音频信号处理方法、装置、电子设备及存储介质与流程
本公开涉及通信,尤其涉及音频信号处理方法、装置、电子设备及存储介质。
背景技术:
1、随着音频技术的发展以及人们日常生活的娱乐需求,越来越多的用户通过客户端进行点歌、k歌等娱乐活动。在用户进行唱歌过程中,用户还可以利用麦克风收录唱歌时的声音信号,以及利用耳返设备将麦克风收录的声音信号与伴奏音乐进行混音,再将混音后的音频信号反馈给用户,形成一条正反馈传输通路。这一正反馈的过程中,由于耳返设备反馈的混音后的音频信号,容易再次被麦克风收录到,从而在麦克风收录到的麦克风信号中包含用户的声音信号以及再次被收录的混音后的音频信号(混音后的音频信号也称为啸叫信号),从而,影响人的声音信号的收录质量。因此,出现了抑制啸叫信号的方法。
2、目前的抑制啸叫信号的方法,通常是将麦克风收录到的麦克风信号进行频域分析,然后,根据频谱上的频谱平坦度、自相关值、峰值谐波功率比等特征进行检测,得到检测结果。然后,再基于检测结果,采用陷波抑制的方法消除收录的麦克风信号中的啸叫信号。
3、然而,目前的抑制啸叫的方法中,针对不同歌曲、不同用户产出的声音信号的多样性,频谱分析耗时较长,且计算量大,仅基于声音信号的频谱特征进行啸叫信号的抑制处理,处理效率较低。
技术实现思路
1、本公开提供一种音频信号处理方法、装置、电子设备及存储介质,以至少解决相关技术中音频信号处理效率较低的问题。本公开的技术方案如下:
2、根据本公开实施例的第一方面,提供一种音频信号处理方法,所述方法包括:
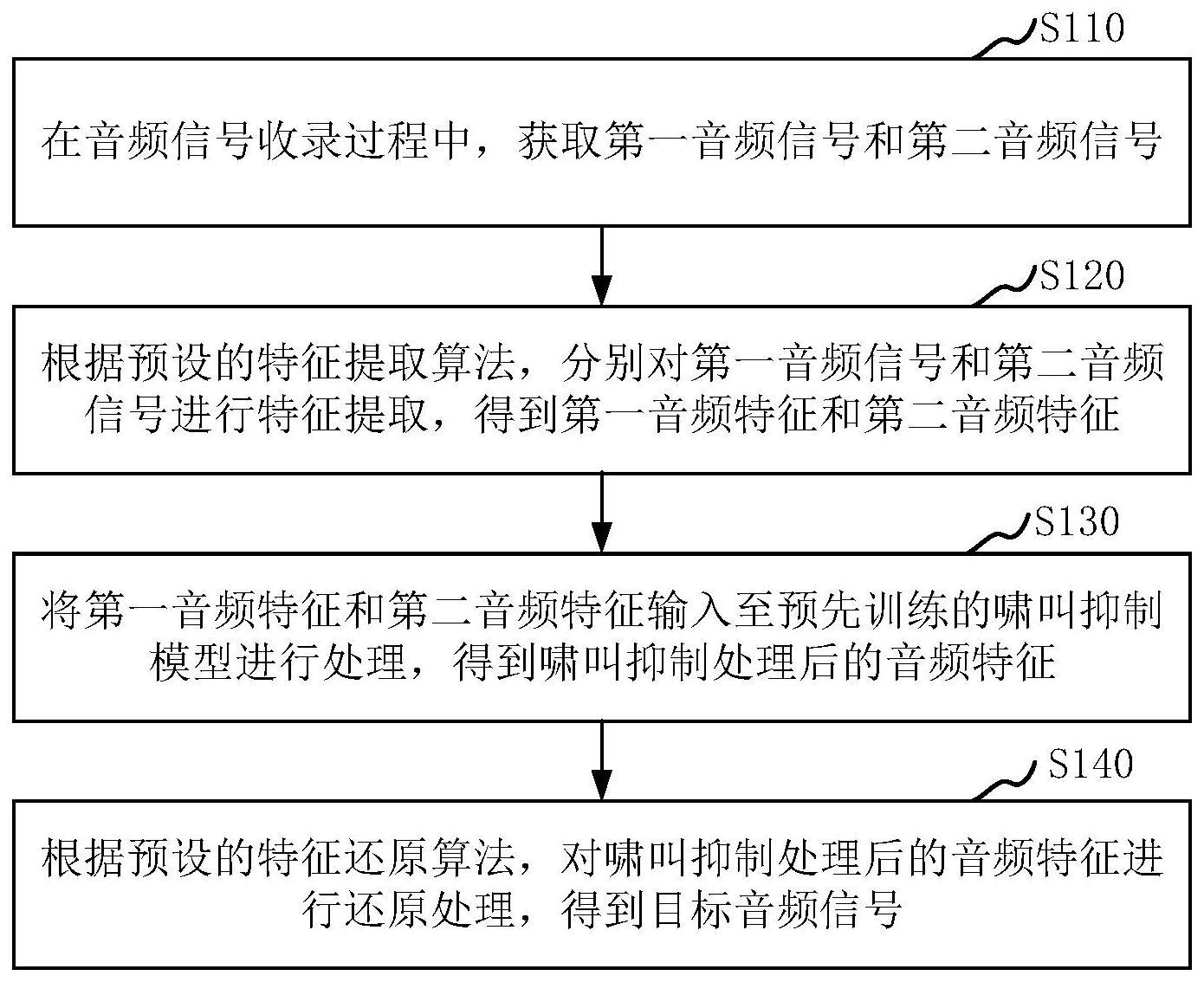
3、在音频信号收录过程中,获取第一音频信号和第二音频信号;所述第一音频信号包含目标对象的声音信号以及啸叫信号,所述第二音频信号为与所述声音信号对应的背景音频信号;
4、根据预设的特征提取算法,分别对所述第一音频信号和所述第二音频信号进行特征提取,得到第一音频特征和第二音频特征;
5、将所述第一音频特征和所述第二音频特征输入至预先训练的啸叫抑制模型进行处理,得到啸叫抑制处理后的音频特征;
6、根据预设的特征还原算法,对所述啸叫抑制处理后的音频特征进行还原处理,得到目标音频信号。
7、在一示例性实施例中,所述根据预设的特征提取算法,分别对所述第一音频信号和所述第二音频信号进行特征提取,得到第一音频特征和第二音频特征,包括:
8、对所述第一音频信号和所述第二音频信号进行短时傅里叶变换处理,得到处理后频域上的第一转换信号和第二转换信号;
9、根据预设的采样策略对频域上的所述第一转换信号和所述第二转换信号进行采样,分别得到第一转换信号对应的多个采样点数据以及所述第二转换信号对应的多个采样点数据;
10、对所述第一转换信号对应的多个采样点数据以及所述第二转换信号对应的多个采样点分别进行压缩分带处理,得到所述第一音频信号对应的第一音频特征和所述第二音频信号对应的第二音频特征。
11、在一示例性实施例中,所述啸叫抑制模型包括卷积层、门控循环单元、全连接层和激活层,所述将所述第一音频特征和所述第二音频特征输入至预先训练的啸叫抑制模型进行处理,得到啸叫抑制处理后的音频特征,包括:
12、将所述第一音频特征和所述第二音频特征输入至所述啸叫抑制模型中;
13、依次通过所述啸叫抑制模型中的卷积层、门控循环单元、全连接层和激活层对所述第一音频特征和所述第二音频特征进行处理,输出啸叫抑制处理后的音频特征。
14、在一示例性实施例中,所述根据预设的特征还原算法,对所述啸叫抑制处理后的音频特征进行还原处理,得到目标音频信号,包括:
15、对所述啸叫抑制处理后的音频特征进行还原处理,得到频域上的还原音频信号;
16、根据反短时傅里叶变换算法,对所述频域上的还原音频信号进行逆变换,得到还原后的时域上的目标音频信号。
17、在一示例性实施例中,所述在音频信号收录过程中,获取包含第一音频信号和第二音频信号,包括:
18、在音频信号收录过程中,通过音频信号收录部件采集目标对象演唱的声音信号以及啸叫信号,得到包含所述声音信号和所述啸叫信号的第一音频信号;
19、通过混音反馈部件获取与所述声音信号对应的背景音频信号,作为第二音频信号。
20、在一示例性实施例中,所述在音频信号收录过程中,获取第一音频信号和第二音频信号之前,所述方法还包括:
21、获取音频训练样本;所述音频训练样本中包含对第三音频信号特征提取得到的第三音频特征和对第四音频信号特征提取得到的第四音频特征;所述第三音频信号包含目标对象的声音信号以及啸叫信号,所述第四音频信号为与所述声音信号对应的背景音频信号;
22、根据所述音频训练样本对预设的啸叫抑制模型进行模型训练,输出训练音频特征;
23、根据预设的特征还原算法,对所述训练音频特征进行特征还原处理,得到训练音频信号;
24、根据预设的标准音频信号对所述训练音频信号进行损失计算,直至所述训练音频信号对应的损失结果满足预设的损失条件时,确定所述啸叫抑制模型训练完成;所述标准音频信号为所述目标对象的声音信号。
25、在一示例性实施例中,所述根据预设的标准音频信号对所述训练音频信号进行损失计算,直至所述训练音频信号对应的损失结果满足预设的损失条件时,确定所述啸叫抑制模型训练完成,包括:
26、将所述训练音频信号与预设的标准音频信号进行预设倍数的压缩处理,得到压缩后的训练音频信号和压缩后的标准音频信号;
27、确定所述压缩后的训练音频信号和所述压缩后的标准音频信号中各采样点间的幅度谱距离,将所述幅度谱距离作为所述训练音频信号对应的损失结果;
28、在所述训练音频信号对应的损失结果满足预设的损失条件的情况下,确定所述啸叫抑制模型训练完成。
29、根据本公开实施例的第二方面,提供一种音频信号处理装置,所述装置包括:
30、获取单元,被配置为执行在音频信号收录过程中,获取第一音频信号和第二音频信号;所述第一音频信号包含目标对象的声音信号以及啸叫信号,所述第二音频信号为与所述声音信号对应的背景音频信号;
31、特征提取单元,被配置为执行根据预设的特征提取算法,分别对所述第一音频信号和所述第二音频信号进行特征提取,得到第一音频特征和第二音频特征;
32、处理单元,被配置为执行将所述第一音频特征和所述第二音频特征输入至预先训练的啸叫抑制模型进行处理,得到啸叫抑制处理后的音频特征;
33、还原单元,被配置为执行根据预设的特征还原算法,对所述啸叫抑制处理后的音频特征进行还原处理,得到目标音频信号。
34、在一示例性实施例中,所述特征提取单元,包括:
35、第一处理子单元,被配置为执行对所述第一音频信号和所述第二音频信号进行短时傅里叶变换处理,得到处理后频域上的第一转换信号和第二转换信号;
36、采样子单元,被配置为执行根据预设的采样策略对频域上的所述第一转换信号和所述第二转换信号进行采样,分别得到第一转换信号对应的多个采样点数据以及所述第二转换信号对应的多个采样点数据;
37、第二处理子单元,被配置为执行对所述第一转换信号对应的多个采样点数据以及所述第二转换信号对应的多个采样点分别进行压缩分带处理,得到所述第一音频信号对应的第一音频特征和所述第二音频信号对应的第二音频特征。
38、在一示例性实施例中,所述啸叫抑制模型包括卷积层、门控循环单元、全连接层和激活层,所述处理单元,包括:
39、输入子单元,被配置为执行将所述第一音频特征和所述第二音频特征输入至所述啸叫抑制模型中;
40、输出子单元,被配置为执行依次通过所述啸叫抑制模型中的卷积层、门控循环单元、全连接层和激活层对所述第一音频特征和所述第二音频特征进行处理,输出啸叫抑制处理后的音频特征。
41、在一示例性实施例中,所述还原单元,包括:
42、转换子单元,被配置为执行对所述啸叫抑制处理后的音频特征进行还原处理,得到频域上的还原音频信号;
43、还原子单元,被配置为执行根据反短时傅里叶变换算法,对所述频域上的还原音频信号进行逆变换,得到还原后的时域上的目标音频信号。
44、在一示例性实施例中,所述获取单元,包括:
45、第一获取子单元,被配置为执行在音频信号收录过程中,通过音频信号收录部件采集目标对象演唱的声音信号以及啸叫信号,得到包含所述声音信号和所述啸叫信号的第一音频信号;
46、第二获取子单元,被配置为执行通过混音反馈部件获取与所述声音信号对应的背景音频信号,作为第二音频信号。
47、在一示例性实施例中,所述装置还包括:
48、训练获取单元,被配置为执行获取音频训练样本;所述音频训练样本中包含对第三音频信号特征提取得到的第三音频特征和对第四音频信号特征提取得到的第四音频特征;所述第三音频信号包含目标对象的声音信号以及啸叫信号,所述第四音频信号为与所述声音信号对应的背景音频信号;
49、模型训练单元,被配置为执行根据所述音频训练样本对预设的啸叫抑制模型进行模型训练,输出训练音频特征;
50、训练还原单元,被配置为执行根据预设的特征还原算法,对所述训练音频特征进行特征还原处理,得到训练音频信号;
51、训练判别单元,被配置为执行根据预设的标准音频信号对所述训练音频信号进行损失计算,直至所述训练音频信号对应的损失结果满足预设的损失条件时,确定所述啸叫抑制模型训练完成;所述标准音频信号为所述目标对象的声音信号。
52、在一示例性实施例中,所述训练判别单元,包括:
53、损失计算子单元,被配置为执行将所述训练音频信号与预设的标准音频信号进行预设倍数的压缩处理,得到压缩后的训练音频信号和压缩后的标准音频信号;确定所述压缩后的训练音频信号和所述压缩后的标准音频信号中各采样点间的幅度谱距离,将所述幅度谱距离作为所述训练音频信号对应的损失结果;
54、确定子单元,被配置为执行在所述训练音频信号对应的损失结果满足预设的损失条件的情况下,确定所述啸叫抑制模型训练完成。
55、根据本公开实施例的第三方面,提供一种电子设备,包括:
56、处理器;
57、用于存储所述处理器可执行指令的存储器;
58、其中,所述处理器被配置为执行所述指令,以实现如上述第一方面中任一项所述的音频信号处理展示方法。
59、根据本公开实施例的第四方面,提供一种计算机可读存储介质,当所述计算机可读存储介质中的指令由电子设备的处理器执行时,使得所述电子设备能够执行如上述第一方面中任一项所述的音频信号处理方法。
60、根据本公开实施例的第五方面,提供一种计算机程序产品,所述指令被电子设备的处理器执行时,使得所述电子设备能够执行上述第一方面中任一项所述的音频信号处理方法。
61、本公开的实施例提供的技术方案至少带来以下有益效果:
62、采用本方法,通过预先对第一音频信号和第二音频信号进行特征提取,以及对模型输出的啸叫抑制处理后的音频特征进行还原处理,简化了啸叫抑制模型的复杂度,减少模型计算量,并且,通过预先训练的啸叫抑制模型实现对第一音频信号中啸叫信号的抑制,提高了啸叫信号抑制处理的效率。
63、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
- 还没有人留言评论。精彩留言会获得点赞!