一种基于声学特征转换的语音清晰度增强方法与流程
本发明提供了一种基于声学特征转换的语音清晰度增强方法,尤其涉及人工智能、机器学习、语音信号处理和网络通信领域,适用于实时语音通信系统、人机交互系统等有关语音通信的系统与设备。
背景技术:
随着移动通信技术的迅猛发展,凭借着强大的移动通信网络和高性能通话终端,移动语音通信逐步取代固话通信成为主流语音通信方式。依靠着移动通信带来的便捷,人们能够随时随地进行语音通信。但随之而来的,是通话者不可避免的在商场、车站、餐厅等噪声环境包围的条件下进行语音通信,环境噪声大幅度降低了语音的听觉清晰度和感知可懂度。
另一方面,随着近年来智能音箱等设备的语音人机交互技术不断发展,人们越来越频繁地通过智能交互设备在各种环境中进行人机对话。合成语音信号在环境噪声中的抗掩蔽性远低于自然语音,其在环境噪声中的听觉清晰度和感知可懂度下降更为严重。
如何有效提高语音信号在噪声环境中听觉清晰度和感知可懂度,是当前语音通信与交互过程中一个亟待解决的问题。
在噪声环境中的语音通信过程可以拆分为说话过程和听音过程;在说话过程中,说话人向语音通信设备说出一段语音信号,设备麦克风采集语音信号,同时也采集到了环境噪声信号;在听音过程中,语音通信设备播放语音信号,人耳听到播放的语音信号,同时也听到了环境噪声信号。
为了滤除说话过程中麦克风采集到的噪声,结合多麦克风阵列抗噪技术等硬件措施和语音增强(speechenhancement)算法,目前说话过程中的噪声已经几乎可以被完全滤除,听音者已基本上免受说话过程中的环境噪声干扰。
为了降低听音过程中人耳受到的环境噪声干扰,针对耳机应用诞生了主动降噪技术,通过频率、振幅相同,相位相反的反噪声信号抵消环境噪声,因为耳机以物理隔绝的方式预先阻隔了绝大部分噪声,剩余能量不高的噪声得以被反噪声信号几乎完全抵消掉。而在最常见的听筒模式或人机交互设备(如:智能音箱)中,人耳和设备均暴露在开放性环境中,主动降噪技术难以抵消能量巨大的环境噪声。语音清晰度增强(speechintelligibilityenhancement)技术,又称作语音可懂度增强技术或近端听音增强(near-endlisteningenhancement)技术,是一种基于声学掩蔽原理、人耳感知特性和语言特性的信号增强方法,经过增强的语音信号在时频特性和语音特性上发生变化,不易被环境噪声掩蔽,较未增强的语音在相同噪声中拥有更高的听觉清晰度和感知可懂度。语音清晰度增强不改变环境中的噪声能量,却能让人耳更容易地获取信息,是一种适用于听筒、耳机、人机交互设备的通用型方案。
本发明提出了一种基于声学特征转换的语音清晰度增强方法,是一种结合说话人噪声对抗的发声机理和自然语音生成模型的全新语音清晰度增强方法。
抗噪发声机理,是指人在噪声环境中说话时,环境噪声压迫说话人,使人本能地改变自己的发声模式来抵御周围噪声的干扰。这种发声模式的改变会带来语音声学特征的转换,使语音信号相对于安静环境中说话时发生明显的改变,这种改变能显著提高语音的听觉清晰度和感知可懂度。这种受压迫而改变音调的本能行为称作lombard效应,故这种噪声对抗的发声机理下产生的语音又称为lombard语音。lombard效应改变了语音声学特征的众多要素,包括:频谱倾斜度(spectraltilt)、基频(fundamentalfrequency,f0)、一阶共振峰(thefirstformant,f1)、二阶共振峰(thesecondformant,f2)、能量、语速……在设备功率受限的实时通信条件下,能量、语速特征无法利用,而频谱倾斜度、基频、能量被众多研究证实为对语音清晰度改善至关重要的因素。本发明正是利用频谱倾斜度、基频、能量这三个最重要的因素,将通信终端接收到的语音信号相关要素映射为lombard语音的相关要素,再利用自然语音生成模型和lombard语音要素合成增强语音信号,从而提升语音清晰度。
自然语音生成模型是利用语音信号声学特征合成完整语音信号的一种方式,本发明以频谱倾斜度、基频、能量这三个关键因素为主,合成lombard语音。
本发明的方法较现有语音清晰度增强算法相比,摒弃了早期的纯数字信号处理方法,不使用生硬的语音频带间抗掩蔽能量调整策略,避免了因不考虑语音自然度而造成的自然度严重失真的问题。较现有基于lombard效应的增强算法而言,本发明考虑了更多lombard效应的要素,并结合深度学习技术与传统机器学习学术,使用长短时记忆(longshort-termmemory,lstm)网络和贝叶斯高斯混合模型(bayesiangaussianmixturemodel,bgmm)映射不同的要素,提高了映射精度,使听觉清晰度和感知可懂度进一步提升。
技术实现要素:
本发明提供了一种基于声学特征转换的语音清晰度增强方法,解决了在噪声环境中收听语音时(如:接听电话、聆听智能音箱的交互语音),原本清晰的语音信号被环境噪声掩蔽从而导致听觉清晰度和感知可懂度下降的问题。由于传统数字信号处理方法所采用的是在语音频带间生硬地进行频谱能量搬移,没有考虑语音自然度的问题,导致语音虽然提升了清晰度,但自然度严重缺失。本发明基于说话人噪声对抗机理——lombard效应和自然语音生成模型,在提升语音清晰度的同时又不失自然度。同时,较现有基于lombard效应的增强算法相比,本发明考虑了更多lombard效应的要素,并结合深度学习与传统机器学习构建声学特征映射模型,使听觉清晰度和感知可懂度得到了进一步提升。为了使本增强算法更好的适用于编码传输后有轻微失真的语音信号,映射模型加入了从有失真的信号中尽可能重建无失真语音信号的声学特征的能力。
具体采用如下方案:
一种基于声学特征转换的语音清晰度增强方法,其特征在于,包括:
步骤a、训练训练贝叶斯高斯混合模型,具体包括:
步骤a1:搜集语音资料构建训练数据集,语音资料包括普通语音和抗噪语音两部分;
步骤a2:使用时长对齐算法,将每一句lombard语音的时长匹配至与对应普通语音时长相等;
步骤a3:对数据集中的普通语音进行编解码处理,获得解码后的语音信号;
步骤a4:使用重叠窗对所有语音信号分帧;
步骤a5:提取每帧普通语音的对数幅度谱、能量系数、基频系数,提取lombard语音的线谱频率、能量系数、基频系数;将对数幅度谱作为普通语音的频谱倾斜度特征表达式,将线谱频率作为lombard语音的频谱倾斜度特征表达式;
步骤a6:使用普通语音的对数幅度谱作为输入数据,使用lombard语音的线谱频率作为输出数据,训练长短时记忆(longshort-termmemory,lstm)网络作为频谱倾斜度特征映射模型;
步骤a7:使用普通语音的能量系数、基频系数作为输入数据,使用lombard语音的能量系数、基频系数作为输出数据训练贝叶斯高斯混合模型(bayesiangaussianmixturemodel,bgmm)作为能量和基频特征映射模型;
步骤b、采用步骤a中训练好的模型进行语音清晰度增强,具体包括:
步骤b1:逐帧获取实时语音通信终端设备或实时语音交互设备解码后的语音信号,提取解码信号的对数幅度谱、能量系数、基频系数,作为待映射的参数;根据步骤b3中合成声码器的差异,若合成声码器需要非映射参数则提取相应的参数,若合不需要非映射参数则不提取;因本发明不限定声码器的种类,故既不限定非映射参数是否提取,也不限定提取的数量和种类;
步骤b2:使用由lstm网络构成的频谱倾斜度特征映射模型将对数幅度谱映射为具备lombard语音特性的线谱频率,使用由bgmm模型构成的能量和基频特征映射模型将能量系数、基频系数映射为具备lombard语音特性的能量系数、基频系数;
步骤b3:根据映射后的特征参数和步骤b1中提取的所需非映射参数,使用声码器合成lombard语音;
步骤b4:根据环境噪声,使用自适应增益控制算法实时调整输出语音信号的增益
在上述的一种基于声学特征转换的语音清晰度增强方法,步骤a1所述训练数据集中,普通语音为说话人在安静环境中产生的普通风格语音信号;抗噪语音为说话人在噪声环境中说话时,受环境噪声压迫而本能产生的一种音调改变、具备更强抵御噪声掩蔽能力的抗噪语音信号,这种受压迫而改变音调的本能行为称作lombard效应,故抗噪语音又称为lombard语音;普通语音和lombard语音是平行数据,即数据集中每一个人说的每一句话既有普通风格语音又有对应的lombard风格语音;lombard语音包含不同场景下不同能量的噪声激励时产生的语音信号;组建数据集过程中既可以一句普通语音对应多个不同场景的lombard语音,也可以每句普通语音只有某一个场景下的lombard语音与之对应。
在上述的一种基于声学特征转换的语音清晰度增强方法,步骤a2中,同一个人在不同环境中说出的同一句话存在一定时长差异,所以需要使用动态时间归整(dynamictimewarping,dtw)等任意一种时长对齐算法,使每一句lombard语音的时长与对应普通语音时长一致。
在上述的一种基于声学特征转换的语音清晰度增强方法,步骤a中,对数据集中的普通语音进行编解码处理,获得解码后的语音信号,从而在步骤a6和a7中,使映射模型能够学习重建无失真语音信号声学特征的能力。
在上述的一种基于声学特征转换的语音清晰度增强方法,步骤a5和b1中对数幅度谱是基于长度为l的离散傅里叶变换并取对数运算得到,l的取值为2n数值,其中n取正整数;线谱频率的特征在于由p阶线性预测模型计算得到,p的长度取4n,其中n为大于等于2的正整数,线性预测模型采用经典线性预测算法或改进型线性预测算法;能量系数和基频系数的特征在于每一帧用一个数值表达,即它们都为一维变量,计算方式可以为现有能量系数和基频系数计算方法中的任意一种;步骤b1所述的非映射参数因步骤b2中所使用的声码器而异,常用参数包括频谱包络、第一共振峰频率、第二共振峰频率等,也有某些声码器不需要非映射参数。
在上述的一种基于声学特征转换的语音清晰度增强方法,步骤a6和b2所述lstm网络中,输入数据为一帧普通语音对数幅度谱的前一半系数,输出数据为一帧对应lombard语音的线谱频率;网络结构由循环层、全连接层和输出层组成;循环层为4层结构,每层节点数目为[l/2,l/4,l/8,l/16],时间步长为s,s的数值根据实验效果选取最优值;全连接层为2层结构,每层节点数量均为s×l/16,激活函数为tanh函数或sigmoid函数;输出层有p个节点,激活函数为linear函数或relu函数;网络训练过程根据情况选择合适的学习算法、训练次数、损失函数一系列超参数。
在上述的一种基于声学特征转换的语音清晰度增强方法,步骤a7和b2所述贝叶斯高斯混合模型中,输入数据为一帧普通语音的基频系数和能量系数,输出数据为一帧对应lombard语音的基频系数和能量系数;贝叶斯高斯混合模型由m个高斯分布组成,m根据实际训练效果自由选择最优值;模型训练过程根据情况选择合适的学习算法、训练次数、损失函数等一系列超参数。
在上述的一种基于声学特征转换的语音清晰度增强方法,步骤b1和b3所述声码器使用映射参数和非映射参数合成具备抗噪增强特性的lombard语音;或者不使用非映射参数只是用映射参数合成lombard语音;所述步骤b1中,还需要根据步骤b3中声码器的需求,提取其他的非映射参数,包括基于滤波器的声码器和基于神经网络的声码器。
本语音清晰度增强方法处理前后的语音信号均为干净、无噪语音,但语音音调、局部能量等声学特征发生了变化,从原本的普通风格语音转变为lombard风格的抗噪语音;较未增强相比,增强后的语音在噪声环境中具备更强的鲁棒性,不易被环境噪声掩蔽,在相同噪声条件下更容易被听音者准确获取语音信息,具备更强的听觉清晰度和感知可懂度。该方法适用于任何实时语音通信终端和实时语音交互设备,且适用于多语种、多模态的语音信号。
附图说明
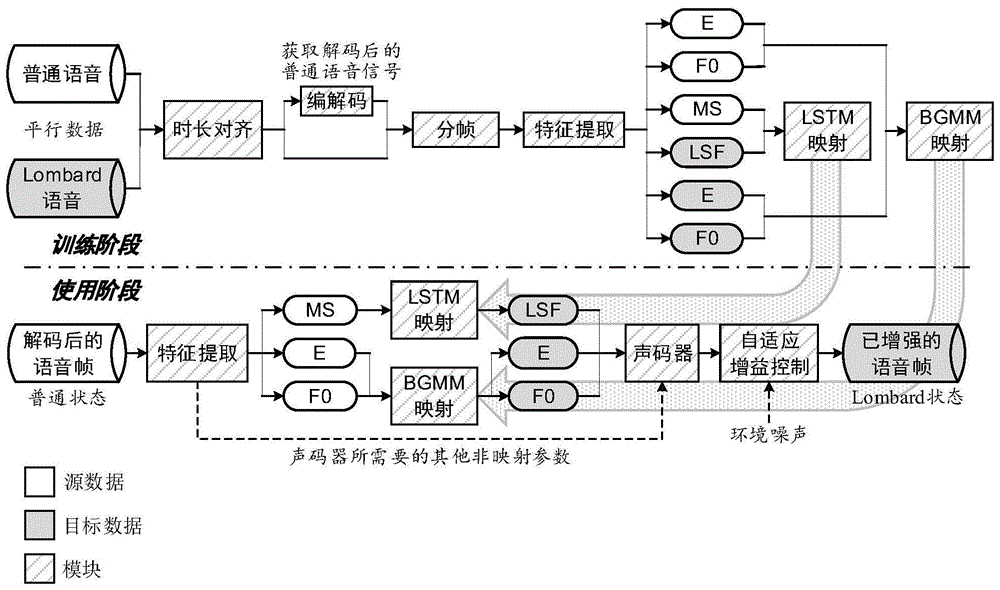
图1为本发明实施例的信号处理流程图。
具体实施方式
以下内容将结合本发明实施例中的附图,对本发明实施例进行进一步详细描述,应当理解,此处所描述的实施例仅是本发明的部分实施例,并非全部的实施例,并不用于限定本发明。本领域内技术人员在没有做出创造性劳动前提下基于本发明实施例所获取的任何实施例,均为本发明申请的保护范围。
本发明提供了一种适用于任意实时语音通信终端和实时语音交互设备的语音清晰度增强方法,即“一种基于声学特征转换的语音清晰度增强方法”,用于解决在噪声环境中收听语音时(如:接听电话、聆听智能音箱的交互语音),原本清晰的语音信号被环境噪声掩蔽从而导致听觉清晰度和感知可懂度下降的问题。
为改进现有语音清晰度增强技术在语音自然度、算法鲁棒性等方面等一系列问题,本实施例阐述出了一种基于声学特征转换的语音清晰度增强方法,本方法实施流程图如图1所示。
实施例的实现过程分为训练阶段和使用阶段。训练阶段:基于语音数据集驱动,训练具备声学特征转换能力的映射模型;使用阶段:利用已经训练好的映射模型和对应的预处理、后处理算法,将普通语音转化那位具备抗噪能力的lombard语音。
本方法训练阶段包括以下具体实施步骤:
步骤a1:如图1训练阶段中源数据“普通语音”和目标数据“lombard语音”所示,搜集普通语音和lombard语音构建训练数据集,语音资料包括普通语音和基于抗噪发声模式的lombard语音两部分;普通语音和lombard语音是平行数据,即数据集中每一个人说的每一句话既有普通风格语音又有对应的lombard风格语音;lombard语音包含不同场景下不同能量的噪声激励时产生的语音信号;
普通语音和lombard语音既可以为一对一关系,又可以为一对多关系;当两者为一对一关系时,则代表每一句普通语音只有一句在某个场景下语言内容相同的语音,此时的一句普通语音与对应lombard语音组成一条训练数据;当两者为一对多关系时,则代表一句普通语音,在多个场景下有语言内容相同的语音,此时的一句普通语音分别与多个不同场景的lombard语音组成多条训练数据;
上述数据集的采样率可以为8000/6000/32000/44100/48000赫兹等;
优选的,数据集采样率为16000赫兹。
步骤a2:如图1训练阶段中“时长对齐”模块所示,使用时长对齐算法,将每一句lombard语音的时长匹配至与对应普通语音时长相等。
优选的,使用动态时间归整(dynamictimewarping,dtw)算法实现对齐。
步骤a3:如图1训练阶段中“编解码”模块所示,为了使映射模型能够学习从有失真的信号中尽可能重建无失真语音信号声学特征的能力,对数据集中的普通语音进行编解码处理,获得解码后的语音信号。
步骤a4:如图1训练阶段中“分帧”模块所示,使用重叠窗对所有语音信号分帧,可选择汉宁窗、海明窗等窗函数,可以取50%重叠、2/3重叠等常见重叠方式;窗长可以为16/20/30/32毫秒等常见数值;
优选的,使用50%重叠的32毫秒时长汉宁窗,即窗长为512个采样点。
步骤a5:如图1训练阶段中“特征提取”模块所示,提取普通语音的对数幅度谱(图中以ms表示)、能量系数(图中以e表示)、基频系数(图中以f0表示),提取lombard语音的线谱频率(图中以lsf表示)、能量系数、基频系数;将对数幅度谱作为普通语音的频谱倾斜度特征表达式,将线谱频率作为lombard语音的频谱倾斜度特征表达式;对数幅度谱通过长度为l的离散傅里叶变换并取对数运算得到,l的取值可以为256/512/1024/2048等2n数值;线谱频率由p阶线性预测模型计算得到,p的长度可以取8/12/16/20等常规值;能量和基频系数可以直接计算得到;
应该注意的是,本实施例不限定线性预测模型和线谱频率的计算方法;
优选的,l取512,p取20。
步骤a6:如图1训练阶段中“lstm映射”模块所示,使用频谱倾斜度特的特征表达式完成频谱倾斜度的特征映射,其中普通语音的对数幅度谱(高维变量)作为输入数据,lombard语音的线谱频率(高维变量)作为输出数据,训练lstm网络作为频谱倾斜度特征映射模型;
不直接使用频谱倾斜度作为映射参数是因为频谱倾斜度存在较大的数据冗余,每一帧信号的频谱倾斜度可以通过谱线频率直接计算得到:
st=dft(lsf,l)
其中,st代表频谱倾斜度,dft(lsf,l)代表对线谱频率(lsf)进行长度为l的离散傅里叶变换(discretefouriertransform,dft);
为了提高映射精度,输入数据使用了比线谱频率信息量更丰富的对数幅度谱(ms),因为频谱对称性,只需要幅度谱前一半系数作为输入数据;
lstm网络的输入与输出数据为逐帧匹配形式,网络结构由循环层、全连接层和输出层组成;循环层为4层结构,每层节点数目为[l/2,l/4,l/8,l/16],时间步长为s,s的数值根据实验效果选取最优值;全连接层为2层结构,每层节点数量均为s×l/16,激活函数为tanh函数或sigmoid函数;输出层有p个节点,激活函数为linear函数或relu函数;lstm网络实现的映射关系表达式为:
其中,下标n代表普通语音,下标l代表lombard语音,k代表当前时刻的第k帧,“:”代表从k-s+1到k的一连串数据;
优选的,s取5,全连接层激活函数为tanh函数,输出层激活函数为linear函数,使用均方误差为作为代价函数,随机梯度下降算法为训练方法,整个数据集迭代200次(epoch=200),每次批处理数据量为1000(batchsize=1000)。
步骤a7:如图1训练阶段中“bgmm映射”模块所示,使用普通语音的能量系数(一维变量)、基频系数作(一维变量)为输入数据,使用lombard语音的能量系数(一维变量)、基频系数(一维变量)作为输出数据训练贝叶斯高斯混合模型(以下简称为bgmm)作为能量和基频特征映射模型,bgmm由m个高斯分布组成;
应该注意的是,本实施例不限定能量和基频的计算方法,计算得到的某一帧(即第k帧)普通语音能量和基频可以表示为[e(k),f0(k)]n,同理,某一帧lombard通语音能量和基频可以表示为[e(k),f0(k)]l;因此bgmm实现的映射关系表达式为:
优选的,m取100,使用均方误差为作为代价函数,最大期望算法为训练方法,整个数据集迭代200次(iteration=200)。
可选的,为了更好的选择步骤a6和步骤a7中的一系列参数和全面的评估模型映射能力,在步骤a1中可以将训练数据集进一步划分为训练集、验证集、测试集三部分,训练集用于模型映射能力的训练,验证集用于在每次训练迭代中进行训练误差的评估,当多次迭代后验证集上的误差没有明显下降后可提前停止训练,测试集用于最终评估映射模型的准确度;
优选的,训练集、验证集、测试集三部分占比为总训练数据集的70%、10%、20%。
当映射模型训练完成后,本发明所述的方法可投入到使用阶段,该方法常嵌入至实时语音通信、交互系统解码器中作为后处理技术。本实施例的使用阶段包括以下具体实施步骤:
步骤b1:在获取图1使用阶段的源数据“解码后的语音帧”后,在使用阶段的“特征提取”模块中提取解码信号的对数幅度谱(ms)、能量系数(e)、基频系数(f0);
若图1使用阶段中“声码器”模块有其他非映射参数的使用需求,则根据声码器的需求提取对应参数。
步骤b2:如图1使用阶段中“lstm映射”模块所示,使用lstm网络将解码信号的对数幅度谱映射为具备lombard语音特性的线谱频率;如图1使用阶段中“bgmm映射”模块所示,使用bgmm将解码信号的能量系数、基频系数映射为具备lombard语音特性的能量系数、基频系数;
步骤b3:如图1使用阶段中“声码器”模块所示,根据映射后的特征参数和步骤b1中提取的所需非映射参数,使用声码器合成lombard语音,即初步完成的已增强的语音帧;
应该注意的是,本实施例不限定所使用的声码器类型和算法,可选择使用传统声码器或任意改进型声码器(如:基于神经网络的声码器);若使用传统声码器,则不需要非映射参数;若使用改进型声码器,根据声码器的具体需求在步骤b1中提取对应参数。
步骤b4:如图1使用阶段中“自适应增益控制”模块所示,根据环境噪声,使用自适应增益控制算法实时调整输出语音信号的增益。
经过训练阶段和使用阶段步骤b1~b4,生成了最终已增强的语音帧(如图1使用阶段中目标数据“已增强的语音帧”所示)。经过处理后的语音信号在语音音调、局部能量等声学特征发生了变化,从原本的普通风格语音转换为lombard风格的抗噪语音;增强前后均为干净、无噪语音;与未增强的语音相比,增强后的语音在噪声环境中具备更强的鲁棒性,不易被环境噪声掩蔽,在相同噪声条件下更容易被听音者准确获取语音信息,具备更强的听觉清晰度和感知可懂度。
综上,本发明提供了一种基于声学特征转换的语音清晰度增强方法,为改进现有语音清晰度增强技术在语音自然度、算法鲁棒性等方面的一系列问题,能应用于所有实时语音通信系统和实时人机交互系统。具体实施时,可使用计算机软件技术实现自动化处理流程。
应该注意的是,以上所描述内容仅为本发明的优先实施例,本发明不受上述实施例形式的限制,本领域的技术人员应当充分了解,凡参照本发明核心技术对上述实施例所做的形式更替、等价变换和描述修改,均在本发明技术方案所要求的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!