一种基于语音识别的会议管理方法与流程
本发明涉及一种基于语音识别的会议管理方法。
背景技术:
在会议室开会时,会议室内的人员包括会议主持人和参会人员,由会议主持人主持会议的进行,在会议进行中,由会议主持人从参会人员中确定发言人,而且,每一个参会人员面前均设置有麦克风。通常情况下,所有的麦克风均处于打开状态,任何参会人员均能够通过面前的麦克风进行发言,首先,全部麦克风均处于打开状态,然而一般情况下,同一时刻只有一个参会人员发言,而其他的麦克风均处于闲置状态,会造成不必要的电能消耗,而且,全部麦克风均处于打开状态,若同一时刻全部的参会人员同时发言的话,会严重干扰会议的顺利进行,不但会延长会议时间,还可以因出现沟通混乱而出现更加严重的后果。因此,需要会议主持人对会议进程进行管理,但是,会议进程全部由会议主持人进行人为管理的话,效果不佳。
技术实现要素:
本发明的目的在于提供一种基于语音识别的会议管理方法,用于解决会议进程全部由会议主持人进行人为管理的管理效果不佳的问题。
为了解决上述问题,本发明采用以下技术方案:
一种基于语音识别的会议管理方法,包括:
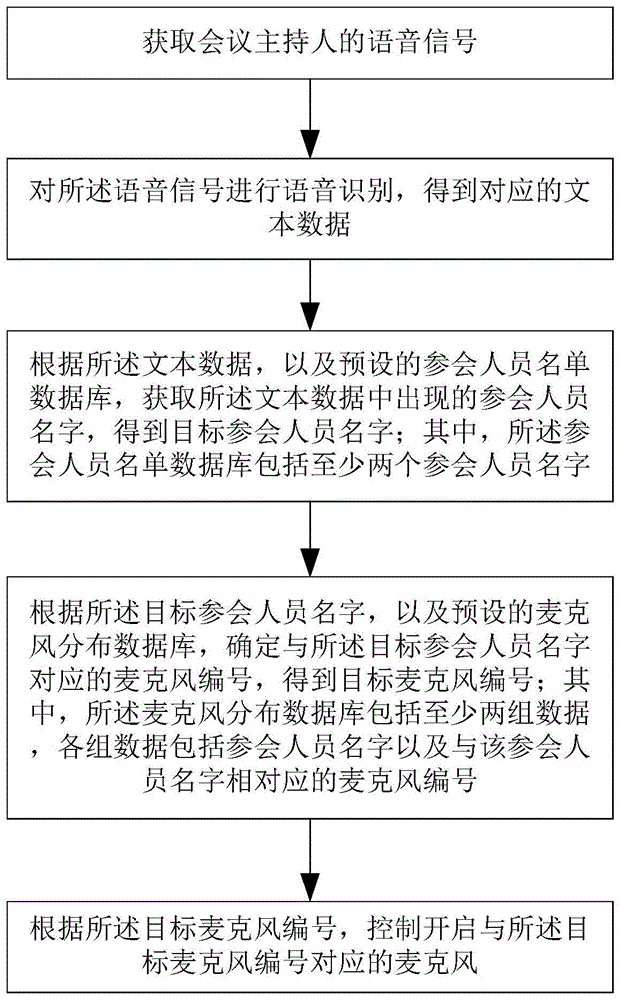
获取会议主持人的语音信号;
对所述语音信号进行语音识别,得到对应的文本数据;
根据所述文本数据,以及预设的参会人员名单数据库,获取所述文本数据中出现的参会人员名字,得到目标参会人员名字;其中,所述参会人员名单数据库包括至少两个参会人员名字;
根据所述目标参会人员名字,以及预设的麦克风分布数据库,确定与所述目标参会人员名字对应的麦克风编号,得到目标麦克风编号;其中,所述麦克风分布数据库包括至少两组数据,各组数据包括参会人员名字以及与该参会人员名字相对应的麦克风编号;
根据所述目标麦克风编号,控制开启与所述目标麦克风编号对应的麦克风。
可选地,所述获取会议主持人的语音信号,包括:
获取会议主持人的语音信号,以及所述语音信号的获取时刻;
根据所述获取时刻,生成会议记录空白模板,所述会议记录空白模板包括会议项目填充区域、发言人名字填充区域和会议记录正文填充区域;
根据所述获取时刻以及预设的会议流程,确定所述获取时刻对应的目标会议项目,并将所述目标会议项目填入所述会议项目填充区域,更新所述会议记录空白模板;
相应地,所述根据所述文本数据,以及预设的参会人员名单数据库,获取所述文本数据中出现的参会人员名字,得到目标参会人员名字之后,所述会议管理方法还包括:
将所述目标参会人员名字填入所述发言人名字填充区域,更新所述会议记录空白模板;
将更新后的所述会议记录空白模板显示给所述会议主持人。
可选地,所述根据所述目标麦克风编号,控制开启与所述目标麦克风编号对应的麦克风之后,所述会议管理方法还包括:
根据所述目标麦克风编号,以及预设的位置坐标数据库,确定与所述目标麦克风编号相对应的目标位置坐标;其中,所述位置坐标数据库包括至少两个麦克风编号,以及与各麦克风编号相对应的位置坐标;
根据所述目标位置坐标向摄像机输出控制指令,所述控制指令用于指示所述摄像机朝向所述目标位置坐标进行图像采集。
可选地,所述语音信号进行语音识别,得到对应的文本数据,包括:
在预设的语音坐标系内生成所述语音信号的语音波形图;
基于语音活性检测算法,从所述语音波形图中划分得到至少两个有效语音段;
通过语音特征识别算法提取各个所述有效语音段对应的语音特征曲线;
从预设的语料库内提取各个候选字符关联的标准特征曲线;
在预设的特征坐标上绘制所述标准特征曲线以及所述语音特征曲线,并计算所述标准特征曲线以及所述语音特征曲线之间相交区域的差异面积;
若任一所述候选字符的所述差异面积小于预设面积差异阈值,则识别所述候选字符为对应有效语音段包含的字符信息;
基于各个有效语音段在所述语音波形图的次序,依次组合各个所述字符信息,生成所述文字数据。
本发明的有益效果为:对会议主持人的语音信号进行语音识别,得到对应的文本数据,根据预设的会议人员数据库确定该文本数据中包含的参会人员名字,就需要该目标参会人员名字对应的参会人员进行发言,而且,每一个参会人员名字对应一个麦克风,每一个麦克风均有特定的编号,那么,根据得到的目标参会人员名字,以及预设的麦克风分布数据库,就能够确定与该目标参会人员名字对应的麦克风编号,得到目标麦克风编号,最后根据目标麦克风编号,控制开启与目标麦克风编号对应的麦克风,即控制开启需要进行发言的参会人员面前的麦克风。该会议管理方法根据采集到的会议主持人的语音信号进行控制和管理,无需会议主持人全程进行人为管理,提升管理效率;只有需要参会人员发言时才控制该参会人员对应的麦克风开启,其他的麦克风处于关闭状态,降低了电能消耗,而且,也能够避免因全部麦克风均处于开启状态而出现同一时刻全部参会人员同时发言的情况,进而避免因这种情况导致会议无法顺利进行,无需延长会议时间,不会因上述情况造成沟通混乱,进而避免出现更加严重的后果。因此,该会议管理办法通过自动控制的方式,能够提升会议管理的效果。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍:
图1是一种基于语音识别的会议管理方法的流程示意图。
具体实施方式
本实施例提供一种基于语音识别的会议管理方法,该会议管理方法适用于会议室,该会议管理方法的执行主体可以为会议室中的计算机设备或者服务器设备,本实施例以计算机设备为例。在会议室中专门设置有一个会议主持人座位,或者定义某一个位置是会议主持人座位,主持会议的会议主持人坐在该座位,该座位设置有一个麦克风,在整个会议过程中,由于会议主持人需要主持会议,因此,该麦克风在整个会议过程中一直处于开启状态。而会议室中设置有至少两个参会人员座位,参加会议的参会人员坐在对应的参会人员座位,本实施例中,每一个参会人员的座位是固定的,不能够更换,即参会人员的座位与参会人员之间是一一对应的。每一个参会人员的座位均设置有麦克风,用于参会人员发言,本实施例中,在参会人员坐在对应的座位时,麦克风处于参会人员的面前。会议主持人座位的麦克风与各参会人员座位的麦克风均与计算机设备通信连接。当然,会议室中还可以设置有扩音器以及大屏幕等,这一部分属于常规技术,不再赘述。需要说明的是,本实施例中,参会人员不包含会议主持人。
如图1所示,该会议管理方法包括以下步骤:
获取会议主持人的语音信号:
会议主持人说话时,处于会议主持人座位的麦克风采集会议主持人的语音信号,并将采集到的语音信号输出给计算机设备,计算机设备获取会议主持人的语音信号。
本实施例中,为了使会议主持人对整个会议进行记录,对于获取会议主持人的语音信号这一步骤,以下给出一种具体的实现过程:
(1)获取会议主持人的语音信号,以及该语音信号的获取时刻。在获取会议主持人的语音信号的同时,还获取该语音信号的获取时刻,即会议主持人发出该语音信号的发出时刻。
(2)根据获取时刻,生成会议记录空白模板,该会议记录空白模板包括会议项目填充区域、发言人名字填充区域和会议记录正文填充区域。在得到获取时刻之后,计算机设备根据该获取时刻,生成会议记录空白模板,该会议记录空白模板是初始的会议记录模板,后续得到的相关数据信息能够填入到该会议记录模板中,以进行会议记录。会议记录空白模板包括会议项目填充区域、发言人名字填充区域和会议记录正文填充区域。其中,会议项目填充区域用于填充会议项目,发言人名字填充区域用于填充发言人的名字,会议记录正文填充区域用于填充会议记录正文。表1给出了会议记录空白模板的一种具体模板结构,其中,a区域为会议项目填充区域,b区域为发言人名字填充区域,c区域为会议记录正文填充区域。
表1
(3)根据获取时刻以及预设的会议流程,确定获取时刻对应的目标会议项目,并将目标会议项目填入会议项目填充区域,更新会议记录空白模板。其中,预设有一个会议流程,包括至少两个会议时间段,以及各会议时间段对应的会议进程(即会议项目),比如:9:00-10:00的会议项目为总经理发言,10:00-11:00的会议项目为部门经理发言,11:00-12:00的会议项目为员工代表发言。那么,根据获取时刻以及预设的会议流程,就能够确定获取时刻对应的目标会议项目,比如:若获取时刻为9:35,结合预设的会议流程,就能够确定获取时刻对应的目标会议项目为总经理发言。然后,将目标会议项目填入会议项目填充区域(即表1的a区域),更新会议记录空白模板。
对所述语音信号进行语音识别,得到对应的文本数据:
计算机设备对获取到的语音信号进行语音识别,得到对应的文本数据。对语音信号进行语音识别,得到文本数据属于常规技术手段,本实施例给出一种具体实现过程,当然,除了该具体实现过程之外,本申请还可以采用现有的其他实现过程。本实施例给出的具体实现过程步骤包括:
(1)在预设的语音坐标系内生成语音信号的语音波形图。该语音坐标系的纵坐标可以为语音振幅,横坐标可以为采集时间,从而生成一个基于时域的语音波形图。另外,在生成语音波形图之前,可以对语音信号进行滤波,过滤得到不包含环境噪声的语音信号,并可以对过滤噪声后的语音信号进行平缓处理,从而可以过滤掉无效的噪声频段。
(2)基于语音活性检测算法,从语音波形图中划分得到至少两个有效语音段。其中,有效语音段是指包含说话内容的语音段,相应地,无效语音段是指不包含说话内容的语音段。可以设置语音启动幅值以及语音结束幅值,语音启动幅值的数值大于语音结束幅值的数值,即有效语音段的启动要求高于有效语音段的结束要求。由于会议主持人在说话的开始时间,往往音量音调较高,此时对应的语音幅值的数值较高;而在说话过程中,部分字符存在弱音或轻音,此时不应该识别说话中断,因此,需要适当降低语音结束幅值,避免误识别的情况发生。因此,根据语音启动幅值以及语音结束幅值,对语音波形图进行有效语音识别,从而划分得到至少两个有效语音段,其中,该有效语音段的启动时刻对应的幅值大于或等于语音启动幅值,且结束时刻对应的幅值小于或等于语音结束幅值。应当理解,除了上述有效语音段的划分实现过程之外,还可以采用其他的实现过程。
(3)通过语音特征识别算法提取各个有效语音段对应的语音特征曲线。本实施例中,该语音特征识别算法可以为傅里叶算法,将有效语音段从时域曲线转换为频域波形,得到各个有效语音段对应的语音特征曲线。另外,若转换得到的频域波形为离散波形,则可以通过线性拟合的方式,对离散波形进行线性拟合,输出对应的语音特征曲线。
(4)从预设的语料库内提取各个候选字符关联的标准特征曲线。预设有一个语料库,该语料库内包含有可以识别的所有候选字符,每个候选字符对应一个关联的标准特征曲线。该标准特征曲线具体可以通过至少一种语种的标准读音的语音信号转换得到。
(5)在预设的特征坐标上绘制标准特征曲线以及语音特征曲线,并计算标准特征曲线以及语音特征曲线之间相交区域的差异面积。本实施例中,在同一特征坐标系上绘制标准特征曲线以及语音特征曲线,从而能够快速比对两个曲线之间的差异度,其中差异度的计算主要通过两个曲线之间的相交面积(即相交区域的差异面积)的大小进行判断:若该相交面积越大,则表示两个曲线之间的差异度越大,则表示该有效语音段内不包含该候选字符的概率越高;反之,若相交面积越小,则表示两个曲线之间的差异度越小,则表示该有效语音段包含该候选字符的概率越高。进一步地,为了提高识别的准确率,对语音特征曲线进行归一化处理,根据有效语音段的语音波形图的峰值变化,将语音波形图划分为多个不同的字符段,一个字符段包含至少一个峰值,从而能够确保每个字符段对应一个字符。根据字符段的长度在时域对字符段进行归一化,即将该字符段的时长设置为预设的标准时长,并且根据预设的最大振幅,等比例调整字符段的振幅值,并对归一化后的字符段进行标准特征曲线的转换,得到归一化后的字符段对应的语音特征曲线。
(6)若任一候选字符的差异面积小于预设面积差异阈值,则识别候选字符为对应有效语音段包含的字符信息。若检测到任一候选字符的标准特征曲线与语音特征曲线之间相交区域的差异面积小于差异阈值,则可以识别该有效语音段的说话内容中包含该候选字符,并根据各个识别得到的候选字符在有效语音段内出现位置,确定各个识别得到的候选字符的次序,并基于该次序进行合并,得到字符信息。通过将各个候选字符的标准特征曲线与语音特征曲线进行比对,从而识别出有效语音段内包含的字符信息,提高了字符信息生成的准确性。
(7)基于各个有效语音段在语音波形图的次序,依次组合各个字符信息,生成文字数据。具体地,可以根据上一有效语音段的末字符与下一有效语音段的首字符之间的关联度,以及两个语音段之间的间隔时长,确定连接两个字符信息所使用的标点符号,通过识别各个字符信息以及连接所用的标点符号,生成文字信息,提高了文字信息的可读性。本实施例中,将语音信号划分为多个语音段,从而能够减少每次语音识别的数据量,同时兼顾了语音识别的准确率以及计算量。
根据所述文本数据,以及预设的参会人员名单数据库,获取所述文本数据中出现的参会人员名字,得到目标参会人员名字;其中,所述参会人员名单数据库包括至少两个参会人员名字:
计算机设备中预设有一个参会人员名单数据库,该参会人员名单数据库包括至少两个参会人员名字,本实施例中,该参会人员名单数据库包括参会的所有参会人员的名字。该参会人员名单数据库的各个参会人员名字是在会议之前录入的,作为一个具体实施方式,在会议开始之前,由会议主持人将各个参会人员名字录入到计算机设备中,构成参会人员名单数据库。
根据文本数据以及参会人员名单数据库,获取文本数据中出现的参会人员名字,本实施例给出以下两种具体实现过程:一、将参会人员名单数据库中的各个参会人员名字分别与文本数据进行比对,确定各个参会人员名字是否存在于文本数据中;二、将文本数据输入到参会人员名单数据库,得到文本数据中出现的参会人员名字。应当理解,本实施例不局限于上述实现过程。
将文本数据中出现的参会人员名字作为目标参会人员名字。
当会议主持人需要参会人员发言时,就会在说出的语音信号中体现参会人员的名字,那么,文本数据中出现的参会人员名字就是需要发言的参会人员名字。比如:文本数据为“xxxxx张三发言”,参会人员名单数据库中包含参会人员名字张三,那么,文本数据中出现的参会人员名字张三就是需要发言的参会人员名字。
应当注意,通常情况下同一时刻只需要一个参会人员发言,因此,会议主持人发出的语音信号中通常只出现一个参会人员名字。因此,文本数据为只包含一个参会人员名字的文本数据。当然,作为特殊情况,若同一时刻需要多个(比如两个)参会人员同时发言,会议主持人发出的语音信号中可以出现多个参会人员名字。当然,这种多个参会人员同时发言的情况极为少见,可以理解为不存在这种情况。
为了进一步更新会议记录空白模板,并将更新后的会议记录空白模板输出给会议主持人,由会议主持人进行会议记录。在得到目标参会人员名字之后,该会议管理方法还包括如下步骤:将得到的目标参会人员名字填入发言人名字填充区域(即表1的b区域),更新会议记录空白模板;然后,将更新后的会议记录空白模板显示给会议主持人,相应地,会议主持人的座位还配设有显示屏或者触摸屏,将更新后的会议记录空白模板由显示屏或者触摸屏进行显示,便于会议主持人进行会议记录,具体是在会议记录正文填充区域(即表1中的c区域)通过键盘手动填入会议记录。
根据所述目标参会人员名字,以及预设的麦克风分布数据库,确定与所述目标参会人员名字对应的麦克风编号,得到目标麦克风编号;其中,所述麦克风分布数据库包括至少两组数据,各组数据包括参会人员名字以及与该参会人员名字相对应的麦克风编号:
计算机设备中预设有一个麦克风分布数据库,该麦克风分布数据库包括至少两组数据,本实施例中,若参会人员有n个,则该麦克风分布数据库包括n组数据,各个参会人员与各组数据一一对应。对于任意一组数据,该组数据包括一个参会人员名字以及与该参会人员名字相对应的麦克风编号。与该参会人员名字相对应的麦克风编号是指:该参会人员面前的麦克风的编号。
将目标参会人员名字输入到麦克风分布数据库,就能够得到该目标参会人员对应的麦克风编号,该麦克风编号为目标麦克风编号。
根据所述目标麦克风编号,控制开启与所述目标麦克风编号对应的麦克风:
计算机设备根据得到的目标麦克风编号,控制开启与该目标麦克风编号对应的麦克风,即控制开启目标参会人员面前的麦克风(控制开启可以指控制麦克风上电)。那么,该目标参会人员就可以通过面前的麦克风进行发言。
应当注意,当出现上文中的极特殊情况时,即当同时需要两个或者更多参会人员发言时,文本数据中就出现多个参会人员名字,最终能够确定多个目标麦克风编号,那么,控制开启与这些目标麦克风编号对应的麦克风,即控制开启这些目标参会人员面前的麦克风,这些目标参会人员就能够同时发言。
本实施例中,为了在目标参会人员发言时,能够获取到目标参会人员的图像,使得会议室中的大屏幕或者会议主持人的显示屏能够实时显示目标参会人员的图像,该会议管理方法还包括以下步骤:
根据所述目标麦克风编号,以及预设的位置坐标数据库,确定与所述目标麦克风编号相对应的目标位置坐标;其中,所述位置坐标数据库包括至少两个麦克风编号,以及与各麦克风编号相对应的位置坐标:
计算机设备中还预设有一个位置坐标数据库,该位置坐标数据库包括至少两个麦克风编号,以及与各麦克风编号相对应的位置坐标。本实施例中,该位置坐标数据库包括n个麦克风编号(n为参会人员个数),位置坐标为麦克风编号对应的麦克风所在位置在会议室中的位置坐标,也可以理解为参会人员座位在会议室中的位置坐标。以会议室的地面作为基础建立二维坐标系,以会议室的地面上的某一个点作为二维坐标原点建立二维坐标系。本实施例中,会议室的地面是长方形,设定该长方形的一个角为二维坐标原点,该角所在的两个边分别设定为x轴和y轴,那么,各参会人员的麦克风位置(即参会人员座位)就处于该二维坐标系内,就能够转换为该二维坐标系内的坐标。
那么,将目标麦克风编号输入到位置坐标数据库,得到与该目标麦克风编号相对应的位置坐标,该位置坐标为目标位置坐标。
根据所述目标位置坐标向摄像机输出控制指令,所述控制指令用于指示所述摄像机朝向所述目标位置坐标进行图像采集:
摄像机固定在会议室的某一个位置,而且摄像机的拍摄角度是可变的,通过驱动电机带动摄像机,使得摄像机可以上下左右转动。计算机设备与该驱动电机电连接,实现驱动电机的控制。
各位置坐标与摄像机的拍摄角度之间一一对应,不同的位置坐标就有不同的摄像机拍摄角度。计算机设备中设置有各个位置坐标与摄像机的拍摄角度之间的对应关系。那么,计算机设备根据得到的目标位置坐标确定对应的拍摄角度,根据确定的拍摄角度向摄像机输出控制指令,该控制指令用于指示摄像机动作,使得动作后的拍摄角度为上述确定得到的拍摄角度,使得摄像机朝向目标位置坐标进行图像采集。采集到的图像可以输出到会议室中的大屏幕上,也可以输出到会议主持人的显示屏上。
上述实施例仅以一种具体的实施方式说明本发明的技术方案,任何对本发明进行的等同替换及不脱离本发明精神和范围的修改或局部替换,其均应涵盖在本发明权利要求保护的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!