语音增强模型训练方法、语音处理方法、装置及设备与流程
本发明涉及信号处理领域,尤其是涉及一种语音增强模型训练方法、语音处理方法、装置及设备。
背景技术:
1、当前单通道语音增强方法主要有监督性语音增强方法和半监督性语音增强方法两种。其中,监督性语音增强方法能够实现含噪语音到纯净语音的映射,但是需要假设目标语音完全纯净,但纯净语音数据的获取需要专业设备,数据采集成本较高。现有半监督性语音增强方法通过引入了自动语音识别(automatic speech recognition,asr)嵌入embedding的目标函数,使错词率下降,然而其听觉感知质量相关的语音整体质量ovl等指标有所降低。并且半监督性语音增强方法需要语音完全纯净或者完全含噪,这使得数据需要额外提供标签,成本高,且其增强后语音质量并不如监督性学习方法。
2、即现有的单通道语音增强方法存在应用成本高,且适用范围窄的问题。
技术实现思路
1、本发明的目的在于提供一种语音增强模型训练方法、语音处理方法、装置及设备,用以解决现有单通道语音增强方法存在的应用成本高,且适用范围窄的问题。
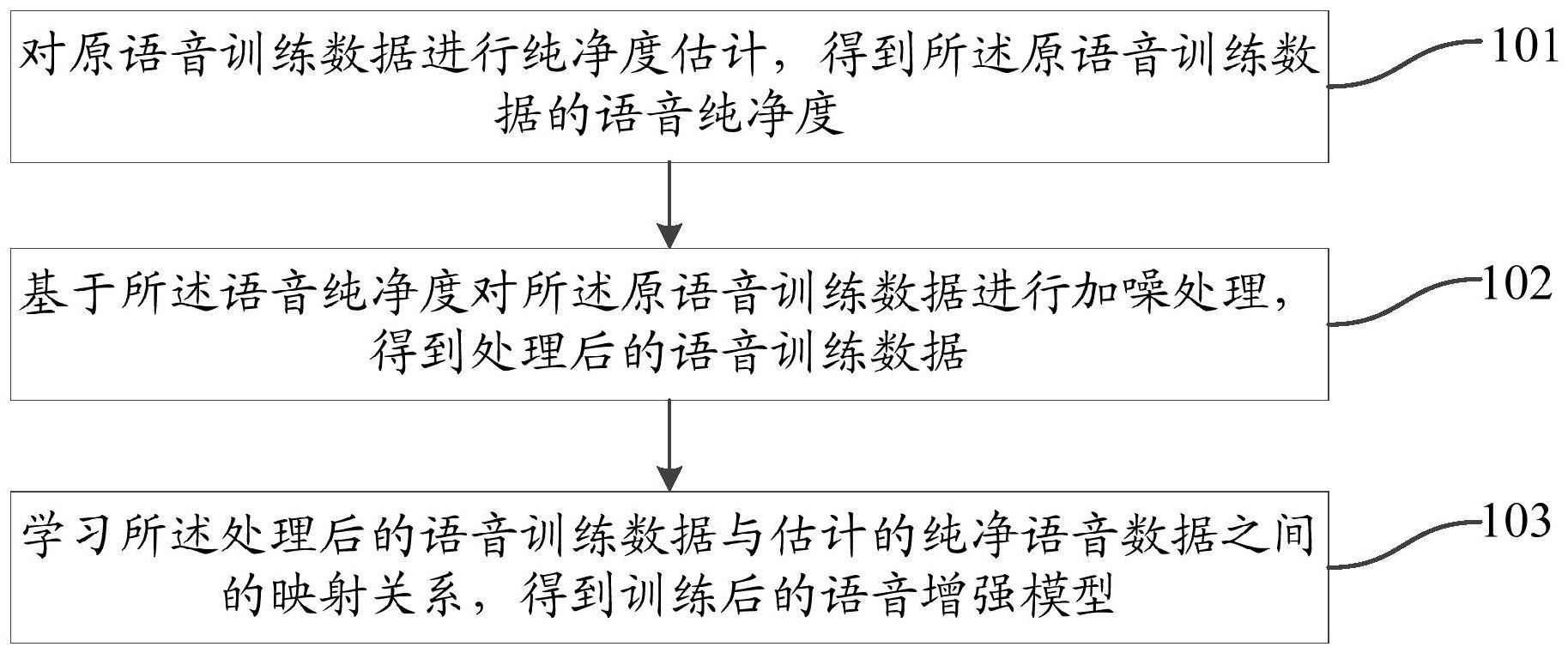
2、为了达到上述目的,第一方面,本发明提供一种语音增强模型训练方法,包括:
3、对原语音训练数据进行纯净度估计,得到所述原语音训练数据的语音纯净度;
4、基于所述语音纯净度对所述原语音训练数据进行加噪处理,得到处理后的语音训练数据;
5、学习所述处理后的语音训练数据与估计的纯净语音数据之间的映射关系,得到训练后的语音增强模型。
6、其中,所述对原语音训练数据进行纯净度估计,得到所述原语音训练数据的语音纯净度,包括:
7、获取所述原语音训练数据的平均意见得分和语音占比;
8、根据所述平均意见得分和所述语音占比进行噪声干扰计算,得到背景噪声干扰程度;
9、对所述背景噪声干扰程度进行裁剪处理,获得所述原语音训练数据的语音纯净度。
10、其中,所述基于所述语音纯净度对所述原语音训练数据进行加噪处理,得到处理后的语音训练数据,包括:
11、在所述语音纯净度大于预设阈值的情况下,根据预设信噪比对所述原语音训练数据进行加噪处理,得到处理后的语音训练数据;
12、在所述语音纯净度小于或者等于预设阈值的情况下,将所述原语音训练数据确定为处理后的语音训练数据。
13、其中,所述学习所述处理后的语音训练数据与估计的纯净语音数据之间的映射关系,得到训练后的语音增强模型,包括:
14、基于半监督目标函数,训练深度神经网络,得到训练后语音增强模型,其中,所述半监督目标函数基于监督性目标函数、非监督性目标函数和所述语音纯净度建立;所述监督性目标函数基于所述原语音训练数据和估计的纯净语音数据获得,所述非监督性目标函数基于估计的纯净语音数据获得;所述深度神经网络用于学习所述处理后的语音训练数据与估计的纯净语音数据之间的映射关系。
15、其中,所述监督性目标函数为最小化尺度不变的信噪比sisnr损失函数,所述非监督性目标函数为深度噪声抑制平均意见得分dnsmos损失函数。
16、第二方面,本发明还提供一种语音处理方法,包括:
17、获取第一语音信号,所述第一语音信号为含噪的语音信号;
18、将所述第一语音信号输入至语音增强模型,得到纯净的语音信号,其中,所述语音增强模型通过学习处理后的语音训练数据与估计的纯净语音数据之间的映射关系训练得到,所述处理后的语音训练数据基于原语音训练数据的语音纯净度对所述原语音训练数据的加噪处理得到。
19、其中,所述方法还包括:
20、对原语音训练数据进行纯净度估计,得到所述原语音训练数据的语音纯净度;
21、基于所述语音纯净度对所述原语音训练数据进行加噪处理,得到处理后的语音训练数据;
22、学习所述处理后的语音训练数据与估计的纯净语音数据之间的映射关系,得到训练后的语音增强模型。
23、第三方面,本发明还提供一种语音增强模型训练装置,包括:
24、第一处理模块,用于对原语音训练数据进行纯净度估计,得到所述原语音训练数据的语音纯净度;
25、第二处理模块,用于基于所述语音纯净度对所述原语音训练数据进行加噪处理,得到处理后的语音训练数据;
26、第一模型训练模块,用于学习所述处理后的语音训练数据与估计的纯净语音数据之间的映射关系,得到训练后的语音增强模型。
27、第四方面,本发明还提供一种语音处理装置,包括:
28、获取模块,用于获取第一语音信号,所述第一语音信号为含噪的语音信号;
29、第三处理模块,用于将所述第一语音信号输入至语音增强模型,得到纯净的语音信号,其中,所述语音增强模型通过学习处理后的语音训练数据与估计的纯净语音数据之间的映射关系训练得到,所述处理后的语音训练数据基于原语音训练数据的语音纯净度对所述原语音训练数据的加噪处理得到。
30、第五方面,本发明还提供一种语音增强模型训练设备,包括处理器和收发器,所述收发器在处理器的控制下接收和发送数据,所述处理器用于执行以下操作:
31、对原语音训练数据进行纯净度估计,得到所述原语音训练数据的语音纯净度;
32、基于所述语音纯净度对所述原语音训练数据进行加噪处理,得到处理后的语音训练数据;
33、学习所述处理后的语音训练数据与估计的纯净语音数据之间的映射关系,得到训练后的语音增强模型。
34、第六方面,本发明还提供一种语音增强模型训练设备,包括存储器、处理及存储在所述存储器上并可在所述处理器上运行的程序;所述处理器执行所述程序时实现如上述第一方面所述的语音增强模型训练方法。
35、第七方面,本发明还提供一种语音处理设备,包括处理器和收发器,所述收发器在处理器的控制下接收和发送数据,所述处理器用于执行以下操作:
36、获取第一语音信号,所述第一语音信号为含噪的语音信号;
37、将所述第一语音信号输入至语音增强模型,得到纯净的语音信号,其中,所述语音增强模型通过学习处理后的语音训练数据与估计的纯净语音数据之间的映射关系训练得到,所述处理后的语音训练数据基于原语音训练数据的语音纯净度对所述原语音训练数据的加噪处理得到。
38、第八方面,本发明还提供一种语音处理设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的程序;所述处理器执行所述程序时实现如上述第二方面所述的语音处理方法。
39、第九方面,本发明还提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上述第一方面所述的语音增强模型训练方法中的步骤,或者实现如上述第二方面所述的语音处理方法中的步骤。
40、本发明的上述技术方案至少具有如下有益效果:
41、本发明实施例中,通过对原语音训练数据进行纯净度估计,得到所述原语音训练数据的语音纯净度;基于所述语音纯净度对所述原语音训练数据进行加噪处理,得到处理后的语音训练数据;学习所述处理后的语音训练数据与估计的纯净语音数据之间的映射关系,得到训练后的语音增强模型,这样,通过采用包括纯净语音数据和含噪语音数据的原语音训练数据,能够扩展语音训练数据集的数量以及范围,降低数据获取成本,并且能使训练的语音增强的适用范围更广,而且通过语音纯净度估计,使数据无需预先标注即可进行网络训练,从而降低了标注产生的成本。
- 还没有人留言评论。精彩留言会获得点赞!