基于多粒度动静态融合特征的语音情感识别方法、装置、系统及存储介质与流程
本发明涉及语音处理技术领域,尤其涉及一种基于多粒度动静态融合特征的语音情感识别方法、装置、系统及存储介质。
背景技术:
传统的方法是先对语音提取以帧为单位的声学特征,然后将整段语音的所有帧特征进行统计分析,得到最终特征。采用支持向量机(supportvectormachine,svm)、感知器等作为分类器。
传统的特征提取方法,提取的特征是针对整段语音的全局静态特征,无法体现说话人说话期间的语音情感动态变化特性。在分类器的选择上也没有针对语音的动态变化信息进行设计或者优化。
技术实现要素:
本发明提供了一种基于多粒度动静态融合特征的语音情感识别方法,包括如下步骤:第一步,帧计算步骤:以帧为单位计算出每一帧的韵律学特征、谱相关特征及声音质量特征;第二步,段粒度特征的提取步骤:通过统计计算得到整句语料的大粒度静态全局特征,同时利用高斯窗对在时序上相邻的帧特征进行卷积,得到多粒度时变动态特征,使得多粒度时变动态特征既能刻画说话人的总体语音特征,又能描述语音情感特征随时间的变化。
本发明还提供了一种基于多粒度动静态融合特征的语音情感识别装置,包括:帧计算模块:用于以帧为单位计算出每一帧的韵律学特征、谱相关特征及声音质量特征;帧计算模块:用于以帧为单位计算出每一帧的韵律学特征、谱相关特征及声音质量特征;
本发明还提供了一种基于多粒度动静态融合特征的语音情感识别系统,包括:存储器、处理器以及存储在所述存储器上的计算机程序,所述计算机程序配置为由所述处理器调用时实现本发明所述的方法的步骤。
本发明还提供了一种计算机可读存储介质,其特征在于:所述计算机可读存储介质存储有计算机程序,所述计算机程序配置为由处理器调用时实现本发明所述的方法的步骤。
本发明的有益效果是:本发明根据人脑对于语音情感识别中表现的时间段上的认知规律,提出多粒度动静态特征融合情感语音分析技术,对语音从三个不同的粒度进行特征的提取,从而得到多粒度时变动态特恒,使得特征既能刻画说话人的总体语音特征,又能描述语音情感特征随时间的变化,让提取的特征更加有效。
附图说明
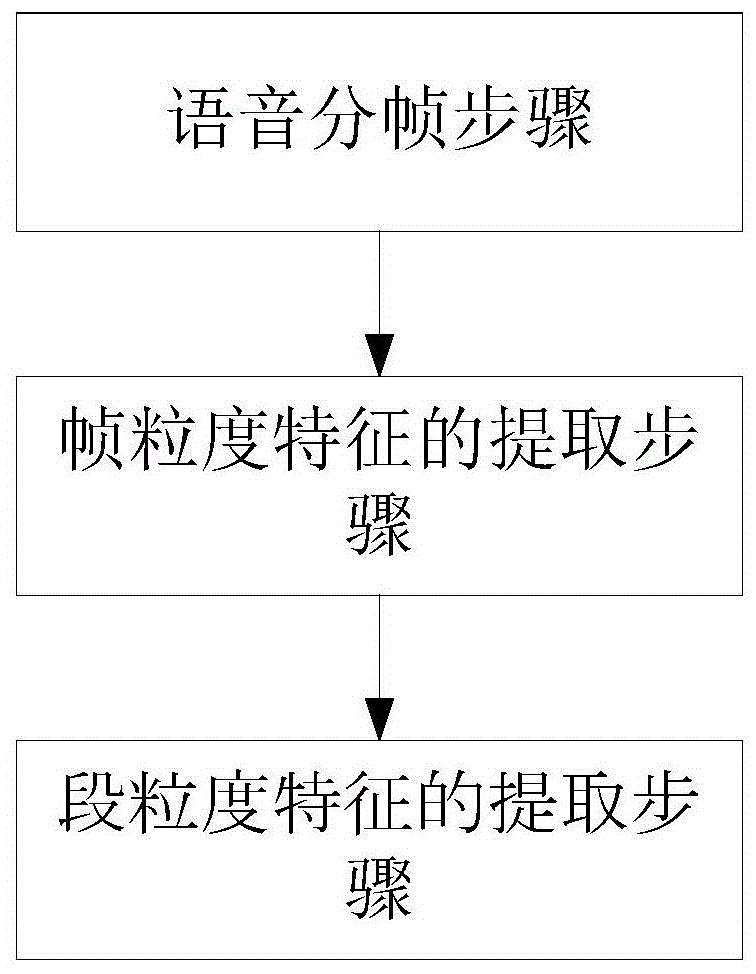
图1是本发明的方法流程图。
具体实施方式
本发明公开了一种基于多粒度动静态融合特征的语音情感识别方法,采用多粒度动静态特征融合的分析技术,首先以帧为单位计算出每一帧的声音韵律学特征、谱特征及声音质量特征等,然后通过统计计算得到整句语料的大粒度静态全局特征。同时我们利用高斯窗对在时序上相邻的帧特征进行卷积,得到多粒度时变动态特征,使得特征既能刻画说话人的总体语音特征,又能描述语音情感特征随时间的变化。
该基于多粒度动静态融合特征的语音情感识别方法,包括如下步骤:
第一步,帧计算步骤:以帧为单位计算出每一帧的韵律学特征、谱相关特征及声音质量特征;
第二步,段粒度特征的提取步骤:通过统计计算得到整句语料的大粒度静态全局特征,同时利用高斯窗对在时序上相邻的帧特征进行卷积,得到多粒度时变动态特征,使得多粒度时变动态特征既能刻画说话人的总体语音特征,又能描述语音情感特征随时间的变化。
在所述第一步,帧计算步骤中,包括如下步骤:
第1步,语音分帧步骤:以汉明窗作为窗函数,设定帧长为25ms,帧移为10ms,对连续的待识别语音片段进行分帧,作为特征提取中的最小处理粒度;
第2步,帧粒度特征的提取步骤:对语音分帧步骤中划分的每一个帧,提取65维声学特征,包括基频、短时能量、短时平均能量、过零率、平均振幅差、共振峰、mfcc等,如下表所示;
这里,用xt=(a(t,1),a(t,2),…,a(t,65))来表示第t个帧特征矢量,其中65为帧特征矢量的维数,于是对于每个包含t个帧的时序信号便可以得到帧特征矩阵
在第二步,段粒度特征的提取步骤中,对于得到的每个大小为65×t的帧特征矩阵,我们利用预先依据人脑听觉机理设定好的段长l=300ms,和相应的卷积函数组g(m,t)进行卷积,其中m为卷积函数组中卷积函数的个数,并由下式计算得出最后的段特征矩阵sm×t,
s(m,t)=g(m,t)*(xt-l+1,xt-l+2,…,xt)t
(xt-l+1,xt-l+2,…,xt)t为段长为l的卷积窗内所覆盖的以xt为结尾的帧特征矩阵。g(m,t)为卷积函数组g(m,t)中第m个高斯函数,可按下式进行计算,其中td为相邻两个卷积窗之间的时延,在这里等同于一个帧的长度。
其中,σm由下式进行计算,这里我们事先定义
本发明还公开了一种基于多粒度动静态融合特征的语音情感识别装置,包括:
帧计算模块:用于以帧为单位计算出每一帧的韵律学特征、谱相关特征及声音质量特征;
段粒度特征的提取模块:用于通过统计计算得到整句语料的大粒度静态全局特征,同时利用高斯窗对在时序上相邻的帧特征进行卷积,得到多粒度时变动态特征,使得多粒度时变动态特征既能刻画说话人的总体语音特征,又能描述语音情感特征随时间的变化。
在所述帧计算模块中,包括:
语音分帧模块:用于以汉明窗作为窗函数,按照设置的帧长和帧移,对连续的待识别语音片段进行分帧,作为特征提取中的最小处理粒度;
帧粒度特征的提取模块:用于对语音分帧模块中划分的每一个帧,提取设定维数的声学特征,对于每个包含t个帧的时序信号便可以得到帧特征矩阵。
在所述段粒度特征的提取模块中,对于得到的的帧特征矩阵,利用预先依据人脑听觉机理设定好的段长,和相应的卷积函数组g(m,t)进行卷积,其中m为卷积函数组中卷积函数的个数,并由下式计算得出最后的段特征矩阵sm×t,s(m,t)=g(m,t)*(xt-l+1,xt-l+2,…,xt)t,g(m,t)为卷积函数组g(m,t)中第m个高斯函数。
在语音分帧模块中,以汉明窗作为窗函数,设定帧长为25ms,帧移为10ms,对连续的待识别语音片段进行分帧,作为特征提取中的最小处理粒度。
在帧粒度特征的提取模块中,对语音分帧模块中划分的每一个帧,提取65维声学特征,65维声学特征包括:平滑的基频、维度1,浊音概率、维度1,过零率、维度1,mfcc、维度14,均方能量、维度1,声谱滤波、维度28,频谱能量、维度15,局部频率抖动、维度1,帧间频率抖动、维度1,局部振幅微扰、维度1,谐噪比、维度1;用xt=(a(t,1),a(t,2),…,a(t,65))来表示第t个帧特征矢量,其中65为帧特征矢量的维数,于是对于每个包含t个帧的时序信号便可以得到帧特征矩阵
在所述段粒度特征的提取模块中,对于得到的每个大小为65×t的帧特征矩阵,利用预先依据人脑听觉机理设定好的段长l=300ms,和相应的卷积函数组g(m,t)进行卷积,其中m为卷积函数组中卷积函数的个数,并由下式计算得出最后的段特征矩阵sm×t,s(m,t)=g(m,t)*(xt-l+1,xt-l22,…,xt)t,g(m,t)为卷积函数组g(m,t)中第m个高斯函数,可按下式进行计算,
本发明还公开了一种基于多粒度动静态融合特征的语音情感识别系统,包括:存储器、处理器以及存储在所述存储器上的计算机程序,所述计算机程序配置为由所述处理器调用时实现本发明所述的方法的步骤。
本发明还公开了一种计算机可读存储介质,其特征在于:所述计算机可读存储介质存储有计算机程序,所述计算机程序配置为由处理器调用时实现本发明所述的方法的步骤。
本发明提出一种基于听觉认知规律的语音情感特征提取分析方法,并基于此构建出语音情感识别方法,涉及利用此方法来解决语音情感识别问题,包括但不限于在计算机、机器终端运行的包含语音情感识别的人工智能技术。
本发明根据人脑对于语音情感识别中表现的时间段上的认知规律,提出多粒度动静态特征融合情感语音分析技术,对语音从三个不同的粒度进行特征的提取,从而得到多粒度时变动态特恒,使得特征既能刻画说话人的总体语音特征,又能描述语音情感特征随时间的变化,让提取的特征更加有效。
在识别算法上,采用长短时记忆(longshortterm-memory,lstm)网络模型。lstm模型可以有效的对时间序列进行建模,充分利用特征中的时序信息。另一方面,lstm的长短时记忆机制可以让网络对不同时刻的特征进行有选择性的记忆和识别,具有特征融合机制。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!