基于VAWGAN-AC的多对多语音转换方法与流程
本发明涉及一种多对多语音转换方法,特别是涉及一种基于vawgan-ac的多对多语音转换方法。
背景技术:
语音转换(voiceconversion,vc)是一种将源说话人语音转为目标说话人语音同时保留语义信息的技术。近几年的研究中,vc模型采用深度神经网络(deepneuralnetworks,dnn),将源语音参数转换为目标语音参数,相比于传统的高斯混合模型(gaussianmixturemodel,gmm),dnn可以更有效地转换语音特征。
最近,变分自动编码器(variationalauto-encoder,vae)已经被用于非平行的vc模型,因为vae比受限制的boltzmann机更容易训练。在传统的基于vae的非平行vc中,编码器从输入语音参数中提取与说话者无关的代表语义内容的潜在变量,然后解码器从潜在变量中重建参数。然而由于vae的潜在变量中的过度正则化效应,这使得潜在变量的分布过于简单化,并且很难代表语义内容的基础结构,这种基于vae的非平行语料转换语音的质量低于用平行语音语料库训练的dnn转换的质量。如果使用潜在变量的更复杂的先验分布,例如gmm来解决该问题,但是因为语义内容的变化很大,不容易确定gmm集群的数量,所以实现起来非常困难。目前,基于vae的非平行语料转换语音方法存在着转换后的语音质量差、噪声多等不足。
技术实现要素:
发明目的:本发明要解决的技术问题是提供一种基于vawgan-ac的多对多语音转换方法,通过添加辅助分类信息来增加输出的分类与真实分类的损失计算,并将分类损失添加到生成器的损失计算中,解决了转换过程中带来的噪声问题,进一步提升生成器生成频谱的质量,能够较好地改善语音转换后的质量和个性相似度,实现高质量的语音转换。
技术方案:本发明所述的基于vawgan-ac的多对多语音转换方法,包括训练阶段和转换阶段,其中所述训练阶段包括以下步骤:
(1.1)获取由多名说话人的语料组成的训练语料,包含源说话人和目标说话人;
(1.2)将所述的训练语料通过world语音分析/合成模型,提取出各说话人语句的频谱包络特征x、非周期性特征、对数基频logf0;
(1.3)将训练语料的频谱包络特征x、说话人标签y输入vawgan-ac网络进行训练,所述vawgan-ac网络由编码器、生成器和鉴别器组成,训练过程使生成器的损失函数尽量小,使鉴别器的损失函数尽量大,直至设置的迭代次数,得到训练好的vawgan-ac网络;
(1.4)构建从源说话人的语音基频到目标说话人的语音基频的基频转换函数;
所述转换阶段包括以下步骤:
(2.1)将待转换语料中源说话人语音通过world语音分析/合成模型提取出每条语句的频谱包络特征xs、非周期性特征、对数基频logf0s;
(2.2)将上述源说话人频谱包络特征xs、目标说话人标签特征yt输入步骤(1.3)中训练好的vawgan-ac网络,从而重构出目标说话人频谱包络特征xt′;
(2.3)通过步骤(1.4)得到的基频转换函数,将步骤(2.1)中提取出的源说话人对数基频logf0s转换为目标说话人的对数基频logf′0t;
(2.4)将步骤(2.2)中得到的频谱包络特征x′t、(2.3)中得到的对数基频logf′0t和步骤(2.1)中提取的非周期性特征通过world语音分析/合成模型,合成得到转换后的说话人语音。
进一步的,步骤(1.3)中的训练过程包括以下步骤:
(1)将所述的训练语料频谱包络特征x,作为所述vawgan-ac网络中编码器的输入数据,输出得到说话人无关的语义特征z;
(2)将上述语义特征z、说话人标签特征y输入生成器进行训练,使生成器的损失函数尽量小,得到生成的说话人频谱包络特征x′;
(3)将上述说话人频谱包络特征x′和训练语料频谱包络特征x输入所述鉴别器,计算yr和yc,yr表示鉴别器输入频谱的真或假,yc表示鉴别器输入频谱的类别,利用yc优化生成器与鉴别器的损失函数,对鉴别器进行训练,使鉴别器的损失函数尽量大;
(4)重复步骤(1)、(2)和(3),直至达到迭代次数,从而得到训练好的vawgan-ac网络。
进一步的,步骤(2.2)中的输入过程包括以下步骤:
(1)将频谱包络特征xs输入vawgan-ac网络中的编码器,得到说话人无关的语义特征z;
(2)将上述语义特征z、目标说话人标签特征yt输入到所述的生成器中,重构出目标说话人频谱包络特征x′t。
进一步的,所述vawgan-ac网络中的编码器采用二维卷积神经网络,包括5个卷积层和1个全连接层。5个卷积层的过滤器大小均为7*1,步长均为3,过滤器深度分别为16、32、64、128、256。
进一步的,所述vawgan-ac网络中的生成器采用二维卷积神经网络g,损失函数为:
所述的鉴别器采用二维卷积神经网络d,损失函数为:
其中,gθ为生成器网络,dψ为鉴别器网络,
进一步的,所述的生成器的二维卷积神经网络g包括4个卷积层,4个卷积层的过滤器大小分别为9*1、7*1、7*1、1025*1,步长分别为3、3、3、1,过滤器深度分别为32、16、8、1;所述的鉴别器的二维卷积神经网络d,包括3个卷积层和1个全连接层,3个卷积层的过滤器大小分别为7*1、7*1、115*1,步长均为3,过滤器深度分别为16、32、64。
进一步的,所述的基频转换函数为:
其中,μs和σs分别为源说话人的基频在对数域的均值和方差,μt和σt分别为目标说话人的基频在对数域的均值和方差,logf0s为源说话人的对数基频,logf0c为转换后目标说话人的对数基频。
有益效果:本发明能够将条件变分自编码器和生成对抗网络(variationalautoencodingwassersteingenerativeadversarialnetwork,vawgan)与辅助分类生成对抗网络(auxiliaryclassifiergenerativeadversarialnetwork,acgan)相结合,实现语音转换系统,通过鉴别器输出辅助分类信息,增加输出分类与真实分类的损失计算,使生成的频谱与其所属的类别一一对应,得到分类损失并添加到生成器的损失计算中,从而对生成器添加类别约束,进一步提升生成器生成频谱的质量,减少转换过程中带来的噪声,能够较好地提升语音转换后的质量和个性相似度,实现高质量的语音转换。此外,本方法的训练过程并不依赖平行文本,能够实现非平行文本条件下的语音转换,而且训练过程不需要任何对齐过程,提高了语音转换系统的通用性和实用性。本方法还可以将多个源-目标说话人对的转换系统通过一个转换模型实现,即实现多说话人对多说话人转换。本方法在电影配音、语音翻译、语音合成等领域有较好的应用前景。
附图说明
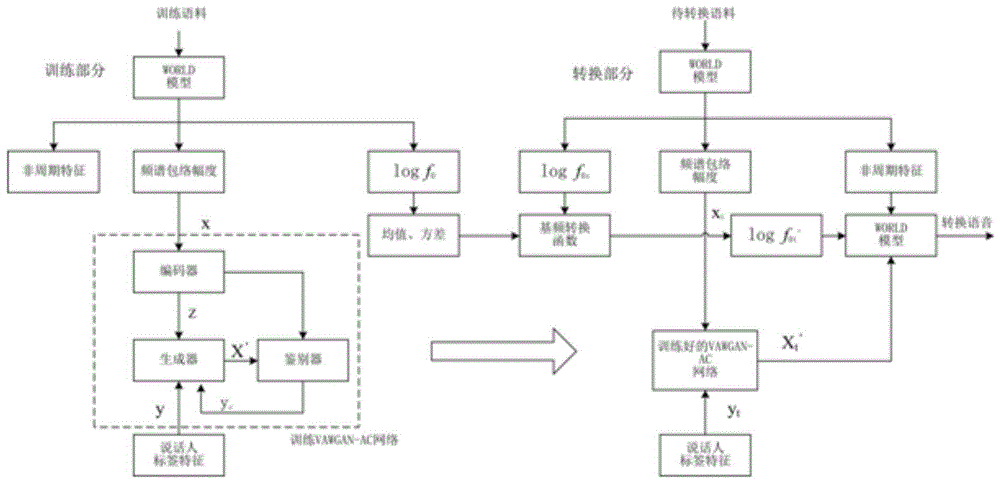
图1是本方法的整体流程图。
具体实施方式
如图1所示,本发明所述高质量语音转换方法分为两个部分:训练部分用于得到语音转换所需的模型参数和转换函数,而转换部分用于实现源说话人语音到目标说话人语音的转换。
训练阶段实施步骤为:
1.1)获取非平行文本的训练语料,训练语料是多名说话人的语料,包含源说话人和目标说话人。训练语料取自vcc2018语音语料库,选取该语料库中4名男性和4名女性说话人的非平行文本训练语料,每名说话人有81句语料。该语料库还包含每句训练语料的语义内容。源说话人和目标说话人的训练语料既可以是平行文本,也可以是非平行文本的。
1.2)训练语料通过world语音分析/合成模型提取出各说话人语句的频谱包络特征x、非周期性特征、对数基频logf0。其中由于快速傅氏变换(fastfouriertransformation,fft)长度设置为1024,因此得到的频谱包络特征x和非周期性特征均为1024/2+1=513维。
1.3)将1.2)提取的训练语料的频谱包络特征x,作为vawgan-ac编码器的输入数据,经过网络训练后得到说话人无关的语义特征z。其中编码器采用二维卷积神经网络,包括5个卷积层和1个全连接层。5个卷积层的过滤器大小均为7*1,步长均为3,过滤器深度分别为16、32、64、128、256。
本实施例中的vawgan-ac网络以条件变分自动编码器(conditionalvariationalauto-encoders,c-vae)为基础,将wgan合并到解码器中来提升c-vae效果,同时借鉴acgan中的鉴别器的结构,将鉴别器输出的类别信息作为辅助信息添加到生成器与鉴别器的损失函数中进行计算,从而进一步提升语音频谱的转换效果。w-gan由两个部分组成:一个产生真实的频谱的生成器g,一个判断输入是真实的频谱还是生成的频谱的鉴别器d,wgan-ac的网络结构与w-gan类似,改进点在于鉴别器将有两个输出,分别为yr和yc,其中yr表示鉴别器输入频谱的真假,yc表示鉴别器输入频谱的类别信息。
vawgan-ac网络的目标函数为:
jvawgan-ac=l(x;φ,θ)+αjwgan-ac,
其中,l(x;φ,θ)为c-vae部分的目标函数:
其中,dkl(qφ(z|x)||pθ(z))表示判别模型qφ(z|x)和真实后验概率p(z|x)之间的kl散度。先验概率pθ(z)为标准多维高斯分布。qφ(z|x)和pθ(x|z)分别为编码器和解码器,服从多维高斯分布,其均值向量和协方差矩阵分别为(μφ(z),σφ(z))和(μθ(x),σθ(x))。因此,右边两项可以简化为:
其中,k为中间变量z的维数,l为对qφ(z|x)取样的次数。由于取样过程是一个非连续的操作,无法求导,因此无法通过反向传播来更新编码器和解码器的网络参数。于是引入另一个随机变量ε对隐藏变量z进行再参数化,令z(l)=μθ(x)+ε(l)*σθ(x),ε(l)~n(0,i),则:
其中,d为x的样本数。
至此,最大化c-vae的目标函数已经转换为求解凸优化问题,利用随机梯度下降法(stochasticgradientdescent,sgd)来更新网络模型参数。α是wgan-ac的损失系数。jwgan-ac表示wgan-ac部分的目标函数:
生成器二维卷积神经网络的损失函数为:
优化目标为:
鉴别器二维卷积神经网络的损失函数为:
优化目标为:
1.4)将1.3)得到的训练语料的语义特征z与说话人标签特征y作为联合特征(z,y)输入到解码器进行训练。其中y为每一个说话人的标签,在本方法中,采用8个说话人进行训练,对每一个说话人进行标号,8个参与训练的说话人分别标为0、1、2、3、4、5、6、7,并将标号编码为one-hot,即得到y。解码器由生成器和鉴别器组成。训练生成器,使生成器的损失函数lg尽量小,得到生成的说话人频谱包络特征x′。生成器采用二维卷积神经网络,包括4个卷积层。4个卷积层的过滤器大小分别为9*1、7*1、7*1、1025*1,步长分别为3、3、3、1,过滤器深度分别为32、16、8、1。鉴别器采用二维卷积神经网络,包括3个卷积层和1个全连接层。3个卷积层的过滤器大小分别为7*1、7*1、115*1,步长均为3,过滤器深度分别为16、32、64。
1.5)将1.4)得到的生成的说话人频谱包络特征x′和1.2)得到的训练语料的频谱包络特征x作为鉴别器的输入,训练鉴别器,使鉴别器的损失函数ld尽量大。
1.6)重复1.3)、1.4)和1.5),直至达到迭代次数,从而得到训练好的vawgan-ac网络,其中编码器参数φ、生成器参数θ、鉴别器参数ψ为训练好的参数。本实验中选择迭代次数为200000次。
1.7)使用对数基频logf0的均值和方差建立基音频率转换关系,统计出每个说话人的对数基频的均值和方差,利用对数域线性变换将源说话人对数基频logf0s转换得到目标说话人语音基频logf′0t。
基频转换函数为:
其中,μs和σs分别为源说话人的基频在对数域的均值和方差,μt和σt分别为目标说话人的基频在对数域的均值和方差。
转换阶段实施步骤:
2.1)将源说话人语音通过world语音分析/合成模型提取出源说话人的不同语句的频谱包络特征xs、非周期性特征、对数基频logf0s。其中由于fft长度设置为1024,因此得到的频谱包络特征x和非周期性特征均为1024/2+1=513维。
2.2)将2.1)提取的源说话人语音的频谱包络特征xs,作为vawgan-ac中编码器的输入数据,得到说话人无关的语义特征z。
2.3)将2.2)得到的语义特征z、说话人标签特征yt作为联合特征(z,yt)输入1.6)训练好的vawgan-ac网络,从而重构出目标说话人频谱包络特征xt′。
2.4)通过1.7)得到的基音频率转换函数,将2.1)中提取出的源说话人对数基频logf0s转换为目标说话人的对数基频logf′0t
2.5)将2.3)中得到的目标说话人频谱包络特征xt′、2.4)中得到的目标说话人的对数基频logf′0t和2.1)提取的非周期性特征通过world语音分析/合成模型合成转换后的说话人语音。
- 还没有人留言评论。精彩留言会获得点赞!