基于多示例学习的自动语音识别困难样本挖掘方法与流程
本发明涉及自动语音识别困难样本挖掘方法,属于语音信号处理技术领域。
背景技术:
自动语音识别技术(automaticspeechrecognition,asr)发展至今,已经有五、六十年的历史,目标是将人类的语音内容转换为计算机可读的输入,它伴随着计算机科学和通信等学科的发展逐步成长。虽然自动语音识别技术已经获得了很大的进展,但识别结果的正确性仍然有待提高。
目前大多数语音识别系统都是数据驱动的,即要通过输入大量的数据来训练系统,并且在面对新的领域时,要将新领域数据输入到已有的模型中对其进行重训练,使系统能够同时胜任新旧领域。然而对于新领域数据集,通常是未标注的,若将其全部进行人工标注费时费力;目前已有的语音识别系统重训练方式不能很好的解决这个问题。
技术实现要素:
本发明为解决现有自动语音识别技术需要人工标注大量数据集的问题,提供了基于多示例学习的自动语音识别困难样本挖掘方法。
本发明所述基于多示例学习的自动语音识别困难样本挖掘方法,通过以下技术方案实现:
步骤一、收集语料数据建立数据集
步骤二、选取训练数据:
将数据集
步骤三、对训练集进行人工标注,得到标注好的训练集
步骤四、使用标注好的训练集建立困难样本检测模型,并对其进行训练;
步骤五、无标注困难样本挖掘:
使用步骤四中训练好的困难样本检测模型在剩余集合
步骤六、困难样本筛选与标注:
对步骤五中检测到的候选困难样本进行人工确认,同时将人工确认后的困难样本进行标注。
作为对上述技术方案的进一步阐述:
进一步的,步骤四中所述建立困难样本检测模型,并对其进行训练具体为:
建立困难样本检测模型:
其中,xi是标注好的训练集
对困难样本检测模型进行训练,得到模型参数:
ai=g(ei)
其中,φ(·)是转录文本中词的特征提取网络,g(·)是注意力激活函数,
进一步的,所述注意力激活函数g(·)采用softmax(·)或sparsemax(·)。
本发明最为突出的特点和显著的有益效果是:
本发明所涉及的基于多示例学习的自动语音识别困难样本挖掘方法,利用标注好的训练集建立并训练困难样本检测模型,来有效挖掘困难样本,进而提供给语音识别系统进行重训练。本发明能够简单而快速的从大量未标记语音数据集中自动筛选困难样本,以减少由于人工标注样本所带来的成本,并将困难样本输入到已有asr系统中,使其能尽快适应新领域,从而快速完成语音识别,使语音识别的效率提高近一倍;本发明可应用于语音识别系统对新领域的快速自适应。
附图说明
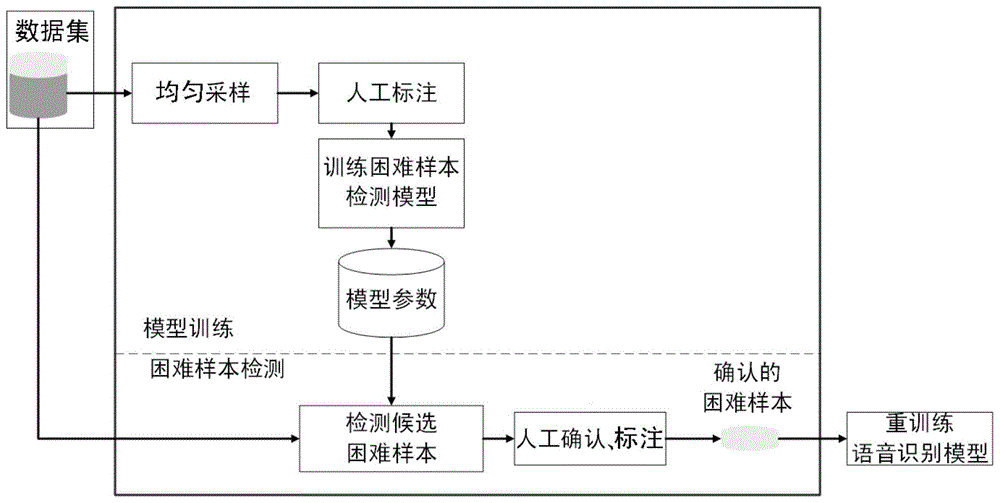
图1为本发明方法流程图。
具体实施方式
具体实施方式一:结合图1对本实施方式进行说明,目前大多数asr系统使用深度神经网络(deepneuralnetwork,dnn)作为语音识别模型,并且采用误差反向传播(backpropagation,bp)算法更新语音识别模型参数。在使用新数据对模型进行重训练的过程中,那些模型无法正确识别的训练样本能够产生更大的反向传播误差,由于该误差是模型更新参数的决定性依据,因此这类样本在模型参数更新过程中起到关键性作用,称其为困难样本。本实施方式给出的基于多示例学习的自动语音识别困难样本挖掘方法,具体包括以下步骤:
步骤一、收集语料数据建立数据集
使用目前已经成熟的技术收集大量无标注语料建立数据集
步骤二、选取训练数据:
将数据集
步骤三、对训练集进行人工标注,得到标注好的训练集
步骤四、使用标注好的训练集建立困难样本检测模型,并对其进行训练;
(1)建立困难样本检测模型:
其中,xi是标注好的训练集
(2)对困难样本检测模型进行训练,得到模型参数:
ai=g(ei)
其中,φ(·)是转录文本中词的特征提取网络;g(·)是注意力激活函数,本实施方式中的注意力激活函数g(·)采用softmax(·)(归一化指数函数)或sparsemax(·)(稀疏概率激活函数)。
步骤五、无标注困难样本挖掘:
使用步骤四中训练好的困难样本检测模型在剩余集合
步骤六、困难样本筛选与标注:
对步骤五中检测到的候选困难样本进行人工确认,同时将人工确认后的困难样本进行标注;确认、标注后的困难样本即可应用于语音识别模型的重训练。
本发明能够从大量未标记语音数据集中自动筛选困难样本,以减少由于人工标注样本所带来的成本,并将困难样本输入到已有asr系统中,使其能尽快适应新领域。
本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,本领域技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!