发音评测方法、装置、设备及存储介质与流程
本申请涉及计算机,尤其涉及一种发音评测方法、装置、设备及存储介质。
背景技术:
1、发音评测技术是计算机辅助语言学习的一个细分方向,其可通过对用户的发音音频进行分析,输出用户关于发音准确度、流利度以及完整度等指标的分数,以便用户基于各种指标的分数纠正自身发音的问题。
2、在现有技术中,家长可指导孩子按照学习设备显示的文本进行朗读时,学习设备采集孩子的音频,基于音频对孩子的发音进行评测。在家长指导孩子朗读文本时,家长可能会先亲自示范文本的发音,再让孩子跟读,此时学习设备会采集到包含有家长发音和孩子发音的音频。基于该音频进行发音评测得到的是针对家长发音和孩子发音的评测结果,评测结果不够准确。
技术实现思路
1、本申请提供一种发音评测方法、装置、设备及存储介质,以解决现有技术中对孩子发音和家长发音进行综合评测而影响评测结果准确性的问题,提高评测结果的准确性。
2、第一方面,本申请提供了一种发音评测方法,包括:
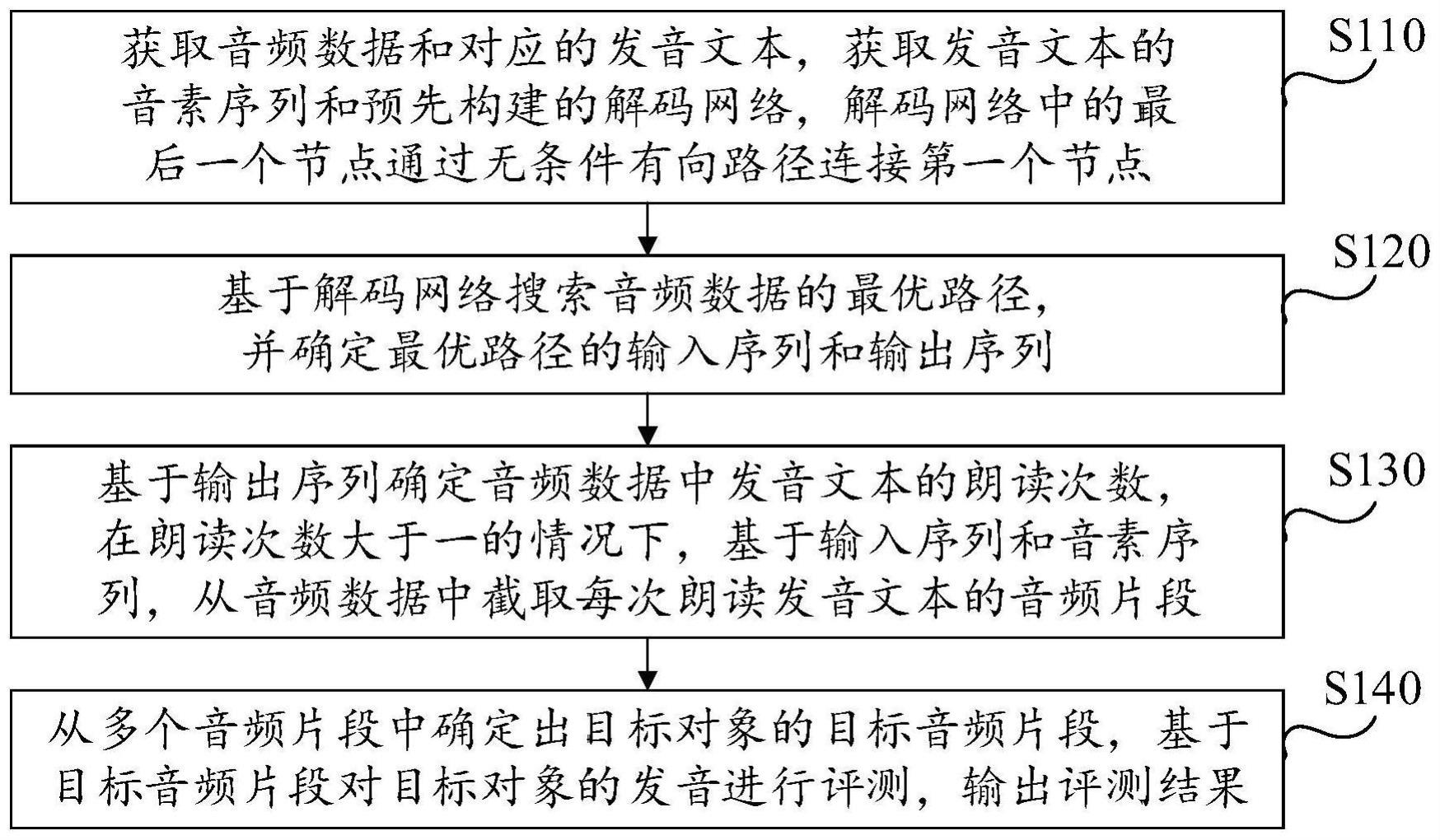
3、获取音频数据和对应的发音文本,获取所述发音文本的音素序列和预先构建的解码网络,所述解码网络中的最后一个节点通过无条件有向路径连接第一个节点;
4、基于所述解码网络搜索所述音频数据的最优路径,并确定所述最优路径的输入序列和输出序列;
5、基于所述输出序列确定所述音频数据中所述发音文本的朗读次数,在所述朗读次数大于一的情况下,基于所述输入序列和所述音素序列,从所述音频数据中截取每次朗读所述发音文本的音频片段;
6、从多个所述音频片段中确定出目标对象的目标音频片段,基于所述目标音频片段对所述目标对象的发音进行评测,输出评测结果。
7、第二方面,本申请提供了一种发音评测装置,包括:
8、数据获取模块,被配置为获取音频数据和对应的发音文本,获取所述发音文本的音素序列和预先构建的解码网络,所述解码网络中的最后一个节点通过无条件有向路径连接第一个节点;
9、路径搜索模块,被配置为基于所述解码网络逐帧搜索所述音频数据的最优路径,并确定所述最优路径的输入序列和输出序列;
10、片段截取模块,被配置为基于所述输出序列确定所述音频数据中所述发音文本的朗读次数,在所述朗读次数大于一的情况下,基于所述输入序列和所述音素序列,从所述音频数据中截取每次朗读所述发音文本的音频片段;
11、第一评测模块,被配置为从多个所述音频片段中确定出目标对象的目标音频片段,基于所述目标音频片段对所述目标对象的发音进行评测,输出评测结果。
12、第三方面,本申请提供了一种发音评测设备,包括:
13、一个或多个处理器;存储器,存储一个或多个程序,当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如第一方面所述的发音评测方法。
14、第四方面,本申请提供了一种包含计算机可执行指令的存储介质,所述计算机可执行指令在由计算机处理器执行时用于执行如第一方面所述的发音评测方法。
15、在本申请中,采集用户朗读发音文本的音频数据,获取发音文本的音素序列和预先基于该音素序列构建的解码网络,基于解码网络搜索音频数据的最优路径,得到最优路径的输入序列和输出序列,输入序列由音频数据的每个音频帧对应的目标音素按照时序组成,输出序列中发音文本的字符序列的数量与用户朗读发音文本的朗读次数相同。基于输出序列中发音文本的字符序列的数量,可确定音频数据中发音文本的朗读次数,在朗读次数大于一的情况下,音频数据可能录入了非目标对象朗读发音文本时的音频,因此基于输入序列和音素序列,从音频数据中截取每次朗读所述发音文本的音频片段。从多个音频片段中确定出目标对象的目标音频片段,基于目标音频片段对目标对象的发音进行评测,得到目标对象朗读发音文本时的评测结果。本申请用于评测的音频片段只包含目标对象朗读发音文本时的音频片段,滤除了非目标对象的音频对评测结果的影响,提高了评测结果的准确性,解决了现有技术中对孩子发音和家长发音进行综合评测而影响评测结果准确性的问题,评测结果可准确反映孩子的发音问题,有利于孩子纠正自身的发音问题。
技术特征:
1.一种发音评测方法,其特征在于,包括:
2.根据权利要求1所述的发音评测方法,其特征在于,所述基于所述解码网络搜索所述音频数据的最优路径,并确定所述最优路径的输入序列和输出序列,包括:
3.根据权利要求2所述的发音评测方法,其特征在于,所述基于所述输出序列确定所述音频数据中所述发音文本的朗读次数,包括:
4.根据权利要求2所述的发音评测方法,其特征在于,所述基于所述输入序列和所述音素序列,从所述音频数据中截取每次朗读所述发音文本的音频片段,包括:
5.根据权利要求1所述的发音评测方法,其特征在于,所述从多个所述音频片段中确定出目标对象的目标音频片段,包括:
6.根据权利要求1所述的发音评测方法,其特征在于,所述从多个所述音频片段中确定出目标对象的目标音频片段,包括:
7.根据权利要求1所述的发音评测方法,其特征在于,在所述基于所述输出序列确定在所述音频数据中所述发音文本的朗读次数之后,还包括:
8.一种发音评测装置,其特征在于,包括:
9.一种发音评测设备,其特征在于,包括:一个或多个处理器;存储器,存储一个或多个程序,当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如权利要求1-7任一所述的发音评测方法。
10.一种包含计算机可执行指令的存储介质,其特征在于,所述计算机可执行指令在由计算机处理器执行时用于执行如权利要求1-7任一所述的发音评测方法。
技术总结
本申请公开了一种发音评测方法、装置、设备及存储介质,该方法包括:获取音频数据和对应的发音文本,获取发音文本的音素序列和预先构建的解码网络,解码网络中的最后一个节点通过无条件有向路径连接第一个节点;基于解码网络搜索音频数据的最优路径,并确定最优路径的输入序列和输出序列;基于输出序列确定音频数据中发音文本的朗读次数,在朗读次数大于一的情况下,基于输入序列和音素序列,从音频数据中截取每次朗读发音文本的音频片段;从多个音频片段中确定出目标对象的目标音频片段,基于目标音频片段对目标对象的发音进行评测,输出评测结果。通过上述技术手段,评测结果可准确反映孩子的发音问题,有利于孩子纠正自身的发音问题。
技术研发人员:潘潇,雷延强
受保护的技术使用者:广州希倍思智能科技有限公司
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!