一种基于对抗语义擦除的语音情感识别方法与流程
本发明涉及一种离散语音情感识别领域,尤其涉及一种基于对抗语义擦除的语音情感识别方法。
背景技术:
语音是人交流沟通的主要方式,也是最自然、最主流的人机交互方式之一。然而在语音交互过程中,系统大多只是学习了语音的内容,却往往忽略语音中所蕴含的情感信息,导致使用者感觉到死板和挫败,而语音情感识别则是改善用户体验感的一种新型交互技术。
语音情感识别是指通过语音中蕴含的情感信息,判断说话人此时的情感状态。在日常生活和交流中,人可以通过情绪感知来判断对方的状态和喜好,因此用户也期待计算机能感知和判断他的情绪和喜好,并做出自然的回应,让使用者得到更好的人机交互体验。随着移动通信技术和互联网技术的发展,语音情感识别在远程教育、电子游戏、智能玩具、陪伴机器人等多方面有着重要的应用价值。
现有语义情感识别研究大多在以下两个方面进行优化:一是提取更具表征力的语音情感特征,包括谱相关特征、韵律特征、声音质量特征、神经网络瓶颈输出等自制特征以及上述特征的融合特征等。二是选择更具识别能力的识别器,包括传统的机器学习分类器和深度学习分类器。
然而不同于语义信息,语音中的情感信息作为一个高维度特征,具有很强的不确定性和主观性,人工很难制定的有效的语音特征提取策略。同时在小数据量限制的情况下,基于统计学意义的深度学习方法也很容易受到不同语义差异间的干扰,导致现有方法识别结果准确率较低,跨数据集识别效果差。因此如何在语音情感识别中去除语义信息的干扰,提高识别准确率和跨数据集表现力,成为了本领域内技术人员亟待解决的问题。
技术实现要素:
本发明的目的是提供一种基于对抗语义擦除的语音情感识别方法,该方法能够快速准确地基于输入的语音数据识别语音情感类别。
为实现上述发明目的,本发明提供的技术方案为:
一种基于对抗语义擦除的语音情感识别方法,包括以下步骤:
(1)获取原始语音数据,并对原始语音数据进行预处理获得输入特征;
(2)利用包含第一特征提取器和第一识别器的语音识别模型对输入特征进行识别,获得识别语义,同时提取特征提取器输出的语义特征;
(3)利用包含第二特征提取器和第二识别器的语音情感识别模型的第二特征提取器对输入特征进行提取获得语音特征,从语音特征中擦除所述语义特征获得情感特征,利用第二识别器识别对输入的情感特征进行识别,输出语音情感类别;
所述语音识别模型和所述语音情感识别模型的网络结构相同,经过对抗训练确定网络参数,从所述语音识别模型中输入层起提取任意个网络层组成第一特征提取器,剩下网络层组成第一识别器;从所述语音情感识别模型中输入层起提取与第一特征提取器相同个数的网络层组成第二特征提取器,剩下网络层组成第二识别器。
与现有技术相比,本发明具有的有益效果为:
(1)本发明通过基于语音识别任务和语音情感识别任务之间学习到的语音特征的对抗性,在语音情感识别中去除了语义内容的干扰,提高了语音情感识别的准确率以及模型跨数据集跨语种的表现能力。
(2)本发明在小数据量的限制下,利用大数据量的语音识别任务进行辅助,提取了更纯正的语音情感特征,克服了语音情感数据量少的困难。
(3)本发明使用的是除语义之外的情感信息,能有效克服“言不由衷”、情感掩饰的使用情景,识别更真实的情感状态。
(4)本发明主要应用于针对独居老人和学龄前儿童的陪伴机器人,并针对相关场景进行了任务适应,具有很高的商业应用价值。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图做简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动前提下,还可以根据这些附图获得其他附图。
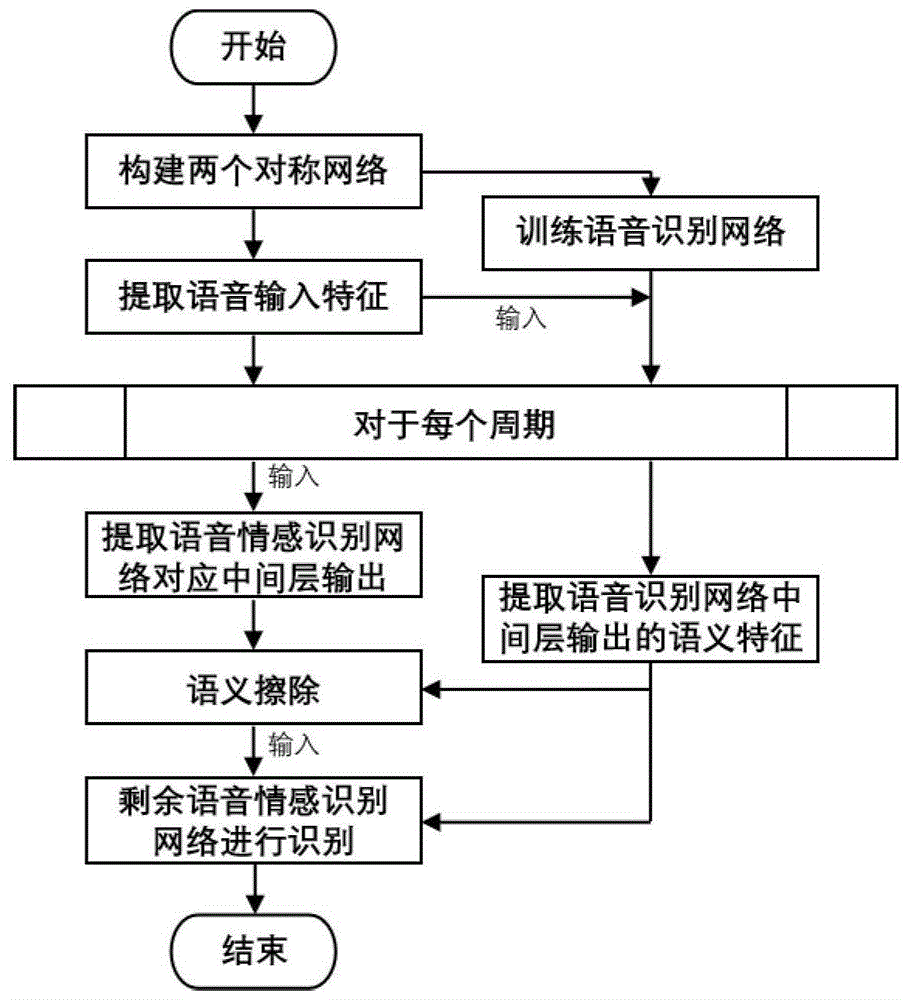
图1是本发明实施例提供的基于对抗语义擦除的语音情感识别方法的流程图;
图2是本发明实施例提供的对原始语音数据进行预处理获得输入特征的过程;
图3是本发明实施例提供的基于对抗语义擦除的语音情感识别方法的总体框架图;
图4(a)~图4(d)是本发明实施例提供的识别准确率图。
具体实施方式
为使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例对本发明进行进一步的详细说明。应当理解,此处所描述的具体实施方式仅仅用以解释本发明,并不限定本发明的保护范围。
图1是本发明实施例提供的基于对抗语义擦除的语音情感识别方法的流程图;图2是本发明实施例提供的对原始语音数据进行预处理获得输入特征的过程;图3是本发明实施例提供的基于对抗语义擦除的语音情感识别方法的总体框架图;参见图1~3,该语音情感识别方法包括以下步骤:
步骤1,获取原始语音数据,并对原始语音数据进行预处理获得输入特征。
步骤1中,对原始语音数据依次进行分帧加窗、傅里叶变换(fft)和复数分解提取原始语音数据对应的时频谱中的实部谱,并对实部谱进行数据平滑,获得输入特征。
具体地,采用以下平滑函数对实部谱进行数据平滑,
log1p=log(x+1)
其中,x表示输入的待平滑数据。
步骤2,利用包含第一特征提取器和第一识别器的语音识别模型对输入特征进行识别,获得识别语义,同时提取特征提取器输出的语义特征。
该语音识别模型是利用大量语音识别数据训练获得的,由于语音识别模型在大量不同语义内容、不同情绪状态的测试样本中表现优秀,因此可以证明该语音识别模型学习到了去除了情感信息影响的有效语义特征。
步骤3,利用包含第二特征提取器和第二识别器的语音情感识别模型的第二特征提取器对输入特征进行提取获得语音特征,从语音特征中擦除所述语义特征获得情感特征,利用第二识别器识别对输入的情感特征进行识别,输出语音情感类别。
由于语音情感识别模型和语音识别模型在语音识别任务和语音情感识别任务之间的特征点对抗性,采用采用语义擦除的方法从语音情感识别模型的第二特征提取器输出的语音特征中除去语音识别模型的第一特征提取器输出的语义特征。
具体地,采用特征相减、异或、卷积、特征融合中的至少一种方式从语音特征中擦除所述语义特征获得情感特征。具体地,所述特征融合包括主成成分分析(pca)、奇异值分解(svd)等。
其中,特征相减擦除方法如下:
其中,fs表示语义特征,fa表示语音特征,fe表示情感特征,
本发明中,所述语音识别模型和语音情感识别模型采用深度学习网络经对抗训练获得。
具体地,所述语音识别模型和语音情感识别模型采用cnn和rnn相结合的网络,经对抗训练获得。
具体地,所述语音识别模型和语音情感识别模型的训练过程为:
获得语音情感识别数据集,并对语音情感识别数据集中的语音数据进行预处理获得输入特征,该输入特征以及对应的识别语义和语音情感类别组成训练样本,构成语音情感训练集;
搭建网络结构相同的语音识别模型和所述语音情感识别模型;
获得语音识别数据集,对语音识别数据集中的语音数据,进行与语音情感识别相同的预处理,获得语音识别输入特征,并使用ctc损失函数和该语音识别输入特征,预训练语音识别模型;
使用语音情感训练集同时训练语音情感模型和微调(finetuning)预训练后的语音识别模型,训练步骤如下:
(1)使用语音情感训练集中的语音输入数据和识别语义,用ctc损失函数微调包含第一特征提取器和第一识别器在内的语音识别模型参数;
(2)提取第一特征提取器输出的语义特征;
(3)将语音情感训练集中的语音输入数据输入第二特征提取器,其输出除擦除步骤(2)中的语义特征后,输入第二识别器,利用交叉熵损失函数训练情感分类后,更新包含第二特征提取器和第二识别器在内的语音情感模型参数,并微调第一特征提取器参数;
重复步骤以上步骤,直至模型训练稳定;
(4)重复步骤以上步骤,直至模型训练稳定训练结束后;
确定网络参数,从所述语音识别模型中输入层起提取任意个网络层组成第一特征提取器,剩下网络层组成第一识别器;从所述语音情感识别模型中输入层起提取与第一特征提取器相同个数的网络层组成第二特征提取器,剩下网络层组成第二识别器。
上述基于对抗语义擦除的语音情感识别方法可以应用到独居老人和学龄前儿童生活陪伴中,原始语音数据可以为英语和德语等语言,识别的语音情感类别包括悲伤、愤怒、开心以及中性四种情绪类别。
图4(a)~图4(d)为本发明实施例提供的识别准确率图,具体表示使用语义擦除和未使用情况下分别在德语和英语数据集上的结果。由图4(a)~图4(d)可知,使用了语义擦除的方法在德语数据集上准确率提高了约2%,在英语数据集上也能保证高准确率并提高系统训练的稳定性。同时使用了语义擦除方法后,英语数据集上训练好的模型在德语数据集上的预测准确率提高了6%,德语数据集上训练好的模型在英语数据集上的预测准确率提高了0.59%,该结果表明该基于对抗语义擦除的语音情感识别方法能有效提高语音情感识别准确率,并且能提高模型跨数据集跨语种的表现能力。
以上所述的具体实施方式对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的最优选实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!