一种语音情绪识别方法及系统与流程
本发明涉及机器学习技术领域,特别是涉及一种语音情绪识别方法及系统。
背景技术:
语音和语调表情(intonationexpression)是表达情绪的重要形式。朗朗笑声表达了愉快的情绪,而呻吟表达了痛苦的情绪。言语是人们沟通思想的工具,同时,语音的高低、强弱和抑扬顿挫等,也是表达说话者情绪的手段。通过语音可以判断和识别说话者的情绪是否异常。消沉的情绪为异常情绪,例如闷闷不乐、悲痛欲绝、木僵、焦虑和运动性激越。语音是一种非侵入式和非侵略式极易获取的信息,可以以更加灵活高效的形式辅助判断说话者的情绪是否正常。
当前,主要有两种方法被采用来判断说话者的情绪是否正常,一种是手动设计的方法,一种是深度学习的方法。手动设计的方法为手动提取语音的声学特征和手动分类,将手动提取的频率特征、倒谱特征、韵律特征和声音质量等声学特征输入到神经网络来进行判断,然后对提取的特征进行分类,但是这种手动提取的方法提取的是低级语音特征,不能充分表征语音特征的更深层次的特征,降低了语音情绪判断的准确度。深度学习的自动语音识别方法也有两种类型,类型一:将原始语音信号作为神经网络的输入;类型二:将手动提取的语音信号特征作为神经网络的输入。基于深度学习的方法比手动设计的方法更有优越性。但是,深度学习对异常情绪语音进行识别的方法存在样本少和样本不平衡的缺点,导致语音情绪判断的准确度低。因此,现有判断语音情绪的方法存在准确度低的问题。
技术实现要素:
本发明的目的是提供一种语音情绪识别方法及系统,解决了现有判断语音情绪的方法存在准确度低的问题。
为实现上述目的,本发明提供了如下方案:
一种语音情绪识别方法,包括:
获取数据库中的语音样本数据;
对所述语音样本数据进行预处理、数据扩充和特征选择,得到特征数据;
利用所述特征数据对递归神经网络进行训练,得到递归神经网络模型;所述递归神经网络模型用于对特征数据进行分类,判断特征数据对应的语音样本数据是否为异常情绪语音样本数据;
获取待识别语音数据;
对所述待识别语音数据进行预处理,得到待识别特征数据;
将所述待识别特征数据输入所述递归神经网络模型,得到待识别语音数据的分类结果。
可选的,所述对所述语音样本数据进行预处理、数据扩充和特征选择,得到特征数据,具体包括:
对所述语音样本数据进行快速傅立叶变换、梅尔滤波和离散余弦变换,得到梅尔频率倒谱系数;
利用条件深度卷积生成对抗网络对所述梅尔频率倒谱系数的数据数量进行扩充,得到扩充数据集;
利用fisher准则的特征选择方法对所述扩充数据集中的数据进行特征选择,得到特征数据。
可选的,所述对所述语音样本数据进行快速傅立叶变换、梅尔滤波和离散余弦变换,得到梅尔频率倒谱系数,具体包括:
对所述语音样本数据进行预加重处理,得到预加重语音样本数据;
对所述预加重语音样本数据进行分帧处理,得到多个语音片段;
对所述语音片段分别进行加窗处理,得到语音波形信号;
对所述语音波形信号进行快速傅立叶变换,得到频谱信号;
对所述频谱信号进行平方值处理,得到语音平方值;
对所述语音平方值进行梅尔滤波处理,得到梅尔频率;
对所述梅尔频率进行取对数处理,得到对数数据;
对所述对数数据进行离散余弦变换,得到动态特征值;
将所述动态特征值转换为特征向量,得到梅尔频率倒谱系数。
可选的,所述利用条件深度卷积生成对抗网络对所述梅尔频率倒谱系数的数据数量进行扩充,得到扩充数据集,具体包括:
获取条件深度卷积生成对抗网络的生成网络的生成约束条件;
将所述生成约束条件和所述梅尔频率倒谱系数输入所述生成网络,得到生成数据;
将所述生成数据和所述梅尔频率倒谱系数输入所述条件深度卷积生成对抗网络的判别网络,得到扩充数据;
将所述扩充数据与所述梅尔频率倒谱系数组成扩充数据集。
可选的,所述对所述待识别语音数据进行预处理,得到待识别特征数据,具体包括:
对所述待识别语音数据进行快速傅立叶变换、梅尔滤波和离散余弦变换,得到待识别梅尔频率倒谱系数;
利用fisher准则的特征选择方法对所述待识别梅尔频率倒谱系数进行特征选择,得到待识别特征数据。
一种语音情绪识别系统,包括:
第一获取模块,用于获取数据库中的语音样本数据;
特征数据获取模块,用于对所述语音样本数据进行预处理、数据扩充和特征选择,得到特征数据;
递归神经网络训练模块,用于利用所述特征数据对递归神经网络进行训练,得到递归神经网络模型;所述递归神经网络模型用于对特征数据进行分类,判断特征数据对应的语音样本数据是否为异常情绪语音样本数据;
第二获取模块,用于获取待识别语音数据;
待识别特征数据获取模块,用于对所述待识别语音数据进行预处理,得到待识别特征数据;
分类结果获取模块,用于将所述待识别特征数据输入所述递归神经网络模型,得到待识别语音数据的分类结果。
可选的,所述特征数据获取模块,具体包括:
梅尔频率倒谱系数获取单元,用于对所述语音样本数据进行快速傅立叶变换、梅尔滤波和离散余弦变换,得到梅尔频率倒谱系数;
数据扩充单元,用于利用条件深度卷积生成对抗网络对所述梅尔频率倒谱系数的数据数量进行扩充,得到扩充数据集;
特征选择单元,用于利用fisher准则的特征选择方法对所述扩充数据集中的数据进行特征选择,得到特征数据。
可选的,所述梅尔频率倒谱系数获取单元,具体包括:
预加重处理子单元,用于对所述语音样本数据进行预加重处理,得到预加重语音样本数据;
分帧处理子单元,用于对所述预加重语音样本数据进行分帧处理,得到多个语音片段;
加窗处理子单元,用于对所述语音片段分别进行加窗处理,得到语音波形信号;
快速傅立叶变换子单元,用于对所述语音波形信号进行快速傅立叶变换,得到频谱信号;
平方值处理子单元,用于对所述频谱信号进行平方值处理,得到语音平方值;
梅尔滤波处理子单元,用于对所述语音平方值进行梅尔滤波处理,得到梅尔频率;
对数处理子单元,用于对所述梅尔频率进行取对数处理,得到对数数据;
离散余弦变换子单元,用于对所述对数数据进行离散余弦变换,得到动态特征值;
特征向量转换子单元,用于将所述动态特征值转换为特征向量,得到梅尔频率倒谱系数。
可选的,所述数据扩充单元,具体包括:
生成约束条件获取子单元,用于获取条件深度卷积生成对抗网络的生成网络的生成约束条件;
生成数据获取子单元,用于将所述生成约束条件和所述梅尔频率倒谱系数输入所述生成网络,得到生成数据;
扩充数据获取子单元,用于将所述生成数据和所述梅尔频率倒谱系数输入所述条件深度卷积生成对抗网络的判别网络,得到扩充数据;
扩充数据集组成子单元,用于将所述扩充数据与所述梅尔频率倒谱系数组成扩充数据集。
可选的,所述待识别特征数据获取模块,具体包括:
待识别梅尔频率倒谱系数获取单元,用于对所述待识别语音数据进行快速傅立叶变换、梅尔滤波和离散余弦变换,得到待识别梅尔频率倒谱系数;
待识别特征数据获取单元,用于利用fisher准则的特征选择方法对所述待识别梅尔频率倒谱系数进行特征选择,得到待识别特征数据。
根据本发明提供的具体实施例,本发明公开了以下技术效果:
本发明提供了一种语音情绪识别方法及系统。该方法包括:获取数据库中的语音样本数据;对语音样本数据进行预处理、数据扩充和特征选择,得到特征数据;利用特征数据对递归神经网络进行训练,得到递归神经网络模型;递归神经网络模型用于对特征数据进行分类,判断特征数据对应的语音样本数据是否为异常情绪语音样本数据;获取待识别语音数据;对待识别语音数据进行预处理,得到待识别特征数据;将待识别特征数据输入递归神经网络模型,得到待识别语音数据的分类结果。本发明对语音样本数据进行数据扩充,减轻数据分布不均引起的偏差,对语音样本数据进行特征选择能准确的提取出语音的情绪特征,提高了语音情绪识别的准确度。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例所提供的语音情绪识别方法的流程图;
图2为本发明实施例所提供的提取梅尔频率倒谱系数的流程图;
图3为本发明实施例所提供的时间递归神经网络的结构图;
图4为本发明实施例所提供的c-dcgan的流程图;
图5为本发明实施例所提供的应用实例构建递归神经网络模型的流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的目的是提供一种语音情绪识别方法及系统,解决了现有判断语音情绪的方法存在准确度低的问题。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
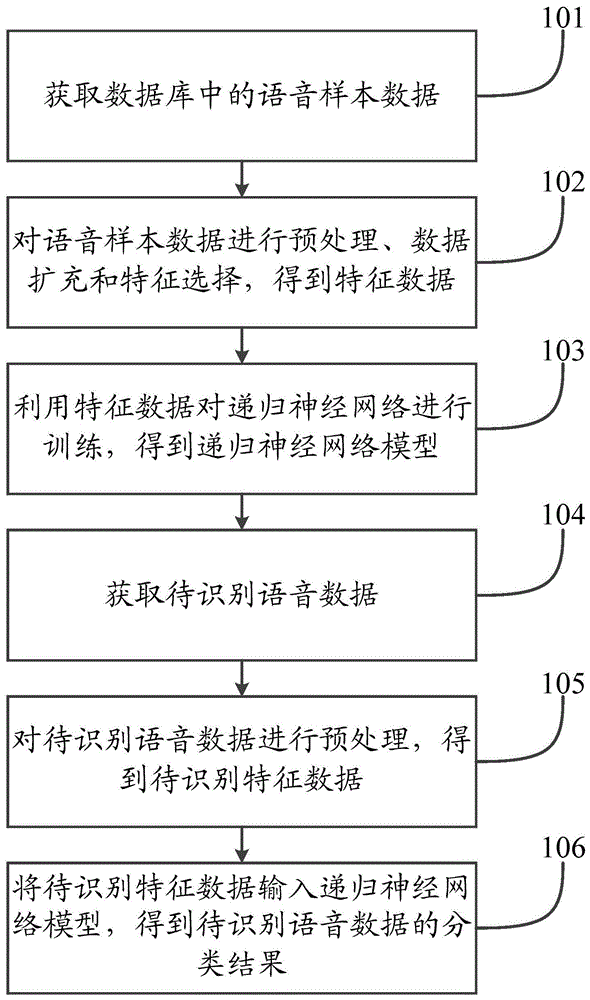
本实施例提供一种语音情绪识别方法,图1为本发明实施例所提供的语音情绪识别方法的流程图。参见图1,语音情绪识别方法包括:
步骤101,获取数据库中的语音样本数据。语音样本数据为异常情绪语音样本数据。
本发明采用情感语音挑战赛avec2017的数据集的daic-woz语音的语料库。该语料库提供了189名采访者和189名被试的语音数据,语音的采集是被试通过访谈方式回答虚拟机器人ellie的问题的形式来实现的,将被试与虚拟机器人的对话进行记录作为语音数据,每个语音数据文件的语音长度为7分钟(min)-35min。但在具体实施的时候由于语音采集技术的限制,仅采用了182个语音数据文件,语音数据文件的平均长度是15分钟,语音的固定采样率为16khz,语音原始帧包含一段时间内1024个采样,音频帧的时间为60ms。
获得语音数据文件后还需要对语音数据文件进行初步预处理,消除由于发声器官本身所具有以及由于在采集语音信号时采集设备所带来的混叠、高次谐波失真和高频部分干扰等因素对语音信号质量产生的影响,采用初步预处理操作可以使得语音信号均匀和平滑,提高语音处理的质量。具体采用端点检测的方法,找到被试人员说话的起点,去掉说话开始段的静音及噪声部分,然后找到被试人员说话的结束点,只提取被试的语音,去除提问者的语音部分,同时只提取带有异常语音特征的被试语音段,得到初步预处理后的语音样本数据。异常语音的语速较慢、停顿的次数多、停顿的时间比较长、声音缺乏抑扬顿挫并且呆板,以及声音频率的变化减少。80%的语音样本数据用于对递归神经网络进行训练,10%的语音样本数据用于对递归神经网络模型进行验证,10%的语音样本数据用于对递归神经网络模型进行测试。
步骤102,对语音样本数据进行预处理、数据扩充和特征选择,得到特征数据。
步骤102具体包括:
对语音样本数据进行快速傅立叶变换、梅尔滤波和离散余弦变换,得到梅尔频率倒谱系数。对语音样本数据进行快速傅立叶变换,从频域对语音样本数据进行处理,然后经过取平方值、梅尔(mel)滤波和离散余弦变换操作后,得到梅尔频率倒谱系数(melfrequencycepstrumcoefficient,mfcc)的动态特征,最后输出特征向量。参见图2,具体包括:
对语音样本数据进行预加重处理,得到预加重语音样本数据。由于声道的终端是口和唇,口和唇对低频部分的影响很小,对高频段的影响大。因此采用预加重技术来提升高频段的分辨率,具体做法是:语音样本数据取样后,加一个一阶高通滤波器,将声门脉冲的影响减低到最小,只留声道部分。所用的传递函数为:
h(z)=1-az-1
其中,h(z)为传递函数;a为预加重系数,且0.9<a<1.0;z为语音样本数据的波形。
对预加重语音样本数据进行分帧处理,得到多个语音片段。对预加重语音样本数据按照帧长25ms,帧移10ms进行分帧处理,得到多个语音片段。一段语音信号整体上不是平稳的,但是在局部上可以看作是平稳的。由于在后期的语音处理中需要输入的是平稳信号,所以要对整段预加重语音样本数据分帧,即切分成很多段。在10毫秒(ms)-30ms范围内都可以认为信号是稳定的,一般以不少于20ms为一帧,1/2左右时长为帧移分帧。帧移是相邻两帧间的重叠区域,是为了避免相邻两帧的变化过大。本发明的帧移选用10ms,帧长选用25ms。
对语音片段分别进行加窗处理,得到语音波形信号。由于分帧之后每一帧的起始段和末尾端会出现不连续的地方,通过加窗可以使分帧后的语音片段的信号变得连续,使每一帧都表现出周期函数的特征。本实施例采用汉明窗,公式如下:
其中,ω(n)表示长度为n的窗函数;汉明窗系数取0.46;n为窗函数的长度;n表示语音片段的长度;π表示圆周率。
对语音波形信号进行快速傅立叶变换(fastfouriertransform,fft),得到频谱信号。因为语音波形信号在时域上的变换通常很难看出语音波形信号的特性,所有通常将语音波形信号转换为频域上的能量分布来观察,不同的能量分布,代表不同语音的特性。所以在进行了加窗处理后,还需要再经过快速傅立叶变换以得到频谱上的能量分布。对分帧加窗后的各帧信号进行快速傅立叶变换得到各帧的频谱。公式为:
其中,s(k)表示语音波形信号的频谱;k表示s(k)输出采样点的点数,即样本数;s(n’)表示输入的语音波形信号,语音波形信号为离散语音信号;n’表示s(n’)的点数,时域的信号值,即s(n’)输入采样点的数目,n’=0,1,…,n’-1;n’表示fft的长度,本实施例取n’=512,即傅立叶变换的点数;j是虚部单位。
对频谱信号进行平方值处理,得到语音平方值。对频谱信号取模平方得到语音波形信号的功率谱,即语音平方值。语音波形信号的能量的分布p(k),即语音平方值为:
还可以取频谱信号的绝对值。
对语音平方值进行梅尔滤波处理,得到梅尔频率。由于mfcc考虑到了人类的听觉特征,先将线性频谱映射到基于听觉感知的mel非线性频谱中,然后转换到倒谱上。在mel频域内,人对音调的感知度为线性关系。利用mel滤波器将能量通过一组mel尺度的三角形滤波器组转换为非线性频谱。从频率转换为mel频率,得到mel滤波器构成的mel滤波器组。从频率转换到mel频率的公式为:
其中,f为语音平方值的频率,单位为赫兹。
对梅尔频率进行取对数处理,得到对数数据。帧的音量(即能量),也是语音的重要特征,因此,通常再加上一帧的对数能量使得每一帧基本的语音特征就多了一维,即对数数据包括一个对数能量和剩下的梅尔频率(倒频谱参数)。具体为:一帧内梅尔频率的平方和,再取以10为底的对数值,再乘以10。
对对数数据进行离散余弦变换(discretecosinetransform,dct),得到动态特征值。对数数据使用离散余弦变换,即进行了傅立叶变换的逆变换,得到倒谱系数。计算公式如下:
其中,c(i)表示第i个余弦变换值,即倒谱系数;i表示梅尔频率变量,取值为i=1,2,...,60;m(j’)是对数数据时域的60个点序列;j’表示点序列的个数。
标准的倒谱系数只反映了语音的静态特性,语音的动态特性可以用这些倒谱系数的差分谱来进行描述,将静态和动态特征结合起来可以提高系统识别性能。差分谱的计算公式如下:
其中,d(t)表示第t个一阶差分谱;k’表示差分倒谱,即差分运算时差分谱向后移动的帧数;k表示一阶导数的时间差,c(t)表示第t个倒谱系数,q表示倒谱系数的阶数。
对静态的倒谱系数进行一阶差分,并对一阶差分谱进行二阶差分,得到动态的一阶mfcc参数和二阶mfcc参数,但由于二阶mfcc参数维数增加,导致识别率下降,因此本实施例只选取了一阶差分谱。由于语音信号是时域连续的,分帧提取的动态特征值只反应了本帧语音的特性,为了使动态特征值更能体现时域连续性,可以在动态特征值的特征维度增加前后帧信息的维度,就是当前语音帧与前一帧之间的关系,一阶差分体现帧与帧(相邻两帧)之间的联系;二阶差分体现到帧上就是相邻三帧之间的动态关系。动态特征是相邻三帧之间的关系;动态特征包括一阶差分和二阶差分,二阶差分的影响不是很大,因此本实施例只进行一阶差分。动态特征值包括倒谱系数和倒谱系数对应的一阶差分谱。
将动态特征值转换为特征向量,得到梅尔频率倒谱系数。取dct后的第2个到第13个系数作为mfcc系数,获得mel频率倒谱系数(mfcc),这个mfcc就是这帧语音片段的特征;这时候,语音样本数据就可以通过一系列的倒谱向量来描述了,每个倒谱向量就是每帧的mfcc特征向量。
步骤102将语音样本数据分为很多帧语音片段,每帧语音片段对应一个频谱,通过对数运算使那些振幅较低的成分相对高振幅成分拉高,便以观察掩盖在低幅噪声中的周期信号。将提取得到的对数数据经过平滑处理和一阶导数运算,得到梅尔频率倒谱系数。本实施例中音频帧的时间为60ms,则每音频帧将会生成60个梅尔特征,将这60个梅尔特征以大小为n1的mfcc矩阵生成梅尔频率倒谱系数,进而计算得到了语音样本数据每一帧的60个mel频率倒谱系数,即为一个语音样本数据的特征数据,mel频率倒谱系数用于之后的分类。
利用条件深度卷积生成对抗网络(conditional-dcgan,c-dcgan)对梅尔频率倒谱系数的数据数量进行扩充,得到扩充数据集。具体包括:
获取条件深度卷积生成对抗网络的生成网络的生成约束条件。c-dcgan是一种基于数据分布的生成模型,是生成式对抗网络(generativeadversarialnetworks,gan)在卷积神经网络(cnn)上的扩展,由生成网络g与判别网络d构成。本实施例获取的生成约束条件是被试语音数据的编号。
将生成约束条件和梅尔频率倒谱系数输入生成网络,得到生成数据。具体过程是利用基于fisher准则的特征选择方法按照辨别能力强弱的顺序对被试的语音数据集排序编号,采用生成网络生成与语音样本数据具有相同分布的样本数据,对生成的样本数据按照步骤102提取特征,生成新的特征,得到生成数据。生成网络的最后一层采用sigmoid激活函数,其他层采用relu激活函数。
将生成数据和梅尔频率倒谱系数输入条件深度卷积生成对抗网络的判别网络,得到扩充数据。将生成数据和梅尔频率倒谱系数输入判别网络后,判别网络依据输入数据的真伪返回概率值,即判别网络根据生成数据和梅尔频率倒谱系数的特征判断输入数据的特征是否与异常情绪相关,判别网络判断为与异常情绪相关的特征对应的生成数据为扩充数据。判别网络使用leakyrelu作为激活函数。输入梅尔频率倒谱系数提取特征的过程使用leakyrelu作为激活函数,输入生成数据提取特征的过程也采用leakyrelu作为激活函数,这是由于leakyrelu激活函数收敛速度快且不易使神经元坏死。判别网络d是一个二分类器,可以判别输入的数据是不是扩充的数据。
将扩充数据与梅尔频率倒谱系数组成扩充数据集。将每名被试的扩充数据集和梅尔频率倒谱系数进行连接形成扩充数据集。
利用fisher准则的特征选择方法对扩充数据集中的数据进行特征选择,得到特征数据。具体包括:
将扩充数据集中的数据分为训练集、测试集和验证集。将扩充数据集中的数据按8:1:1比例分为训练集、测试集和验证集,并从扩充数据集中的数据中获得能表征异常情绪的特征。利用训练集来构建递归神经网络模型,训练集的作用就是训练模型,形成模型的内部结构和参数估计,比如古典的线性回归模型中每个变量前边的参数都是由训练集估计出来的。测试集来验证训练集构建的递归神经网络模型的可行性,测试集来输出模型的准确率,评价模型是不是有很好的性能。借助验证集来对递归神经网络模型的性能辅助检验,验证集的存在就是为了对超参数进行选择,如果由训练集得出超参数,很容易造成过拟合,所以通过一个独立于训练集的数据对超参数进行选择。
利用fisher准则的特征选择方法对训练集和测试集中的数据进行特征选择,得到特征数据。特征包含足够的信息对于递归神经网络模型的性能有很大的影响,所以最大限度的提取与异常情绪相关的特征至关重要。为了尽量不降低分类准确度,尽量降低特征的位数,进行特征选择。特征选择的依据是能够表征异常情绪的特征,通过计算特征权重,利用fisher准则的特征选择方法进行特征选择,即从训练集和测试集的数据中提取高维特征得到原始高维特征集合,然后从原始高维特征集合中选择出最能代表向量空间的向量作为特征子集,去除掉冗余,最大化相关。训练集和测试集中提取出的特征一般数量很大,维度很高,在进行分类的时候,往往太耗费时间,特征选择能够选出最具代表性的特征,来优化模型,较少冗余,可以提高分类器的速度和准确度,还能提高可理解性。fisher准则的特征选择方法根据辨别能力越强的特征具有组内距离越小、组间距离越大的特性,以单个特征的fisher比(组间离差和组内离差的比值)作为度量准则,对特征进行排序,从而达到降维的目的并得到较优的识别性能。具体包括:
求最大特征值对应的特征向量组成的空间。取几个最大特征值对应的特征向量组成特征空间,先求训练集和测试集中数据的类内离散度sw和类间离散度sb:
其中,m是数据总数,c是类别总数,mi1是类i1中数据的总数目,mj1表示类i1中训练样本的总数目,
数据在新的投影空间中的类内离散度
其中,w为需要求解的投影方向,wt是低维空间w的投影。
数据在新的投影空间中的类间离散度
最大化
jd(w)=wtsbw-b·wtsww=wt(sb-b·sw)w
其中,jd(w)为fisher准则函数;b是权衡因子,用于权衡类间距离和类内距离谁的比重大,根据实际需要调节b的值。也就是说,可以根据梯度下降法迭代w,使得jd(w)最大化的w就是所要求的最好的投影方向。在fisher中最大特征值对应的特征向量就是最佳投影方向,取最大特征值对应的特征向量作为投影方向,w是使fisher准则函数jd(w)中最大特征值对应的特征向量取极大值时的解,也就是最佳投影方向。数据投影在类内距离最小,类间距离最大的空间上,空间的每一维代表一个特征,对空间中的特征进行排序,得到最大特征值,最大特征值基本上可以涵盖90%以上的信息。
选取fisher准则,即特征子集最前面一定数目的特征作为特征数据。fisher准则预选出提取的特征中鉴别性能较强的特征,一定数目为10%的训练数据。
步骤103,利用特征数据对递归神经网络进行训练,得到递归神经网络模型;递归神经网络模型用于对特征数据进行分类,判断特征数据对应的语音样本数据是否为异常情绪语音样本数据。
构建递归神经网络,对80%的扩充数据集数据进行预训练,即将梅尔频率倒谱系数以矩阵的形式输入到递归神经网络中,得到初始递归神经网络模型。通过数据增强技术中的条件深度卷积生成对抗网络增加训练的数据量,防止过拟合现象的发生,然后递归神经网络可以提取到能表征异常情绪的更深层次的特征,即仅生成被试语音的新音频片段。
通过构建时间递归神经网络,利用深度学习的方法提取mfcc的高级特征。本实施例具体采用时间递归神经网络。时间递归神经网络(rnn)可以处理不同长度的序列,参见图3,时间递归神经网络主要包含3层-输入层、隐含层和输出层。输入层是提取的能表征异常情绪的特征;隐含层是长短时记忆网络(longshort-termmemory,lstm),隐含层的输出不仅进入输出层,还进入了下一个时间步骤的隐含层,能够持续保留信息,可以根据之前状态推出后面的状态;输出层是由sigmoid函数激活的全连接层,用于训练时对识别结果进行分类。输入层的mfcc矩阵,经过三层lstm网络层,通过sigmoid激活函数激活两层全连接层后将神经单元进行分类,判断是否为异常情绪语音样本数据,输出层输出分类结果,0表示为异常情绪语音样本数据,1表示为正常情绪语音样本数据。
时间递归神经网络中起主要作用的是长短时记忆网络(lstm),长短时记忆网络包含输入门、遗忘门、输出门和细胞状态。将经过特征选择之后的能表征异常情绪的相关特征数据添加到长短时记忆网络的输入门;遗忘门决定输入的特征有多少保留到当前时刻;输出门决定当前的特征有多少需要输出到当前的输出值。本实施例的隐含层由三个长短时记忆网络组成,三个长短时记忆网络的长度分别取20、30和40。长短时记忆网络单元是递归神经网络的变形结构,在普通rnn基础上,在隐含层的各神经单元中增加记忆单元,从而使时间序列上的记忆信息可控,每次在隐含层的各单元间传递时通过几个可控门(遗忘门、输入门和输出门),可以控制之前信息和当前信息的记忆和遗忘程度,从而使rnn网络具备了长期记忆功能。
lstm网络包含输入门、遗忘门、输出门和细胞状态,其工作步骤包括:
1.遗忘门,决定从细胞状态中丢弃什么信息,这个决定通过一个遗忘门来完成。输出一个在0到1之间的数值给每个在细胞状态中的数字。1表示“完全保留”,0表示“完全舍弃”。
2.输入门,确定什么样的新信息被存放在细胞状态中。这里包含两个部分。第一,sigmoid层称为“输入门层”决定什么值将要更新。然后,一个tanh层创建一个新的候选值向量,新的候选值向量会被加入到细胞状态中。tanh函数创建新的输入值,sigmoid函数决定可以输入进去的比例。
3.输出门最终需要确定输出什么值,输出值为深层次的特征。这个输出将会基于细胞状态,但是也是一个过滤后的版本。首先,运行一个sigmoid层来确定细胞状态的哪个部分将输出出去。接着,把细胞状态通过tanh进行处理,得到一个在-1到1之间的值,并将-1到1之间的值和sigmoid门的输出相乘,最终仅仅会输出确定输出的那部分。因为sigmoid层的输出是0-1的值,代表多少信息流过sigmoid层,0表示不能通过,1表示能通过。最终仅仅会输出0或1,0表示异常,1表示正常。
全连接层的每一个结点都与上一层的所有结点相连,全连接层中的每一层是由许多神经元组成,用来把全连接层之前提取到的特征综合起来,全连接层中一层的一个神经元可以看成一个多项式,用许多神经元去拟合数据分布,通过矩阵向量乘积的计算,把特征整合到一起,输出一个值,利用激活函数sigmoid将异常的神经元激活,输出识别结果,1表示异常,0表示正常。全连接层的激活函数是在人工神经网络的神经元上运行的函数,负责将神经元的输入映射到输出端,本实施例采用的是softmax。
全连接层之前的作用是提取特征,全连接层的作用主要就是实现分类,用许多神经元去拟合语音样本数据提取出的mfcc特征,表征异常情绪的神经元被激活,同一层的其他神经元,要么是异常情绪不明显,要么没找到,把这些找到的特征组合在一起,最符合异常情绪的就是异常情绪。全连接层中一层的一个神经元就可以看成一个多项式,通过mfcc矩阵向量乘积,通过将静态特征和动态特征整合到一起,符合异常情绪则将该神经元激活,否则不激活。mfcc矩阵向量乘积的本质就是从上述的特征提取中发现从训练集和测试集数据中提取特征是将训练集和测试集数据映射到一个更高维的空间,特征空间中的特征是对训练集和测试集数据数据更高维的抽象。利用测试集的特征数据验证训练集构建的初始递归神经网络模型的可行性,得到训练后的递归神经网络模型。利用验证集对训练后的递归神经网络模型的性能进行辅助检验时,需要先利用fisher准则的特征选择方法对验证集中的数据进行特征选择,将从验证集得到的特征数据输入训练后的递归神经网络模型,对训练后的递归神经网络模型的性能进行辅助检验,得到递归神经网络模型。
步骤104,获取待识别语音数据。
步骤105,对待识别语音数据进行预处理,得到待识别特征数据。
步骤105具体包括:对待识别语音数据进行快速傅立叶变换、梅尔滤波和离散余弦变换,得到待识别梅尔频率倒谱系数。
利用fisher准则的特征选择方法对待识别梅尔频率倒谱系数进行特征选择,得到待识别特征数据。步骤105的具体处理过程参见步骤102。
步骤106,将待识别特征数据输入递归神经网络模型,得到待识别语音数据的分类结果。
输入到递归神经网络模型的待识别特征数据经过递归神经网络模型的处理后,由激活函数以神经元的形式来进行分类。通过由sigmoid函数激活的递归神经网络模型的全连接层经矩阵向量乘积的计算,把待识别特征数据整合到一起,输出一个值,利用激活函数sigmoid将异常的神经元激活,激活的神经元表征了异常状态。
对输入的待识别特征数据进行分类,分类是由lstm后面加的全连接层实现的。语音情绪识别方法的分类结果采用留一十倍交叉验证技术,将所有的待识别特征数据平分为10份,9份数据用来训练,1份数据用来测试,将待识别特征数据输入递归神经网络模型的过程重复10次,并将最终得到的10次交叉验证结果正确率的平均值作为最终的识别结果,也作为对语音情绪识别方法精度的估计。
本实施例还提供一种语音情绪识别系统,包括:
第一获取模块,用于获取数据库中的语音样本数据。
特征数据获取模块,用于对语音样本数据进行预处理、数据扩充和特征选择,得到特征数据。
特征数据获取模块具体包括:
梅尔频率倒谱系数获取单元,用于对语音样本数据进行快速傅立叶变换、梅尔滤波和离散余弦变换,得到梅尔频率倒谱系数。
梅尔频率倒谱系数获取单元具体包括:
预加重处理子单元,用于对语音样本数据进行预加重处理,得到预加重语音样本数据。
分帧处理子单元,用于对预加重语音样本数据进行分帧处理,得到多个语音片段。
加窗处理子单元,用于对语音片段分别进行加窗处理,得到语音波形信号。
快速傅立叶变换子单元,用于对语音波形信号进行快速傅立叶变换,得到频谱信号。
平方值处理子单元,用于对频谱信号进行平方值处理,得到语音平方值。
梅尔滤波处理子单元,用于对语音平方值进行梅尔滤波处理,得到梅尔频率。
对数处理子单元,用于对梅尔频率进行取对数处理,得到对数数据。
离散余弦变换子单元,用于对对数数据进行离散余弦变换,得到动态特征值。
特征向量转换子单元,用于将动态特征值转换为特征向量,得到梅尔频率倒谱系数。
数据扩充单元,用于利用条件深度卷积生成对抗网络对梅尔频率倒谱系数的数据数量进行扩充,得到扩充数据集。
数据扩充单元具体包括:
生成约束条件获取子单元,用于获取条件深度卷积生成对抗网络的生成网络的生成约束条件。
生成数据获取子单元,用于将生成约束条件和梅尔频率倒谱系数输入生成网络,得到生成数据。
扩充数据获取子单元,用于将生成数据和梅尔频率倒谱系数输入条件深度卷积生成对抗网络的判别网络,得到扩充数据。
扩充数据集组成子单元,用于将扩充数据与梅尔频率倒谱系数组成扩充数据集。
特征选择单元,用于利用fisher准则的特征选择方法对扩充数据集中的数据进行特征选择,得到特征数据。
特征选择单元具体包括:
数据分集子单元,用于将扩充数据集中的数据分为训练集、测试集和验证集。
特征选择子单元,用于利用fisher准则的特征选择方法对训练集和测试集中的数据进行特征选择,得到特征数据。
递归神经网络训练模块,用于利用特征数据对递归神经网络进行训练,得到递归神经网络模型;递归神经网络模型用于对特征数据进行分类,判断特征数据对应的语音样本数据是否为异常情绪语音样本数据。
第二获取模块,用于获取待识别语音数据。
待识别特征数据获取模块,用于对待识别语音数据进行预处理,得到待识别特征数据。
待识别特征数据获取模块具体包括:
待识别梅尔频率倒谱系数获取单元,用于对待识别语音数据进行快速傅立叶变换、梅尔滤波和离散余弦变换,得到待识别梅尔频率倒谱系数。
待识别特征数据获取单元,用于利用fisher准则的特征选择方法对待识别梅尔频率倒谱系数进行特征选择,得到待识别特征数据。
分类结果获取模块,用于将待识别特征数据输入递归神经网络模型,得到待识别语音数据的分类结果。
本实施例还提供一种语音情绪识别方法在抑郁症识别的实例应用:
本实例应用采用的数据库为情感语音挑战赛avec2017的数据集的daic-woz语音的抑郁症识别的语料库,该语料库支持心理疾病的诊断:抑郁和压力失调等。从语料库的原始语音数据的所有语音样本中,挑选出具有明显抑郁特征的语音样本,去掉提问者的语音部分,只保留被试的语音数据,获得语音数据文件。对语音数据文件进行初步预处理,只提取带有抑郁特征的被试语音段。抑郁被试的语音具有语速较慢、停顿的次数多、停顿的时间比较长、声音缺乏抑扬顿挫并且呆板,以及声音频率的变化减少等特点,同时只提取被试的语音,去除提问者的语音部分,得到初步预处理后的语音数据文件,即语音样本数据。
参见图5,对语音样本数据(原始语音)经过预加重、分帧、加窗、快速傅立叶变换、取平方值、mel滤波、取对数、离散余弦变换和特征向量转换等,得到特征数据。然后将提取的特征数据(梅尔频率倒谱系数矩阵)作为递归神经网络的输入。将语音样本数据分帧为多个60ms的语音片段,语音样本数据中音频帧的时间为60ms。
针对抑郁症数据难采集和用于研究的被试数远小于特征维数的问题,利用条件深度卷积生成对抗网络生成抑郁数据。由于原始抑郁的数据集太小,借助于条件深度卷积生成对抗网络来扩充样本数量,生成与训练数据同分布的语音样本,从而解决了数据集过小的瓶颈。将提取出的具有较强抑郁识别能力的特征数据即梅尔频率倒谱系数通过c-dcgan扩充数据数量,得到扩充数据集;将扩充数据集中的数据按8:1:1比例分为训练集、测试集和验证集,从扩充数据集的数据中获得能表征抑郁的特征。用fisher准则的特征选择方法对训练集和测试集的数据进行特征选择。参见图4和图5,c-dcgan用于加入生成约束条件(条件信息)和混合语音数据(训练集和测试集的数据)后,提取输入数据的特征得到抑郁相关的特征,抑郁相关的特征输入生成网络生成数据样本,提取原始语音数据(梅尔频率倒谱系数)和生成的数据样本的特征,得到抑郁相关的特征,将抑郁相关的特征输入判别网络,判别网络判别所提取的特征是否与抑郁相关,并输出真伪。特征数据包含足够的信息对于递归神经网络模型的性能有很大的影响,所以最大限度的提取抑郁相关的特征至关重要,特征选择的依据是能够表征抑郁患者的特征。
构建递归神经网络,对80%的扩充数据集数据进行预训练,即将梅尔频率倒谱系数矩阵输入到递归神经网络中,得到递归神经网络。通过数据增强技术增加训练的数据量,防止过拟合现象的发生,然后递归神经网络可以提取到能表征抑郁的更深层次的特征,即仅生成被试语音的新音频片段。本实例应用具体采用时间递归神经网络。
然后利用10%的扩充数据集数据的特征数据验证递归神经网络的可行性,得到训练后的递归神经网络模型。利用剩余10%的扩充数据集数据对训练后的递归神经网络模型的性能进行辅助检验,得到递归神经网络模型。
时间递归神经网络的输入层是提取的能表征抑郁的特征,隐含层是长短时记忆网络,隐含层的输出不仅进入输出层,还进入了下一个时间步骤的隐含层,输出层是由sigmoid函数激活的全连接层。输入层的mfcc矩阵,经过三层lstm网络,通过sigmoid激活函数激活后将神经单元进行分类,通过病人健康问卷phq-8对抑郁的严重程度和是否抑郁进行分类,输出层输出分类结果。
时间递归神经网络中起主要作用的是长短时记忆网络(lstm),长短时记忆网络包含输入门、遗忘门、输出门和细胞状态。将经过特征选择之后的能表征抑郁的相关特征添加到长短时记忆网络的输入门。运行一个sigmoid层来确定细胞状态的哪个部分将输出出去,接着把细胞状态通过tanh进行处理,得到一个在-1到1之间的值,并将-1到1之间的值和sigmoid门的输出相乘,最终仅仅会输出确定输出的那部分。因为sigmoid层的输出是0-1的值,代表多少信息流过sigmoid层,0表示抑郁,1表示健康。
获取待识别语音数据;对待识别语音数据进行预处理,得到待识别特征数据;将待识别特征数据输入递归神经网络模型,得到待识别语音数据的分类结果。输入到递归神经网络模型的待识别特征数据经过递归神经网络模型的处理后,由激活函数以神经元的形式来进行分类,分类的结果通过病人健康问卷phq-8来显示被试的抑郁情况及抑郁的严重程度。通过由sigmoid函数激活的递归神经网络模型的全连接层经矩阵向量乘积的计算,把待识别特征数据整合到一起,输出一个值,利用激活函数sigmoid将抑郁的神经元激活,激活的神经元表征了抑郁状态,用病人健康问卷phq-8量表的二分类进行分类,利用病人健康问卷phq-8的数值对抑郁患者是否抑郁以及抑郁的严重程度做出判断,1表示抑郁,0表示不抑郁。
语音抑郁症识别的分类结果采用留一十倍交叉验证技术,将所有待识别特征数据平分为10份,9份数据用来训练,1份数据用来测试,将这个过程重复10次,并将最终得到的10次交叉验证结果正确率的平均值作为最终的识别结果。本实例应用的softmax用于预测phq-8得分和sigmoid激活函数预测phq-8二进制。
全连接层之前的作用是提取特征,全连接层的作用主要就是实现分类,用许多神经元去拟合语音样本数据提取出的mfcc特征,表征抑郁特征的神经元被激活,同一层的其他神经元,要么是抑郁特征不明显,要么没找到,把这些找到的特征组合在一起,最符合抑郁特质那就是抑郁。全连接层中一层的一个神经元就可以看成一个多项式,通过mfcc矩阵向量乘积,通过将静态特征和动态特征整合到一起,符合抑郁则将该神经元激活,否则不激活。
病人健康问卷phq-8的分值是0-23,预测phq-8得分的输出层是由softmax功能激活的24个神经元的密集层。当分数大于10,则为抑郁;分数小于10则为健康。rnn的输出层是一个两单元密集层,通过sigmoid函数激活以预测phq-8二进制,预测为抑郁时,二进制评分为0;预测为非抑郁症的评分为1,从而预测抑郁。
条件深度卷积生成对抗网络在图像和语音增强等领域表现出很好的性能。条件深度卷积生成对抗网络能够生成与训练数据同分布的样本,条件深度卷积生成对抗网络模型利用卷积层提取语音特征,同时利用条件信息,生成高质量的语音,从而可以生成能很好的表征抑郁的特征,为抑郁症的有效判别提供了支持,将条件深度卷积生成对抗网络用到抑郁症的诊断领域是一个新的思路。本应用实例就是利用条件深度卷积生成对抗网络和递归神经网络实现基于语音信号的临床抑郁症识别。本应用实例将条件深度卷积生成对抗网络和长短时记忆单元组合在一起,条件深度卷积生成对抗网络扩充了数据集,提供更全面的音频表示;在条件深度卷积生成对抗网络模型的训练阶段采用了一种随机抽样策略,以平衡正样本和负样本,大大减轻了语音样本数据分布不均引起的偏差;正样本指健康的被试;负样本指具有抑郁特征的被试。
本发明利用条件深度卷积生成对抗网络生成与训练集数据同分布的样本,扩充原始的语音样本数据,减轻数据分布不均引起的偏差,对语音样本数据进行特征选择能准确的提取出语音的情绪特征,优化模型,较少冗余,可以提高分类器的速度和准确度,还能提高可理解性,进而提高了语音情绪识别的准确度。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!