一种基于强化学习的降噪方法与流程
本发明涉及噪声控制技术领域,尤其涉及一种基于强化学习的降噪方法。
背景技术:
噪声是人们生产生活中常见的污染源,方方面面影响人们的工作效率和生活质量,长期处于噪声环境中,会诱发人体的多种慢性疾病,大幅度噪声振动还会破坏建筑物的结构强度。常用的隔音,吸声,降噪等手段主要对高频噪声有效,低频噪声波长长,衍射效果强,主要采用主动降噪方式消噪。由于大声学量情形下,噪声源辐射声波的会产生波形畸变以及诱发高次非线性谐波,并且在声波传播介质中含有的非线性因素,使得降噪系统需要具备较强的非线性噪声表达能力,进一步提升降噪性能,这是目前降噪系统所不具备的。
技术实现要素:
本发明要解决的技术问题是针对上述现有技术的不足,提供一种基于强化学习的降噪方法,基于机器学习领域中的强化学习算法实现自适应主动降噪。
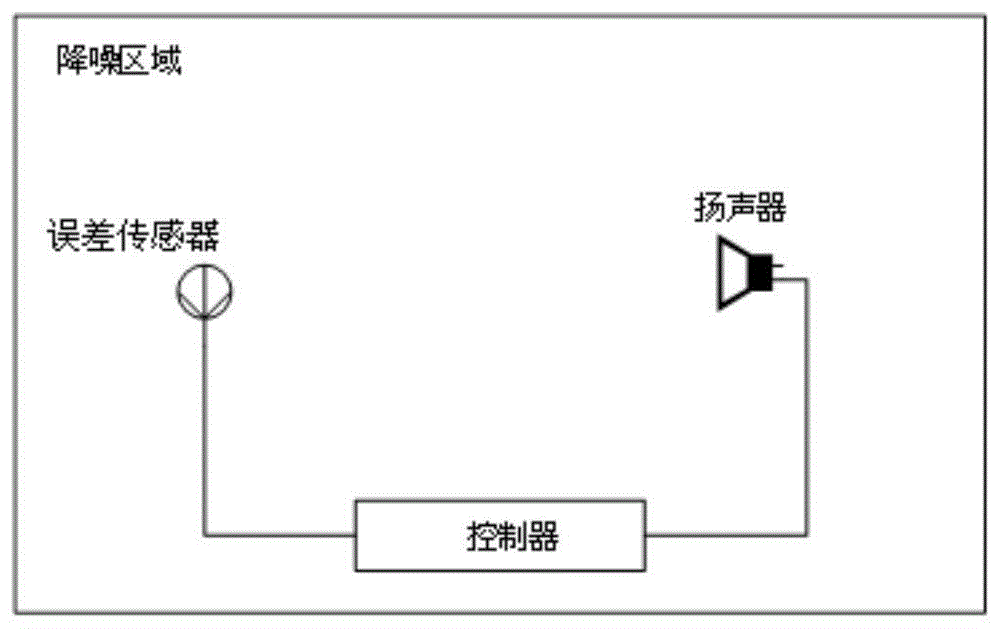
为解决上述技术问题,本发明所采取的技术方案是:一种基于强化学习的降噪方法,基于现有的主动降噪系统实现;所述主动降噪系统包括布置在目标降噪区域的误差传感器,扬声器和控制器;误差传感器以一定频率采集目标降噪空间中的残余噪声信号;扬声器用于辐射次级声音信号,依据主动降噪原理,抵消空间中的噪声信号;控制器接收并分析误差传感器采集的目标降噪区域的残余噪声信号,并通过降噪策略控制扬声器的辐射声信号频率,相位和强度;该方法首先通过误差传感器采集到的残余噪声声压值与控制器控制次级扬声器发出抵消声信号的关系建立降噪策略函数;然后根据强化学习方法,依据降噪奖励函数对降噪过程进行建模,按照降噪策略执行降噪后,将后续各个时刻依据奖励函数获得的累计奖励值最大化作为建模降噪策略的依据;建立关于累计奖励值的价值函数,并迭代更新价值函数,使当前动作的价值函数等于目标函数,得到最优价值函数,进一步得到最大化的累计奖励,并确定此时的降噪策略为最优;控制器按照当前最优降噪策略控制次级扬声器进行降噪。
所述基于强化学习的降噪方法的具体过程为:
步骤1、通过训练、学习得到误差传感器采集到的残余噪声声压值与控制器控制次级扬声器发出抵消声信号的关系,确定降噪策略,用函数π表示,如下公式所示:
at=π(st)(1)
该函数的输入为当前误差传感器采集到的目标区域内噪声声压值,表示当前时刻t的环境st,输出为要执行的动作at,即控制器对次级扬声器辐射声信号的控制;
步骤2、建立奖励函数r,奖励函数的设置决定降噪过程执行的速度和算法收敛速度,即当前环境st时,控制器执行动作at后的下一时刻的环境信息为st+1,此时st+1值小于st,表示该动作at对降噪有效果,则获得奖励rt=st-st+1;
步骤3、将降噪系统按照降噪策略执行降噪后,后续各个时刻获得的累计奖励值最大化作为建模降噪策略π的依据;
所述累计奖励值的表达式为:
其中,ut为t时刻的累计奖励值,γ为折扣因子,为[0,1]区间内取值,rt+n表示执行完动作at后,后续n个时刻由于控制器做出at动作得到的奖励;
步骤4、对累计奖励值ut函数求期望得到价值函数q,如下公式所示:
e[ut]=q(st,at,wt)
其中,e[ut]表示在t时刻的环境st状态下,按照降噪策略π执行动作at,累计奖励值ui的数学期望,wt为价值函数的模型参数;
则在t+1时刻的环境st+1状态下,按照降噪策略π执行动作at+1,累计的奖励ut+1的数学期望,如下公式所示:
e[ut+1]=q(st+1,at+1,wt+1)
根据累计奖励值ut的表达式(2),则t时刻环境st下执行的降噪动作at获得的价值函数q约等于该时刻得到奖励rt加上下一时刻的价值函数,如下公式所示:
q(st,at,wt)≈rt+γq(st+1,at+1,wt+1)
定义目标函数:yt=rt+γmax(q(st+1,at+1,wt)),为当前t时刻获得的奖励与下一时刻所有价值函数中的最大值;
步骤5、迭代更新价值函数,使当前动作的价值函数等于目标函数,此时强化学习模型稳定并能够得到最优价值函数qbest,进一步得到最大化的累计奖励utmax,并确定此时的降噪策略π为最优;
步骤6、控制器按照当前最优降噪策略控制次级扬声器进行降噪直至误差传感器采集到环境噪声低于40db。
所述价值函数的更新过程为:
(1)、记录当前t时刻的误差传感器采集的降噪区域声压值,即当前环境st,并记录控制器控制次级扬声器的动作at;
(2)、计算t时刻环境st,动作at的价值函数qt=q(st,at,wt),wt初始值定义为0;
(3)、对价值函数q(st,at,wt)关于模型参数wt求微分
(4)、得到对t时刻的动作at的奖励rt;同时,获取下一时刻t+1的降噪区域的声压值作为环境st+1,控制器准备执行动作at+1;
(5)、计算目标函数yt=rt+γq(st+1,at+1,wt);
(6)、采用梯度下降法更新价值函数的模型参数wt+1=wt-α(qt-yt)dt,α为取值在0~1的系数常数;
(7)、重复上述步骤(2)-(6),更新价值函数,直至当前动作的价值函数等于目标函数时停止价值函数更新。
采用上述技术方案所产生的有益效果在于:本发明提供的一种基于强化学习的降噪方法,针对环境空间中噪声源辐射噪声的特点,降噪区域采用全方位声学传感器,采集空间中混合的噪声信号;降噪控制器持续降噪,直至环境噪声低于40db;采用的降噪策略为t+1时刻声传感器采集到的残余噪声信号强度低于当前t时刻采集到的噪声信号强度时,即给与模型奖励,则模型会按照累计奖励最大的方向执行降噪动作,并且不依赖降噪环境的状态转移概率,直接通过生成随机信号进行计算,使该降噪系统及方法具有更好的噪声跟踪性能和声场适应能力,有效解决大声学量噪声源辐射噪声信号中含有非线性畸变和高次谐波,以及声传播介质中含非线性因素,导致传统降噪控制器降噪性能不佳的问题,具有更强的泛化能力及更广泛的适用范围。该降噪系统省掉工程中常用的前馈控制系统结构中的噪声源参考传感器部分,布放更灵活,结构更简单,可应用于多种降噪场合。
附图说明
图1为本发明实施例提供的主动降噪系统的结构框图;
图2为本发明实施例提供的基于强化学习方法进行主动降噪控制的原理示意图;
图3为本发明实施例提供的一种基于强化学习的降噪方法的流程图。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
一种基于强化学习的降噪方法,基于现有的主动降噪系统实现;所述主动降噪系统如图1所示,包括布置在目标降噪区域的误差传感器,扬声器和控制器;误差传感器以一定频率采集目标降噪空间中的残余噪声信号;扬声器用于辐射次级声音信号,依据主动降噪原理,抵消空间中的噪声信号;控制器接收并分析误差传感器采集的目标降噪区域的残余噪声信号,并通过降噪策略控制扬声器的辐射声信号频率,相位和强度;该方法首先通过误差传感器采集到的残余噪声声压值与控制器控制次级扬声器发出抵消声信号的关系建立降噪策略函数;然后根据强化学习方法,依据降噪奖励函数对降噪过程进行建模,按照降噪策略执行降噪后,将后续各个时刻依据奖励函数获得的累计奖励值最大化作为建模降噪策略的依据;建立关于累计奖励值的价值函数,并迭代更新价值函数,使当前动作的价值函数等于目标函数,得到最优价值函数,进一步得到最大化的累计奖励,并确定此时的降噪策略为最优;控制器按照当前最优降噪策略控制次级扬声器进行降噪。
强化学习(reinforcementlearning),又称再励学习、评价学习,是一种重要的机器学习方法,在智能控制机器人及分析预测等领域有许多应用。强化学习包括四个元素,智能体(agent)、环境状态(environmentstate)、行动(action)和奖励(reward);强化学习解决的问题是,针对一个具体问题得到一个最优的策略(policy),使得在该策略下获得的奖励最大。所谓的策略其实就是一系列动作,强化学习的目标就是获得最多的累计奖励。本实施例中,基于强化学习方法进行主动降噪控制的原理如图2所示。
本实施例中,基于强化学习的降噪方法的具体过程如图3所示,具体为:
步骤1、通过训练、学习得到误差传感器采集到的残余噪声声压值与控制器控制次级扬声器发出抵消声信号的关系,确定降噪策略,用函数π表示,如下公式所示:
at=π(st)(1)
该函数的输入为当前误差传感器采集到的目标区域内噪声声压值,表示当前时刻t的环境st,输出为要执行的动作at,即控制器对次级扬声器辐射声信号的控制;降噪策略的目标是降噪区域内误差传感器采集的残余噪声声压级最小,强化学习的目标是得到最优的降噪策略函数控制次级扬声器达到降噪目标;
步骤2、建立奖励函数r,奖励函数的设置决定降噪过程执行的速度和算法收敛速度,即当前环境st时,控制器执行动作at后的下一时刻的环境信息为st+1,此时st+1值小于st,表示该动作at对降噪有效果,则获得奖励rt=st-st+1;
步骤3、因为控制器当前的执行动作at会影响降噪系统后续时刻的状态,所以将降噪系统按照降噪策略执行降噪后,后续各个时刻获得的累计奖励值最大化作为建模降噪策略π的依据;
累计奖励值的表达式为:
其中,ut为t时刻的累计奖励值,γ为折扣因子,为[0,1]区间内取值,rt+n表示执行完动作at后,后续n个时刻由于控制器做出at动作得到的奖励;折扣因子表达的含义为当前动作at对未来时刻可能获得的奖励具有不确定性,未来时刻越远,给当前动作带来的奖励越小。(2)式的推导表明,累计奖励ut等于执行动作at后立刻获得的奖励rt加上下一时刻可能获得的累计奖励ut+1乘以折扣因子。
步骤4、对累计奖励值ut函数求期望得到价值函数q,如下公式所示:
e[ut]=q(st,at,wt)
其中,e[ut]表示在t时刻的环境st状态下,按照降噪策略π执行动作at,累计奖励值ut的数学期望,wt为价值函数的模型参数;
则在t+1时刻的环境st+1状态下,按照降噪策略π执行动作at+1,累计的奖励ut+1的数学期望,如下公式所示:
e[ut+1]=q(st+1,at+1,wt+1)
根据累计奖励值ut的表达式(2),则t时刻环境st下执行的降噪动作at获得的价值函数q约等于该时刻得到奖励rt加上下一时刻的价值函数,如下公式所示:
q(st,at,wt)≈rt+γq(st+1,at+1,wt+1)
定义目标函数:yt=rt+γmax(q(st+1,at+1,wt)),为当前t时刻获得的奖励与下一时刻所有价值函数中的最大值;
步骤5、迭代更新价值函数,使当前动作的价值函数等于目标函数,此时强化学习模型稳定并能够得到最优价值函数qbest,进一步得到最大化的累计奖励utmax,并确定此时的降噪策略π为最优;
步骤6、控制器按照当前最优降噪策略控制次级扬声器进行降噪直至误差传感器采集到环境噪声低于40db。
所述价值函数的更新过程为:
(1)、记录当前t时刻的误差传感器采集的降噪区域声压值,即当前环境st,并记录控制器控制次级扬声器的动作at;
(2)、计算t时刻环境st,动作at的价值函数qt=q(st,at,wt),wt初始值定义为0;
(3)、对价值函数q(st,at,wt)关于模型参数wt求微分
(4)、得到对t时刻的动作at的奖励rt;同时,获取下一时刻t+1的降噪区域的声压值作为环境st+1,控制器准备执行动作at+1;
(5)、计算目标函数yi=rt+γq(st+1,at+1,wt);
(6)、采用梯度下降法更新价值函数的模型参数wt+1=wt-α(qt-yi)dt,α为取值在0~1的系数常数;
(7)、重复上述步骤(2)-(6),更新价值函数,使当前动作的价值函数等于目标函数停止价值函数更新。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明权利要求所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!