声纹识别模型训练方法、装置、电子设备及存储介质与流程
本技术涉及声纹识别,还涉及人工智能,具体涉及一种声纹识别模型训练方法、装置、电子设备及存储介质。
背景技术:
1、声纹识别(voiceprint recognition,vpr)技术,也称为说话人识别(speakerrecognition,sr)技术,属于生物特征识别技术的一种,包括说话人辨认和说话人确认。人类声音的产生过程是语言中枢和发音器官之间的复杂生理过程,尽管每个人的声音受如年龄、身体状况、情绪波动等各种因素的影响而具有一定的可变性,但由于每个人的发声器官如舌头、牙齿、肺、鼻腔等的大小和形态基本都不相同,因此不同人的声音仍然是具有区分性的。声纹识别是计算机利用语音波形中所包含的反映特定说话人生理和行为特征的语音特征参数来自动识别说话人身份的技术。
2、另外,利用声纹识别技术,说话人确认是比较给定的两段语音,并验证它们是否来自同一个说话人。近年来,随着深度神经网络取得的巨大进展,说话人确认技术也深受影响,逐渐从传统的基于概率统计方法转移到基于深度学习的方法。目前说话人确认已经变成一种日常生活中的一项重要技术,如生物认证、智能控制等。但是当前的说话人确认系统在真实工业应用场景下的表现仍然不太令人满意,数据量的缺失是复杂场景下性能鲁棒性的一个关键挑战,因此音频数据的需求也与日俱增。
3、在用于声纹识别的神经网络以及用于说话人确认的神经网络的训练过程中,数据增强是一种解决数据缺失、增加训练样本数量和分布多样性的重要技术。现有技术中常用的数据增强包括加噪声、加混响和速度扰动,还有将语音识别中常用的specaugment(即在训练过程中对频谱直接进行掩码)技术应用到上述神经网络中。这些方法都是直接操作原始的语音信号,是信号级别的增强方法,因此生成的增强样本多样性会受到限制。除此之外,这些增强方法也会带来巨大的计算和i/o开销。
4、现有技术中还提出利用深度生成模型如generative adversarial networks(gans)、variational autoencoder(vae)等网络来学习带噪声的说话人特征分布,并从这个分布中生成新的特征。但是这些方法需要利用复杂的深度生成模型去显式地增强样本,很大程度上减慢了声纹识别模型的训练过程。还有一种方法通过从指定噪声数据生成纯噪声分布,然后再从中生成新的噪声加到原始的数据特征上来增强数据,这种方法的缺点是这种分布需要依赖于额外的特定噪声数据集,并且生成样本的多样性也远远不够。
技术实现思路
1、鉴于以上问题,本技术实施例提供一种声纹识别模型训练方法、装置、电子设备及存储介质,以解决上述技术问题。
2、第一方面,本技术实施例提供一种声纹识别模型训练方法,包括:
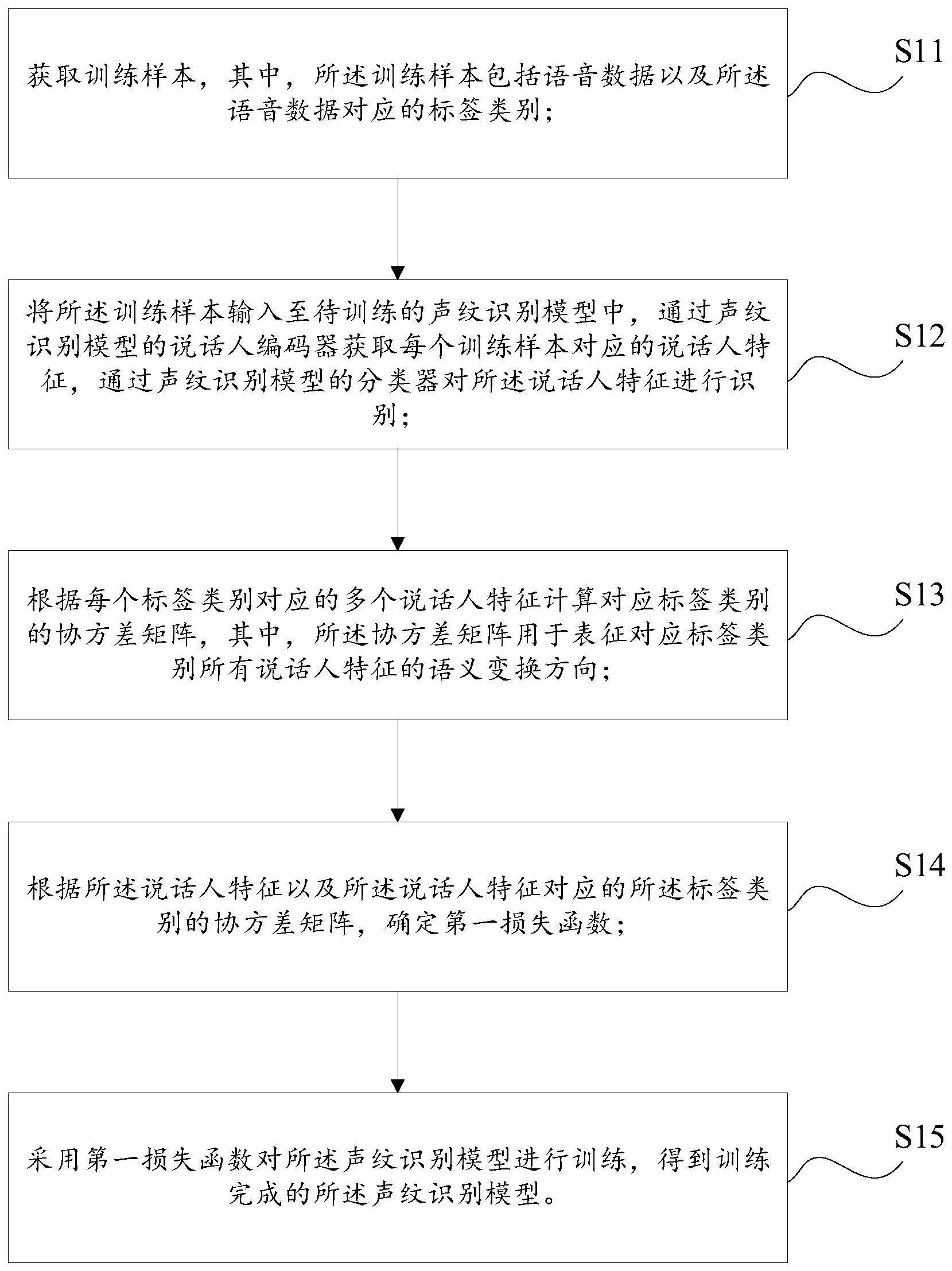
3、获取训练样本,其中,所述训练样本包括语音数据以及所述语音数据对应的标签类别;
4、将所述训练样本输入至待训练的声纹识别模型中,通过声纹识别模型的说话人编码器获取每个训练样本对应的说话人特征,通过声纹识别模型的分类器对所述说话人特征进行识别;
5、根据每个标签类别对应的多个说话人特征计算对应标签类别的协方差矩阵,其中,所述协方差矩阵用于表征对应标签类别所有说话人特征的语义变换方向;
6、根据所述说话人特征以及所述说话人特征对应的所述标签类别的协方差矩阵,确定第一损失函数;
7、采用第一损失函数对所述声纹识别模型进行训练,得到训练完成的所述声纹识别模型。
8、可选地,所述根据每个标签类别对应的多个说话人特征计算对应标签类别的协方差矩阵之后,还包括:
9、根据所述说话人特征对应的标签类别的权重矩阵以及所述说话人特征计算所述说话人特征的难度系数,其中,所述难度系数用于表征对应说话人特征的识别难度;
10、相应地,所述根据所述说话人特征以及所述说话人特征对应的所述标签类别的协方差矩阵,确定第一损失函数,包括:
11、根据所述说话人特征、所述说话人特征对应的难度系数以及所述说话人特征对应的所述标签类别的协方差矩阵,确定第一损失函数。
12、可选地,所述第一损失函数为:
13、
14、其中,n为训练样本的总数,c为标签类别的数量,fi为第i个训练样本的说话人特征,yi为第i个训练样本的标签类别,wyi为第i个训练样本的标签类别yi对应的权重矩阵,wj为第j个标签类别对应的权重矩阵,∑yi为第i个训练样本对应的标签类别yi的协方差矩阵,dilli为第i个训练样本的难度系数,m为第一超参数,s为第二超参数,λ为第三超参数。
15、可选地,所述根据每个标签类别对应的多个说话人特征计算对应标签类别的协方差矩阵,包括:
16、根据标签类别对应的多个训练样本的说话人特征获取所述标签类别的类别均值中心μj,其中,fk为第j个标签类别中第k个训练样本的说话人特征,m为第j个标签类别的训练样本的数量;
17、根据所述类别均值中心以及所述标签类别的所有说话人特征,获取所述标签类别的协方差矩阵中每个矩阵元素∑j(m,n),其中,∑j(m,n)为协方差矩阵∑j中第m行、第n列的矩阵元素,和分别为第j个标签类别中第k个训练样本的说话人特征在第m维和第n维的数值,和分别为第j个标签类别的类别均值中心μj在第m维和第n维的数值,d为说话人特征的维度。
18、可选地,所述采用第一损失函数对所述声纹识别模型进行训练,得到训练完成的所述声纹识别模型之后,还包括:
19、利用训练完成的声纹识别模型的说话人编码器对训练集中每个语音样本进行声纹特征提取,得到所述语音样本对应的说话人特征;
20、根据每个标签类别对应的多个说话人特征计算对应标签类别的协方差矩阵,其中,所述协方差矩阵用于表征对应标签类别所有说话人特征的语义变换方向;
21、根据所述说话人特征以及对应的所述标签类别的协方差矩阵,为所述说话人特征建立高斯分布,从所述高斯分布中采样出具有无限语义转换的说话人增强特征。
22、可选地,所述根据所述标签类别对应的多个说话人特征以及协方差矩阵,为所述标签类别建立高斯分布,从所述高斯分布中采样出具有无限语义转换的说话人增强特征之后,还包括:
23、利用所述标签类别的多个说话人特征以及多个说话人增强特征构建所述标签类别的训练数据集;
24、利用所述训练数据集以及所述第一损失函数对所述声纹识别模型的分类器进行训练,得到优化的声纹识别模型。
25、第二方面,本技术实施例提供一种声纹识别方法,包括:
26、将待识别语音数据输入至声纹识别模型,输出所述待识别语音的识别结果,其中,所述声纹识别模型是根据上述的声纹识别模型训练方法训练获取的。
27、第三方面,本技术实施例提供一种声纹识别模型训练装置,包括:
28、训练样本构建模块,用于获取训练样本,其中,所述训练样本包括语音数据以及所述语音数据对应的标签类别;
29、声纹识别模块,用于将所述训练样本输入至待训练的声纹识别模型中,通过声纹识别模型的说话人编码器获取每个训练样本对应的说话人特征,通过声纹识别模型的分类器对所述说话人特征进行识别;
30、样本增强模块,用于根据每个标签类别对应的多个说话人特征计算对应标签类别的协方差矩阵,其中,所述协方差矩阵用于表征对应标签类别所有说话人特征的语义变换方向;
31、损失计算模块,用于根据所述说话人特征以及所述说话人特征对应的所述标签类别的协方差矩阵,确定第一损失函数;
32、参数调节模块,用于采用第一损失函数对所述声纹识别模型进行训练,得到训练完成的所述声纹识别模型。
33、第四方面,本技术实施例提供一种电子设备,包括处理器、以及与所述处理器耦接的存储器,所述存储器存储有可被所述处理器执行的程序指令;所述处理器执行所述存储器存储的所述程序指令时实现上述的声纹识别模型训练方法或者实现上述的声纹识别方法。
34、第五方面,本技术实施例提供一种存储介质,所述存储介质内存储有程序指令,所述程序指令被处理器执行时实现能够实现上述的声纹识别模型训练方法或者实现上述的声纹识别方法。
35、本技术实施例提供的声纹识别模型训练方法、装置、电子设备及存储介质,包括如下步骤:获取训练样本;将所述训练样本输入至待训练的声纹识别模型中,通过声纹识别模型的说话人编码器获取每个训练样本对应的说话人特征,通过声纹识别模型的分类器对所述说话人特征进行识别;根据每个标签类别对应的多个说话人特征计算对应标签类别的协方差矩阵;根据所述说话人特征以及所述说话人特征对应的所述标签类别的协方差矩阵,确定第一损失函数;采用第一损失函数对所述声纹识别模型进行训练,得到训练完成的所述声纹识别模型;通过上述方式,利用对应标签类别的协方差矩阵实现对说话人特征的语义上的数据增强,将说话人特征以及对应标签类别的协方差矩阵融入到第一损失函数的计算中,在模型的训练过程中实现了特征空间上的数据增强,能够解决声纹识别模型数据增强困难的问题,具有实现了语义数据增强的效果,还具有提高了声纹识别模型的识别准确性的效果。并且,本技术的训练方法无需直接对语音训练样本进行数据增强,有利于简化模型训练的过程,同时,数据增强可以体现在第一损失函数的构建中,无需改变声纹识别模型的结构,能够兼容各种不同网络结构的声纹识别模型。
36、本技术的这些方面或其他方面在以下实施例的描述中会更加简明易懂。
- 还没有人留言评论。精彩留言会获得点赞!