一种声纹识别方法及声纹识别装置与流程
本发明涉及语音信息处理技术领域,尤其涉及一种声纹识别方法及声纹识别装置。
背景技术:
声纹识别,生物识别技术的一种,也称为说话人识别,有两类,即说话人辨认和说话人确认。不同的任务和应用会使用不同的声纹识别技术,如缩小刑侦范围时可能需要辨认技术,而银行交易时则需要确认技术。声纹识别就是把声信号转换成电信号,再用计算机进行识别。
声纹识别有文本相关的(text-dependent)和文本无关的(text-independent)两种。
与文本有关的声纹识别系统要求用户按照规定的内容发音,每个人的声纹模型逐个被精确地建立,而识别时也必须按规定的内容发音,因此可以达到较好的识别效果,但系统需要用户配合,如果用户的发音与规定的内容不符合,则无法正确识别该用户。
与文本无关的识别系统则不规定说话人的发音内容,模型建立相对困难,识别率也次于文本相关技术,但这种方式用户使用方便,可应用范围较宽。
故如何提高文本无关的声纹识别准确率是本领域研究的一大重要课题。
技术实现要素:
针对上述研究课题,本发明的实施例,提供了一种声纹识别方法,所述方法包含步骤:接收未知用户输入的待识别语音信号;提取所述待识别语音信号中每一帧所对应的帧声纹特征;计算各所述帧声纹特征的后验概率;基于所述后验概率对各所述帧声纹特征进行分类,并确定每种分类的类型标识;基于所述类型标识确定已知用户对应的注册语音信号中是否包含相同的分类;若包含,则基于所述待识别语音信号的各所述相同分类中所包含的所述帧声纹特征,训练生成待识别模型,并基于所述注册语音信号的各所述相同分类中所包含的所述帧声纹特征,训练生成声纹识别模型;基于所述待识别模型与所述声纹识别模型的相似度确定所述未知用户是否为所述已知用户。
在一实施中,在所述基于所述类型标识确定已知用户对应的注册语音信号中是否包含相同的分类之前,所述方法还包含步骤:对所述已知用户对应的注册语音信号进行分类,得到每个分类的类型标识。
在一实施中,所述对所述已知用户对应的注册语音信号进行分类包含:采集已知用户输入的注册语音信号,其中所述注册语音信号的时长大于一预设阈值;提取所述注册语音信号中每一帧所对应的帧声纹特征;计算各所述帧声纹特征的后验概率;基于所述后验概率对各所述帧声纹特征进行分类,并记录每种分类的类型标识。
在一实施中,所述采集已知用户输入的注册语音信号,包括:采集所述已知用户朗读一预设文本所产生的所述注册语音信号。
在一实施中,所述预设阈值为30秒。
在一实施中,所述计算各所述帧声纹特征的后验概率包含:分别以各所述帧声纹特征作为输入样本,基于tdnn-ubm模型得到所述注册语音信号中每一帧所对应的后验概率。
在一实施中,所述基于所述后验概率对各所述帧声纹特征进行分类,包含:计算各所述后验概率的热独值;将相同热独值所对应的所述帧声纹特征归为同一分类。
在一实施中,所述待识别语音信号为短文本无关的语音信号。
在一实施中,所述计算所述待识别语音信号的各所述帧声纹特征的后验概率包含:分别以各所述帧声纹特征作为输入样本,基于tdnn-ubm模型得到所述识别语音信号中每一帧所对应的后验概率。
在一实施中,所述基于所述后验概率对各所述帧声纹特征进行分类,包含:计算各所述后验概率的热独值;将相同热独值所对应的所述帧声纹特征归为同一分类。
基于本发明实施例所提供的声纹识别方法可先基于后验概率来对待识别语音信号进行分类,并基于类型标识确定是否有包含相同分类的已知用户的注册语音信号,来初步确认待识别语音信号的有效性,当确定包含相同分类后,在基于相同分类所包含的帧特征向量分别训练生成待识别模型与声纹识别模型,并基于两个模型的相似度来确定未知用户的身份,不仅可实现快速过滤无效信号,而且可提升识别准确率。
基于同样的发明构思,本发明还提供一种声纹识别装置,所述装置包含一输入模块、一声纹识别模块,及一输出模块;其中,所述输入模块接收未知用户输入的待识别语音信号,并发送给所述声纹识别模块,所述声纹识别模块基于上述的声纹识别方法对所述未知用户的身份进行确认,并发送识别结果至所述输出模块;所述输出模块对所述识别结果进行输出。
附图说明
一个或多个实施方式通过与之对应的附图中的图片进行示例性说明,这些示例性说明并不构成对实施方式的限定,附图中具有相同参考数字标号的元件表示为类似的元件,除非有特别申明,附图中的图不构成比例限制。
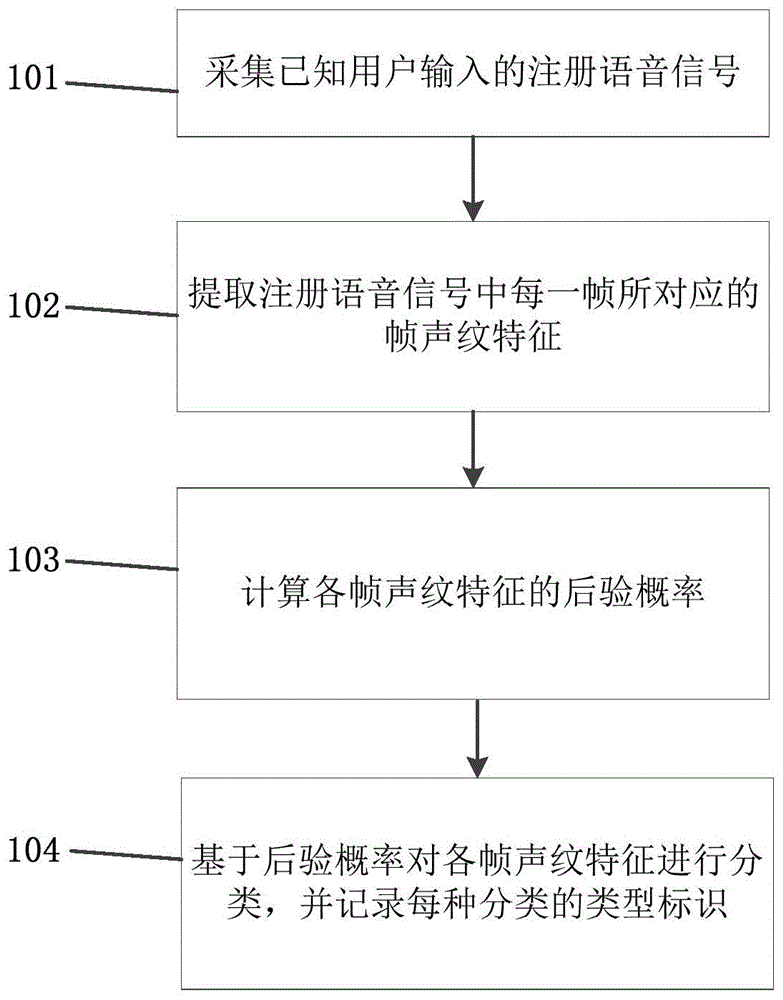
图1绘示本发明第一实施例所提供的声纹识别方法中已知用户的注册语音信号的分类方法的流程图;
图2绘示本发明第一实施例所提供的声纹识别方法流程图;
图3绘示本发明第二实施例所提供的声纹识别装置结构示意图。
具体实施方式
为使本发明实施方式的目的、技术方案和优点更加清楚,下面将结合附图对本发明的各实施方式进行详细的阐述。然而,本领域的普通技术人员可以理解,在本发明各实施方式中,为了使读者更好地理解本申请而提出了许多技术细节。但是,即使没有这些技术细节和基于以下各实施方式的种种变化和修改,也可以实现本申请所要求保护的技术方案。
本发明所提供的第一实施例为一种声纹识别方法,可基于运行在计算机电子设备上的程序模块来实现,通过对待识别语音信号进行分类,并基于相同分类中所包含的帧声纹特征训练生成待识别模型,与对应生成的声纹识别模型进行相似度的比较,以确定待识别语音信号的身份信息,可有效提升声纹识别的准确性。
在本实施例所提供的声纹识别方法中,需预先收集已知用户的注册语音信号,并对其进行分类处理,以供后续识别过程中进行使用,故在对具体的识别过程进行说明之前,本说明书将先对已知用户的注册语音信号的分类方法进行说明,具体请参照图1。
图1绘示本发明第一实施例所提供的声纹识别方法中已知用户的注册语音信号的分类方法。如图1所示,所述分类方法具体包含步骤:
步骤101,采集已知用户输入的注册语音信号。
具体而言,在构建声纹识别模型之前,需预先收集样本数据,其中样本数据具体可包含已知用户朗读预设文本所产生的语音信息,其中预设文本可以是预先根据需求而设定的,可以包含字母、数字等,该文本中应尽可能的包含全部音素,以尽量保证样本的完整性,该语音信号可称为注册语音信号,更进一步的,注册语音信号的时长应大于一预设阈值,较佳的,预设阈值可为30s。
步骤102,提取注册语音信号中每一帧所对应的帧声纹特征。
在本实施例中,声纹特征可以为梅尔频率倒谱系数(melfrequencycepstrumcoefficient,mfcc)。具体而言,提取注册语音信号中每一帧所对应的帧声纹特征,可基于以下两种方式实现:
第一种,可直接提取注册语音信号的特征参数mfcc,由于mfcc在提取过程中会自动进行分帧,并处理得到每一帧对应的mfcc,从而获得注册语音信号中每一帧所对应的帧声纹特征。
第二种,可先对注册语音信号以帧为单位进行切片,并分别提取各切片的mfcc特征,从而得到每一帧对应的mfcc,即帧声纹特征。
值得注意的是,在对注册语音信号进行帧声纹特征提取之前,可先对注册语音信号进行降噪处理,先剔除其中的无效音频片段,如静音片段和噪声片段,从而提升样本的有效性。
步骤103,计算各帧声纹特征的后验概率。
在本实施例中,可利用tdnn-ubm模型来计算后验概率。具体过程可包含:
分别以各帧声纹特征作为输入样本,基于tdnn-ubm模型得到所述注册语音信号中每一帧所对应的后验概率(timedelayneuralnetwork,tdnn)。其中tdnn-ubm模型是指使用时延神经网络(timedelayneuralnetwork,tdnn)来实现的通用背景模型(universalbackgroundmode,ubm)。
步骤104,基于后验概率对各帧声纹特征进行分类,并记录每种分类的类型标识。
在经过步骤103获得各帧声纹特征对应的后验概率之后,基于该后验概率对各帧声纹特征进行分类。具体而言,可先计算各后验概率的热独值(one-hot),再将相同热独值所对应的帧声纹特征归为同一分类,并可记录该热独值为对应分类的类型标识。
通过上述方法,可对采集到的已知用户的注册语音信号进行分类,并记录对应的类型标识,以供后续声纹识别过程中进行查找和匹配。
在本实施例中,通过借助tdnn-ubm模型,获取每一帧片段所对应的后验概率,并基于后验概率对帧片段进行分类,从而完成对注册语音数据的收敛,有利于提取出注册语音信号中的关键特征;然后将类型相同的帧片段归为同类,以获得更明确的识别特征,可为后续的识别过程提供更全面的识别验证,以提升识别准确性。
更进一步的,在基于后验概率对帧声纹特征进行分类时,可通过计算后验概率的热独值来生成分类标准,从而提升分类的精准度。
由于本实施例在对注册语音信号的处理时,是以帧为单位来进行分类的,那么在后续的识别过程中,也可以基于帧片段来对文本无关语音信号进行识别,不仅细化了识别粒度,可对识别结果有更精准的呈现,并且可更适用于短语音信号的识别中。
上述对已知用户的注册语音信号的分类处理可在识别应用前预先完成,并保存相关数据,以供后续识别过程中的快速查验。值得注意的是,在实际应用过程中,可根据具体的需求,逐步增加已知用户的注册语音信号,并进行相应的分类处理。
下面将对本发明第一实施例所提供的声纹识别方法进行详细介绍。
请参照图2,图2绘示本发明第一实施例所提供的声纹识别方法流程图。
如图2所示,所述声纹识别方法具体可包含以下步骤:
步骤201,接收未知用户输入的待识别语音信号。
其中,未知用户输入的待识别语音信号可以为文本无关语音信号,更进一步的,待识别语音信号可为短文本无关的语音信号,所谓短文本无关的语音信号可包含有效信号时长在2s左右的文本无关语音信号,具体的时长范围为1s至3s之间,也就是说,本实施例所提供的声纹识别方法可应用于有效时长为1s至3s之间的文本无关语音信号的识别,且可保证有较高的准确性。
步骤202,提取待识别语音信号中每一帧所对应的帧声纹特征。
在本实施例中,声纹特征可以为梅尔频率倒谱系数(melfrequencycepstrumcoefficient,mfcc)。具体而言,提取待识别语音信号中每一帧所对应的帧声纹特征,可基于以下两种方式实现:
第一种,可直接提取待识别语音信号的特征参数mfcc,由于mfcc在提取过程中会自动进行分帧,并处理得到每一帧对应的mfcc,从而获得待识别语音信号中每一帧所对应的帧声纹特征。
第二种,可先对待识别语音信号以帧为单位进行切片,并分别提取各切片的mfcc特征,从而得到每一帧对应的mfcc,即帧声纹特征。
值得注意的是,在对待识别语音信号进行帧声纹特征提取之前,可先对待识别语音信号进行降噪处理,先剔除其中的无效音频片段,如静音片段和噪声片段,从而提升数据的有效性。
步骤203,计算各帧声纹特征的后验概率。
在本实施例中,可利用tdnn-ubm模型来计算后验概率。具体过程可包含:
分别以各帧声纹特征作为输入样本,基于tdnn-ubm模型得到识别语音信号中每一帧所对应的后验概率(timedelayneuralnetwork,tdnn)。其中tdnn-ubm模型是指使用时延神经网络(timedelayneuralnetwork,tdnn)来实现的通用背景模型(universalbackgroundmode,ubm)。
步骤204,基于后验概率对各帧声纹特征进行分类,并确定每种分类的类型标识。
在经过步骤203获得各帧声纹特征对应的后验概率之后,基于该后验概率对各帧声纹特征进行分类。具体而言,可先计算各后验概率的热独值(one-hot),再将相同热独值所对应的帧声纹特征归为同一分类,并可记录该热独值为对应分类的类型标识。
值得注意的是,本说明书的实施例中,类型标识可直接采用分类所对应的热独值来表示,在本发明的其他实施例中,类型标识也可以采用其他表示方式,只需满足不同分类可有效区分即可,并且,在上述已知用户的注册语音信号的分类方法和声纹识别方法中,类型标识的表示方式应相同。
步骤205,基于类型标识确定已知用户对应的注册语音信号中是否包含相同的分类。
具体而言,本步骤中提及的已知用户对应的注册语音信号已预先基于图1所示实施例所提供的已知用户的注册语音信号的分类方法进行分类,故可基于相关记录中查找待识别语音信号中所包含的分类,是否也同样包含在已知用户的注册语音信号中。
在本步骤中,可基于不同的应用需求,来设置不同的处理方法,具体的应用需求可包含以下两种:
第一种,是已获得未知用户的预设身份,再基于语音信号进行身份验证,例如,用户已经通过账号登陆了应用系统,系统已确定了登陆账号所对应的预设身份,当用户想要进行限制访问时,需再次对用户身份进行安全性验证,已确定用户的真实身份与预设身份一致。
在这种应用场景下,可基于用户的预设身份,从本地数据库中查找出与该预设身份对应的已知用户的验证信息,该验证信息可具体包含各分类所对应的类型标识。在获取到已知用户所对应的类型标识之后,再分别与待识别语音信号所对应的类型标识进行匹配,确定是否有相同的类型标识存在,若存在,表示已知用户对应的注册语音信号中包含相同的分类。
第二中,是未获得未知用户的预设身份,而直接进行语音信号的身份验证,例如,未知用户通过语音信号来控制门禁的运行。
在这种应用场景下,可直接基于待识别语音信号对应的类型标识来查找已保存的所有已知用户注册语音信号对应的类型标识。由于在这种应用场景下,可能会出现查找到多个已知用户的注册语音信号对应的类型标识中,包含有至少一个待识别语音信号对应的类型标识。
基于上述方法,根据不同应用场景,都可确定出已知用户对应的注册语音信号中是否包含相同的分类,以及具体包含了哪些相同分类。若确定包含了相同的分类,则可执行步骤206;若不包含,则无法对待识别语音进行识别,可提示错误信息,并终止流程。
步骤206,基于待识别语音信号的各相同分类中所包含的帧声纹特征,训练生成待识别模型,并基于注册语音信号的各相同分类中所包含的帧声纹特征,训练生成声纹识别模型。
举例而言,注册语音信号中含有类别a,b,c,d;待识别语音信号中含有类别a,c,e。则可将待识别语音信号的a,c类型中所包含的帧声纹特征取出,训练生成待识别模型v;并将注册语音信号中的a,c类别中包含的帧声纹特征取出,并训练生成声纹识别模型t。
具体而言,可以分别将待识别语音信号中各相同分类所包含的帧声纹特征、以及注册语音信号中各相同分类所包含的帧声纹特征作为输入层,基于plda(probabilisticlineardiscriminantanalysis)算法分别训练生成待识别模型和声纹识别模型。
步骤207,基于待识别模型与声纹识别模型的相似度确定未知用户是否为已知用户。
在获取待识别模型与声纹识别模型后,可进行两个模型的相似度计算,从而确定出未知用户的身份信息。
具体而言,在不同的应用场景下,用户身份信息的确认方式也不相同。
在步骤205中所提及的第一种应用场景下,可计算直接待识别模型与声纹识别模型的相似度来判断预设身份是否与已知用户一致。例如,可通过判断相似度是否超过预设阈值来确定,若至少一个分类所对应的相似度大于阈值,那么可断定未知用户为已知用户。其中,阈值的设定,可基于实际情况来设定和调整,本发明并不作限制。
在在步骤205中所提及的第二种应用场景下,与第一种场景不同的是,可能会有两个或以上的已知用户被识别出,即该些已知用户的注册语音信号中都有包含与待识别语音信号相同的分类。
在这一情况下,可通过设定判定规则来确定出未知用户的身份。例如,可分别计算各个待识别模型与声纹识别模型相似度,然后选取相似度大于预设阈值,且相似度最高的值所对应的已知用户确定为未知用户。具体的判定规则,可根据实际需求进行调整,本发明不作任何限制。
在本实施例中,可先基于后验概率来对待识别语音信号进行分类,并基于类型标识确定是否有包含相同分类的已知用户的注册语音信号,来初步确认待识别语音信号的有效性,当确定包含相同分类后,在基于相同分类所包含的帧特征向量分别训练生成待识别模型与声纹识别模型,并基于两个模型的相似度来确定未知用户的身份,不仅可实现快速过滤无效信号,而且可提升识别准确率。
基于同样的发明构思,本发明还提供了一种声纹识别装置。请参照图3,图3绘示本发明第二实施例所提供的声纹识别装置结构示意图。
如图3所示,声纹识别装置300包含输入模块310、声纹识别模块320,及输出模块330。其中声纹识别模块320分别与其他两个模块都有建立通信连接。
输入模块310具体可包含麦克风等音频信号接收器。
输出模块330具体可包含音箱、显示屏等设备中的一种或多种。
声纹识别模块320可基于运行对应的程序指令来实现对应的功能。
具体而言,在对已知用户的注册语音信号的采集阶段,输入模块310可接收已知用户输入的注册语音信号,并发送给声纹识别模块320,声纹识别模块320基于图1所示实施例所提供的已知用户的注册语音信号的分类方法对所述注册语音信信号进行分类处理,并获得对应的类型标识。
在声纹识别阶段,输入模块310接收未知用户输入的待识别语音信号,并发送给声纹识别模块320,声纹识别模块320基于图2所示实施例所提供的声纹识别方法对所述未知用户的身份进行确认,并发送识别结果至输出模块330,输出模块330对所述识别结果进行输出。
本发明实施例所提供的声纹识别装置结构简单,识别准确率高,可对短文本无关语音信号进本发明又一实施例涉及一种计算机可读存储介质,存储有计算机程序。计算机程序被处理器执行时,实现上述方法实施例。
本领域技术人员可以理解,实现上述实施例方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序存储在一个存储介质中,包括若干指令用以使得一个设备(可以是单片机,芯片等)或处理器(processor)执行本申请各个实施例方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read-onlymemory)、随机存取存储器(ram,randomaccessmemory)、磁碟或者光盘等各种可以存储程序代码的介质。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!