语音识别测试方法、装置及系统与流程
本发明属于语音识别技术领域,具体涉及一种语音识别测试方法、装置及系统。
背景技术:
随着技术的不断发展,具有语音识别功能智能终端设备越来越受到用户的欢迎,但是应用语音识别功能时,往往用户语音信息与智能终端屏幕显示的信息不同步,用户语音与智能终端屏幕显示的信息之间存在一定的时间延迟,为了降低时间延迟,提高用户体验,需要对存在的时间延迟进行语音识别测试。
目前主要采用两种方式进行语音识别测试,第一种是抓取智能终端设备底层接口的各个时间点,第二种是通过摄像设备拍摄屏幕显示的信息。然而,发明人发现现有技术中至少存在如下问题:在第一种方式中,需要获取智能终端设备系统的管理权限,存在一定的数据安全风险,并且操作复杂。在第二种方式中,摄像设备只获取屏幕显示的信息,不对用户语音进行分析,存在较大的误差,从而容易造成测试结果不准确。
技术实现要素:
本发明旨在至少解决现有技术中存在的技术问题之一,提供一种语音识别测试方法、装置及系统。
解决本发明技术问题所采用的技术方案是一种语音识别测试方法,包括:
获取摄像设备采集的包含视频和第一音频的数据文件;所述第一音频包括用户语音和第一噪音,所述视频包括响应于所述用户语音的图像变化视频;
获取终端设备采集的第二音频;所述第二音频包括用户语音和第二噪音;所述终端设备与用户之间的距离小于所述摄像设备与用户之间的距离;
将所述视频和所述第一音频分离;
根据所述视频的信息,计算所述视频的终止时间;
根据所述第一音频和所述第二音频,计算所述用户语音的终止时间;
判断分离的所述视频和所述第一音频的时钟是否同步;
若分离的所述视频和所述第一音频的时钟不同步,则计算所述视频与所述第一音频的时间差;
根据所述视频的终止时间、所述用户语音的终止时间和所述时间差,计算所述语音识别的响应延迟。
可选地,所述将所述视频和所述第一音频分离,之前包括:
在所述数据文件的视频的起始位置添加图像标识;
当所述数据文件的视频中出现所述图像标识时,在所述数据文件的第一音频中相应位置添加音频标识。
可选地,所述判断分离的所述视频和所述第一音频的时钟是否同步,包括:
根据所述视频出现所述图像标识时的帧数和帧率,获取所述视频的第一时间;
获取所述第一音频出现所述音频标识时的第二时间;
若所述第一时间和所述第二时间相同,则判断出所述视频和所述第一音频的时钟同步。
可选地,若所述第一时间和所述第二时间不同,则判断出所述视频和所述第一音频的时钟不同步;
根据所述第一时间和所述第二时间,计算时间差。
可选地,所述计算所述视频的终止时间,包括:
根据所述视频出现既定画面且不再刷新时与出现所述图像标识时之间的帧数和帧率,计算所述视频的第三时间。
可选地,所述计算所述用户语音的终止时间,包括:
将所述第一音频和所述第二音频进行差分器相减,获得特征函数;
将所述第一音频、所述第二音频和所述特征函数由时域转换到频域;
在频域上,对所述第一音频、所述第二音频和所述特征函数进行卷积运算,获得第一音频函数和第二音频函数;
获取所述第一音频函数的最大值对应在时域上的第五时间和所述第二音频函数的最大值对应在时域上的第六时间;
根据所述第五时间和所述第六时间的平均值,获得第四时间。
可选地,所述计算所述语音识别的响应延迟,包括:
根据所述第三时间、所述第四时间和所述时间差,计算所述语音识别的响应时延。
解决本发明技术问题所采用的技术方案是一种语音识别测试装置,其特征在于,包括:
第一获取单元,用于获取摄像设备采集的包含视频和第一音频的数据文件;所述第一音频包括用户语音和第一噪音,所述视频包括响应于所述用户语音的图像变化视频;
第二获取单元,用于获取终端设备采集的第二音频;所述第二音频包括用户语音和第二噪音;所述终端设备与用户之间的距离小于所述摄像设备与用户之间的距离;
分离单元,用于将所述视频和所述第一音频分离;
第一计算单元,用于根据所述视频的信息,计算所述视频的终止时间;
第二计算时间,用于根据所述第一音频和所述第二音频,计算所述用户语音的终止时间;
判断单元,用于判断分离的所述视频和所述第一音频的时钟是否同步;
第三计算单元,用于若分离的所述视频和所述第一音频的时钟不同步,则计算所述视频与所述第一音频的时间差;
第四计算单元,用于根据所述视频的终止时间、所述用户语音的终止时间和所述时间差,计算所述语音识别的响应延迟。
可选地,该语音识别测试装置还包括:
第一标识单元,用于在所述数据文件的视频的起始位置添加图像标识;
第二标识单元,用于当所述数据文件的视频中出现所述图像标识时,在所述数据文件的第一音频中相应位置添加音频标识。
解决本发明技术问题所采用的技术方案是一种语音识别测试系统,其特征在于,包括:终端设备、摄像设备和上述提供的语音识别测试装置。
附图说明
图1、图2、图3、图4为本发明实施例提供的一种语音测试方法的流程图;
图5为本发明实施例提供的一种语音测试装置的结构示意图;
图6为本发明实施例提供的一种语音测试系统的结构示意图。
附图标记说明:501-第一获取单元、502-第二获取单元、503-分离单元、504-第一计算单元、505-第二计算时间、506-判断单元、507-第三计算单元、508-第四计算单元、509-第一标识单元、510-第二标识单元、601-终端设备、602-摄像设备、和603-语音识别测试装置。
具体实施方式
为使本领域技术人员更好地理解本发明的技术方案,下面结合附图和具体实施方式对本发明作进一步详细描述。
实施例一:
图1为本发明实施例提供的一种语音识别测试方法的流程图,可用于智能终端设备的语音识别的测试,该智能终端设备可以为智能手机、平板电脑、智能电视以及车载终端中的一种,本发明实施例将以智能手机为例并结合附图对该语音识别测试方法进行详细描述。在以下的实施例中的摄像设备可以为高速摄像机,其具有视频采集功能,精确度为毫秒级别,可以精确采集智能手机屏幕上图像变化的视频信息。而且,该高速摄像机中具有语音采集功能,在采集视频的同时,还可以精确采集用户语音。在实际应用中,无论是智能手机还是高速摄像机,对用户语音的采集过程中无法避免周围环境噪音的干扰,因此,需要对智能手机和高速摄像机采集的用户语音进行处理,具体处理方式将在之后的实施例中详细说明。在测试过程中,用户向智能手机发出语音指令,该语音指令可以为指示移动终端显示一句话或者打开某一应用,例如该语音指令可以为“中国联通”或者“打开百度地图”,相应的,在智能手机上显示“中国联通”或者打开百度地图应用。本发明实施例及之后的实施例中以智能手机屏幕显示“中国联通”为例进行说明。
本发明实施例提供的语音识别测试方法可以包括以下的步骤:
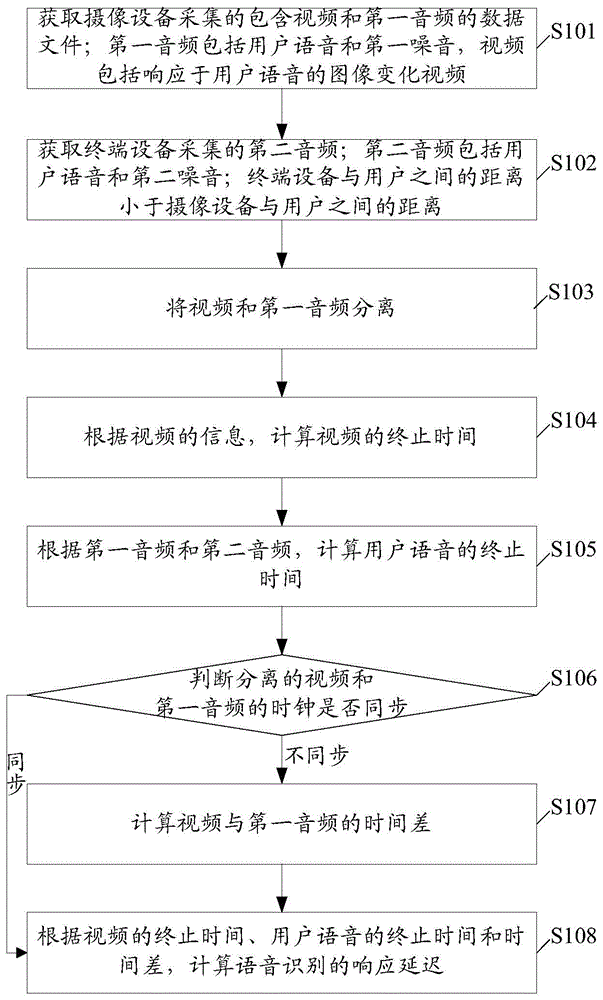
s101,获取摄像设备采集的包含视频和第一音频的数据文件;第一音频包括用户语音和第一噪音,视频包括响应于用户语音的图像变化视频。
本步骤s101中,用户发出包括“中国联通”的语音指令,智能手机接收到该语音指令后,在屏幕上显示有“中国联通”字样的图像,高速摄像机通过视频采集模块可以采集智能手机屏幕从开始到“中国联通”字样完全显示的图像变化视频。同时,高速摄像机中的语音采集模块可以采集用户语音以及周围的周围环境的第一噪音,即第一音频。最终生成包括视频和第一音频的数据文件。需要说明的是,本发明实施例中的高速摄像机的拍摄帧率可以为60帧每秒,当然,也可以为其他的高速帧率。
s102,获取终端设备采集的第二音频;第二音频包括用户语音和第二噪音;终端设备与用户之间的距离小于摄像设备与用户之间的距离。
本步骤s102中,用户发出包括“中国联通”的语音指令,智能手机可以采集用户语音以及周围环境的第二噪音,即第二音频。由于智能手机与用户之间的距离小于高速摄像机与用户之间的距离,用户语音对智能手机采集的第二音频有明显的增益,并且,智能手机采集的第二音频中的第二噪音与高速摄像机采集的第一音频中的第一噪音有明显的区别,从而可以结合第一音频和第二音频对用户语音进行分析,进而实现对用户语音在音频波形图中的起始位置与终止位置的精确定位。
s103,将视频和第一音频分离。
需要说明的是,由于高速摄像机采集的数据文件中包含视频和第一音频,在之后对用户语音的分析中,需要将第一音频和第二音频结合,因此,需要将第一音频从数据文件中单独分离出来,以便于之后的用户语音分析。
s104,根据视频的信息,计算视频的终止时间。
本步骤s104中,根据高速摄像机的设备参数,以及分离后的视频的信息,可以计算出智能手机在接收的用户发出的“中国联通”语音指令后,在屏幕上完全显示“中国联通”字样的图像需要的时间。
s105,根据第一音频和第二音频,计算用户语音的终止时间。
需要说明的是,由于高速摄像机在采集第一音频和智能手机采集第二音频时,由于设备及周围环境因素,对用户语音的采集过程中无法避免周围环境噪音的干扰,因此,需要结合第一音频和第二音频进行分析,并计算得到用户语音精确的起始时间和结束时间。
s106,判断分离的视频和第一音频的时钟是否同步。
基于上述步骤s103中需要对数据文件中的视频和第一音频进行分离,可以利用现有的分离技术进行,但是,利用现有技术对数据文件进行分离时,可能会造成分离的视频和第一音频的时钟不同步。因此,在本步骤s106中,需要判断分离的视频和第一音频的时钟是否同步,以保证分离后的视频和第一音频的起始时间相同,进而保证最终计算得到的视频的终止时间和用户语音的终止时间的准确。
若分离的视频和第一音频的时钟不同步,则执行步骤s107,计算视频与第一音频的时间差。
需要说明的是,当判断出由于数据文件的分离造成分离的视频和第一音频的时钟不同步,则需要对视频和第一音频进行校准,计算出视频与第一音频的时间差。
s108,根据视频的终止时间、用户语音的终止时间和时间差,计算语音识别的响应延迟。
需要说明的是,当分离的视频和第一音频的时钟同步时,视频和第一音频的时间差为0,可以直接利用视频和终止时间和用户语音的终止时间,计算出语音识别的响应延迟。
本发明实施例提供的语音识别测试方法中,终端设备与用户的距离小于摄像设备与用户的距离,可以获取摄像设备采集的用户语音以及周围的第一噪音,即第一音频,以及采集的终端设备响应于用户语音的图像变化视频,并且,获取终端设备采集的用户语音即周围的第二噪音,即第二音频,通过结合第一音频和第二音频,得到视频的终止时间、用户语音的终止时间,以及视频与第一音频的时间差,从而通过计算可以精确得到语音识别的响应延迟,进而提高了语音识别测试的精确度,减少了利用人耳对语音识别的人力消耗,并且,不需要获取终端设备的管理权限,因此,也避免了数据安全风险。
由于对于分离后的视频和第一音频的分析精确度为毫秒级别,因此,在数据文件分离前,需要对该数据文件校准时钟同步,其具体方式可以通过以下步骤实现。
s201,在数据文件的视频的起始位置添加图像标识。
s202,当数据文件的视频中出现图像标识时,在数据文件的第一音频中相应位置添加音频标识。
需要说明的是,由于数据文件通过高速摄像机采集获得的,其中的视频的起始时间不容易受到其他因素的干扰,当接收的用户发出的“中国联通”的语音指令后,可以控制智能手机在屏幕出现“中国联通”字样的起始位置添加一个图像标识,该图像标识可以为一个红色圆点,以表示视频由这里开始。同时,控制智能手机发出一个特定频率的音频标识,该音频标识可以为“滴”一声。由于视频的起始位置更加直观便于确定,因此,可以对应的在第一音频中添加音频标识,以保证分离前视频和第一音频的时钟同步。
分离后的视频和第一音频,由于分离过程中的技术原因,容易出现时钟不同步,需对分离后的视频和第一音频判断时钟是否同步,其具体方式可以通过以下步骤实现。
s301,根据视频出现图像标识时的帧数和帧率,获取视频的第一时间。
s302,获取第一音频出现音频标识时的第二时间。
s303,判断第一时间和第二时间是否相同,若第一时间和第二时间相同,则判断出视频和第一音频的时钟同步。
s304,若第一时间和第二时间不同,则判断出视频和第一音频的时钟不同步。则执行步骤s305。
s305,根据第一时间和第二时间,计算时间差。
需要说明的是,由于在视频和第一音频分离前,在数据文件中的视频起始位置添加了图像标识,相应地,在数据文件中的第一音频起始位置添加了音频标识。分离后,当视频播放至图像标识时,可以将该时间记为第一时间,当第一音频的波形图中出现特定频率的音频标识的波形图时,可以将该时间记为第二时间。比较第一时间和第二时间,如果第一时间和第二时间相同,则表示视频和第一音频的起始时间相同,不需要进行校准。如果第一时间和第二时间不同,则表示视频和第一音频的起始时间不同,不需要进行校准,计算出第一时间和第二时间之间的时间差。
可选地,计算视频的终止时间,可以根据视频出现既定画面且不再刷新时与出现图像标识时之间的帧数和帧率,计算视频的第三时间。
需要说明的是,数据文件通过高速摄像机采集获得的,其中的视频展示较为直观,并且不容易受到其他因素的干扰。当视频出现既定画面且不再刷新,即屏幕中完全显示“中国联通”字样,并且不再刷新,则表示该图像变化视频结束,可以通过获取该视频的帧数和帧率,计算出该视频的第三时间。
高速摄像机和智能手机在采集用户语音的过程中,无法避免周围环境噪音的干扰,因此需要结合高速摄像机采集的第一音频和智能手机采集的第二音频,对用户语音进行分析,其具体方式可以通过以下步骤实现。
s401,将第一音频和第二音频进行差分器相减,获得特征函数。
需要说明的是,由于智能手机与用户之间的距离小于高速摄像机与用户之间的距离,用户语音对于智能手机的第一音频采集具有明显的增益。因此,第一音频和第二音频经过差分器进行相减后可以得到特征函数,该特征函数的特征矩阵中对环境噪音有所抑制,从而增强第一音频和第二音频中的用户语音。
s402,将第一音频、第二音频和特征函数由时域转换到频域。
s403,在频域上,对第一音频、第二音频和特征函数进行卷积运算,获得第一音频函数和第二音频函数。
s404,获取第一音频函数的最大值对应在时域上的第五时间和第二音频函数的最大值对应在时域上的第六时间。
本步骤s404中,在特征函数中主要是用户语音的响应函数,第一音频和第二音频中也包含该特征函数的信息,因此卷积运算会在第一音频、第二音频与特征函数相同的位置形成最大值。
s405,根据第五时间和第六时间的平均值,获得第四时间。
本发明实施例中,通过将第一音频和第二音频结合,并进行卷积运算,精准获取用户语音的时间,避免通过人耳进行语音回放,从而减少了人力消耗。
基于上述的方法中计算得到的第三时间、第四时间和时间差,可以计算出语音识别的响应延迟。
需要说明的是,第三时间可以记为t3,第四时间可以记为t4,时间差可以记为tx,则语音识别的响应延迟t=t3-t4-tx。该响应延迟t越长,表示语音识别延迟越严重,可以通过其他方式尽量减少相应延迟t,从而提高用户使用体验。
实施例二
基于同于发明构思,本发明实施例提供了一种语音识别测试装置,图5为本发明实施例提供的一种语音识别测试装置的结构示意图,如图5所示,该语音识别测试装置包括:
第一获取单元501用于获取摄像设备采集的包含视频和第一音频的数据文件;第一音频包括用户语音和第一噪音,视频包括响应于用户语音的图像变化视频。
第二获取单元502用于获取终端设备采集的第二音频;第二音频包括用户语音和第二噪音;终端设备与用户之间的距离小于摄像设备与用户之间的距离。
分离单元503用于将视频和第一音频分离。
第一计算单元504用于根据视频的信息,计算视频的终止时间。
第二计算单元505用于根据第一音频和第二音频,计算用户语音的终止时间。
判断单元506用于判断分离的视频和第一音频的时钟是否同步。
第三计算单元507用于若分离的视频和第一音频的时钟不同步,则计算视频与第一音频的时间差。
第四计算单元508用于根据视频的终止时间、用户语音的终止时间和时间差,计算语音识别的响应延迟。
基于上述实施例提供的语音识别测试装置,该语音识别测试装置还包括:
第一标识单元509用于在数据文件的视频的起始位置添加图像标识。
第二标识单元510用于当数据文件的视频中出现图像标识时,在数据文件的第一音频中相应位置添加音频标识。
本发明实施例提供的语音识别测试装置可以执行上述实施例一提供的语音识别测试方法,其实现原理相同,在此不再赘述。
实施例三
基于同一发明构思,本发明实施例提供了一种语音识别测试系统,图6为本发明实施例提供的语音识别测试系统的结构示意图,如图6所示,该语音识别测试系统包括:终端设备601、摄像设备602和语音识别测试装置603。
本发明实施例提供的语音识别测试系统,可以执行上述实施例一提供的语音识别测试方法,其实现原理相同,在此不再赘述。
可以理解的是,以上实施方式仅仅是为了说明本发明的原理而采用的示例性实施方式,然而本发明并不局限于此。对于本领域内的普通技术人员而言,在不脱离本发明的精神和实质的情况下,可以做出各种变型和改进,这些变型和改进也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!