基于注意力门控的循环神经网络的单通道语音增强方法与流程
本发明涉及语音增强技术领域,具体涉及一种基于注意力门控的循环神经网络的单通道语音增强方法。
背景技术:
语音增强作为语音信号处理的一个分支,在语音通信、助听设备、自动语音识别(asr)系统前端等领域具有重要的应用。语音增强一般分为单通道语音增强和多通道语音增强。单通道语音增强由于不存在麦克风阵列的空间信息,实现起来相对更加困难。
早期提出的一些无监督的单通道语音增强算法,比如谱减法、维纳滤波法、基于最小均方误差(mmse)的幅度谱估计或对数域的谱估计方法,由于噪声平稳性的假设,无法有效抑制非平稳噪声。随后,基于隐马尔可夫模型(hmm)、非负矩阵分解(nmf)和深度学习的有监督的单通道语音增强算法被提出,其中深度学习的应用使语音增强领域取得了突破性的进展。神经网络凭借强大的拟合能力,能够从带噪语音的特征中学习纯净目标语音的表示,而不需要噪声平稳性的假设。
但是,目前提出的语音增强方法一般对非平稳噪声的抑制效果欠佳,而且,基于深度学习的语音增强方法往往由于其高计算复杂度而无法应用于实时语音增强中,如何解决以上问题,是当前亟需解决的。
技术实现要素:
本发明的目的是解决现有语音增强方法对非平稳噪声的抑制效果欠佳,以及基于深度学习的语音增强方法由于高计算复杂度而无法满足实时要求的问题。本发明的基于注意力门控的循环神经网络的单通道语音增强方法,能够有效抑制包括非平稳噪声在内的噪声,同时保持足够低的计算复杂度,从而能够用于实时的单通道语音增强,方法巧妙,构思新颖,具有良好的应用前景。
为了达到上述目的,本发明所采用的技术方案是:
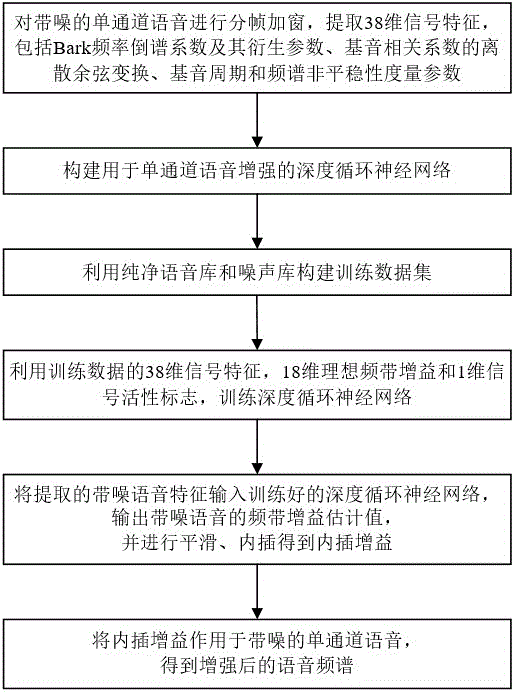
一种基于注意力门控的循环神经网络的单通道语音增强方法,包括以下步骤,
步骤(a),对带噪的单通道语音进行分帧加窗,提取38维信号特征,包括bark频率倒谱系数及其衍生参数、基音相关系数的离散余弦变换、基音周期和频谱非平稳性度量参数;
步骤(b),构建用于单通道语音增强的深度循环神经网络;
步骤(c),利用纯净语音库和噪声库构建训练数据集;
步骤(d),利用训练数据的38维信号特征,18维理想频带增益和1维信号活性标志,训练步骤(b)构建的深度循环神经网络;
步骤(e),将提取的带噪语音特征输入训练好的深度循环神经网络,输出带噪语音的频带增益估计值,并进行平滑、内插得到内插增益;
步骤(f),将内插增益作用于带噪的单通道语音,得到增强后的语音频谱。
前述的基于注意力门控的循环神经网络的单通道语音增强方法,步骤(a),提取38维信号特征,具体包括18个bark频率倒谱系数,前6个bark频率倒谱系数的一阶时间导数和二阶时间导数,前6个频带间基音相关系数的离散余弦变换,1个基音周期系数以及1个频谱非平稳性度量参数。
前述的基于注意力门控的循环神经网络的单通道语音增强方法,步骤(b),构建用于单通道语音增强的深度循环神经网络,该深度循环神经网络包含六层,第一层为dense层,激活函数为tanh,单元数为24;第二到五层为注意力门控lstm层,激活函数为tanh,单元数分别为24,48,48和96;第六层为dense层,激活函数为sigmoid,单元数为18。该网络的第二层输出通过一层的dense层,得到1维信号活性标志。
前述的基于注意力门控的循环神经网络的单通道语音增强方法,所述深度循环神经网络的前向传播过程如公式(1)至公式(5)所示:
at=σ[vatanh(wact-1)](1)
ot=σ(wo·[ht-1,xt]+bo)(2)
其中,t为帧序号;a,o,c,h分别为注意力门、输出门、细胞状态矢量和隐藏矢量,
前述的基于注意力门控的循环神经网络的单通道语音增强方法,步骤(c),利用纯净语音库和噪声库构建训练数据集,具体是将每个样本通过双二阶滤波器,以改变混合信号的幅度,所述双二阶滤波器h(z)的形式如公式(6)所示:
其中,r1...r4是在[-3/8,3/8]范围内均匀分布的随机值。
前述的基于注意力门控的循环神经网络的单通道语音增强方法,步骤(d),训练步骤(b)构建的深度循环神经网络,包括以下步骤。
(d1),计算频带b的频带增益gb,如公式(7)所示,
其中,es(b)和ex(b)分别为纯净语音和带噪语音在频带b的能量,gb的值在[0,1]之间;
(d2),将提取的38维信号特征作为所述深度循环神经网络的输入;
(d3),将18维理想频带增益和1维信号活性标志作为所述循环神经网络的训练目标,损失函数l如公式(8)所示:
l=lg+αlvad(8)
其中,lg为频带增益估计值对应的损失函数,lvad为vad估计值对应的损失函数,α为加权系数。其中,频带增益估计值对应的损失函数lg如公式(9)所示:
其中,
(d4),训练时,每训练完一个批次,对所有参数作截断处理,使其范围在[-0.5,0.5]之间。
前述的基于注意力门控的循环神经网络的单通道语音增强方法,步骤(e),对网络输出的频带增益估计值进行平滑、内插,得到内插增益,具体过程如下,
平滑后的频带增益
其中,
其中,wb(k)为频带b在频点k的幅度。
前述的基于注意力门控的循环神经网络的单通道语音增强方法,步骤(f),将内插增益作用于带噪的单通道语音,得到增强后的语音频谱
其中,αb为滤波系数,p(k)为基音延迟信号x(n-t)的频谱,x(k)为带噪的单通道语音的频谱。
本发明的有益效果是:本发明的基于注意力门控的循环神经网络的单通道语音增强方法,通过在传统lstm模型中使用注意力,使单元专注于当前输入的上下文信息中对输出有用的信息,从而提高网络的学习能力。使用深度循环神经网络从带噪特征中估计频带增益,而不需要任何假设,通过在训练集中包含多种噪声条件可以提高网络的泛化能力。此外,循环神经网络只需输出18个在0~1之间的频带增益估计值和1个vad估计值,大大降低了计算复杂度。本发明的单通道语音增强方法能够有效抑制包括非平稳噪声在内的噪声,通过频带划分避免噪声抑制中常见的音乐噪声问题,同时保持足够低的计算复杂度,从而能够用于实时的单通道语音增强,方法巧妙,构思新颖,具有良好的应用前景。
附图说明
图1是本发明的基于注意力门控的循环神经网络的单通道语音增强方法的流程图;
图2是本发明的深度循环神经网络的框架示意图。
具体实施方式
下面将结合说明书附图,对本发明作进一步的说明。
如图1所示,本发明的基于注意力门控的循环神经网络的单通道语音增强方法,包括以下步骤。
步骤(a),对带噪的单通道语音进行分帧加窗,提取38维信号特征,包括bark频率倒谱系数及其衍生参数、基音相关系数的离散余弦变换、基音周期和频谱非平稳性度量参数,具体包括18个bark频率倒谱系数,前6个bark频率倒谱系数的一阶时间导数和二阶时间导数,前6个频带间基音相关系数的离散余弦变换,1个基音周期系数以及1个频谱非平稳性度量参数;
步骤(b),构建用于单通道语音增强的深度循环神经网络,该深度循环神经网络包含六层,如图2所示,第一层为dense层,激活函数为tanh,单元数为24;第二到五层为注意力门控lstm层,激活函数为tanh,单元数分别为24,48,48和96;第六层为dense层,激活函数为sigmoid,单元数为18;第二层输出通过一层的dense层(激活函数为sigmoid,单元数为1),得到1维信号活性标志。该深度循环神经网络的前向传播过程如公式(1)至公式(5)所示:
at=σ[vatanh(wact-1)](1)
ot=σ(wo·[ht-1,xt]+bo)(2)
其中,t为帧序号;a,o,c,h分别为注意力门、输出门、细胞状态矢量和隐藏矢量,
步骤(c),利用纯净语音库和噪声库构建训练数据集,具体是将每个样本通过双二阶滤波器,以改变混合信号的幅度,所述双二阶滤波器h(z)的形式如公式(6)所示:
其中,r1...r4是在[-3/8,3/8]范围内均匀分布的随机值吗,z为z变换的符号;
步骤(d),利用训练数据的38维信号特征,18维理想频带增益(即为18个bark频带的增益)和1维信号活性标志,训练步骤(b)构建的深度循环神经网络,包括以下步骤。
(d1),计算频带b的频带增益gb,如公式(7)所示,
其中,es(b)和ex(b)分别为纯净语音和带噪语音在频带b的能量,gb的值在[0,1]之间;
(d2),将提取的38维信号特征作为所述深度循环神经网络的输入;
(d3),将18维理想频带增益和1维信号活性标志作为所述循环神经网络的训练目标,损失函数l如公式(8)所示:
l=lg+αlvad(8)
其中,lg为频带增益估计值对应的损失函数,lvad为vad估计值对应的损失函数,α为加权系数。其中,频带增益估计值对应的损失函数lg如公式(9)所示:
其中,
(d4),训练时,每训练完一个批次,对所有参数作截断处理,使其范围在[-0.5,0.5]之间。
步骤(e),将提取的带噪语音特征输入训练好的深度循环神经网络,输出带噪语音的频带增益估计值,并进行平滑、内插得到内插增益,具体过程如下。
平滑后的频带增益
其中,
其中,wb(k)为频带b在频点k的幅度。
步骤(f),将内插增益作用于带噪的单通道语音,得到增强后的语音频谱,增强后的语音频谱
其中,αb为滤波系数,p(k)为基音延迟信号x(n-t)的频谱,x(k)为带噪的单通道语音的频谱。
在不同含噪语音下,算法的增强效果如表1所示,用于构建测试集的纯净语音来自普通话水平测试配套光盘中的朗读作品集,从中选择4个段落,将其截成15s的语音段,得到45个纯净样本,与录制的噪声以6种信噪比(包括-5db,0db,5db,10db,15db,20db)混合,共生成270个带噪样本。用于衡量增强性能的指标包括pesq(perceptualevaluationofspeechquality,主观语音质量评估),fwsegsnr(frequency-weightedsegmentalsnr,频率加权分段信噪比)和stoi(short-timeobjectiveintelligibility,短时客观可懂度)。由表1中的结果可以看出,本发明的单通道语音增强方法在所有信噪比条件下均显著地提升了pesq和fwsegsnr,对stoi也有一定改善效果,平均pesq,fwsegsnr和stoi分别提升了0.51,2.29db和0.018,实现了较强的语音增强性能。
表1本发明的单通道语音增强方法的增强性能测试结果
综上所述,本发明的基于注意力门控的循环神经网络的单通道语音增强方法,通过在传统lstm模型中使用注意力,使单元专注于当前输入的上下文信息中对输出有用的信息,从而提高网络的学习能力。使用深度循环神经网络从带噪特征中估计频带增益,而不需要任何假设,通过在训练集中包含多种噪声条件可以提高网络的泛化能力。此外,循环神经网络只需输出18个在0~1之间的频带增益估计值和1个vad估计值,大大降低了计算复杂度。本发明的单通道语音增强方法能够有效抑制包括非平稳噪声在内的噪声,通过频带划分避免噪声抑制中常见的音乐噪声问题,同时保持足够低的计算复杂度,从而能够用于实时的单通道语音增强,方法巧妙,构思新颖,具有良好的应用前景。
以上显示和描述了本发明的基本原理、主要特征及优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!