讲日语的第1说话者51,但误按下显示有“english”的按钮32并进行了讲话。或者,用户虽然是想要将英语翻译为日语的讲英语的第2说话者52,应位于集音方向62,但位于集音方向61并按下显示有“english”的按钮32进行了讲话。
同样,通过用户的操作指定第1波束成形部111的输出,意味着该用户是位于集音方向61的第1说话者51,预计讲第1语言。但是,在第1波束成形部111的输出<第2波束成形部112的输出的情况下,意味着该用户实际上位于与预计的集音方向61不同的集音方向62。由此,可知发生了以下这样的误操作。即,用户虽然是想要将英语翻译为日语的讲英语的第2说话者52,但误按下显示有“日本語”的按钮31并进行了讲话。或者,用户虽然是想要将日语翻译为英语的讲日语的第1说话者51,应位于集音方向61,但位于集音方向62并按下显示有“日本語”的按钮31进行了讲话。
这样,能够判定用户的误操作。
此外,显示决定部13例如在判定为有用户的误操作的情况下,决定消除误操作且用于向用户通知的讲话方法。
这里的讲话方法,例如是正确的操作方法,或促使在正确的位置再次进行讲话。例如,在方向指定部12中被指定第2波束成形部112的输出、并且(第1波束成形部111的输出>第2波束成形部112的输出)的情况下,也可以决定促使将显示有“日本語”的按钮31按下的讲话方法。此外,例如在方向指定部12中被指定第1波束成形部111的输出、并且(第1波束成形部111的输出<第2波束成形部112的输出)的情况下,也可以决定促使将显示有“english”的按钮32按下的讲话方法。
[识别部14]
对识别部14而言,由方向指定部12指定识别波束成形部11的输出的语言。并且,识别部14用被指定的语言对波束成形部11的输出进行识别。
在本实施方式中,识别部14如图5所示,具备第1识别部141和第2识别部142。
第1识别部141在由方向指定部12指定的一方的输出是由第1波束成形部111形成的第1波束的情况下,通过对第1波束以第1语言进行识别处理,将第1波束的内容识别为第1语言的第1内容。这里,第1语言是第1说话者51预计要讲的语言,例如是日语。在图4a所示的例子中,第1语言是位于集音方向61的第1说话者51预计要讲的日语。在图4b所示的例子中,第1语言是位于集音方向61a的第1说话者51预计要讲的日语。
第2识别部142在由方向指定部12指定的一方的输出是由第2波束成形部112形成的第2波束的情况下,通过对第2波束以第2语言进行识别处理,将第2波束的内容识别为第2语言的第2内容。这里,第2语言是第2说话者52预计要讲的语言,例如是英语。在图4a所示的例子中,第2语言是位于集音方向62的第2说话者52预计要讲的英语。在图4b所示的例子中,第2语言是位于集音方向62a的第2说话者52预计要讲的英语。
[翻译部15]
翻译部15根据识别部14识别出的语言,对识别部14识别出的内容进行翻译。并且,翻译部15将翻译出的内容向显示部16输出。例如,如果识别部14识别出的语言是日语,则翻译部15将识别部14识别出的内容翻译为英语。另一方面,如果识别部14识别出的语言是英语,则翻译部15将识别部14识别出的内容翻译为日语。
在本实施方式中,翻译部15如图5所示,具备第1翻译部151和第2翻译部152。
第1翻译部151将第1识别部141识别出的第1内容翻译为第2语言。更具体地讲,第1翻译部151将第1识别部141识别出的日语的内容翻译为英语。第1翻译部151将翻译出的英语的内容向显示部16输出。
第2翻译部152将第2识别部142识别出的第2内容翻译为第1语言。更具体地讲,第2翻译部152将第2识别部142识别出的英语的内容翻译为日语。第2翻译部152将翻译出的日语的内容向显示部16输出。
[显示部16]
显示部16根据显示决定部13的判定结果,将第1翻译部151的输出或第2翻译部152的输出、或者由显示决定部13决定的内容显示在显示器30上。
更具体地讲,显示部16在由显示决定部13判定为没有用户的误操作的情况下,显示第1翻译部151翻译出的第1内容或第2翻译部152翻译出的第2内容。另一方面,显示部16在由显示决定部13判定为用户误操作的情况下,显示由显示决定部13决定的消除误操作的讲话方法。
图6a及图6b是表示实施方式1的由显示部16显示的消除用户的误操作的讲话方法的一例的图。对于与图1~图4b同样的要素赋予相同的标号。
在图6a中,表示了在将显示器30以横向状态使用的情况下,说话者53按下显示有“english”的按钮32而讲话但判定为误操作时的讲话方法的一例。在此情况下,显示部16显示由显示决定部13决定的表示消除误操作的讲话方法的消息或通知内容。在图6a中,在显示器30的左侧区域中显示有“日本語ボタンを押して下さい(请按下日语按钮)”,在显示器30的右侧区域中显示有“ifyouwanttotranslateenglish,talkthisdirection(如果您想翻译英语,请这个方向讲话).”和促使向箭头33的方向移动的消息。
在图6b中,表示了在将显示器30以纵向状态使用的情况下,说话者53按下显示有“english”的按钮32而讲话但判定为误操作时的讲话方法的一例。在此情况下,显示部16也显示由显示决定部13决定的消除误操作的讲话方法。在图6b中,在显示器30的下侧区域中显示有“日本語ボタンを押して下さい(请按下日语按钮)”、“ifyouwanttotranslateenglishtalkoppositeside(如果您想翻译英语,请到对边讲话).”和促使向显示器30的相反侧移动的消息。
这样,显示部16,作为由显示决定部13决定的消除误操作的讲话方法而将第1语言及第2语言的通知(消息)同时显示在显示器30上。由此,说话者53通过阅读自己语言的通知,知道正确的操作方法。
[效果]
如以上这样,根据本实施方式的语音翻译装置10,能够判定用户是否进行了误操作并向用户通知适当的讲话方法。即,在判定为用户的误操作的情况下,能够向用户通知用于消除该误操作的行动。在用户进行了误操作的情况下,因为用户的误操作而正确的语音识别等变得困难的可能性高,所以通过消除误操作,使得语音翻译装置10能够正确地进行语音识别,能够正确地翻译。
(实施方式2)
在实施方式1中,由于因用户的误操作而正确的语音识别等变得困难的可能性高,所以在发生了用户的误操作的情况下,通知促使用户进行用于消除误操作的行动的讲话方法。在实施方式2中,说明在因噪音等而语音识别困难的情况下,通知促使用户进行用于消除该困难的行动的讲话方法。以下,以与实施方式1不同之处为中心进行说明。
图7是表示实施方式2的语音翻译装置10a的结构的一例的图。对于与图5同样的要素赋予相同的标号,省略详细的说明。
语音翻译装置10a相对于有关实施方式1的语音翻译装置10,显示决定部13a和显示部16a的结构不同,并追加了s/n比计算部17。
[s/n比计算部17]
s/n比计算部17使用由波束成形部11形成的波束集音到的语音信号,计算sn比(signaltonoiseratio:信噪比)。在本实施方式中,s/n比计算部17将由方向指定部12指定的一方的输出作为sn比中的信号成分,将没有被方向指定部12指定的另一方的输出作为噪声成分,计算sn比。
[显示决定部13a]
显示决定部13a基于由s/n比计算部17计算出的sn比,判定用户进行的讲话的语音识别是否困难。并且,显示决定部13a在判定为语音识别困难的情况下,决定促使用户进行用于消除该困难的行动的讲话方法,向显示部16a输出。
在本实施方式中,显示决定部13a使用由s/n比计算部17计算出的sn比,判定由方向指定部12指定的一方的输出的识别是否困难。显示决定部13在判定为所指定的一方的输出的识别困难的情况下,决定消除该困难且用于向用户通知的讲话方法。
例如,显示决定部13a在由s/n比计算部17计算出的sn比小于阈值的情况下,判定为语音识别困难,作为讲话方法而决定使sn比成为阈值以上的行动内容。即,作为讲话方法,决定为了抑制语音识别中的噪音的影响而促使用户进行且使sn比成为阈值以上的行动(行动内容)。例如,决定促使在麦克风阵列部20的近处再次讲话、或促使以较大的语音再次讲话、或促使在安静的场所讲话、或促使在远离噪音源的位置讲话等的行动内容。
另外,显示决定部13a也可以还判定用户的误操作的有无。由于用户的误操作的有无的判定方法的详细情况如在实施方式1中说明的一样,所以省略说明。
[显示部16a]
显示部16a根据显示决定部13a的判定结果,将第1翻译部151的输出或第2翻译部152的输出、或者由显示决定部13a决定的讲话方法显示在显示器30上。
更具体地讲,显示部16a在由显示决定部13a判定为语音识别不困难的情况下,显示第1翻译部151翻译出的第1内容或第2翻译部152翻译出的第2内容。另一方面,显示部16a在由显示决定部13判定为语音识别困难的情况下,显示由显示决定部13a决定的消除该困难的讲话方法。
图8a~图8d是表示实施方式2的由显示部16a显示的讲话方法的一例的图。对于与图1~图4b同样的要素赋予相同的标号。在图8a~图8d中,表示了将显示器30以横向状态使用,在判定为第1说话者51的讲话的语音识别较困难的情况下作为讲话方法而表示的消息34的例子。
更具体地讲,也可以如图8a所示,在显示器30的左侧区域中,作为讲话方法而显示促使进行使sn比成为阈值以上的行动的“マイクの近くでお話ください(请在麦克风的近处说话)”的消息34。此外,也可以如图8b所示,在显示器30的左侧区域中,作为讲话方法而显示促使进行使sn比成为阈值以上的行动的“大きな声でお話ください(请大声说话)”的消息34。此外,也可以如图8c所示,在显示器30的左侧区域中,作为讲话方法而显示促使进行使sn比成为阈值以上的行动的“静かな場所でお使いください(请在安静的地方使用)”的消息34。此外,也可以如图8d所示,在显示器30的左侧区域中,作为讲话方法而显示促使进行使sn比成为阈值以上的行动的“騒音源から離れてください(请远离噪音源)”的消息34。不论怎样,只要在显示器30的左侧区域中作为讲话方法而显示促使进行使sn比成为阈值以上的行动的消息34就可以。由此,能够使作为用户的第1说话者51进行用于抑制语音识别中的噪音的影响且使sn比成为阈值以上的行动。
图9a~图9d是表示实施方式2的由显示部16a显示的讲话方法的另一例的图。对与图1~图4b同样的要素赋予相同的标号。在图9a~图9d中,表示了将显示器30以横向状态使用,在判定为第2说话者52的讲话的语音识别困难的情况下作为讲话方法而表示的消息35的例子。
更具体地讲,也可以如图9a所示,在显示器30的右侧区域中,作为讲话方法而显示促使进行使sn比成为阈值以上的行动的“moveclosertomicrophone(请靠近麦克风).”的消息35。此外,也可以如图9b所示,在显示器30的右侧区域中,作为讲话方法而显示促使进行使sn比成为阈值以上的行动的“pleasespeaklouder(请大声说话).”的消息35。此外,也可以如图9c所示,在显示器30的右侧区域中,作为讲话方法而显示促使进行使sn比成为阈值以上的行动的“pleaseuseinaquietplace(请在安静的地方使用).”的消息35。此外,也可以如图9d所示,在显示器30的右侧区域中,作为讲话方法而显示促使进行使sn比成为阈值以上的行动的“pleasekeepawayfromnoisesource(请远离噪音源).”的消息35。不论怎样,只要显示器30的右侧区域中作为讲话方法而显示促使进行使sn比成为阈值以上的行动的消息35就可以。由此,能够使作为用户的第2说话者52进行用于抑制语音识别中的噪音的影响且使sn比成为阈值以上的行动。
这样,显示部16能够将语音识别困难的状况下的讲话方法向用户通知,所以能够使用户进行用于消除语音识别困难的状况的行动。
另外也可以是,在显示决定部13a还判定用户的误操作的有无的情况下,显示部16a在显示器30上显示由显示决定部13a决定的消除误操作的讲话方法。讲话方法的显示的详细情况如在实施方式1中说明的一样,所以省略说明。
[语音翻译装置10a的动作]
对如以上那样构成的语音翻译装置10a进行的动作处理进行说明。
图10是表示实施方式2的语音翻译装置10a进行的动作处理的流程图。
首先,语音翻译装置10a对由麦克风阵列部20取得的语音信号进行信号处理,形成第1波束(s11)。更具体地讲,语音翻译装置10a通过对由麦克风阵列部20取得的语音信号进行信号处理,计算将集音的指向性控制为第1方向后的语音信号即第1波束成形输出,形成第1波束。
接着,语音翻译装置10a对由麦克风阵列部20取得的语音信号进行信号处理,形成第2波束(s12)。更具体地讲,语音翻译装置10a通过对由麦克风阵列部20取得的语音信号进行信号处理,计算将集音的指向性控制为与第1方向不同的第2方向后的语音信号即第2波束成形输出,形成第2波束。
接着,在语音翻译装置10a中,通过用户的操作,指定第1波束成形部111或第2波束成形部112的输出(s13)。更具体地讲,在语音翻译装置10a中,通过用户的操作,指定第1波束成形部111的输出及第2波束成形部112的输出中的一方的输出。
接着,语音翻译装置10a将被指定的输出作为信号成分,将没有被指定的输出作为噪声成分,计算sn比(s14)。更具体地讲,语音翻译装置10a将在步骤s13中指定的一方的输出作为sn比中的信号成分,将在步骤s13中没有被指定的另一方的输出作为噪声成分,计算sn比。
接着,语音翻译装置10a判定被指定的输出的识别是否困难(s15)。更具体地讲,语音翻译装置10a使用在步骤s14中计算出的sn比,判定在步骤s13中被指定的一方的输出的识别是否困难。
在步骤s15中语音翻译装置10a判定为被指定的输出的识别困难的情况下(s15中是),决定消除该困难且用于向用户通知的讲话方法(s16)。并且,语音翻译装置10a将所决定的讲话方法向显示器30显示(s17)。
另一方面,在步骤s15中语音翻译装置10a判定为被指定的输出的识别不困难的情况下(s15中否),判定在步骤s13中被指定的一方的输出(s18)。如果在步骤s13中被指定的一方的输出是第1波束成形输出(在s18中是第1波束成形输出),则向步骤s19前进。另外,如果在步骤s13中被指定的一方的输出是第2波束成形输出(在s18中是第2波束成形输出),则向步骤s22前进。
在步骤s19中,语音翻译装置10a将第1波束成形输出的内容识别为第1语言的第1内容。更具体地讲,语音翻译装置10a通过对第1波束成形输出以第1语言进行识别处理,将第1波束成形输出的内容识别为第1语言的第1内容。接着,在步骤s20中,语音翻译装置10a将在步骤s19中识别出的第1内容翻译为第2语言。接着,在步骤s21中,语音翻译装置10a将翻译出的第2语言的第1内容显示在显示器30上。
另一方面,在步骤s22中,语音翻译装置10a将第2波束成形输出的内容识别为第2语言的第2内容。更具体地讲,语音翻译装置10a通过对第2波束成形输出以第2语言进行识别处理,将第2波束成形输出的内容识别为第2语言的第2内容。接着,在步骤s23中,语音翻译装置10a将在步骤s22中识别出的第2内容翻译为第1语言。接着,在步骤s24中,语音翻译装置10a将翻译出的第1语言的第2内容显示在显示器30上。
[效果]
如以上这样,根据本实施方式的语音翻译装置10a,使用sn比判定是否有望能够正确地进行语音识别,在正确的语音识别困难的情况下,能够向用户通知适当的讲话方法。即,语音翻译装置10a能够判定因噪音等而语音识别困难,并向用户通知用于消除该困难的行动。由此,使得语音翻译装置10a能够正确地进行语音识别,能够正确地翻译。
这里,例如语音翻译装置10a也可以在sn比小于阈值的情况下判定为语音识别困难,作为讲话方法而决定表示使sn比成为阈值以上的讲话方法的内容。由此,能够向用户通知改善sn比那样的讲话方法。即,语音翻译装置10a能够判定因噪音等而语音识别困难,作为消除该困难的行动向用户通知改善sn比的行动。结果,语音翻译装置10a能够使用户进行消除该困难的行动,所以使得能够正确地进行语音识别,能够正确地翻译。
(变形例1)
接着,对变形例1进行说明。以下,以与实施方式2不同之处为中心进行说明。
图11是表示实施方式2的变形例1的语音翻译装置10b的结构的一例的图。对于与图7同样的要素赋予相同的标号,省略详细的说明。
语音翻译装置10b相对于图7所示的语音翻译装置10a,显示决定部13b的结构不同。
[显示决定部13b]
显示决定部13b基于由s/n比计算部17计算出的sn比,判定用户进行的讲话的语音识别是否困难。显示决定部13b在判定为语音识别困难的情况下,决定促使用户进行用于消除该困难的行动的讲话方法,向显示部16a输出。
在本变形例中,显示决定部13b在由s/n比计算部17计算出的sn比小于阈值的情况下,作为讲话方法而决定表示靠近麦克风阵列部而讲话之意的内容。更具体地讲,显示决定部13b根据由s/n比计算部17计算出的sn比是否小于阈值,判定由方向指定部12指定的一方的输出的识别是否困难。显示决定部13在判定为被指定的一方的输出的识别困难的情况下,作为消除该困难的讲话方法而决定促使靠近麦克风阵列部20而讲话的行动的内容。
在此情况下,显示决定部13b将与由方向指定部12指定的一方的输出对应的第1识别部141或第2识别部142的输入从一方的输出切换为麦克风阵列部20的输出。并且,显示决定部13b使麦克风阵列部20取得的语音信号向与一方的输出对应的第1识别部141或第2识别部142输入。
另外,显示决定部13b也可以还判定用户的误操作的有无。用户的误操作的有无的判定方法的详细情况如在实施方式1中说明的一样,所以省略说明。
[效果]
如以上这样,根据本变形例的语音翻译装置10b,使用sn比,判定是否有望能够正确地进行语音识别,在正确的语音识别困难的情况下,作为消除该困难的行动,向用户通知靠近麦克风阵列部20而讲话。与此同时,本实施方式的语音翻译装置10b通过原样使用由麦克风阵列部20取得的语音信号进行识别处理及翻译处理,改善讲话者的讲话的语音识别性能。这是因为,在讲话者在靠近麦克风阵列部20的状态下讲话的情况下,当从比适合形成波束的距离短的位置讲话时,有时不能正确地得到希望的语音而变形、语音识别性能比不进行任何处理的情况更下降。
(变形例2)
在实施方式2及其变形例1中,说明了在因噪音等而语音识别困难的情况下促使用户进行用于消除该困难的行动的讲话方法,但并不限于此。也可以在用户的讲话时进行促使用户进行即使在噪音等环境下也不使语音识别变困难那样的行动的显示。以下,关于在用户的讲话时促使进行不使语音识别变困难那样的行动的显示的例子,作为变形例2进行说明。
首先,作为在用户的讲话时促使用户进行不使语音识别变困难那样的行动的显示的例子,说明显示部16a显示由波束成形部11形成的波束的音量的电平的电平表的情况。即,也可以是,显示决定部13a及13b还计算由方向指定部12指定的一方的输出的音量,决定将计算出的音量显示在显示器30上。并且,显示部16a只要还将表示该音量的电平的电平表显示在显示器30上就可以。
图12a及图12b是表示实施方式2的变形例2的由显示部16a显示的电平表的一例的图。对于与图3等同样的要素赋予相同的标号,省略详细的说明。如图12a及图12b所示,在显示器30上,显示有表示由波束成形部11形成的波束的音量的电平的电平表36。电平表36根据来自集音方向的讲话的音量而音量的电平增减。
更具体地讲,在图12a中,表示了当第1说话者51位于集音方向61并且按下显示有“日本語”的按钮31而讲话时,电平表36的音量的电平增减的样子。并且,第1说话者51通过观察电平表36的音量的电平的增减,知道正处于作为正确的位置的集音方向61而讲话。此外,第1说话者51通过观察电平表36的音量的电平的增减,能够确认是否以适当的音量进行了讲话。由此,能够促使第1说话者51进行适合于识别部14的识别处理的音量下的讲话,所以能够改善识别部14的识别性能。
另一方面,在图12b中表示了第1说话者51不位于集音方向61而按下显示有“日本語”的按钮31并讲话时,电平表36的音量的电平无反应(零)的样子。并且,第1说话者51通过观察电平表36的音量的电平无反应,知道没有在正确的位置讲话。由此,促使第1说话者51移动到作为正确的位置的集音方向61而讲话,所以能够促使第1说话者51进行不使语音识别变困难的行动。
另外,在图12a及图12b中,说明了第1说话者51使用语音翻译装置10a及10b的情况,但并不限于此。也可以由第2说话者52使用语音翻译装置10a及10b,可以说是同样的。
接着,作为在用户的讲话时促使用户进行不使语音识别变困难那样的行动的显示的例子,说明显示部16a显示表示由s/n比计算部17计算的s/n比的电平的电平表的情况。即,也可以是,显示决定部13a及13b还决定将由s/n比计算部17计算出的sn比显示在显示器30上。并且,显示部16a只要将表示该sn比的电平的电平表显示在显示器30上就可以。
图13a及图13b是表示实施方式2的变形例2的由显示部16a显示的电平表的另一例的图。如图13a及图13b所示,在显示器30上,显示有表示由s/n比计算部17计算的sn比的电平的电平表36a。电平表36a根据计算出的sn比的值而音量的电平增减。
更具体地讲,如图13a所示,在计算出的sn比的值高的情况下,电平表36a表示的sn比的电平高。另一方面,如图13b所示,在计算出的sn比的值低的情况下,电平表36a表示的sn比的电平低。因此,例如第1说话者51等用户通过观察电平表36a的sn比的电平的增减,能够确认是否以适当的音量进行了讲话。由此,能够促使用户进行适合于识别部14的识别处理的音量下的讲话,所以能够改善识别部14的识别性能。
另外,在图13a及图13b中,表示了计算第1波束成形部111的输出作为sn比中的信号成分的情况下的例子,但并不限于此。也可以计算第2波束成形部112的输出作为sn比中的信号成分,可以说是同样的。
接着,作为在用户的讲话时促使用户进行不使语音识别变困难那样的行动的显示的例子,说明显示部16a显示表示能够根据由波束成形部11形成的波束来计算的信号电平和噪声电平的电平表的情况。即,也可以是,显示决定部13a及13b还计算第1波束成形部111的输出及第2波束成形部112的输出中的由方向指定部12指定的一方的输出的音量作为信号音量,计算由麦克风阵列部20取得的语音信号的音量作为噪语音量。在此情况下,显示决定部13a及13b也可以决定在显示器30上显示计算出的信号音量及噪语音量。并且,显示部16a只要还将表示该信号音量及该噪语音量的电平的电平表显示在显示器30上就可以。
图14a及图14b是表示实施方式2的变形例2的由显示部16a显示的电平表的再另一例的图。如图14a及图14b所示,在显示器30上,显示有将由波束成形部11形成的波束的音量的电平表示为信号音量的电平的电平表36b。此外,在显示器30上,显示有将由麦克风阵列部20取得的语音信号的音量的电平表示为噪语音量的电平的电平表36c。
更具体地讲,在第1说话者51在正确的集音方向61上以适当的音量讲话的情况下,如图14a所示,电平表36b表示的信号音量的电平比电平表36c表示的噪语音量的电平高。另一方面,在第1说话者51在正确的集音方向61上以较小的语音等不适当的音量讲话的情况下,如图14b所示,电平表36b表示的信号音量的电平比电平表36c表示的噪语音量的电平低。因此,第1说话者51等用户通过将电平表36b及电平表36c比较来观察,能够确认是否以适当的音量进行了讲话。由此,能够促使用户进行适合于识别部14的识别处理的音量下的讲话,所以能够改善识别部14的识别性能。
另外,在图14a及图14b中,说明了第1说话者51使用语音翻译装置10a及10b的情况,但并不限于此。也可以由第2说话者52使用语音翻译装置10a及10b,可以说是同样的。
[效果]
如以上这样,根据本变形例的语音翻译装置10a及10b,能够在用户的讲话时促使用户进行不使语音识别变困难那样的行动。更具体地讲,根据本变形例,用户能够一边确认是否以适当的音量的电平、sn比的电平或信号音量及噪语音量的电平进行了讲话,一边进行讲话。因此,能够促使用户进行适合于语音的识别处理的音量的电平、sn比的电平、或信号音量及噪语音量的电平下的讲话,所以能够进一步改善语音的识别性能。
另外,在上述中,将计算出的音量、sn比、或信号音量及噪语音量的电平原样显示在电平表上,但并不限于此。显示部16a也可以使电平表的电平在从下限阈值到上限阈值的范围中变化而显示在显示器30上。这里,关于下限阈值和上限阈值,考虑适当的音量等的电平的范围而预先设定。由此,用户能够一边直观地确认是否以适当的音量等的电平进行了讲话,一边进行讲话。使用图15a~图15c对该情况下的一例进行说明。
图15a~图15c是表示实施方式2的变形例2的由显示部16a显示的设定有上下限范围的电平表36d的一例的图。更具体地讲,在图15a中表示了在音量等的电平小于预先设定的下限阈值的情况下,电平表36d的音量等的电平无反应的样子。在图15b中,表示了在音量等的电平是预先设定的下限阈值以上且小于上限阈值的情况下,电平表36d的音量等的电平增减的样子。在图15c中,表示了在音量等的电平是预先设定的上限阈值以上的情况下,电平表36d的音量等的电平充满的状态的样子。因此,例如第1说话者51等用户通过观察设定有上下限范围的电平表36d的音量等的电平的增减,能够一边直观地确认是否以适当的音量等的电平进行了讲话,一边进行讲话。
这里,在图15a~图15c中,在使电平表的电平在从下限阈值到上限阈值的范围中变化的情况下,也可以不是以单色、而是使颜色不同来表现音量等的电平。即,显示部16a也可以根据音量等的电平的大小使电平表的颜色不同地显示。使用图16a~图16c对该情况下的一例进行说明。
图16a~图16c是表示实施方式2的变形例2的由显示部16a显示的音量等的电平的颜色变化的、设定有上下限范围的电平表36e的一例的图。对于与图15a~图15c同样的要素赋予相同的标号,省略详细的说明。
更具体地讲,在图16a中,表示了在音量等的电平小于预先设定的下限阈值的情况下,将电平表36e的音量等的电平以例如红等初始颜色的1段表现的样子。在图16b中,表示了在音量等的电平为预先设定的下限阈值以上且小于上限阈值的情况下,将电平表36e的音量等的电平以例如绿等初始颜色以外的段的增减来表现的样子。在图16c中,表示了在音量等的电平是预先设定的上限阈值以上的情况下,将电平表36e的音量等的电平以例如红等与下限阈值以上且小于上限阈值的情况不同的颜色的段表现的样子。因此,例如第1说话者51等用户通过观察设定有上下限范围的电平表36e的音量等的电平的颜色,能够一边直观地确认是否以适当的音量等的电平进行了讲话,一边进行讲话。
此外,在图16a~图16c中,在使电平表的电平在从下限阈值到上限阈值的范围中变化、并且使颜色不同地表现的情况下,也可以在显示器30上还显示表示促使用户行动的讲话方法的消息。即,也可以是,显示部16a还在显示器30上显示与音量等的电平的大小相应的通知。使用图17a~图17c对该情况下的一例进行说明。
图17a~图17c是表示实施方式2的变形例2的由显示部16a显示的电平表36f和消息37的一例的图。对于与图16a~图16c同样的要素赋予相同的标号,省略详细的说明。
更具体地讲,在图17a中,在音量等的电平小于下限阈值的情况下,将电平表36f的音量等的电平用初始颜色的1段表现,并且显示“マイクの近くでお話ください(请在麦克风的近处说话)”的消息37。在图17b中,在音量等的电平为下限阈值以上且小于上限阈值的情况下,将电平表36f的音量等的电平用初始颜色以外的段的增减表现,并显示“認識可能(能够识别)”的消息37。在图17c中,在音量等的电平为上限阈值以上的情况下,将电平表36f的音量等的电平用与下限阈值以上、小于上限阈值的情况不同的颜色的段表现,并且显示“マイクから離れてお話ください(请远离麦克风说话)”的消息37。因此,例如第1说话者51等用户不仅通过观察电平表36f的音量等的电平的颜色,还通过确认消息37,能够一边确认是否以适当的音量等的电平进行了讲话,一边进行讲话。
(变形例3)
在变形例1中,使用sn比判定了语音识别是否困难,但并不限于此。以下,以与变形例1不同之处为中心进行说明。
图18是表示实施方式2的变形例3的语音翻译装置10c的结构的一例的图。对于与图11同样的要素赋予相同的标号,省略详细的说明。
语音翻译装置10c相对于图11所示的语音翻译装置10b,显示决定部13c的结构不同,并追加了噪音特性计算部18。
[噪音特性计算部18]
噪音特性计算部18使用通过由波束成形部11形成的波束来集音而得到的语音信号,计算噪音特性。在本变形例中,噪音特性计算部18使用由麦克风阵列部20取得的语音信号、或由方向指定部12指定的一方的输出,计算噪音特性。
例如,噪音特性计算部18也可以计算峰度作为噪音特性。这里,峰度是表示信号的频数分布相对于正态分布尖多少的统计量,是表示信号的时间变化(稳定性/非稳定性)的指标。峰度可用于表示由麦克风阵列部20取得的语音信号或由波束成形部11形成的波束成形的时间上的变化小还是大的指标。
此外,噪音特性计算部18也可以计算与语音模型的类似度作为噪音特性。噪音特性计算部18使用方向指定部12中未被指定的输出,计算作为未被指定的输出的第1波束或第2波束与语音模型的类似度。该类似度表示语音拟合度。并且,与语音模型的类似度越高,表示包含与语音的频率成分越相似的噪音(语音拟合度),所以可知语音识别困难。
[显示决定部13c]
显示决定部13c还使用由噪音特性计算部18计算出的噪音特性,判定由方向指定部12指定的一方的输出是否识别困难。显示决定部13c在使用噪音特性判定为语音识别困难的情况下,决定促使用户进行用于消除该困难的行动的讲话方法,并向显示部16a输出。
例如,假设噪音特性计算部18计算峰度作为噪音特性。在此情况下,如果由噪音特性计算部18计算出的峰度是阈值以上,则显示决定部13c判定为语音识别困难,决定讲话方法。并且,显示决定部13c将所决定的讲话方法向显示部16a输出。
另一方面,假设噪音特性计算部18计算与语音模型的类似度作为噪音特性。在此情况下,如果由噪音特性计算部18计算出的与语音模型的类似度是阈值以上,则显示决定部13c判定为语音识别困难,决定讲话方法。并且,显示决定部13c只要将所决定的讲话方法向显示部16a输出就可以。
另外,显示决定部13c也可以使用由s/n比计算部17计算出的sn比和由噪音特性计算部18计算出的噪音特性,判定用户进行的讲话的语音识别是否困难。此外,显示决定部13c也可以判定用户的误操作的有无。判定用户的误操作的有无的方法的详细情况如在实施方式1中说明的一样,所以省略说明。
[效果]
如以上这样,根据本变形例的语音翻译装置10c,至少使用噪音特性计算部18计算的噪音特性,能够高精度地判定是否因噪音而语音识别困难。即,能够提高语音识别是否困难的判定精度。
这样,语音翻译装置10c能够高精度地判定是否因噪音而语音识别困难,所以在语音识别困难的噪音状况下能够决定用于消除该困难的行动并向用户通知。由此,使得能够正确地进行语音识别,能够正确地翻译。
(变形例4)
接着,对变形例4进行说明。以下,以与变形例3不同之处为中心进行说明。
图19是表示实施方式2的变形例4的语音翻译装置10d的结构的一例的图。对于与图11及图18同样的要素赋予相同的标号,省略详细的说明。
语音翻译装置10d相对于图18所示的语音翻译装置10c,显示决定部13d、s/n比计算部17d和噪音特性计算部18d的结构不同,并追加了语音判定部19。
[语音判定部19]
语音判定部19通过判定利用由波束成形部11形成的波束来集音而得到的语音信号是表示语音还是表示语音以外的非语音,来判定该语音信号的语音区间。在本变形例中,语音判定部19判定由方向指定部12指定的一方的输出的语音区间。
[s/n比计算部17d]
s/n比计算部17d使用通过由波束成形部11形成的波束来集音的语音信号中的由语音判定部19判定的语音区间的语音信号,计算sn比。在本变形例中,s/n比计算部17将由方向指定部12指定的一方的输出中的由语音判定部19判定的语音区间的输出作为sn比中的信号成分,将被指定的该一方的输出中的由语音判定部19判定的非语音区间作为噪声成分,计算sn比。
[噪音特性计算部18d]
噪音特性计算部18d使用通过由波束成形部11形成的波束来集音而得到的语音信号中的由语音判定部19判定的非语音区间的输出,计算噪音特性。在本变形例中,噪音特性计算部18d使用由方向指定部12指定的一方的输出中的由语音判定部19判定的非语音区间的输出,计算噪音特性。
这里,噪音特性如上述那样,既可以是峰度,也可以是与语音模型的类似度。在噪音特性是与语音模型的类似度的情况下,噪音特性计算部18计算由方向指定部12指定的一方的输出中的由语音判定部19判定的非语音区间的输出与语音模型的类似度。
[显示决定部13d]
显示决定部13d使用由语音判定部19判定的语音区间,判定由方向指定部12指定的一方的输出是否识别困难。在本变形例中,显示决定部13d使用由噪音特性计算部18d计算出的噪音特性,判定由方向指定部12指定的一方的输出是否识别困难。显示决定部13d在使用噪音特性判定为语音识别困难的情况下,决定促使用户进行用于消除该困难的行动的讲话方法,并向显示部16a输出。
另外,显示决定部13d也可以使用由s/n比计算部17d计算出的sn比和由噪音特性计算部18计算出的噪音特性,判定用户进行的讲话的语音识别是否困难。此外,显示决定部13d也可以判定用户的误操作的有无。即,也可以是,显示决定部13d还使用由语音判定部19判定的语音区间,来判定用户的操作是否错误。在此情况下,显示决定部13d只要基于通过用户的操作进行的向方向指定部12的指定、和通过由波束成形部11形成的波束来集音的语音信号中的由语音判定部19判定的语音区间的语音信号的大小,来判定用户的误操作的有无就可以。关于用户的误操作的有无的判定方法的详细情况如在实施方式1中说明的一样,所以省略说明。
[效果]
如以上这样,根据本变形例的语音翻译装置10d,由于能够提高sn比及噪音特性的计算的精度,所以能够更高精度地进行语音识别是否困难的判定。进而,根据本变形例的语音翻译装置10d,能够更高精度地进行用户是否进行了误操作的判定。
以上,基于实施方式及变形例对有关本发明的一个或多个技术方案的语音翻译装置等进行了说明,但本发明并不限定于这些实施方式等。只要不脱离本发明的主旨,对本实施方式实施了本领域技术人员想到的各种变形后的形态、或将不同实施方式的构成要素组合而构建的形态也可以包含在本发明的一个或多个技术方案的范围内。例如,以下这样的情况也包含在本发明中。
(1)构成上述语音翻译装置的识别部14的识别处理及翻译部15的翻译处理也可以在云上进行。在此情况下,识别部14及翻译部15只要进行与云的通信、将对象数据向云发送、取得进行识别处理及翻译处理后的数据就可以。
(2)在上述的语音翻译装置等中,假设作为讲不同语言的2名说话者用来实现意思的沟通的工具而被使用、相互地将一方的说话者的语音翻译为另一方的说话者的语言而进行了说明,但并不限于此。上述的语音翻译装置等也可以作为讲不同语言的多个说话者用来实现意思的沟通的工具而被使用。在此情况下,波束成形部只要使集音方向分别朝向作为将语音翻译装置的显示器30包围的多个说话者所处的区域而被分配的区域就可以。并且,只要将一个说话者的语音翻译为多个其他说话者各自的语言并显示在多个说话者所处的区域中就可以。
(3)上述的语音翻译装置等具体而言也可以是由微处理器、rom、ram、硬盘单元、显示器单元、键盘、鼠标等构成的计算机系统。在上述ram或硬盘单元中存储有计算机程序。通过由上述微处理器按照上述计算机程序动作,各构成要素达成其功能。这里,为了达成规定的功能,计算机程序是将表示对计算机的指令的命令代码组合多个而构成的。
(4)构成上述语音翻译装置等的构成要素的一部分或全部也可以由1个系统lsi(largescaleintegration:大规模集成电路)构成。系统lsi是将多个结构部集成到1个芯片上而制造出的超多功能lsi,具体而言,是包括微处理器、rom、ram等而构成的计算机系统。在上述ram中存储有计算机程序。通过由上述微处理器按照上述计算机程序动作,系统lsi达成其功能。
(5)构成上述语音翻译装置等的构成要素的一部分或全部也可以由相对于各装置可拆装的ic卡或单体的模块构成。上述ic卡或上述模块是由微处理器、rom、ram等构成的计算机系统。上述ic卡或上述模块也可以包括上述的超多功能lsi。通过由微处理器按照计算机程序而动作,上述ic卡或上述模块达成其功能。该ic卡或该模块也可以具有耐篡改性。
本发明能够利用于作为讲不同语言的说话者用来实现意思的沟通的工具而使用的语音翻译装置、语音翻译方法及记录介质。
- 还没有人留言评论。精彩留言会获得点赞!