一种基于三值量化压缩的VAD实现方法与流程
本发明涉及音频处理技术领域,具体涉及一种基于三值量化压缩的vad实现方法。
背景技术:
区分人声语音与噪音是现有音频处理领域的一个重点,也是难点。
现有的技术中,在特征提取过程中采用多分辨率耳蜗谱图mrcg(multi-resolutioncochleagram)特征。对预先处理好的噪声与人声混合的数据集音频计算输入信号的gammatone系数g,gammatone是一组模拟人耳特性的滤波器,滤波器的个数n决定最后特征的维度。
然后采用两种不用的帧长和帧移计算g的cochleagram之后取log10得到耳蜗图谱c1,c2。然后利用get_avg函数计算c1的5*5、11*11模糊图,得到耳蜗图谱c3,c4。然后将四个耳蜗图串联[c1;c2;c3;c4]得到all_cochleas。接下来对all_cochleas求一阶导和二阶导,分别得到del和ddel。最后将三个串联得到最后特征[all_cochleas,del,ddel],特征的维度是n*4*3。
将这些mrcg特征视为神经网络的输入来训练模型;神经网络则采用深度神经网络(dnn),将上一层输入的mrcg特征通过深度神经网络(dnn)中,对音频信号的每一帧特征数据进行处理,并且将dnn的计算结果经过softmax函数来计算语音/非语音的后验概率,概率值在(0,1)之间,大于设定阈值即可认定为是语音,小于阈值则认定为非语音。
技术实现要素:
基于此,针对上述问题,有必要提出一种基于三值量化压缩的vad实现方法,能从带有噪声的语音中准确的定位出语音的开始和结束点,主要对麦克风中录到的音频进行处理,识别其中的语音部分,并删去非语音部分。
本发明的技术方案是:
一种基于三值量化压缩的vad实现方法,包括以下步骤:
a、提取人声数据及噪音数据,按预设定的信噪比结合,得到训练音频数据;
b、针对每一帧训练音频数据提取mfcc特征后,经拼接得到最终特征数据;
c、拼接多帧特征数据,输入神经网络进行数据训练;
d、接收训练后的数据模型,进行三值量化处理;
e、利用相同训练数据,训练三值化bdnn后,提取并保存其权重、参数。
在本技术方案中,采用了三值量化压缩的vad实现方法(ternaryvoiceactivitydetection),以下简称tvad,主要包括数据预处理、神经网络(neuralnetwork)和量化处理部分三个部分。
数据预处理,是指对于纯净人声数据与噪声数据进行按不同信噪比进行融合得到原始数据集,然后进行预处理使其数据符合神经网络的计算需求;其中,数据预处理主要步骤包括:语音信号的预加重、分帧、加窗、短时快速傅里叶变换(fft)、计算不同fft子带的能量、梅尔滤波、dct变换、lifter变换等。
神经网络(neuralnetwork,nn)是人类基于人类大脑的神经网络设计出来的一种数学模型,用以模拟人脑的功能实现类人工智能。神经网络是一种运算模型,由大量的神经元之间相互联接构成。每个神经元代表一种特定的输出函数,称为激活函数(activationfunction)。每两个神经元间的连接都表示一个对于通过该连接信号的加权值,称之为权重。这个权重的大小会随着神经元之间连接的重要性改变而改变。在得到上一层神经元的加权和之后,加权和会经过一个激活函数,最后得到当前神经元的输出。
本方案,网络结构为输入层、三个隐层、输出层;其目前的参数数目为输入层为24*5,三个隐层是128*64*32,输出层为5维。隐藏层的维度可自由调节以便获取更好的预测结果。
量化处理部分,是指对于神经网络的进行三值量化压缩从而降低神经网络模型所需要的存储空间。
优选的,还包括以下步骤:
f、提取人声数据及噪音数据,按预设定的信噪比结合,获取测试音频数据;
g、针对每一帧测试音频数据提取mfcc特征后,经拼接得到最终特征数据;
h、拼接多帧特征数据,输入神经网络进行数据训练;
i、进行三值化bdnn,计算待预测帧的预测值,待批量预测结束后,将所有预测中包含待预测帧的结果求平均值,得到当前帧的最终预测值。
本技术方案,分为训练部分和测试部分,训练部分与测试部分中对输入神经网络的特征数据的处理方式相同,但测试部分在进行神经网络训练并经过三值化bdnn后会得到待预测帧的预测结果,等批量预测结束后将所有预测中包含待预测帧的结果求平均值即得到当前帧的最终预测结果。如图4所示,其中,每一行中虚线框中就是含有待预测帧的结果,将其取平均值,则得到待预测帧的最终预测结果。
优选的,所述步骤i还包括以下步骤:
判断最终预测值是否大于设定阈值,若是,则判定待预测帧含语音,反之,则不含语音。
比较得到的待预测帧的最终预测结果与设定阈值的大小,大于设定阈值的即可认为含语音,小于阈值则认为不含语音。
优选的,所述步骤i还包括以下步骤:
计算auc值作为评估标准,auc值取值为(0,1)。
计算auc值可以解决因为正负样本不均导致的问题,能够更好地反应模型的性能,auc值取值为(0,1),越接近于1表示预测效果越好。
优选的,所述步骤i还包括以下步骤:
将测试音频的波形与预测结果进行可视化展示。
将预测值和波形图进行可视化直观展示模型,区别语音与非语音的效果。
优选的,所述步骤a和步骤f中混合人声数据及噪音数据的步骤还包括:
p1、构造噪声数据列表与语料数据列表;
p2、设定每段音频的长度为l,从步骤s1中的噪声列表中随机选择音频进行串联,直到长度达到l;
p3、从步骤s1中的语料数据列表中随机选取一段音频,在所选取的音频首尾各添加音频总长度1/4的静音,重复选取至长度达到l;
p4、将选取的音频与噪声按预设定的信噪比结合,获取音频数据。
本方案中p3步骤可在所选取的音频首尾各添加音频总长度1/4的静音,亦可在所选取的音频首尾各添加4秒的静音,具体以添加静音时间更短的方案为最优。
优选的,所述步骤b和步骤g中提取mfcc特征的步骤还包括:
q1、对每一帧音频数据进行预加重,其中预加重因子取0.97;
q2、对每一帧音频数据进行分帧,设定帧长为32ms,帧移为16ms;
q3、基于汉明窗函数进行加窗,汉明窗函数如下:
q4、进行快速傅里叶变换,将信号分离到不同的子带;
q5、计算不同子带的能量;
q6、生成相应的梅尔滤波器对子带进行滤波,梅尔滤波函数如下:
q7、计算每个梅尔滤波器输出的对数能量;
q8、经离散余弦变换,得到mfcc系数;
q9、提取一阶差分参数;
q10、将mfcc系数与其一阶差分参数拼接,得到最终特征数据。
优选的,所述步骤c和步骤h中拼接多帧特征数据的步骤包括:
s1、获取每一帧最终特征数据;
s2、提升每一帧的上下文信息,生成每一帧上的多个基预测;
s3、拼接包括待预测帧在内的5帧特征数据,输入神经网络进行数据训练。
本方案使用待预测帧的相邻帧来联合预测待预测帧,通过提升帧的上下文信息来生成帧上的多个基预测,然后将基础预测聚合为更强的基础预测,相比于传统的dnn能实现更高的性能。
在本方案中,取包含待预测帧在内的5帧特征数据拼接起来作为一组输入数据送入神经网络中进行训练,对于第一帧数据,我们在其前面补零,如图5所示,其中:每个方框代表一帧数据,其中虚线方框表示5帧数据拼接,xn表示待预测帧,当xn是输入数据第一帧时,由于算法需要其前面帧的数据,所以在此对其做补零处理,对待预测帧前面补10帧,数据为0。最终得到5帧特征数据共5*24=120维数据,送入神经网络作训练处理。
优选的,所述步骤d中进行三值量化的步骤包括:
d1、接收训练后的数据模型,从该数据模型的矩阵中,计算得出阈值δ和缩放因子α,计算公式如下:
其中,iδ={1≤i≤n||wi>δ|},|iδ|表示iδ中的元素;
d2、将原权重转变为三值权重,三值权重公式如下:
d3、将输入x与缩放因子α相乘作为新的输入数据,并与三值权重进行加法计算进行正向传播;
d4、使用sgd算法反向传播进行迭代训练。
将训练好的模型进行三值量化,量化操作流程图如图3所示,三值量化方法可以将权重从32bit浮点型量化为2bit定点型,即将原始浮点型权重用三值权重(-1,0,+1)与一个比例系数α相乘来近似表示。即:
其中,阈值δ从原权重矩阵w中产生,通过推导,其值为:
α的值为:
其中:iδ={1≤i≤n||wi>δ|},|iδ|表示iδ中的元素。
这里的阈值δ与比例系数α都是针对每一层的权重来考虑的,也就是说每一层都有独立的阈值δ与比例系数α。
本发明的有益效果是:
1、相比较使用通用公开噪声和人声数据集来训练,本方案的训练数据集中的噪声数据部分专门定制,数据量更多,覆盖面更广,对于人声数据部分,不仅包含通用公开数据集部分,还对各种场景定制了一些干净人声,对各种环境的鲁棒性更强。
2、不同于基于dnn的vad方法只关注当前帧信息,本方法考虑到了相邻帧的信息对当前帧vad的判决的影响,将当前帧和前后相邻帧的特征向量连接在一起,对应的判决标记也合并成一个向量连接起来,用于神经网络训练。
3、不同于mrcg特征,本方法提取语音的mfcc特征,在计算完fft子带的能量并做梅尔滤波之后,进行dct变换和lifter变换得到mfcc特征,并且对提取到的mfcc特征舍去其直流分量,并求其一阶差分,得到mfcc-delta特征,最后将mfcc和mfcc-delta特征拼接起来作为送入神经网络处理的特征。
4、本方法对训练完成的神经网络模型进行量化压缩,减少其占用存储空间大小。
5、本方法不仅节约了成本,提高了处理效率,同时也能精确的从带有噪声的语音中准确的定位出语音的开始和结束点,识别其中的语音部分,并删去非语音部分。
附图说明
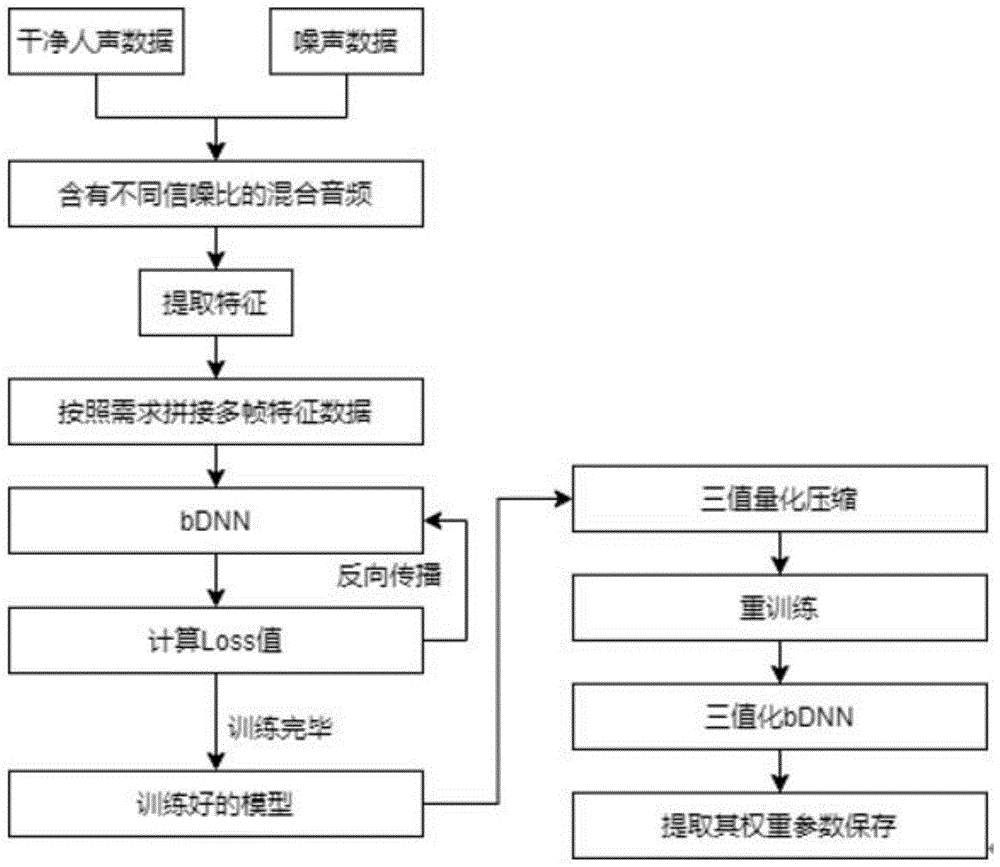
图1是本发明实施例所述基于三值量化压缩的vad实现方法训练流程图;
图2是本发明实施例所述基于三值量化压缩的vad实现方法测试流程图;
图3是本发明实施例所述的三值量化操作流程图;
图4是本发明实施例所述的将所有预测中包含待预测帧的结果求平均值得到当前帧的最终预测结果的示意图;
图5是本发明实施例所述的将特征数据拼接作为输入数据的示意图。
具体实施方式
下面结合附图对本发明的实施例进行详细说明。
实施例
如图1所示,一种基于三值量化压缩的vad实现方法,包括以下步骤:
a、提取人声数据及噪音数据,按预设定的信噪比结合,得到训练音频数据;
b、针对每一帧训练音频数据提取mfcc特征后,经拼接得到最终特征数据;
c、拼接多帧特征数据,输入神经网络进行数据训练;
d、接收训练后的数据模型,进行三值量化处理;
e、利用相同训练数据,训练三值化bdnn后,提取并保存其权重、参数。
在本实施例中,采用了三值量化压缩的vad实现方法(ternaryvoiceactivitydetection),以下简称tvad,主要包括数据预处理、神经网络(neuralnetwork)和量化处理部分三个部分。
数据预处理,是指对于纯净人声数据与噪声数据进行按不同信噪比进行融合得到原始数据集,然后进行预处理使其数据符合神经网络的计算需求;其中,数据预处理主要步骤包括:语音信号的预加重、分帧、加窗、短时快速傅里叶变换(fft)、计算不同fft子带的能量、梅尔滤波、dct变换、lifter变换等。
神经网络(neuralnetwork,nn)是人类基于人类大脑的神经网络设计出来的一种数学模型,用以模拟人脑的功能实现类人工智能。神经网络是一种运算模型,由大量的神经元之间相互联接构成。每个神经元代表一种特定的输出函数,称为激活函数(activationfunction)。每两个神经元间的连接都表示一个对于通过该连接信号的加权值,称之为权重。这个权重的大小会随着神经元之间连接的重要性改变而改变。在得到上一层神经元的加权和之后,加权和会经过一个激活函数,最后得到当前神经元的输出。
本实施例,网络结构为输入层、三个隐层、输出层;其目前的参数数目为输入层为24*5,三个隐层是128*64*32,输出层为5维。隐藏层的维度可自由调节以便获取更好的预测结果。
量化处理部分,是指对于神经网络的进行三值量化压缩从而降低神经网络模型所需要的存储空间。
在其中一个实施例中,如图2所示,还包括以下步骤:
f、提取人声数据及噪音数据,按预设定的信噪比结合,获取测试音频数据;
g、针对每一帧测试音频数据提取mfcc特征后,经拼接得到最终特征数据;
h、拼接多帧特征数据,输入神经网络进行数据训练;
i、进行三值化bdnn,计算待预测帧的预测值,待批量预测结束后,将所有预测中包含待预测帧的结果求平均值,得到当前帧的最终预测值。
本实施例,分为训练部分和测试部分,训练部分与测试部分中对输入神经网络的特征数据的处理方式相同,但测试部分在进行神经网络训练并经过三值化bdnn后会得到待预测帧的预测结果,等批量预测结束后将所有预测中包含待预测帧的结果求平均值即得到当前帧的最终预测结果。如图4所示,其中,每一行中虚线框中就是含有待预测帧的结果,将其取平均值,则得到待预测帧的最终预测结果。
在另一个实施例中,如图2所示,所述步骤i还包括以下步骤:
判断最终预测值是否大于设定阈值,若是,则判定待预测帧含语音,反之,则不含语音。
比较得到的待预测帧的最终预测结果与设定阈值的大小,大于设定阈值的即可认为含语音,小于阈值则认为不含语音。
在另一个实施例中,如图2所示,所述步骤i还包括以下步骤:
计算auc值作为评估标准,auc值取值为(0,1)。
计算auc值可以解决因为正负样本不均导致的问题,能够更好地反应模型的性能,auc值取值为(0,1),越接近于1表示预测效果越好。
在另一个实施例中,如图2所示,所述步骤i还包括以下步骤:
将测试音频的波形与预测结果进行可视化展示。
将预测值和波形图进行可视化直观展示模型,区别语音与非语音的效果。
在另一个实施例中,所述步骤a和步骤f中混合人声数据及噪音数据的步骤还包括:
p1、构造噪声数据列表与语料数据列表;
p2、设定每段音频的长度为l,从步骤s1中的噪声列表中随机选择音频进行串联,直到长度达到l;
p3、从步骤s1中的语料数据列表中随机选取一段音频,在所选取的音频首尾各添加音频总长度1/4的静音,重复选取至长度达到l;
p4、将选取的音频与噪声按预设定的信噪比结合,获取音频数据。
本实施例中p3步骤可在所选取的音频首尾各添加音频总长度1/4的静音,亦可在所选取的音频首尾各添加4秒的静音,具体以添加静音时间更短的方案为最优。
在另一个实施例中,所述步骤b和步骤g中提取mfcc特征的步骤还包括:
q1、对每一帧音频数据进行预加重,其中预加重因子取0.97;
q2、对每一帧音频数据进行分帧,设定帧长为32ms,帧移为16ms;
q3、基于汉明窗函数进行加窗,汉明窗函数如下:
q4、进行快速傅里叶变换,将信号分离到不同的子带;
q5、计算不同子带的能量;
q6、生成相应的梅尔滤波器对子带进行滤波,梅尔滤波函数如下:
q7、计算每个梅尔滤波器输出的对数能量;
q8、经离散余弦变换,得到mfcc系数;
q9、提取一阶差分参数;
q10、将mfcc系数与其一阶差分参数拼接,得到最终特征数据。
在另一个实施例中,所述步骤c和步骤h中拼接多帧特征数据的步骤包括:
s1、获取每一帧最终特征数据;
s2、提升每一帧的上下文信息,生成每一帧上的多个基预测;
s3、拼接包括待预测帧在内的5帧特征数据,输入神经网络进行数据训练。
本实施例使用待预测帧的相邻帧来联合预测待预测帧,通过提升帧的上下文信息来生成帧上的多个基预测,然后将基础预测聚合为更强的基础预测,相比于传统的dnn能实现更高的性能。
在本实施例中,取包含待预测帧在内的5帧特征数据拼接起来作为一组输入数据送入神经网络中进行训练,对于第一帧数据,我们在其前面补零,如图5所示,其中:每个方框代表一帧数据,其中虚线方框表示5帧数据拼接,xn表示待预测帧,当xn是输入数据第一帧时,由于算法需要其前面帧的数据,所以在此对其做补零处理,对待预测帧前面补10帧,数据为0。最终得到5帧特征数据共5*24=120维数据,送入神经网络作训练处理。
在另一个实施例中,如图3所示,所述步骤d中进行三值量化的步骤包括:
d1、接收训练后的数据模型,从该数据模型的矩阵中,计算得出阈值δ和缩放因子α,计算公式如下:
其中,iδ={1≤i≤n||wi>δ|},|iδ|表示iδ中的元素;
d2、将原权重转变为三值权重,三值权重公式如下:
d3、将输入x与缩放因子α相乘作为新的输入数据,并与三值权重进行加法计算进行正向传播;
d4、使用sgd算法反向传播进行迭代训练。
本实施例中,三值量化方法可以将权重从32bit浮点型量化为2bit定点型,即将原始浮点型权重用三值权重(-1,0,+1)与一个比例系数α相乘来近似表示。即:
其中,阈值δ从原权重矩阵w中产生,通过推导,其值为:
α的值为:
其中:iδ={1≤i≤n||wi>δ|},|iδ|表示iδ中的元素。
这里的阈值δ与比例系数α都是针对每一层的权重来考虑的,也就是说每一层都有独立的阈值δ与比例系数α。
以上所述实施例仅表达了本发明的具体实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!