基于特征集融合的语音情感识别及评价方法与流程
本发明涉及一种语音情感识别方法,具体涉及一种基于特征集融合的语音情感识别及评价方法。
背景技术:
语音作为情感的载体之一,包含了丰富的情感信息。在过去几十年中语音情感识别的相关研究取得了巨大的进步并在许多不同的研究领域都有着广阔的前景。随着计算机语音识别等技术的成熟以及相关研究不断涌现,语音情感识别开始更多地应用到教育业、娱乐业、通讯业当中,加强对语音情感、情绪的识别成为了下一代人工智能发展的重点,鉴于此开展针对语音情感识别的研究具有较强的理论价值和实用意义。
情感描述方式一般可分为离散和维度两种形式。pad三维空间情感模型是既简单又被广泛使用的维度情感描述模型,其中p代表愉悦度(pleasure-displeasure),表明了个体情感状态的积极或消极特性;a代表激活度(arousal-nonarousal),表明了个体的神经生理激活程度;d代表优势度(dominance-submissiveness),表明了个体对环境和他人的主观控制状态。
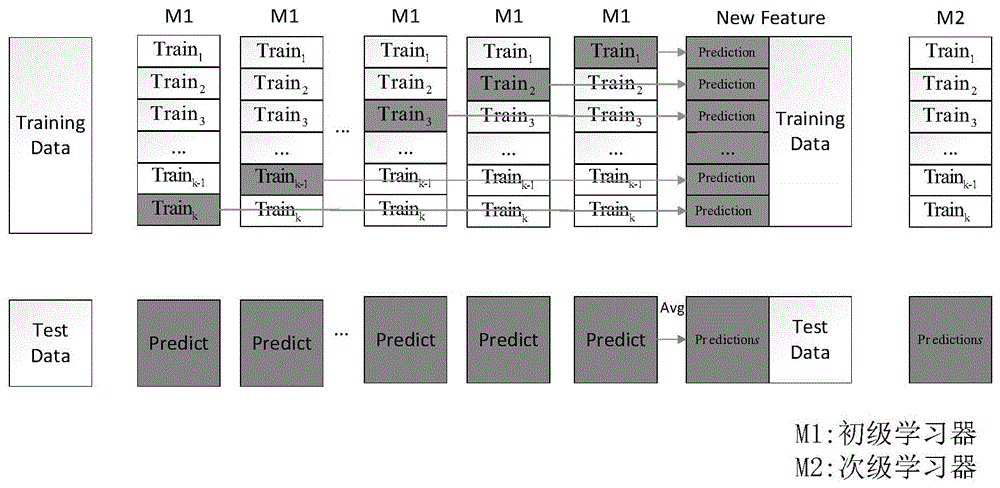
stacking是一种集成学习模型,在stacking方法中,我们把个体学习器叫做初级学习器,用于结合的学习器叫做次级学习器,次级学习器用于训练的数据叫做次级训练集。次级训练集是在训练集上用初级学习器得到的。
技术实现要素:
本发明针对目前语音情感识别中特征集单一、预测结果不精准等问题,提出了一种基于特征集融合的语音情感识别及评价方法。通过opensmile工具包提取is09_emotion、is10_paraling、is11_speaker_state、is12_speaker_trait四种不同的语音情感特征集,基于stacking的初级学习器融合四种不同语音特征集,建立了不同语音情感特征集的关系,并通过stacking的次级学习器建立最终的语音情感识别模型,进而达到更好的情感识别效果。
基于特征集融合的语音情感识别及评价方法。实现包括以下步骤:
步骤一:从语音数据库中读取.wav语音文件,对语音文件预处理后提取n种语音特征集;
步骤二:建立stacking学习模型;
通过初级学习器融合n种语音特征集,并建立stacking学习模型的次级学习器,通过次级学习器对融合后的语音特征集做最终的语音情感识别预测;
将得到的语音特征集切分为训练数据和测试数据,分别为trainingdata、testdata;采用k折交叉验证来切分训练数据得到train1,train2…traink。此时初级学习器要做k次训练和预测。
使用训练数据中的train2,train3…traink做为训练集set1,train1做为验证集,基于训练集set1训练初级学习器,预测得到验证集train1的预测结果val1,同时预测得到测试集test的预测结果test1。
使用训练数据中的train1,train3…traink做为训练集set2,train2做为验证集,基于训练集set2训练初级学习器,预测得到验证集train2的预测结果val2,同时预测得到测试集test的预测结果test2。
同理分别预测得到验证集train3,train4…traink的预测结果val3,val4…valk,同时分别预测得到测试集test的预测结果test3,test4…testk。
将得到的val1,val2…valk进行矩阵拼接,得到1列的val数据。将此val数据作为次级学习器的训练数据。
对test1,test2…testk求取平均值得到testavg,将testavg作为次级学习器的测试数据。
n种语音情感特征的训练数据经过stacking的初级学习器预测后得到n列数据,并将此数据作为次级学习器的训练数据。
n种语音情感特征集的测试数据经过stacking的初级学习器预测后得到n列数据,并将此数据作为次级学习器的测试数据。
将次级学习器的训练数据作为次级学习器的训练数据,经训练后通过次级学习器的测试数据来验证次级学习器的预测结果。
步骤三:建立评价标准,通过stacking学习模型得到的预测结果与真实结果进行计算,得到评价该模型的评价标准;
平均绝对误差(mae)
其中m,yi,
均方差(mse)
其中m,yi,
判定系数(r2)
其中m,yi,
皮尔逊相关系数(pea)
其含义是计算测试集真实值与测试集预测值的相关度,相关系数在[-1,1]之间,pea值越大,表示相关系数越显著。
作为优选,步骤一中提取的语音特征集,具体为:opensmile工具包提取is09_emotion、is10_paraling、is11_speaker_state、is12_speaker_trait四种语音特征集。
本发明相对于现有技术具有的有益效果:
本发明利用opensmile工具包提取is09_emotion、is10_paraling、is11_speaker_state、is12_speaker_trait四种不同的语音情感特征集,采用lightgbm、adaboostregressor作为stacking的初级学习器,初级学习器融合了四种不同语音特征集,建立了不同语音情感特征集的关系,并将岭回归作为stacking的次级学习器,基于融合后特征集训练岭回归模型,建立最终的语音情感识别模型。
附图说明
图1为基于特征集融合的语音情感识别流程图;
图2为stacking实验过程示意图;
图3为emodb语音数据库的平均绝对误差(mae)结果簇状图;
图4为emodb语音数据库均方差(mse)结果簇状图;
图5为emodb语音数据库判定系数(r_2)结果簇状图;
图6为emodb语音数据库皮尔逊相关系数(pcc)结果簇状图;
图7为ravdess语音数据库平均绝对误差(mae)结果簇状图;
图8为ravdess语音数据库均方差(mse)结果簇状图;
图9为ravdess语音数据库判定系数(r_2)结果簇状图;
图10为ravdess语音数据库皮尔逊相关系数(pcc)结果簇状图;
具体实施方式
本次实验选取的语音数据库是emodb和ravdess,它们在语音情感识别中应用广泛。emodb由10位演员对10条语句演绎得到,语音情感包括温和、生气、害怕、高兴、悲伤、厌恶、难过,经过听辨测试后保留男性情感语句233句,女性情感语句302句,共535句语料。ravdess语音数据库中由24位专业演员(12位女性,12位男性)用中性的北美口音述说,语音情感包括平静(温和),快乐(高兴),悲伤(难过),愤怒(生气),恐惧(害怕),惊吓和令人厌恶(厌恶),共1440句语料。
上述2个数据库虽然是离散语音情感数据库,但是根据mehrabian研制的原版pad情绪量表以及中国科学院心理所修订的中文简化版pad情绪量表与基本情感类型的对应关系,可以获得数据库中各情感类型的pad量表值,所以以上2个数据库中语料能够作为本文实验所需的维度情感语音数据,涉及的基本情感类型对应的pad量表值见表2。
表2基本情感类型对应的pad量表值
步骤1、使用opensmile工具包读取语音数据库中.wav语音文件,并分别提取四种语音特征集。
步骤1.1、配置opensmile工具包读取is09_emotion特征集,并读取emodb语音数据库中的每一个.wav语音文件,opensmile工具包自动提取is09_emotion的语音特征并保存在.txt文件,将每个.txt文件中的特征集保存在.csv文件中,得到emodb语音数据库中每一个.wav语音文件的is09_emotion特征集;
步骤1.2、同理配置opensmile工具包分别读取is10_paraling、is11_speaker_state、is12_speaker_trait特征集,得到emodb语音数据库中每一个.wav语音文件的is10_paraling、is11_speaker_state、is12_speaker_trait特征集;
步骤1.3、同上述提取步骤,得到ravdess语音数据库中每一个.wav语音文件的is09_emotion、is10_paraling、is11_speaker_state、is12_speaker_trait特征集;
步骤2、建立stacking学习模型。如图1所示,将lightgbm、adaboostregressor作为stacking的m1(初级学习器,下同),通过m1融合四种语音特征集,并将岭回归作为stacking的m2(次级学习器,下同),通过m2对融合后的语音特征集做最终的语音情感识别预测。如图2所示基于特征集融合的语音情感识别流程图。
lightgbm(lightgradientboostingmachine)是gbdt(gradientboostingdecisiontree,梯度提升迭代决策树)的一种,2015年由微软公司提出。传统gbdt模型在保证速率时往往会导致精度的丢失,同时在分布式处理时,各机器之间的通信损失,也在一定程度上降低了数据的处理效率。
lightgbm摈弃了level-wise(按层生长)的决策树生长算法,而采用了leaf-wise(按叶子生长)算法。level-wise是一种低效的算法,因为它不加区分的对待同一层的叶子,带来了很多没必要的开销,因为实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。leaf-wise每轮迭代都从现有的叶子中找到最大增益的分裂方法,如此循环直至达到给定的最大深度,此方法有效避免了不必要的开销,提高了计算速率。另外,传统gbdt算法中,最耗时的步骤是利用pre-sorted的方式在排好序的特征值上枚举所有可能的特征点,然后找到最优划分点,而lightgbm中使用histogram直方图算法替换了传统的pre-sorted以减少对内存的消耗。
adaboostregressor是adaboost的回归算法。adaboost是一种迭代算法,本身是通过改变数据分布来实现的,它根据每次训练集之中每个样本的分类是否正确,以及上次的总体分类的准确率,来确定每个样本的权值。其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。
岭回归(ridgeregression)实质上是一种改良的最小二乘估计法,它是一种专用于共线性数据分析的有偏估计回归方法。最小二乘法可以简单的求得未知的数据,并使得这些求的数据与实际数据之间误差的平方和为最小。如通过线性函数f(x)=ax+b来拟合d={(x1,y1),(x2,y2)...(xn,yn)}并使得损失函数
步骤2.1、分别将emodb和ravdess语音数据切分训练数据集、测试数据集,分别记为train、test,切分比例为4∶1。如下表3所示。
表3语音数据库切分
步骤2.2、基于emodb语音数据库采用4折交叉验证来切分is09_emotion的训练特征集得到train1,train2,train3,train4。此时lightgbm模型要进行4次训练和预测。
步骤2.3、将训练数据中的train2,train3,train4做为训练集set1,train1做为验证集,基于训练集set1训练lightgbm模型,预测得到验证集train1的结果val1,同时预测得到测试集test的结果test1。
步骤2.4、将训练数据中的train1,train3,train4做为训练集set2,train2做为验证集,基于训练集set2训练lightgbm模型,预测得到验证集train2的结果val2,同时预测得到测试集test的结果test2。
步骤2.5、同理预测得到验证集train3,train4的结果val3,val4,同时每次预测得到测试集test的结果test3,test4。
步骤2.6、将得到的val1,val2val3,val4进行矩阵拼接,得到is09_emotion特征集的融合前训练特征集vallgbm-09=[val1,val2val3,val4]t,同理基于adaboostregressor模型要进行4次训练和预测,得到is09_emotion特征集的融合前训练特征集valad-09。将此vallgbm-09、valad-09数据作为m2的训练数据。
步骤2.7、对test1,test2,test3,test4求平均值,得到融合前测试特征集testlgbm-avg-09=(+test2+test3+test4)/4,同理也可得到testad-avg-09,将testlgbm-avg-09、testad-avg-09作为m2的测试数据。
步骤2.8、基于is10_paraling、is11_speaker_state、is12_speaker_trait特征集做上述相同操作,分别得到融合前训练特征集vallgbm-10、valad-10、vallgbm-11、valad-11、vallgbm-12、valad-12,同样也可以得到融合前测试特征集testad-avg-10、testad-avg-11、testad-avg-12、testlgbm-avg-10、testlgb-avg-11、testlgbm-avg-12
步骤2.9、基于ravdess语音数据库做上述相同操作。
步骤3、建立评价标准,通过stacking学习模型得到的预测结果与真实结果进行计算,得到评价该模型的评价标准。
步骤3.1、基于emodb语音数据库,将vallgbm-09、valad-09、vallgbm-10、valad-10、vallgbm-11、valad-11、vallgbm-12、valad-12作为岭回归的训练数据,经训练后通过testad-avg-09、testad-avg-10、testad-avg-11、testad-avg-12、testlgbm-avg-09、testlgbm-avg-10、testlgbm-avg-11、testlgbm-avg-12测试数据来验证模型的预测结果。通过预测计算得到各个评价标准值如表4所示。图3、4、5、6分别为mae、mse、r_2、pcc结果簇状图。
表4emodb语音数据库的预测结果
步骤3.2、基于ravdess语音数据库做上述相同操作,得到最终的预测结果,并通过预测计算得到评价标准如表5所示。图7、8、9、10分别为mae、mse、r_2、pcc结果簇状图。(注意:ad_is09_emotio意思是在is09_emotio特征集上使用adaboostregresso模型训练预测得到的评价指标;stacking方法1指的是使用stacking模型训练预测得到的评价指标,次级学习器做了交叉验证;stacking方法2指的是使用stacking模型训练预测得到的评价指标,次级学习器没做交叉验证。上同)。
表5ravdess语音数据库的预测结果
- 还没有人留言评论。精彩留言会获得点赞!