分布式唤醒的语音增强方法和装置、存储介质与流程
本技术涉及智能家居,具体而言,涉及一种分布式唤醒的语音增强方法和装置、存储介质。
背景技术:
1、随着科技的发展,智能语音设备逐渐进入日常生活,智能语音设备想要听到声音,就需要依赖于麦克风阵列。
2、麦克风阵列就是由一定数据的声学传感器(例如,麦克风)组成,用来对声场的空间特性进行采样并处理的系统,在麦克风阵列中,麦克风会按照一定的几何结构摆放,比如线形、环形、球形等。在麦克风按照线形结构摆放时,根据麦克风的数量分为二麦线性阵列、四麦线性阵列、六麦线性阵列等。通过麦克风阵列对采集的不同空间方向的声音信号进行空时处理,实现回声消除、去混响、降噪、声源分离等功能,进而提高语音信号处理质量。
3、相关技术中,麦克风阵列的声源分离技术,可用波束形成和auxiva等技术实现,但是四麦线性阵列的波束低频主瓣较宽,语音信号处理质量较差,且四麦线阵的auxiva计算量较大,难以满足实时计算的要求。
4、针对相关技术中,麦克风阵列的波束低频主瓣较宽,语音信号处理质量较差等问题,尚未提出有效的解决方案。
技术实现思路
1、本技术实施例提供了一种分布式唤醒的语音增强方法和装置、存储介质,以至少解决相关技术中,麦克风阵列的波束低频主瓣较宽,语音信号处理质量较差等问题。
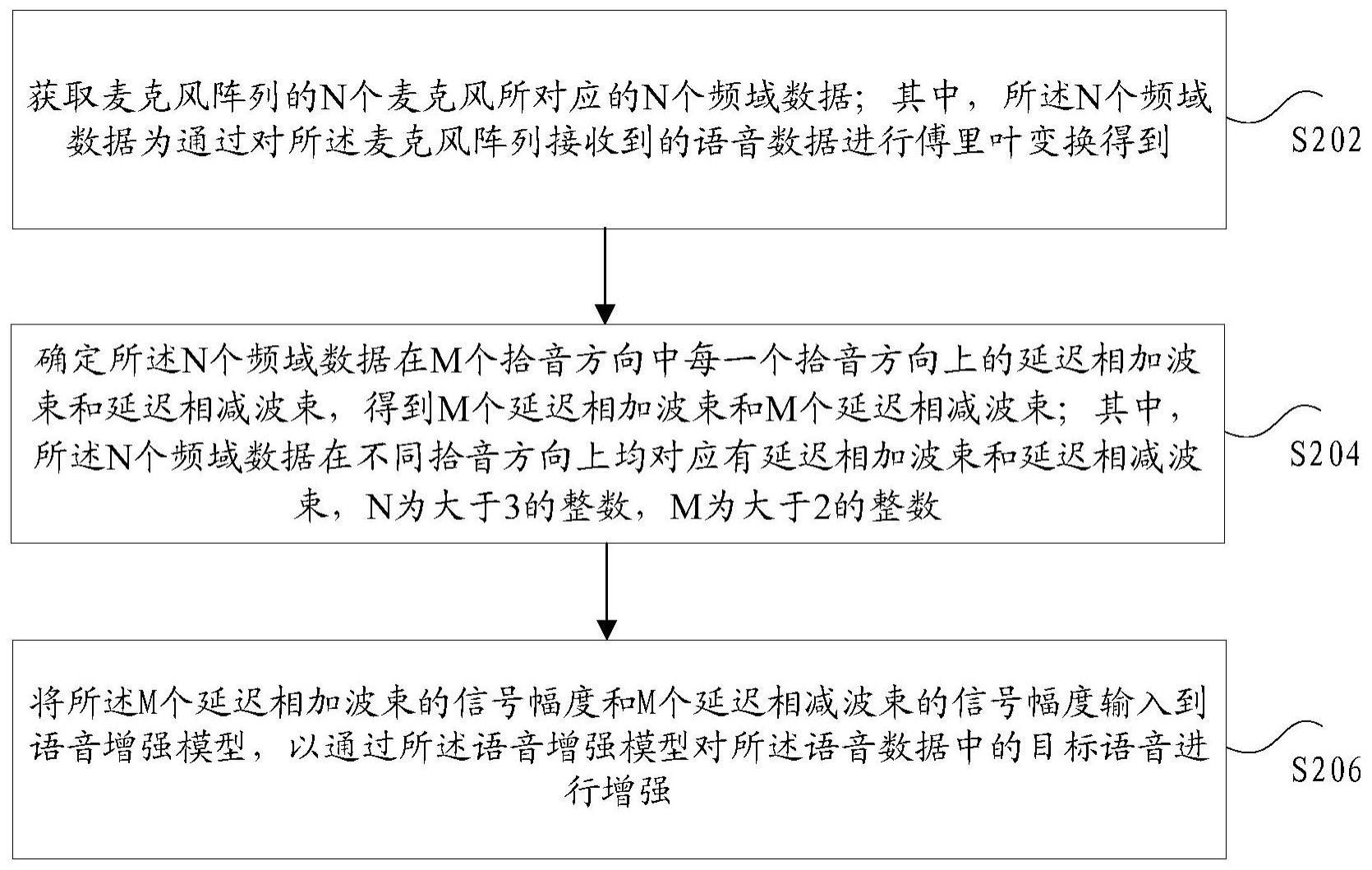
2、根据本技术实施例的一个实施例,提供了一种分布式唤醒的语音增强方法,包括:获取麦克风阵列的n个麦克风所对应的n个频域数据;其中,所述n个频域数据为通过对所述麦克风阵列接收到的语音数据进行傅里叶变换得到;确定所述n个频域数据在m个拾音方向中每一个拾音方向上的延迟相加波束和延迟相减波束,得到m个延迟相加波束和m个延迟相减波束;其中,所述n个频域数据在不同拾音方向上均对应有延迟相加波束和延迟相减波束,n为大于3的整数,m为大于2的整数;将所述m个延迟相加波束的信号幅度和m个延迟相减波束的信号幅度输入到语音增强模型,以通过所述语音增强模型对所述语音数据中的目标语音进行增强。
3、在一个示例性实施例中,确定所述n个频域数据在m个拾音方向中每一个拾音方向上的延迟相加波束和延迟相减波束,得到m个延迟相加波束和m个延迟相减波束,包括:对于m个拾音方向中每一个拾音方向,根据所述n个频域数据确定目标频域数据,以及根据在所述每一个拾音方向上所述n个麦克风之间的时延确定所述目标频域数据对应的权重矢量;根据所述目标频域数据和所述目标频域数据对应的权重矢量确定所述m个延迟相加波束和m个延迟相减波束,其中,所述目标频域数据用于指示所述n个频域数据对应的阵列信号。
4、在一个示例性实施例中,根据所述n个频域数据确定所述目标频域数据,包括:确定所述n个频域数据的对应的第一矩阵,其中,所述第一矩阵的行信息用于指示所述n个频域数据;根据所述第一矩阵确定所述目标频域数据。
5、在一个示例性实施例中,根据所述麦克风阵列在所述每一个拾音方向上所述 n个麦克风之间的时延确定所述目标频域数据对应的权重矢量,包括:确定n个麦克风中的每一个麦克风相对于目标麦克风的时延以及根据所述时间延时确定所述每一个麦克风对应的子权重矢量,其中,所述目标麦克风为最先接收到所述语音数据的麦克风;确定所述子权重矢量的对应的第二矩阵,其中,所述第二矩阵的列信息用于指示所述每一个麦克风对应的子权重矢量;根据麦克风阵列中的麦克风数量n和所述第二矩阵确定所述目标频域数据对应的权重矢量。
6、在一个示例性实施例中,确定n个麦克风中的每一个麦克风相对于目标麦克风的时延,包括:确定步骤:确定n个麦克风中的任一麦克风在坐标轴上的横坐标,以及任一麦克风在坐标轴上的纵坐标;确定所述横坐标和所述任一麦克风的拾音方向的余弦值的第一乘积,以及所述纵坐标和所述任一麦克风的拾音方向的正弦值的第二乘积;根据声速、第一乘积、第二乘积确定所述任一麦克风相对于目标麦克风的时延,其中,所述目标麦克风的坐标点为所述坐标轴的原点;根据声速、第一乘积、第二乘积确定所述任一麦克风相对于目标麦克风的时延;循环执行所述确定步骤,直至确定n个麦克风中的每一个麦克风相对于目标麦克风的时延。
7、在一个示例性实施例中,根据所述目标频域数据和所述目标频域数据对应的权重矢量确定所述m个延迟相加波束和m个延迟相减波束,包括:确定所述每一个拾音方向的所述目标频域数据和所述目标频域数据对应的权重矢量的卷积结果,根据所述卷积结果确定所述m个延迟相加波束;确定所述每一个拾音方向的所述目标频域数据和所述目标频域数据对应的权重矢量的卷积结果的共轭复数,根据所述共轭复数果确定所述m个相减相加波束。
8、在一个示例性实施例中,在m=3的情况下,将所述m个延迟相加波束的信号幅度和m个延迟相减波束的信号幅度输入到语音增强模型,以通过所述语音增强模型对所述语音数据中的目标语音进行增强之后,所述方法还包括:按照第一预设算法对第一拾音方向上的第一语音增强数据进行线性滤波,得到所述第一拾音方向上的语音增强结果,其中,所述第一预设算法包括:以所述第一拾音方向的延迟相加波束作为主波束,将第二拾音方向和第三拾音方向上的语音增强结果作为噪声参数;以及按照第二预设算法对第二拾音方向上的第二语音增强数据进行线性滤波,得到所述第二拾音方向上的语音增强结果,其中,所述第二预设算法包括:以所述第二拾音方向的延迟相加波束作为主波束,将第一拾音方向和第三拾音方向上的语音增强结果作为噪声参数;以及按照第三预设算法对第二拾音方向上的第三语音增强数据进行线性滤波,得到所述第二拾音方向上的语音增强结果,其中,所述第三预设算法包括:以所述第三拾音方向的延迟相加波束作为主波束,将第一拾音方向和第二拾音方向上的语音增强结果作为噪声参数;其中,所述第一语音增强数据,所述第二语音增强数据,第三语音增强数据为所述语音增强模型的输出结果。
9、根据本技术实施例的另一个实施例,还提供了一种分布式唤醒的语音增强方法装置,包括:获取模块,用于获取麦克风阵列的n个麦克风所对应的n个频域数据;其中,所述n个频域数据为通过对所述麦克风阵列接收到的语音数据进行傅里叶变换得到;确定模块,用于确定所述n个频域数据在m个拾音方向中每一个拾音方向上的延迟相加波束和延迟相减波束,得到m个延迟相加波束和 m个延迟相减波束;其中,所述n个频域数据在不同拾音方向上均对应有延迟相加波束和延迟相减波束,n为大于3的整数,m为大于2的整数;输入模块,用于将所述m个延迟相加波束的信号幅度和m个延迟相减波束的信号幅度输入到语音增强模型,以通过所述语音增强模型对所述语音数据中的目标语音进行增强。
10、根据本技术实施例的又一方面,还提供了一种计算机可读的存储介质,该计算机可读的存储介质中存储有计算机程序,其中,该计算机程序被设置为运行时执行上述分布式唤醒的语音增强方法。
11、根据本技术实施例的又一方面,还提供了一种电子装置,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其中,上述处理器通过计算机程序执行上述的分布式唤醒的语音增强方法。
12、在本技术实施例中,获取麦克风阵列的n个麦克风所对应的n个频域数据;其中,所述n个频域数据为通过对所述麦克风阵列接收到的语音数据进行傅里叶变换得到;确定所述n个频域数据在m个拾音方向中每一个拾音方向上的延迟相加波束和延迟相减波束,得到m个延迟相加波束和m个延迟相减波束;其中,所述n个频域数据在不同拾音方向上均对应有延迟相加波束和延迟相减波束,n 为大于3的整数,m为大于2的整数;将所述m个延迟相加波束的信号幅度和 m个延迟相减波束的信号幅度输入到语音增强模型,以通过所述语音增强模型对所述语音数据中的目标语音进行增强;采用上述技术方案,解决了由于麦克风阵列的波束低频主瓣较宽,语音信号处理质量较差等问题,进而本技术实施例中将 m个拾音方向的延迟相加波束和延迟相减波束作为语音增强模型的输入,增强语音信号处理质量。
- 还没有人留言评论。精彩留言会获得点赞!