一种基于双深度网络的多模式情感信息融合与识别方法与流程
本发明涉及情感识别
技术领域:
,尤其涉及一种基于双深度网络的多模式情感信息融合与识别方法。
背景技术:
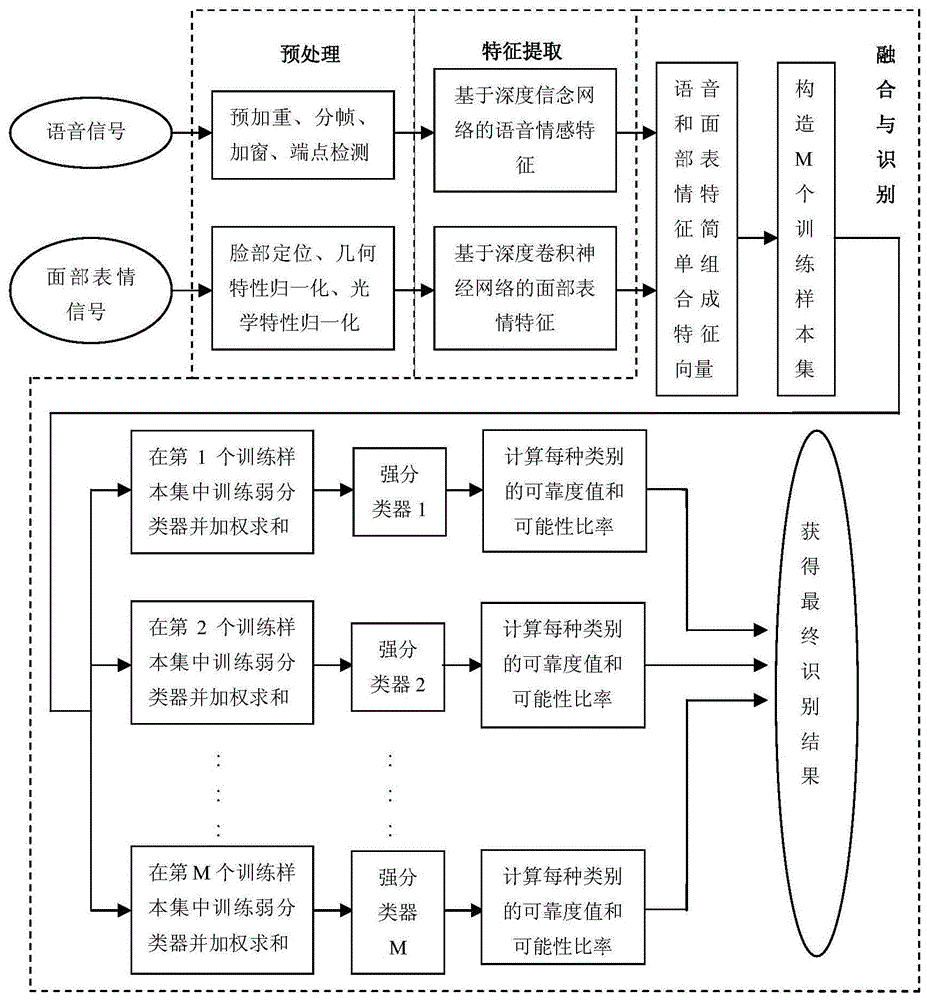
:情感识别是一个跨学科的研究领域,近年来受到越来越多的关注。虽然单一地依靠语音信号、面部表情信号和生理参数来进行情感识别的研究取得了一定的成果,但却存在着很多局限性,因为人类是通过多模式的方式表达情感信息的,它具有表达的复杂性和文化的相对性。如美国mit媒体实验室情感计算研究小组picard教授等人率先以图片为诱发材料,从人体肌电、脉搏、皮肤电导和呼吸信号中提取特征,并对愤怒、憎恶、悲伤、柏拉图式的爱、罗曼蒂克的爱、高兴、崇敬以及中性状态共8种情感进行分类,取得了较好的分类效果。东南大学的赵力、黄程韦等通过融合语音信号与心电信号进行了多模式情感识别,获得较高的融合识别率。但是上述方法均为与生理信号相融合,而生理信号的测量必须与身体接触,因此对于此通道的信号获取有一定的困难,所以语音和面部表情作为两种最为主要的表征情感的方式,得到了广泛的研究。如patwadhan提出了一种利用多模态音视频连续数据自动检测情感的方法,采用特征层融合的方法建立组合特征向量,利用支持向量机分类器进行情感检测。esam等使用不同的融合方案利用每种模式的属性,提出了一种基于信息增益原理的分层决策方法,并利用遗传算法对其参数进行了优化。中国人民大学的陈师哲等在多文化场景下进行了多模态情感识别,验证了文化因素对于情感识别的重要影响。从一定意义上说,不同信道信息的融合是多模式情感识别研究的瓶颈问题,它直接关系到情感识别的准确性。因此,基于语音与面部表情信号的多模式情感识别研究是一个具有重要理论意义和很高实用价值的科学问题。目前,融合多模式情感信息的方法主要有2种:决策层的融合和特征层的融合。决策层的融合技术是先把各个模式的信息提取出来,输入相应的分类器得到单模式识别结果,然后用规则的方法将单模式的结果综合起来,得到最终的识别结果;特征层的融合方法则是将各个模式的信息提取出来,将这些信息组成一个统一的特征向量,然后再输入到分类器中,得到最终的识别结果。这两种方法各有优缺点,决策层的融合技术考虑了不同模式对于情感识别重要性的不同,因此他们通过主观感知实验给不同的模式赋予不同的权重,但往往对同一模式仅赋一个权重,由于各模式对不同类别数据的分类能力是不同的,因此这种通过主观感知实验得到的权重能否应用到其他的情况下是值得怀疑的。特征层的融合技术更接近人类识别情感的过程,能更好地利用统计机器学习的技术,但是这种方法没有考虑到识别不同情感时,不同模式重要性的不同,因此这种方法不能最大程度地发挥多模式融合的优势。可以看出,目前对于情感信息融合技术的研究尚处于起步阶段,相应的基础理论和方法框架仍很欠缺。技术实现要素:本发明要解决的技术问题是针对上述现有技术的不足,提供一种基于双深度网络的多模式情感信息融合与识别方法,通过语音特征和面部表情特征相融合,对情感信息进行识别。为解决上述技术问题,本发明所采取的技术方案是:一种基于双深度网络的多模式情感信息融合与识别方法,包括以下步骤:步骤1、情感信号获取;首先诱发情感,再同步获取相应情感状态下的语音信号和面部表情信号,并将二者绑定存储,获得多个情感样本;所述获取相应情感状态下的语音信号和面部表情信号的具体方法为:利用麦克风接收语音数据后,再通过采样量化获得相应的语音信号;而面部表情信号则通过摄像机拍摄获得;所述的采样量化的采样频率为11.025khz、量化精度为16bit;所述的通过摄像机拍摄获得的每幅面部表情信号图像大小为256×256像素;步骤2、对每个情感样本的情感信号进行预处理;步骤2-1、语音信号预处理;对获取的情感样本中的语音信号进行预处理,包括预加重、分帧加窗和端点检测;所述预加重采用一阶数字预加重滤波器实现,预加重滤波器的系数取值为0.93~0.97;所述分帧加窗为以帧长256点的标准进行分帧,并对分帧后的数据加汉明窗处理;所述端点检测利用基于短时能零积和鉴别信息的语音端点检测法进行;步骤2-2、面部表情信号预处理;对获取的情感样本中的面部表情信号,首先进行脸部定位,然后进行图像几何特性和光学特性的归一化处理;所述脸部定位利用肤色模型实现;所述图像几何特性归一化根据左右两眼的坐标值旋转图像实现;所述图像光学特性的归一化处理先采用直方图均衡化方法对图像灰度做拉伸,然后对图像像素灰度值进行归一化处理,使标准人脸图像的像素灰度值为0,方差为1;步骤3、对每个情感样本中的情感特征参数进行提取;步骤3-1、训练深度信念网络,并将预处理后的语音信号送入训练好的深度信念网络来自动提取语音信号中的情感特征;所述深度信念网络包括四个隐含层,每层的每个单元连接到每个相邻层中的每个单元,没有层内连接,即使用多个受限玻尔兹曼机堆叠而成;所述训练深度信念网络的具体方法为:1)训练第一个受限玻尔兹曼机,其联合概率分布由能量函数指定,如下式所示:其中,p(v,h;θ)为第一个受限玻尔兹曼机的联合概率,v为m维的可见层向量,m是可见层的神经元个数,h为n维的隐含层向量,n是隐含层的神经元个数,θ={a,b,w},w为权重矩阵,b为可见层的偏置向量,a为隐含层的偏置向量,z(θ)为配分函数的归一化常数,如下公式所示:其中,e(v,h;θ)为能量函数,公式为:其中,wij是可见层的第i个神经元和隐含层的第j个神经元之间的对称权值,bi是可见层的第i个神经元的偏置,aj是隐含层的第j个神经元的偏置,vi是可见层向量的第i个元素,hj是隐含层向量的第j个元素;2)训练第二个受限玻尔兹曼机,并将第一个受限玻尔兹曼机的隐含层作为第二个受限玻尔兹曼机的可见层,并依此添加任意多层继续扩展,其中每个新的受限玻尔兹曼机对前一个受限玻尔兹曼机的样本建模;步骤3-2、用深度卷积神经网络自动提取情感样本中的面部表情特征;步骤3-2-1、建立深度卷积神经网络结构;所述深度卷积神经网络结构包括卷积层、最大池化层、第一组残差块、第二组残差块、平均池化层和全连接层;并分别在第一组残差块的始端与末端之间加入跨层连接支路,第二组残差块的始端与末端之间加入跨层连接支路;所述第一组残差块包括两种类型的残差块,分别是resnet-34和resnet-50;第二组残差块包括三种类型的残差块,分别是resnet-34、resnet-50和resnet-101;步骤3-2-2、采用梯度下降算法训练建立好的深度卷积神经网络;步骤3-2-3、将预处理后的面部表情信号作为训练好的深度卷积神经网络的输入,其输出即为面部表情特征参数;步骤4、将每个情感样本中的情感特征参数进行组合,获得情感样本的组合特征向量;将用深度信念网络提取的语音情感特征和用深度卷积神经网络自动提取的面部表情特征顺序组合起来获得情感样本的组合特征向量;步骤5、基于adaboost算法和类可靠度实现情感识别;步骤5-1、将获得的所有情感样本的组合特征向量构成一个集合称为组合特征向量集,并将该组合特征向量集等分成三份,分别作为训练样本集、可靠度预测样本集和测试样本集;步骤5-2、通过对训练样本集做有放回的抽样,获得若干个子训练样本集;步骤5-3、利用adaboost算法对各子训练样本集分别进行训练,获得每个子训练样本集上的强分类器;所述强分类器的输出层有6个神经元,代表6种人类基本情感,即高兴、愤怒、惊奇、悲伤、恐惧和中性;步骤5-4、用可靠度预测样本集中的数据作为各强分类器的测试样本来预测各强分类器输出各情感类别的正确率,作为各情感类别的可靠度值;步骤5-5、将待测样本送入各强分类器进行识别,每个强分类器对每类情感均产生一个可能性比率;将各强分类器输出的每类情感的可靠度值与可能性比率作乘积,然后将各强分类器类别相同的乘积值累加,将累加值最大的情感类别作为最终的情感识别结果。采用上述技术方案所产生的有益效果在于:本发明提供的一种基于双深度网络的多模式情感信息融合与识别方法,(1)将语音信号和面部表情信号进行融合,弥补了单模式的不足;(2)充分利用了深度学习模型可提取抽象特征的优势,有效地降低了运算量,提高了特征参数的鲁棒性;(3)在深度卷积神经网络结构中加入跨层连接支路,使低层残差块可以向高层残差块传递信息,起到抑制梯度消失的作用;(4)依据集成学习多分类器共同决策的思想,基于adaboost算法和类可靠度实现多模式情感识别算法,充分发挥了决策层融合与特征层融合的优点,使整个识别过程更加接近人类情感识别,有利于提升分类的可靠性和效率;(5)由于各强分类器训练集数据的代表性差异,对不同类别数据的分类能力是不同的,通过计算每个强分类器的各情感类别的可靠度值的方式来获得最终识别结果,提高了情感识别的准确率。附图说明图1为本发明实施例提供的一种基于双深度网络的多模式情感信息融合与识别方法的流程图。具体实施方式下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。一种基于双深度网络的多模式情感信息融合与识别方法,如图1所示,包括以下步骤:步骤1、情感信号获取;首先诱发情感,再同步获取相应情感状态下的语音信号和面部表情信号,并将二者绑定存储,获得多个情感样本;所述获取相应情感状态下的语音信号和面部表情信号的具体方法为:利用麦克风接收语音数据后,再通过采样量化获得相应的语音信号;而面部表情信号则通过摄像机拍摄获得;所述的采样量化的采样频率为11.025khz、量化精度为16bit;所述的通过摄像机拍摄获得的每幅面部表情信号图像大小为256×256像素;本实施例中,利用麦克风输入语音数据,然后利用计算机、单片机或dsp芯片等处理单元以11.025khz的采样频率、16bit的量化精度进行采样量化,获得相应的语音信号;本实施例中的面部表情信号则是通过摄像机拍摄,每幅图像大小为256×256像素;步骤2、对每个情感样本的情感信号进行预处理;步骤2-1、语音信号预处理;对获取的情感样本中语音信号进行预处理,包括预加重、分帧加窗和端点检测;所述预加重采用一阶数字预加重滤波器实现,预加重滤波器的系数取值为0.93~0.97;所述分帧加窗为以帧长256点的标准进行分帧,并对分帧后的数据加汉明窗处理;所述端点检测利用基于短时能零积和鉴别信息的语音端点检测法进行;步骤2-2、面部表情信号预处理;对获取的情感样本中面部表情信号,首先进行脸部定位,然后进行图像几何特性归一化处理和图像光学特性归一化处理;所述脸部定位利用肤色模型实现;所述图像几何特性归一化根据左右两眼的坐标值旋转图像实现,以保证人脸方向的一致性;所述图像光学特性的归一化处理先采用直方图均衡化方法对图像灰度做拉伸,以改善图像的对比度,然后对图像像素灰度值进行归一化处理,使标准人脸图像的像素灰度值为0,方差为1,如此可以部分消除光照对识别结果的影响;本发明实施例中,归一化后的图像大小为75×100像素;步骤3、对每个情感样本中的情感特征参数进行提取;步骤3-1、训练深度信念网络,并将预处理后的语音信号送入训练好的深度信念网络来自动提取语音信号中的情感特征;所述深度信念网络包括四个隐含层,每层的每个单元连接到每个相邻层中的每个单元,没有层内连接,即使用多个受限玻尔兹曼机堆叠而成;所述训练深度信念网络的具体方法为:1)训练第一个受限玻尔兹曼机,其联合概率分布由能量函数指定,如下式所示:其中,p(v,h;θ)为第一个受限玻尔兹曼机的联合概率,v为m维的可见层向量,m是可见层的神经元个数,h为n维的隐含层向量,n是隐含层的神经元个数,本实施例中,第一隐含层神经元个数为176个,第二隐含层神经元个数为116个,第三隐含层神经元个数为58个,第四隐含层神经元的个数即情感特征参数个数为20个,θ={a,b,w},w为权重矩阵,b为可见层的偏置向量,a为隐含层的偏置向量,z(θ)为配分函数的归一化常数,如下公式所示:其中,e(v,h;θ)为能量函数,公式为:其中,wij是可见层的第i个神经元和隐含层的第j个神经元之间的对称权值,bi是可见层的第i个神经元的偏置,aj是隐含层的第j个神经元的偏置,vi是可见层向量的第i个元素,hj是隐含层向量的第j个元素;2)训练第二个受限玻尔兹曼机,并将第一个受限玻尔兹曼机的隐含层作为第二个受限玻尔兹曼机的可见层,并依此添加任意多层继续扩展,其中每个新的受限玻尔兹曼机对前一个受限玻尔兹曼机的样本建模;步骤3-2、用深度卷积神经网络自动提取情感样本中的面部表情特征;步骤3-2-1、建立深度卷积神经网络结构;所述深度卷积神经网络结构包括卷积层、最大池化层、第一组残差块、第二组残差块、平均池化层和全连接层;并分别在第一组残差块的始端与末端之间加入跨层连接支路,第二组残差块的始端与末端之间加入跨层连接支路;所述第一组残差块包括两种类型的残差块,分别是resnet-34和resnet-50;第二组残差块包括三种类型的残差块,分别是resnet-34、resnet-50和resnet-101;本实施例中,深度卷积神经网络首先经过卷积层,卷积核大小为7×7,步长为2,再经过最大池化层,卷积核大小为3×3,步长为2;其次经过第一组残差块,该组残差块包含两种类型的残差块,分别是resnet-34和resnet-50,此两种残差块数量均为3;接着经过第二组残差块,该组残差块包含三种类型的残差块,分别是resnet-34、resnet-50和resnet-101,此三种残差块数量均为2;并分别在第一组残差块的始端与末端之间加入跨层连接支路,第二组残差块的始端与末端之间加入跨层连接支路;最后经过平均池化层和全连接层;步骤3-2-2、采用梯度下降算法训练建立好的深度卷积神经网络;步骤3-2-3、将预处理后的面部表情信号作为训练好的深度卷积神经网络的输入,其输出即为面部表情特征参数;步骤4、将每个情感样本中的情感特征参数进行组合,获得情感样本的组合特征向量;将用深度信念网络提取的语音情感特征和用深度卷积神经网络自动提取的面部表情特征顺序组合起来获得情感样本的组合特征向量,其中前20个特征为用深度信念网络提取的新的语音情感特征,后32个特征为用深度卷积神经网络提取的新的面部表情特征;步骤5、基于adaboost算法和类可靠度实现情感识别;步骤5-1、将获得的所有情感样本的组合特征向量u1,u2,…,ur,ur+1,ur+2,…,u2r,u2r+1,u2r+2,…,u3r构成一个集合称为组合特征向量集,本实施例中,r取值为6000;并将该组合特征向量集等分成三份,分别作为训练样本集、可靠度预测样本集和测试样本集,其中u1,u2,…,ur为训练样本集中元素,ur+1,ur+2,…,u2r为可靠度预测样本集中元素,u2r+1,u2r+2,…,u3r为测试样本集中元素;步骤5-2、通过对训练样本集做有放回的抽样n′(n′的取值不要超过训练样本集中向量的数量即可)次,获得若干个子训练样本集;本实施例中,首先获得子训练样本集s1,s1中包含3000个特征向量,而且是随机获得的;然后依此继续抽取样本获得子训练样本集s2,…,sm′,即获得m′个子训练样本集;本实施例中,n′取值为3000,m′取值为25;步骤5-3、利用adaboost算法对各子训练样本集分别进行训练,获得每个子训练样本集上的强分类器;本实施例中利用adaboost算法对各子训练样本集进行训练时,使用的弱分类器是三层小波神经网络,输入层有52个神经元,代表52个情感特征参数(20个语音情感特征参数加上32个面部表情特征参数),输出层有6个神经元,代表6种人类基本情感,即高兴、愤怒、惊奇、悲伤、恐惧和中性;步骤5-4、用可靠度预测样本集中的数据作为各强分类器h′t,t=1,2,…,m′的测试样本来预测各强分类器输出各情感类别的正确率,作为各情感类别的可靠度值crkt,k=1,2,…,6,k表示6种人类基本情感,即k=1代表高兴,k=2代表愤怒,k=3代表惊奇,k=4代表悲伤,k=5代表恐惧和k=6代表中性情感;步骤5-5、将待测样本x送入各强分类器进行识别,每个强分类器对每类情感均产生一个可能性比率,其中,pkt表示第t个强分类器对第k个情感类别产生的可能性比率。将各强分类器输出的每类情感的可靠度值与可能性比率作乘积,即crkt×pkt,然后将各强分类器类别相同的乘积值累加,将累加值最大的类别作为最终的情感识别结果,即通过下式获得最终情感识别结果:本发明实施例中,为证明本发明方法的情感识别效果,将单模式条件下的情感识别结果与本发明多模式条件下的情感识别结果进行对比。本实施例中,训练样本集、,可靠度预测样本集和测试样本集均包含每种情感的1000条语句。在单模式条件下,仅通过语音信号进行情感识别的情感识别正确率如表1所示,仅通过面部表情信号进行情感识别的情感识别正确率如表2所示;本发明方法的多模式情感识别方法的情感识别正确率如表3所示。表1仅通过语音信号进行情感识别的情感识别正确率情感类别高兴愤怒惊奇悲伤恐惧中性高兴90%1%2%2%5%0愤怒3%89%06%1%1%惊奇4%6%83%5%1%1%悲伤2%2%4%86%3%3%恐惧6%1%02%84%7%中性4%5%01%6%84%表2仅通过面部表情信号进行情感识别的情感识别正确率情感类别高兴愤怒惊奇悲伤恐惧中性高兴80%8%1%07%4%愤怒4%93%2%1%00惊奇3%8%80%7%1%1%悲伤1%6%8%82%2%1%恐惧1%2%3%15%76%3%中性05%1%10%3%81%表3本发明方法的多模式情感识别方法的情感识别正确率情感类别高兴愤怒惊奇悲伤恐惧中性高兴96%01%01%2%愤怒1%99%0000惊奇2%095%02%1%悲伤01%095%04%恐惧001%099%0中性01%04%1%94%由表1和表2可知,仅通过语音信号进行情感识别的平均识别正确率是86%(该平均识别正确率86%是通过表1中高兴的识别正确率90%、愤怒的识别正确率89%、惊奇的识别正确率83%、悲伤的识别正确率86%、恐惧的识别正确率84%和中性的识别正确率84%求和后取平均值得到的,即86%=(90%+89%+83%+86%+84%+84%)/6);仅通过面部表情信号进行情感识别的平均识别正确率是82%。因此,单纯依靠语音信号或面部表情信号进行识别在实际应用中会遇到一定的困难,因为人类是通过多模式的方式表达情感信息的,所以研究多模式情感识别的方法十分必要。从表3可以看出,通过本发明方法中的多模式情感识别方法进行情感识别的识别正确率达到了96.3%,明显有所提高,因此不同模式信息的融合是多模式情感识别研究的瓶颈问题,它直接关系到情感识别的准确性。本发明方法充分发挥了决策层融合与特征层融合的优点,整个融合过程更加接近人类情感识别,从而提高了情感识别的平均正确率。最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明权利要求所限定的范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1