一种语音识别方法、装置、存储介质及设备与流程
本技术涉及语音处理,尤其涉及一种语音识别方法、装置、存储介质及设备。
背景技术:
1、随着人工智能技术的不断突破和各种智能终端设备的日益普及,人机交互在人们日常工作、生活中出现的频率越来越高。语音识别技术也得到了广泛使用,涵盖了人机交互的各个领域。领域语音识别的核心难题在于存在大量的领域专业实体词汇,如何对语音识别中的实体词汇进行准确检测和纠错,以实现领域语音识别保持较高的准确率显得尤为关键。
2、现有的领域语音识别中对于实体词汇进行检测和纠错的方法通常包含两种:一种是纯文本的专业实体词汇的检测与纠错,该方案是在使用语音识别模型获得识别结果后,使用bert等自然语言处理模型检测识别结果句子中的实体名词,并修改实体名词中不合理的错误,但该方案实际上没有考虑到声学发音特征,其与语音识别是相割裂的,导致最终的识别结果虽然往往是能获得看似很合理的纠错结果,答有可能与真实的发音并不相符,出现矫枉过正的情况。而另一种则是直接对语音识别模型的纠错方案,该方案需要对语音识别模型进行更新学习,无法实现零样本学习,因此整个过程费时费力,成本较高,且识别准确率的提升幅度高度依赖于所构造的训练语料。但对于未构造的上下文说法,识别准确率通常提升幅度十分有限。另外,对语音识别模型进行更新学习存在一定增量学习的风险,即,难以保证更新后的语音识别模型对于已有领域词汇识别准确率不会产生下降的情况。由于现有的语音识别模型根据新的语料进行了更新,或多或少的会出现对之前训练数据的遗忘,而为了避免这个问题,往往需要采用配合之前的大量数据同步训练的方式,同样会造成费时费力。
技术实现思路
1、本技术实施例的主要目的在于提供一种语音识别方法、装置、存储介质及设备,能够在进行语音识别时,有效提高语音识别的效率和准确率。
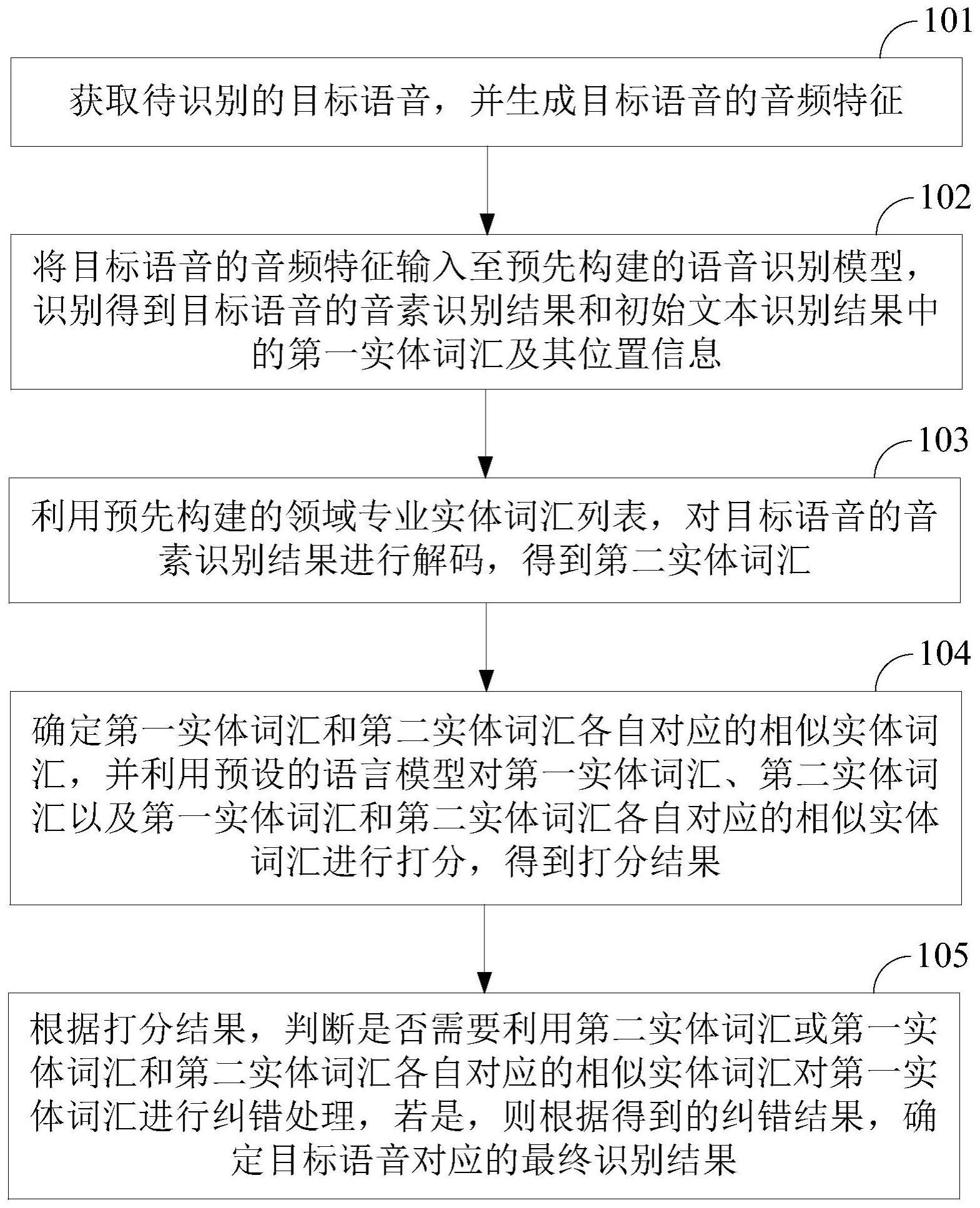
2、本技术实施例提供了一种语音识别方法,包括:
3、获取待识别的目标语音,并生成所述目标语音的音频特征;
4、将所述目标语音的音频特征输入至预先构建的语音识别模型,识别得到所述目标语音的音素识别结果和初始文本识别结果中的第一实体词汇及其位置信息;
5、利用预先构建的领域专业实体词汇列表,对所述目标语音的音素识别结果进行解码,得到第二实体词汇;
6、确定所述第一实体词汇和第二实体词汇各自对应的相似实体词汇,并利用预设的语言模型对所述第一实体词汇、第二实体词汇以及所述第一实体词汇和第二实体词汇各自对应的相似实体词汇进行打分,得到打分结果;
7、根据所述打分结果,判断是否需要利用第二实体词汇或所述第一实体词汇和第二实体词汇各自对应的相似实体词汇对所述第一实体词汇进行纠错处理,若是,则根据得到的纠错结果,确定所述目标语音对应的最终识别结果。
8、一种可能的实现方式中,所述目标语音的音频特征为所述目标语音的幅度谱特征。
9、一种可能的实现方式中,所述语音识别模型包括编码层、音素识别层、解码层和文本实体词汇检测层;所述将所述目标语音的音频特征输入至预先构建的语音识别模型,识别得到所述目标语音的音素识别结果和初始文本识别结果中的第一实体词汇及其位置信息,包括:
10、将所述目标语音的音频特征输入所述语音识别模型的编码层进行编码处理,得到所述目标语音的高维语音表征向量;
11、将所述目标语音的高维语音表征向量输入所述语音识别模型的音素识别层进行识别处理,得到所述目标语音的音素识别结果;
12、将所述目标语音的高维语音表征向量输入所述语音识别模型的解码层进行解码处理,得到所述目标语音的初始文本识别结果;
13、将所述目标语音的初始文本识别结果输入所述语音识别模型的文本实体词汇检测层进行检测处理,得到所述初始文本识别结果中的第一实体词汇及其位置信息。
14、一种可能的实现方式中,所述识别得到所述目标语音的音素识别结果和初始文本识别结果中的第一实体词汇及其位置信息之后,所述方法还包括:
15、根据所述第一实体词汇的位置信息和所述第一实体词汇的标记符号,确定所述目标语音所属的目标领域分类。
16、一种可能的实现方式中,所述利用预先构建的领域专业实体词汇列表,对所述目标语音的音素识别结果进行解码,得到第二实体词汇,包括:
17、将所述目标领域分类的领域专业实体词汇与所述目标语音的音素识别结果进行对齐处理,得到所述音素识别结果中所述第一实体词汇对应的发音序列;
18、将预先构建的所述目标领域分类的领域专业实体词汇列表打包成解码资源;并利用所述解码资源,对所述第一实体词汇对应的发音序列进行解码,得到第二实体词汇。
19、一种可能的实现方式中,所述确定所述第一实体词汇和第二实体词汇各自对应的相似实体词汇,包括:
20、对所述第一实体词汇和第二实体词汇分别进行相似音的拓展,并根据拓展结果确定第一实体词汇和第二实体词汇各自对应的相似实体词汇。
21、一种可能的实现方式中,所述根据所述打分结果,判断是否需要利用第二实体词汇或所述第一实体词汇和第二实体词汇各自对应的相似实体词汇对所述第一实体词汇进行纠错处理,若是,则根据得到的纠错结果,确定所述目标语音对应的最终识别结果,包括:
22、从所述第一实体词汇的得分、所述第二实体词汇的得分、以及所述第一实体词汇和第二实体词汇各自对应的相似实体词汇的得分中选择出第一高得分和第二得分;
23、计算所述第一高得分和第二得分的差值,并判断所述差值是否高于预设阈值,若是,则利用所述第一高得分对应的实体词汇对所述第一实体词汇进行纠错处理,得到所述目标语音对应的最终识别结果。
24、本技术实施例还提供了一种语音识别装置,包括:
25、获取单元,用于获取待识别的目标语音,并生成所述目标语音的音频特征;
26、识别单元,用于将所述目标语音的音频特征输入至预先构建的语音识别模型,识别得到所述目标语音的音素识别结果和初始文本识别结果中的第一实体词汇及其位置信息;
27、解码单元,用于利用预先构建的领域专业实体词汇列表,对所述目标语音的音素识别结果进行解码,得到第二实体词汇;
28、打分单元,用于确定所述第一实体词汇和第二实体词汇各自对应的相似实体词汇,并利用预设的语言模型对所述第一实体词汇、第二实体词汇以及所述第一实体词汇和第二实体词汇各自对应的相似实体词汇进行打分,得到打分结果;
29、纠错单元,用于根据所述打分结果,判断是否需要利用第二实体词汇或所述第一实体词汇和第二实体词汇各自对应的相似实体词汇对所述第一实体词汇进行纠错处理,若是,则根据得到的纠错结果,确定所述目标语音对应的最终识别结果。
30、一种可能的实现方式中,所述目标语音的音频特征为所述目标语音的幅度谱特征。
31、一种可能的实现方式中,所述语音识别模型包括编码层、音素识别层、解码层和文本实体词汇检测层;所述识别单元包括:
32、第一输入子单元,用于将所述目标语音的音频特征输入所述语音识别模型的编码层进行编码处理,得到所述目标语音的高维语音表征向量;
33、第二输入子单元,用于将所述目标语音的高维语音表征向量输入所述语音识别模型的音素识别层进行识别处理,得到所述目标语音的音素识别结果;
34、第三输入子单元,用于将所述目标语音的高维语音表征向量输入所述语音识别模型的解码层进行解码处理,得到所述目标语音的初始文本识别结果;
35、第四输入子单元,用于将所述目标语音的初始文本识别结果输入所述语音识别模型的文本实体词汇检测层进行检测处理,得到所述初始文本识别结果中的第一实体词汇及其位置信息。
36、一种可能的实现方式中,所述装置还包括:
37、确定单元,用于根据所述第一实体词汇的位置信息和所述第一实体词汇的标记符号,确定所述目标语音所属的目标领域分类。
38、一种可能的实现方式中,所述解码单元包括:
39、对齐子单元,用于将所述目标领域分类的领域专业实体词汇与所述目标语音的音素识别结果进行对齐处理,得到所述音素识别结果中所述第一实体词汇对应的发音序列;
40、解码子单元,用于将预先构建的所述目标领域分类的领域专业实体词汇列表打包成解码资源;并利用所述解码资源,对所述第一实体词汇对应的发音序列进行解码,得到第二实体词汇。
41、一种可能的实现方式中,所述打分单元具体用于:
42、对所述第一实体词汇和第二实体词汇分别进行相似音的拓展,并根据拓展结果确定第一实体词汇和第二实体词汇各自对应的相似实体词汇。
43、一种可能的实现方式中,所述纠错单元包括:
44、选择子单元,用于从所述第一实体词汇的得分、所述第二实体词汇的得分、以及所述第一实体词汇和第二实体词汇各自对应的相似实体词汇的得分中选择出第一高得分和第二得分;
45、纠错子单元,用于计算所述第一高得分和第二得分的差值,并判断所述差值是否高于预设阈值,若是,则利用所述第一高得分对应的实体词汇对所述第一实体词汇进行纠错处理,得到所述目标语音对应的最终识别结果。
46、本技术实施例还提供了一种语音识别设备,包括:处理器、存储器、系统总线;
47、所述处理器以及所述存储器通过所述系统总线相连;
48、所述存储器用于存储一个或多个程序,所述一个或多个程序包括指令,所述指令当被所述处理器执行时使所述处理器执行上述语音识别方法中的任意一种实现方式。
49、本技术实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有指令,当所述指令在终端设备上运行时,使得所述终端设备执行上述语音识别方法中的任意一种实现方式。
50、本技术实施例还提供了一种计算机程序产品,所述计算机程序产品在终端设备上运行时,使得所述终端设备执行上述语音识别方法中的任意一种实现方式。
51、本技术实施例提供的一种语音识别方法、装置、存储介质及设备,首先获取待识别的目标语音,并生成目标语音的音频特征,然后将目标语音的音频特征输入至预先构建的语音识别模型,识别得到目标语音的音素识别结果和初始文本识别结果中的第一实体词汇及其位置信息;接着,利用预先构建的领域专业实体词汇列表,对目标语音的音素识别结果进行解码,得到第二实体词汇;再确定第一实体词汇和第二实体词汇各自对应的相似实体词汇,并利用预设的语言模型对第一实体词汇、第二实体词汇以及第一实体词汇和第二实体词汇各自对应的相似实体词汇进行打分,得到打分结果;进而可以根据打分结果,判断是否需要利用第二实体词汇或第一实体词汇和第二实体词汇各自对应的相似实体词汇对第一实体词汇进行纠错处理,若是,则根据得到的纠错结果,确定目标语音对应的最终识别结果。
52、可见,本技术既实现了文本实体词汇检测的高效性,又添加了根据音素识别结果进行实体词汇纠错的先进性,同时还不需要对已有的语音识别模型进行更新迭代,从而有效提高了语音识别的效率和准确率。
- 还没有人留言评论。精彩留言会获得点赞!